원자에서 복합까지 강화학습이 보완적 추론 일반화를 가능하게 하다
📝 원문 정보
- Title: From Atomic to Composite: Reinforcement Learning Enables Generalization in Complementary Reasoning
- ArXiv ID: 2512.01970
- 발행일: 2025-12-01
- 저자: Sitao Cheng, Xunjian Yin, Ruiwen Zhou, Yuxuan Li, Xinyi Wang, Liangming Pan, William Yang Wang, Victor Zhong
📝 초록 (Abstract)
강화학습(RL)을 사후 학습 단계로 활용하고 사전 학습 단계에 감독 학습(SFT)을 적용하는 방식이 대형 언어 모델(LLM)의 표준 파이프라인이 되고 있다. 그러나 RL이 추론 능력에 어떻게 기여하는지—새로운 기술을 합성하도록 유도하는지, 아니면 기존 행동을 단순히 증폭시키는지—는 아직 논쟁이 많다. 본 연구는 내부 파라메트릭 지식과 외부 컨텍스트 정보를 통합해야 하는 복합 과제인 ‘보완적 추론(Complementary Reasoning)’을 통해 이 질문을 탐구한다. 인간 전기 데이터셋을 인위적으로 설계해 이 능력을 두 개의 원자적 스킬, 즉 파라메트릭 추론(모델 파라미터에 내재된 지식 활용)과 컨텍스트 추론(컨텍스트 창에 제공된 새로운 정보 활용)으로 명확히 분리하였다. 