동남아 문화 이해를 위한 비전‑언어 모델 평가 벤치마크 RICE‑VL
📝 원문 정보
- Title: Rice-VL: Evaluating Vision-Language Models for Cultural Understanding Across ASEAN Countries
- ArXiv ID: 2512.01419
- 발행일: 2025-12-01
- 저자: Tushar Pranav, Eshan Pandey, Austria Lyka Diane Bala, Aman Chadha, Indriyati Atmosukarto, Donny Soh Cheng Lock
📝 초록 (Abstract)
비전‑언어 모델(VLM)은 멀티모달 작업에서 뛰어난 성능을 보이지만, 서구 중심의 편향으로 인해 동남아시아와 같은 문화적으로 다양한 지역에서는 한계가 있다. 이를 해결하고자 본 연구는 11개 ASEAN 국가의 문화적 이해도를 평가하는 새로운 벤치마크인 RICE‑VL을 제안한다. RICE‑VL은 28,000개가 넘는 인간이 직접 선별한 시각‑질문‑답변(VQA) 샘플(참/거짓, 빈칸 채우기, 자유형식)과 1,000개의 이미지‑바운딩 박스 쌍(시각적 그라운딩)을 포함하며, 14개의 하위 영역에 걸쳐 문화적으로 숙련된 전문가가 주석을 달았다. 우리는 텍스트 정확도, 문화 정렬도, 국가 식별을 동시에 측정하는 SEA‑LAVE라는 LAVE 메트릭의 확장판을 제안한다. 여섯 개의 공개·폐쇄형 VLM을 평가한 결과, 자원 부족 국가와 추상적인 문화 영역에서 현저한 성능 격차가 드러났다. 시각적 그라운딩 과제는 복합 장면에서 문화적으로 중요한 요소를 정확히 위치시키는 모델의 능력을 시험함으로써 공간적·맥락적 정확성을 검증한다. RICE‑VL은 VLM의 문화적 이해 한계를 드러내며, 보다 포괄적인 모델 개발의 필요성을 강조한다.💡 논문 핵심 해설 (Deep Analysis)

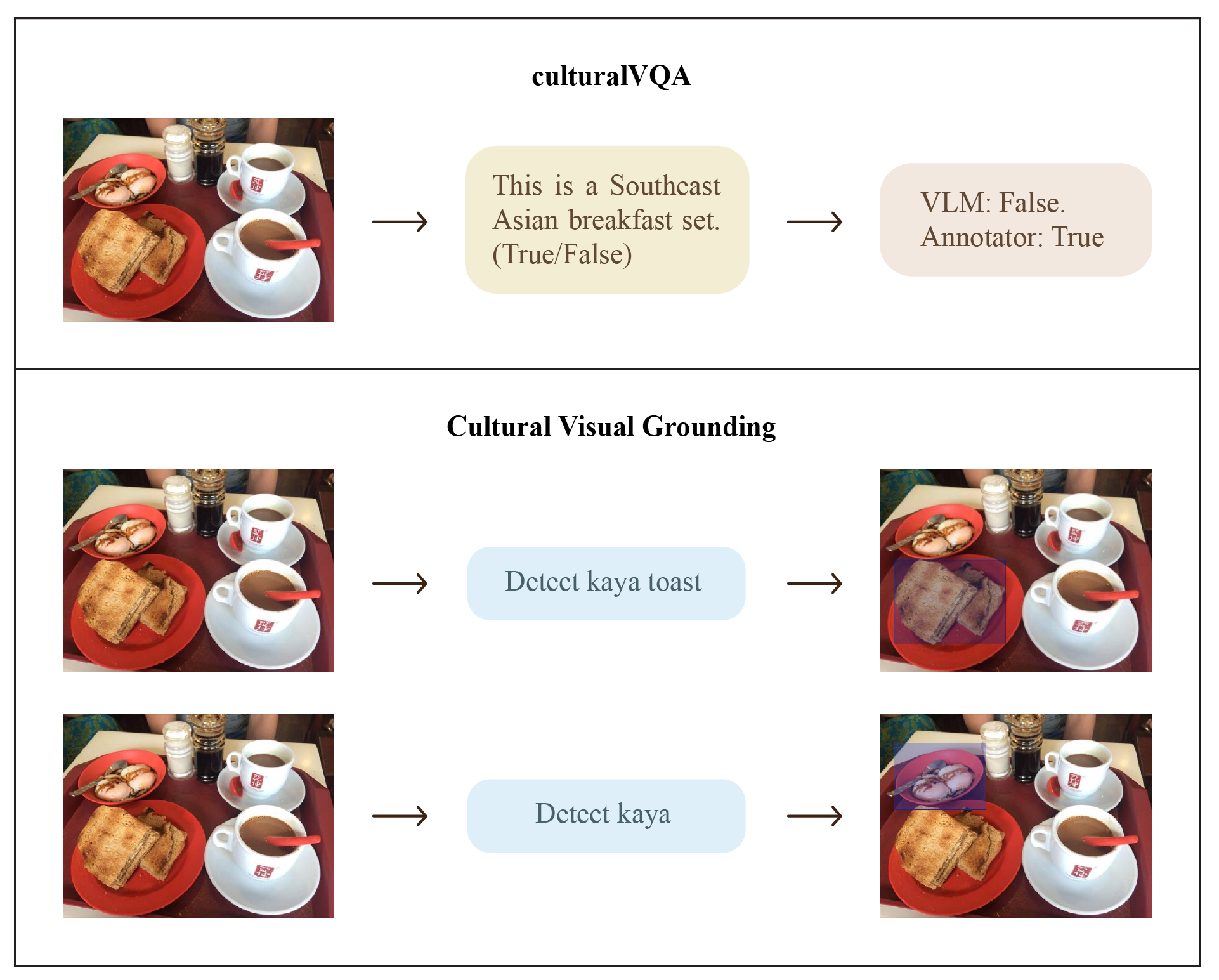
시각적 그라운딩 파트는 1,000개의 이미지‑바운딩 박스 쌍을 포함한다는 점에서 주목할 만하다. 이 데이터는 “문화적 의미가 부여된 객체”를 정확히 식별하고 위치를 지정하도록 요구한다. 