프로그래밍 기반 프롬프트로 자동화된 무작위 대조시험 위험 편향 평가 GEPA 프레임워크 첫 시도
📝 원문 정보
- Title: Automated Risk-of-Bias Assessment of Randomized Controlled Trials: A First Look at a GEPA-trained Programmatic Prompting Framework
- ArXiv ID: 2512.01452
- 발행일: 2025-12-01
- 저자: Lingbo Li, Anuradha Mathrani, Teo Susnjak
📝 초록 (Abstract)
무작위 대조시험(RCT)의 위험 편향(RoB) 평가가 증거 종합의 신뢰성을 확보하는 핵심 단계이지만, 현재 방법은 인력 소모가 크고 평가자 간 변동성이 존재한다. 대형 언어 모델(LLM)을 활용한 자동화가 가능하나 기존 연구는 수작업으로 설계된 프롬프트에 의존해 재현성과 일반화에 한계가 있다. 본 연구는 DSPy와 그 GEPA 모듈을 이용해 구조화된 코드 기반 최적화를 통해 프롬프트 설계를 대체하는 프로그래머블 RoB 평가 파이프라인을 제안한다. GEPA는 파레토 가이드 탐색을 통해 LLM 추론을 정제하고, 실행 추적을 제공해 최적화 과정을 투명하게 복제할 수 있게 한다. 7개 RoB 영역에 걸쳐 100개의 메타분석에 포함된 RCT를 대상으로 평가했으며, 오픈‑웨이트 모델(Mistral Small 3.1 + GPT‑oss‑20b)과 상용 모델(GPT‑5 Nano, GPT‑5 Mini)을 적용했다. 보고가 명확한 영역(예: 무작위 시퀀스 생성)에서는 GEPA가 생성한 프롬프트가 가장 높은 성능을 보였으며, 할당 은폐와 참여자 블라인딩에서도 유사한 결과가 나타났다. 전체적으로는 상용 모델이 약간 우수했다. 또한 Claude 3.5 Sonnet을 이용한 수동 설계 프롬프트 3종과 비교했을 때, GEPA는 전반적인 정확도에서 최고였으며 무작위 시퀀스 생성과 선택적 보고 영역에서 30‑40% 향상을 달성했다. 이러한 결과는 GEPA가 RoB 평가를 위한 일관되고 재현 가능한 프롬프트를 제공함으로써 증거 종합에서 LLM 활용을 구조적이고 원칙적으로 지원할 수 있음을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
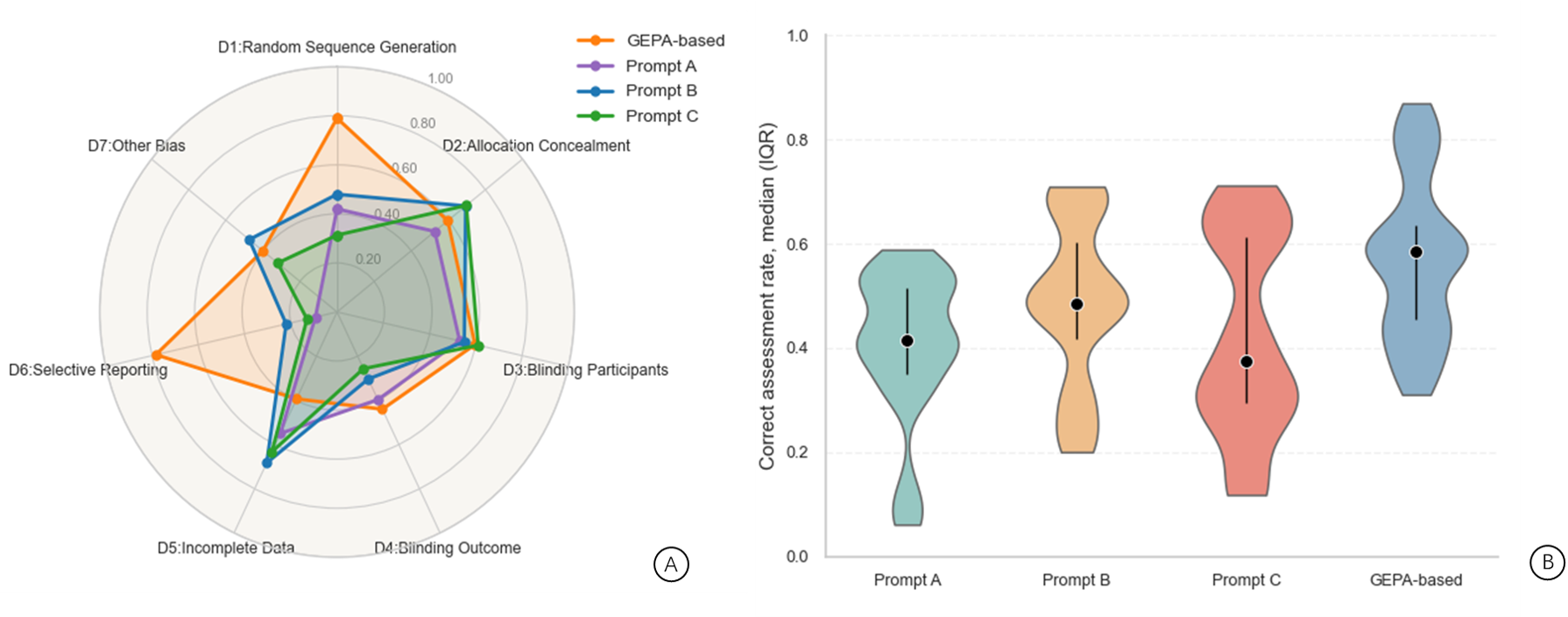