일반화 경계를 엄격히 평가하기 위해 I.I.D., 조합(Composition), 제로샷(Zero‑shot) 세 가지 난이도 수준을 설정하였다. 실험 결과, SFT만으로는 동일 분포 내 성능은 충분히 확보하지만, 특히 새로운 관계 조합이 요구되는 제로샷 상황에서는 외부 일반화가 크게 떨어진다. 특히 ‘SFT 일반화 역설’이라 명명한 현상이 관찰되었는데, 복합 과제에만 감독을 부여한 모델은 I.I.D.에서는 90%에 육박하는 정확도를 보이지만, OOD 일반화에서는 18% 수준으로 급락한다. 이는 모델이 경로 단축(shortcut) 기억에 의존하고 있음을 의미한다. 반면 RL은 확률 증폭이 아니라 추론 합성기 역할을 수행한다는 점이 확인되었다. 다만 RL이 이러한 복합 전략을 합성하려면, 사전 모델이 파라메트릭 및 컨텍스트 추론이라는 두 원자적 스킬을 SFT를 통해 먼저 마스터해야 한다는 엄격한 전제조건이 존재한다. 따라서 RL을 단순 증폭기로 보는 기존 시각에 도전하면서, 충분한 원자적 기반 위에 RL을 적용하면 명시적 복합 전략 감독 없이도 복합 추론 전략을 스스로 합성할 수 있음을 보여준다. 