예를 들어, 인도네시아의 바틱 무늬, 말레이시아의 바투 케다르, 베트남의 전통 옷인 아오자이 등은 서구 데이터셋에서 거의 등장하지 않으며, 이러한 요소를 정확히 인식하고 바운딩 박스로 표시하는 능력은 모델의 문화적 일반화 능력을 직접적으로 드러낸다.
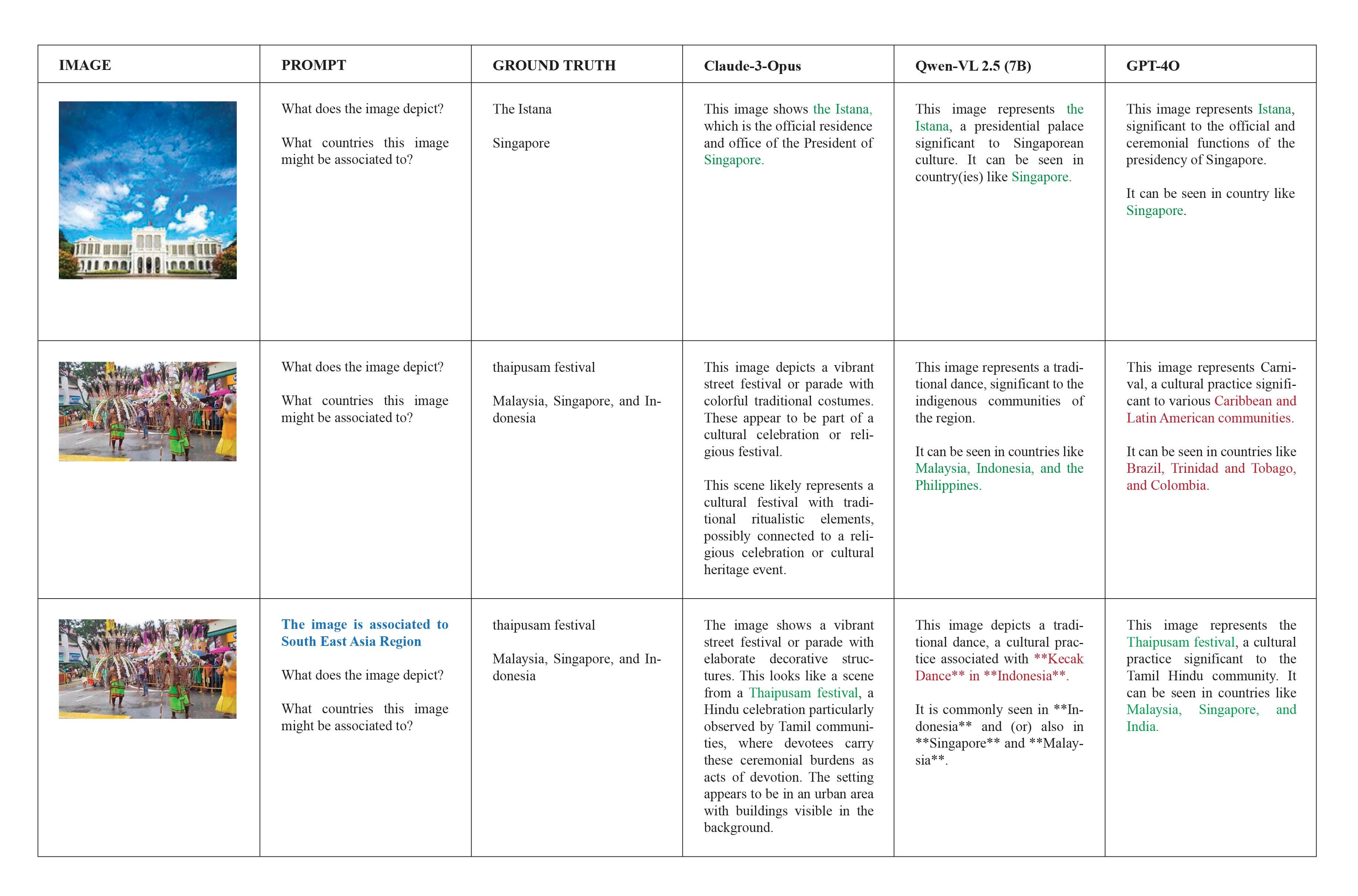
SEA‑LAVE 메트릭은 기존 LAVE에 “문화 정렬도(Cultural Alignment)”와 “국가 식별(Country Identification)”이라는 두 축을 추가함으로써 평가 차원을 확장한다. 텍스트 정확도는 전통적인 정답 일치율을 측정하고, 문화 정렬도는 모델이 제공한 답변이 해당 문화적 배경과 얼마나 일치하는지를 평가한다. 국가 식별은 모델이 질문에 언급된 국가를 정확히 인식하고, 그에 맞는 문화적 정보를 제공하는지를 점검한다. 이 세 가지 요소를 가중 평균하는 방식은 단순 정확도만으로는 포착하기 어려운 미묘한 문화적 편향을 드러내는 데 효과적이다.