실험 설계는 7개 RoB 도메인(무작위 시퀀스 생성, 할당 은폐, 참여자·연구자·평가자 블라인딩, 결과 측정, 누락 데이터, 선택적 보고, 기타)에서 100개의 실제 RCT를 표본으로 사용했다. 두 종류의 모델군—오픈‑웨이트(Mistral Small 3.1 + GPT‑oss‑20b)과 상용 모델(GPT‑5 Nano, GPT‑5 Mini)—에 동일한 GEPA‑생성 프롬프트를 적용함으로써 모델 자체의 성능 차이를 분리해 평가했다. 결과는 보고가 명확히 기술된 도메인(특히 Random Sequence Generation)에서 GEPA 프롬프트가 가장 높은 정확도를 기록했으며, Allocation Concealment과 Blinding of Participants에서도 비슷한 수준을 유지했다. 반면, 보고가 불완전하거나 주관적 판단이 요구되는 도메인(Selective Reporting 등)에서는 상용 모델이 약간 우위를 보였지만, GEPA가 수동 설계 프롬프트 대비 30‑40% 향상된 성능을 보여 자동화의 효용성을 입증했다.
또한, Claude 3.5 Sonnet을 이용해 수동으로 설계된 3개의 프롬프트와 비교했을 때, GEPA는 전반적인 정확도와 일관성 면에서 최고였으며, 특히 Random Sequence Generation과 Selective Reporting에서 큰 폭의 개선을 보였다. 이는 파레토 기반 다목표 최적화가 단순 정확도 최적화보다 더 균형 잡힌 프롬프트를 생성한다는 실증적 증거로 해석될 수 있다.
한계점으로는 100개의 RCT라는 비교적 제한된 샘플 규모와, 선택된 모델군이 최신 최첨단 모델을 모두 포함하지 않았다는 점을 들 수 있다. 또한, GEPA의 탐색 비용(컴퓨팅 자원 및 시간)이 아직 상용 환경에서 실시간 적용하기엔 부담스러울 수 있다. 향후 연구에서는 더 다양한 언어·분야의 RCT, 최신 LLM(예: GPT‑4o, Claude 3.5 등)과의 비교, 그리고 비용‑효율성을 고려한 탐색 전략을 모색해야 할 것이다.
결론적으로, 본 연구는 프로그래밍 기반 프롬프트 최적화가 RoB 자동 평가에 있어 재현성, 투명성, 성능 측면에서 유의미한 진전을 제공한다는 점을 보여준다. 이는 증거 종합 워크플로우에 LLM을 체계적으로 통합하려는 연구자와 실무자에게 중요한 참고 모델이 될 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리

