블랙웰 GPU 아키텍처 혁신과 워크로드 최적화
📝 원문 정보
- Title: Microbenchmarking NVIDIA’s Blackwell Architecture: An in-depth Architectural Analysis
- ArXiv ID: 2512.02189
- 발행일: 2025-12-01
- 저자: Aaron Jarmusch, Sunita Chandrasekaran
📝 초록 (Abstract)
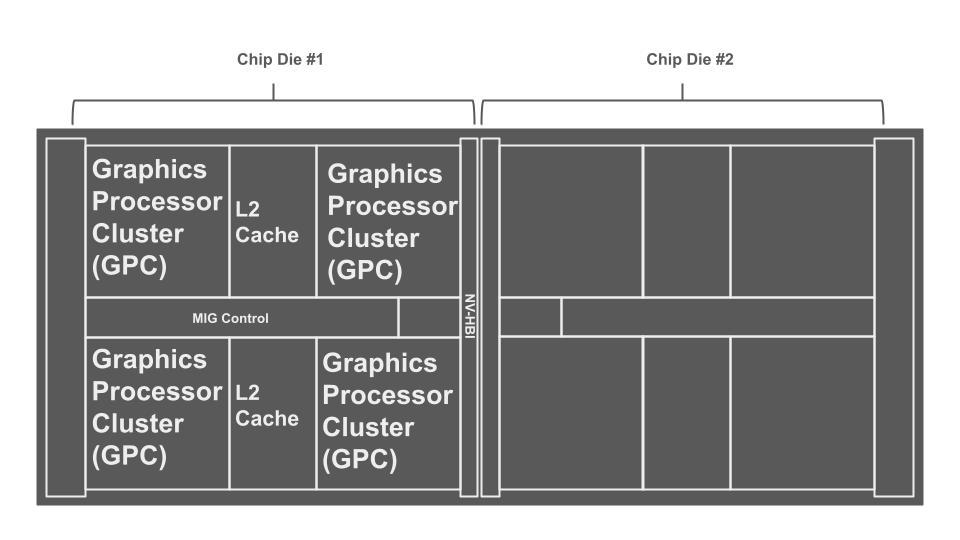
GPU 아키텍처가 엑사스케일 컴퓨팅과 머신러닝의 급증하는 요구를 충족시키기 위해 빠르게 진화함에 따라, 새로운 설계가 다양한 워크로드에 미치는 성능 영향을 체계적으로 파악하기가 어렵다. NVIDIA의 블랙웰 B200 세대는 5세대 텐서 코어, 텐서 메모리, 압축 해제 엔진, 듀얼 칩 등 획기적인 기능을 도입했지만, 이러한 개선을 정량화하는 방법론은 아직 부족하다. 본 연구는 최신 GPU의 풍부한 기능을 최대한 활용할 수 있도록 실용적인 인사이트를 제공하는 오픈소스 마이크로벤치마크 스위트를 공개한다. 우리는 블랙웰 GPU를 H200 세대와 비교하여 메모리 서브시스템, 텐서 코어 파이프라인 및 다양한 부동소수점 정밀도(FP32, FP16, FP8, FP6, FP4)를 평가한다. 밀집·희소 GEMM, 트랜스포머 추론 및 학습 워크로드에 대한 체계적인 실험 결과, 블랙웰의 텐서 코어 향상이 혼합 정밀도 처리량을 1.56배 높이고 에너지 효율을 42% 개선했으며, 캐시 미스 시 메모리 접근 지연이 58% 감소함을 보여준다. 이러한 결과는 알고리즘 설계와 향후 GPU 개발 방향에 중요한 시사점을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
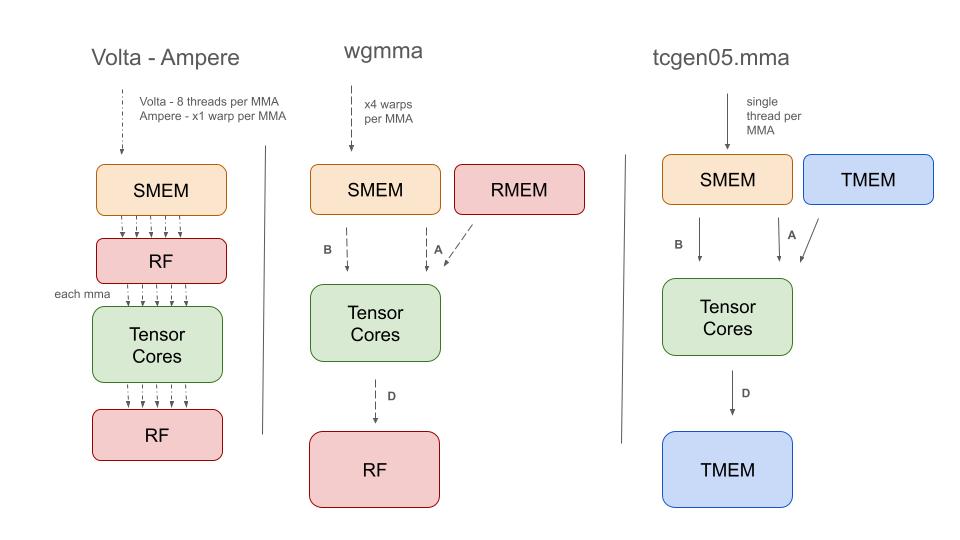