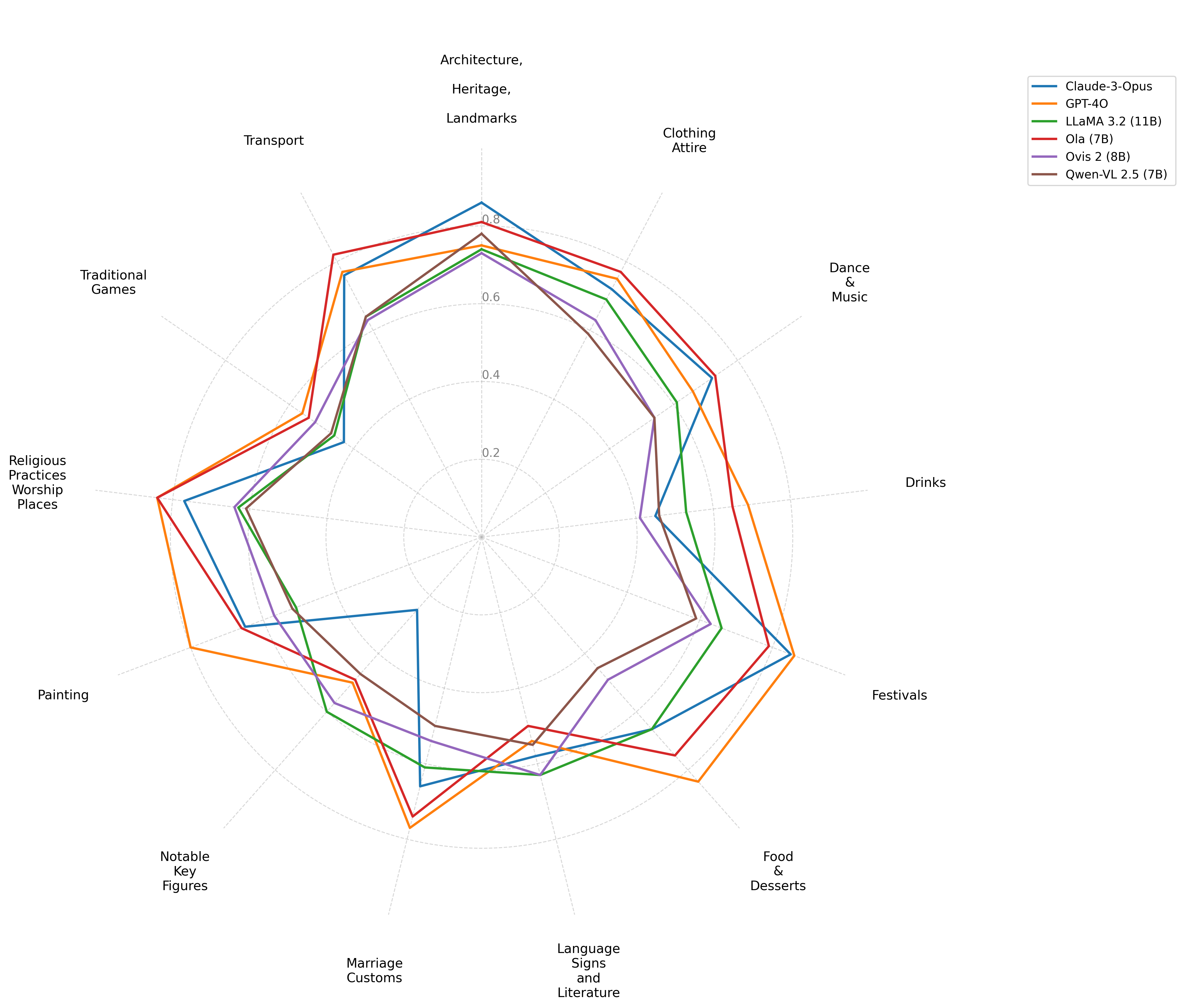
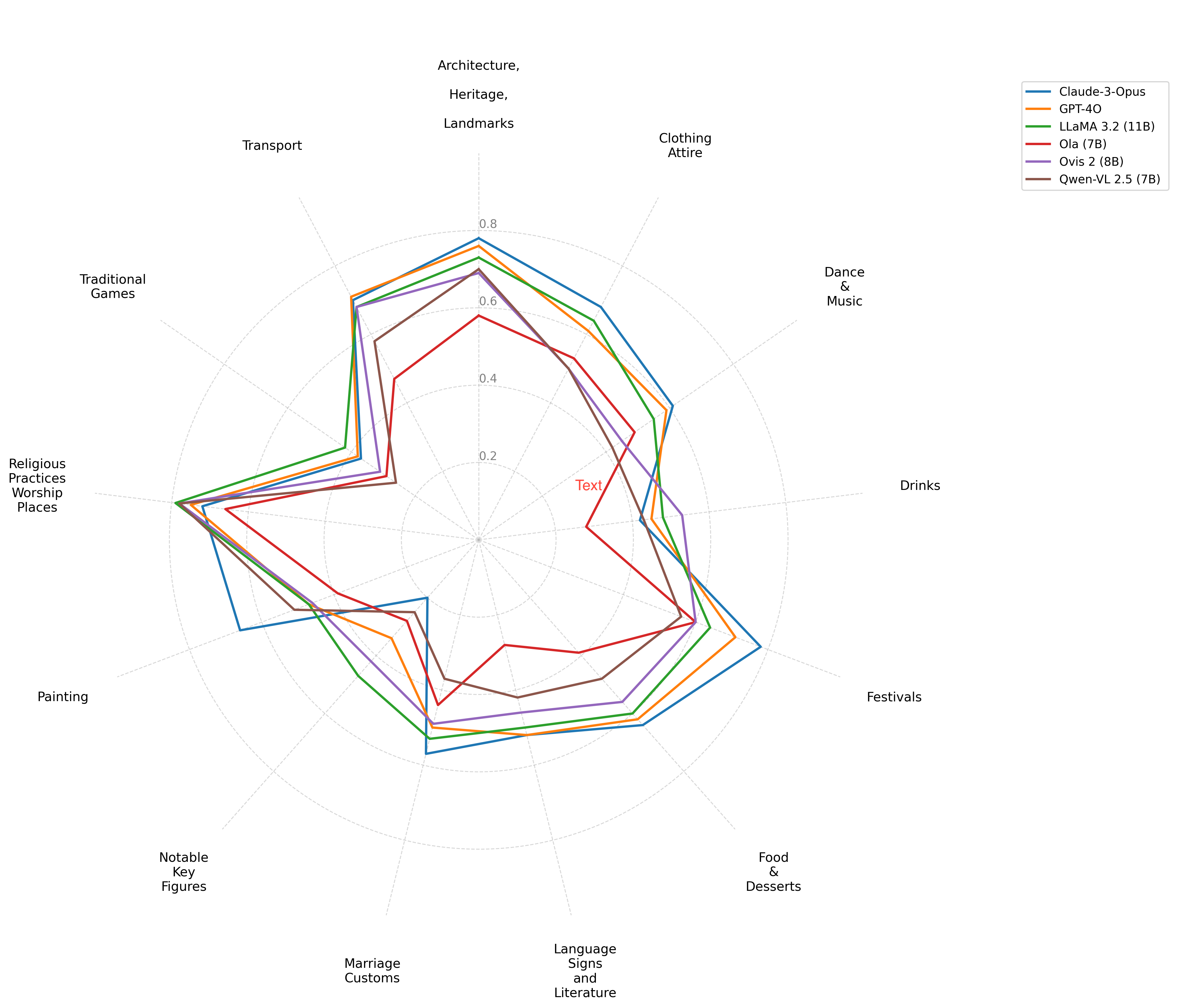
실험 결과는 흥미롭다. GPT‑4‑Vision, LLaVA‑1.5, BLIP‑2 등 최신 공개 모델들은 전반적으로 높은 텍스트 정확도를 보였지만, 문화 정렬도와 국가 식별 점수에서는 크게 뒤처졌다. 특히 자원 부족 국가(예: 라오스, 캄보디아)와 추상적 문화 영역(예: 전통 의식, 민속 전설)에서 성능 격차가 두드러졌다. 이는 모델이 대규모 웹 데이터에 의존하면서 서구·중국·일본 중심의 이미지와 텍스트에 과도하게 노출된 결과로 해석할 수 있다.
또한, 시각적 그라운딩 테스트에서 대부분의 모델은 “문화적 핵심 객체”를 정확히 로컬라이징하지 못했다. 예를 들어, 베트남의 전통 시장 풍경에서 “반찬을 파는 노점”을 식별하지 못하거나, 필리핀의 축제 장면에서 “전통 춤을 추는 인물”을 놓치는 경우가 빈번했다. 이는 현재 VLM이 이미지 내 객체 인식은 뛰어나지만, 문화적 의미 부여와 같은 고차원적 이해에는 한계가 있음을 시사한다.
결론적으로, RICE‑VL은 VLM 연구에 문화적 다양성을 정량화할 수 있는 강력한 도구를 제공한다. 향후 모델 개발에서는 다국어·다문화 데이터의 균형 잡힌 수집, 문화‑특화 프롬프트 엔지니어링, 그리고 문화 정렬도를 직접 최적화하는 손실 함수를 도입하는 것이 필요하다. 이러한 방향성을 통해 VLM이 전 세계 다양한 사용자에게 공정하고 유용한 서비스를 제공할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리