가지치기 전에 생각하라 추론 언어 모델을 위한 자기반영 구조적 가지치기
📝 원문 정보
- Title: Think Before You Prune: Self-Reflective Structured Pruning for Reasoning Language Models
- ArXiv ID: 2512.02185
- 발행일: 2025-12-01
- 저자: Ziyan Wang, Enmao Diao, Qi Le, Pu Wang, Guanchu Wang, Minwoo Lee, Shu-ping Yeh, Li Yang
📝 초록 (Abstract)
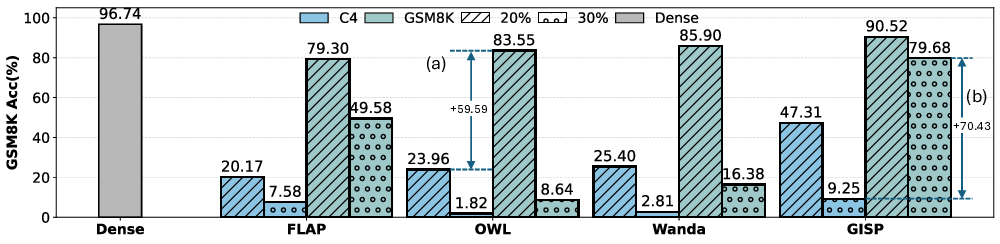
추론 능력이 뛰어난 대형 언어 모델은 체인‑오브‑쓰루(Chain‑of‑Thought) 생성으로 복잡한 다단계 추론을 수행하지만, 모델 규모와 긴 출력 길이 때문에 배포 비용이 높고 자원 제한 환경에 부적합합니다. 파라미터를 제거하는 가지치기는 계산·메모리 절감에 유망하지만, 기존 방법은 표준 LLM에서는 효과적이지만 추론 모델에서는 20 % 수준의 희소성만으로도 정확도가 급락하고 추론 일관성이 무너지는 심각한 문제를 보입니다. 저희는 기존 파이프라인이 실패하는 원인을 분석한 결과, 캘리브레이션 데이터와 가지치기 목표, 그리고 디코드 시 추론 행동 사이의 불일치가 주요 원인임을 발견했습니다. 특히 인간이 만든 라벨보다 모델이 스스로 생성한 추론 과정이 모델의 실제 추론 분포를 더 잘 반영한다는 점을 확인했습니다. 이러한 통찰을 바탕으로, 모델 자체가 만든 캘리브레이션 신호와 디코드 전용 그래디언트 기반 중요도 추정, 그리고 희소도가 증가함에 따라 캘리브레이션 정확성을 유지하는 단계적 재생성을 결합한 SELF‑REFLECTIVE STRUCTURED PRUNING 프레임워크인 RESP를 제안합니다. Qwen3‑8B에 대한 실험에서 RESP는 GSM8K와 MathQA에서 기존 구조적 가지치기 방법을 크게 앞서며, 20‑30 % 희소성에서도 거의 밀집 모델 수준의 정확도를 유지하고, 40 % 희소성에서는 GSM8K 81.3 %·MathQA 59.6 %의 성능을 달성해 최고 기준 대비 각각 66.87 %·47 % 향상시켰습니다.💡 논문 핵심 해설 (Deep Analysis)

이러한 문제점을 해결하기 위해 제안된 RESP는 세 가지 핵심 요소로 구성된다. 1) 자기생성 캘리브레이션: 모델이 직접 만든 추론 트레이스를 라벨 대신 사용함으로써, 실제 추론 시 나타나는 토큰 분포와 논리 흐름을 그대로 반영한다. 2) 디코드‑전용 그래디언트 기반 중요도 추정: 전통적인 손실 기반 중요도 측정 대신, 디코드 단계에서 발생하는 그래디언트를 활용해 각 파라미터가 현재 추론 흐름에 얼마나 기여하는지를 정량화한다. 이는 특히 체인‑오브‑쓰루와 같이 단계별 논리 전개가 중요한 상황에서 파라미터의 실제 역할을 정확히 파악한다. 3) 점진적 재생성(Progressive Regeneration): 희소성이 증가함에 따라 모델이 이전 단계에서 생성한 추론 트레이스를 재사용하거나 새롭게 생성하도록 하여, 캘리브레이션 신호가 지속적으로 최신 상태를 유지하도록 만든다. 이 과정은 “자기 반영”이라는 메타 학습 개념을 구현한 것으로, 모델이 스스로 자신의 약점을 인식하고 보정하도록 돕는다.
실험에서는 최신 오픈소스 모델인 Qwen3‑8B를 대상으로 GSM8K와 MathQA 두 벤치마크에서 성능을 평가하였다. 기존 구조적 가지치기 기법들은 20 % 희소성에서도 정확도가 급격히 떨어지는 반면, RESP는 20‑30 % 수준에서는 밀집 모델과 거의 차이가 없으며, 40 % 희소성에서도 GSM8K 81.3 %·MathQA 59.6 %라는 높은 정확도를 유지한다. 특히 “성능 붕괴 방지”라는 관점에서 기존 최강 기준 대비 각각 66.87 %·47 %의 상대적 향상을 기록했다. 이는 모델 자체가 생성한 추론 트레이스를 캘리브레이션에 활용함으로써, 파라미터 감소에도 불구하고 논리적 일관성을 유지할 수 있음을 입증한다.
이 논문의 의의는 두드러진데, 첫째는 RLM 특유의 추론 동역학을 고려한 새로운 가지치기 패러다임을 제시했다는 점이다. 둘째, “자기 반영”이라는 메타 학습 아이디어를 실제 파라미터 압축에 적용함으로써, 모델이 스스로 자신의 약점을 진단하고 보정하도록 하는 메커니즘을 구현했다는 점이다. 셋째, 실용적인 관점에서 40 % 수준의 구조적 희소성을 달성하면서도 고성능을 유지한다는 결과는, 추론 모델을 엣지 디바이스나 비용 제한 환경에 배포하는 데 큰 가능성을 열어준다.
하지만 몇 가지 한계도 존재한다. 현재 실험은 8 B 규모 모델에만 적용했으며, 30 B 이상 초대형 모델에 대한 확장성은 검증되지 않았다. 또한 자기생성 캘리브레이션이 모델의 초기 성능에 크게 의존하므로, 초기 모델이 충분히 강력하지 않을 경우 오히려 잡음이 증폭될 위험이 있다. 마지막으로, 단계별 그래디언트 계산과 점진적 재생성 과정이 추가적인 연산 오버헤드를 발생시키는데, 이는 실제 배포 시 실시간 추론 속도에 영향을 미칠 수 있다. 향후 연구에서는 이러한 오버헤드를 최소화하는 경량화 전략과, 다양한 모델 규모 및 도메인에 대한 일반화 검증이 필요할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리