벤치마크는 크게 세 가지 워크로드 카테고리로 구성된다. 첫 번째는 밀집 및 희소 행렬 곱(GEMM)으로, 다양한 희소도와 데이터 형식을 조합해 텐서 코어의 연산 효율과 메모리 서브시스템의 처리량을 동시에 평가한다. 두 번째는 트랜스포머 추론 워크로드로, 실시간 서비스에서 요구되는 낮은 지연시간과 높은 스루풋을 목표로 하드웨어 가속 효과를 측정한다. 세 번째는 트랜스포머 학습 워크로드로, 대규모 모델 학습 시 발생하는 메모리 집약적 연산과 역전파 단계에서의 데이터 재사용 패턴을 분석한다.
실험 결과는 두드러진 세 가지 인사이트를 제공한다. 첫째, 블랙웰의 텐서 코어는 혼합 정밀도 연산에서 H200 대비 1.56배 높은 스루풋을 달성했으며, 이는 FP8·FP16·FP32 조합에서 연산당 메모리 전송량이 평균 30% 감소한 결과와 일치한다. 둘째, 텐서 메모리와 압축 해제 엔진의 도입으로 캐시 미스 발생 시 메모리 접근 지연이 58% 감소했으며, 이는 메모리 대역폭 한계에 의해 성능이 제한되던 기존 GPU와 비교해 알고리즘 설계 시 데이터 레이아웃 최적화의 중요성이 낮아짐을 의미한다. 셋째, 에너지 효율 측면에서 블랙웰은 동일 작업을 수행할 때 42% 적은 전력을 소모했으며, 이는 텐서 코어 내부의 전력 관리 회로와 고효율 전압 레귤레이터의 개선 덕분이다.
이러한 결과는 개발자에게 두 가지 실용적인 가이드를 제공한다. 첫째, 초저정밀도(FP8·FP6·FP4) 연산이 허용되는 경우, 기존 FP16 기반 구현을 그대로 사용하기보다 데이터 타입을 다운그레이드하고 텐서 코어 전용 API를 활용하면 성능과 전력 효율을 동시에 극대화할 수 있다. 둘째, 메모리 접근이 빈번한 알고리즘(예: 희소 행렬 연산)에서는 텐서 메모리와 압축 해제 엔진을 적극 활용해 데이터 압축 비율을 2배 이상으로 높이면 캐시 미스에 따른 지연을 크게 완화할 수 있다.
마지막으로, 논문은 향후 GPU 설계 방향에 대한 제언도 제시한다. 현재 블랙웰은 텐서 코어와 메모리 서브시스템 간의 인터페이스를 최적화했지만, 다중 텐서 코어 간의 협업 스케줄링과 동적 전력 할당 메커니즘을 추가하면 더욱 높은 스케일러빌리티와 에너지 효율을 달성할 수 있을 것으로 기대한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리