이는 복합 추론 과제에 대한 확장 가능한 일반화 경로로서, 원자적 학습 후 RL을 적용하는 접근법의 가능성을 시사한다. 코드와 데이터는 https://github.com/sitaocheng/from‑atomic‑to‑composite 에 공개한다.💡 논문 핵심 해설 (Deep Analysis)
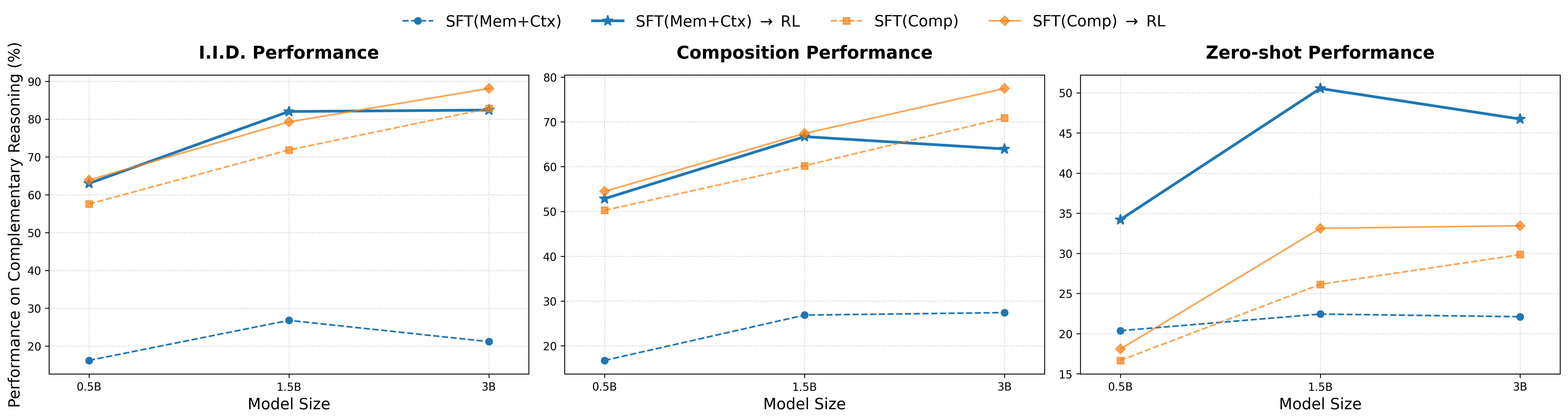
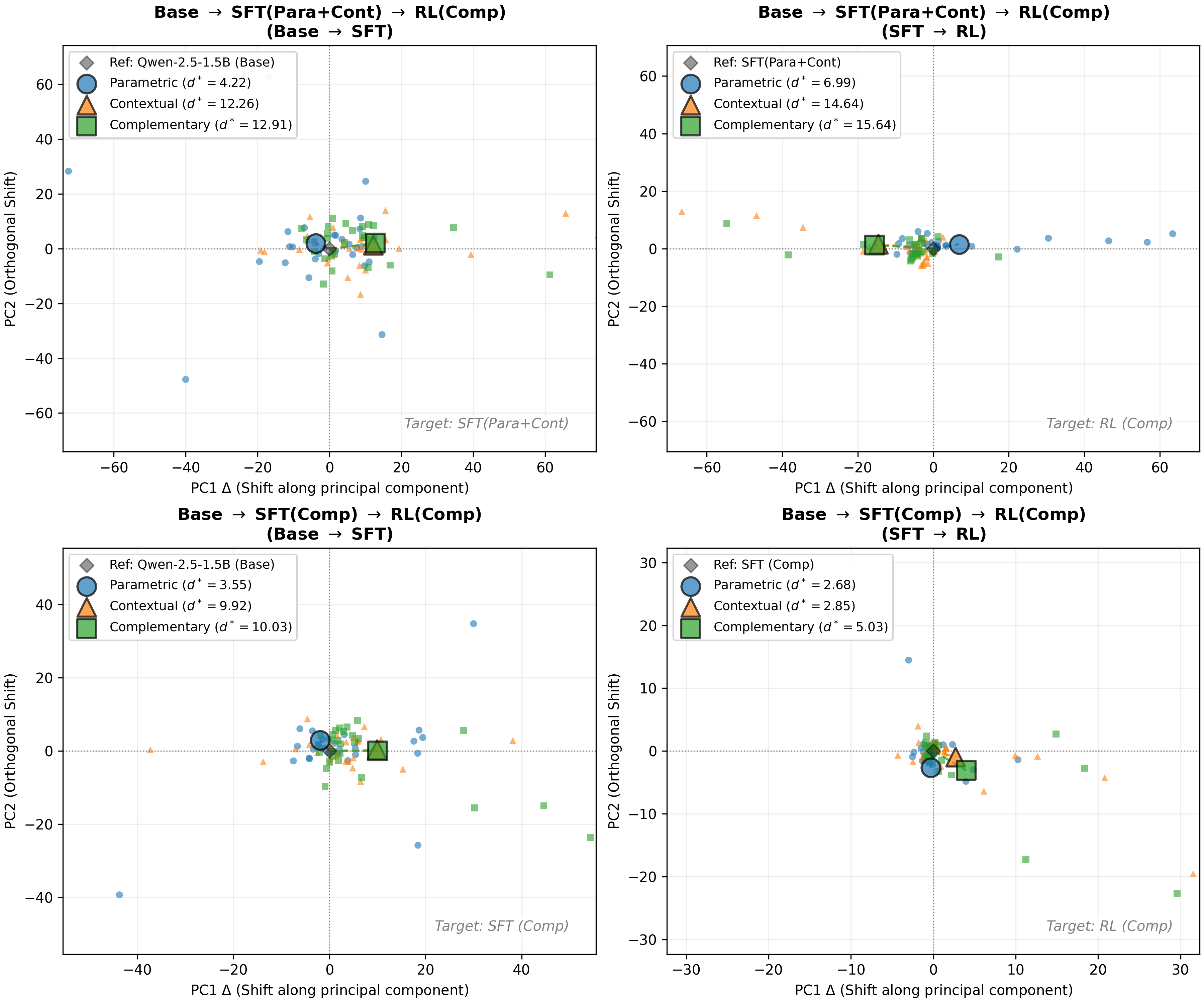
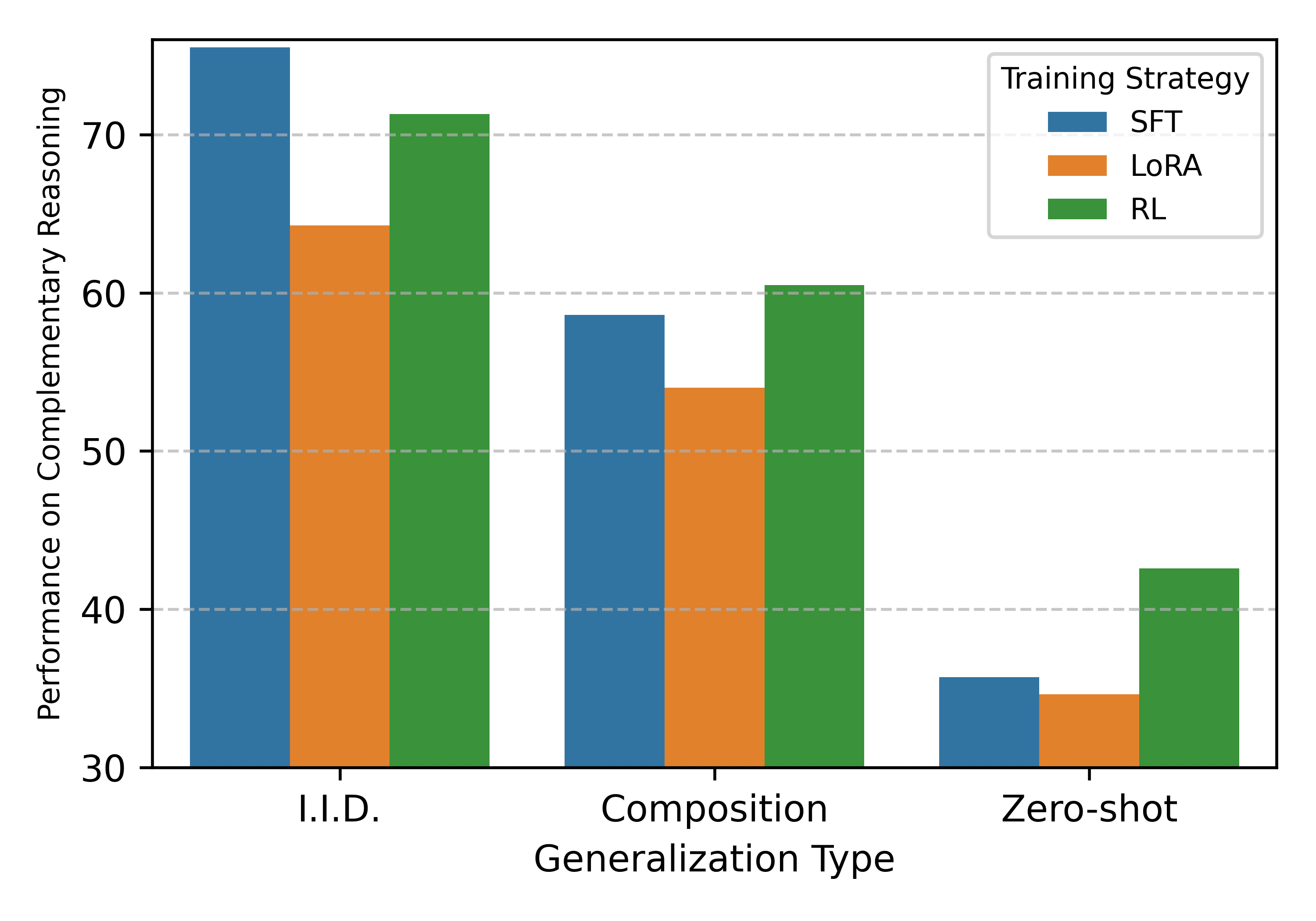
실험은 크게 세 가지 일반화 수준으로 나뉜다. I.I.D.는 훈련과 동일한 분포의 데이터에 대한 성능을 측정하고, Composition은 훈련에선 보지 못한 스킬 조합을 요구하며, Zero‑shot은 완전히 새로운 관계(예: 새로운 인물과 새로운 직업 조합)를 제시한다. 결과는 놀라웠다. SFT만 적용한 모델은 I.I.D.에서는 90%에 달하는 높은 정확도를 보였지만, Composition과 Zero‑shot에서는 각각 35%와 18% 수준으로 급락했다. 특히 ‘SFT 일반화 역설’이라 부른 현상은, 복합 과제에만 감독을 주면 모델이 “정답 경로”를 외우고, 실제 추론 능력은 전혀 향상되지 않았음을 보여준다. 이는 기존 연구에서 “RL이 단순히 확률을 높인다”는 주장에 대한 강력한 반증이다.
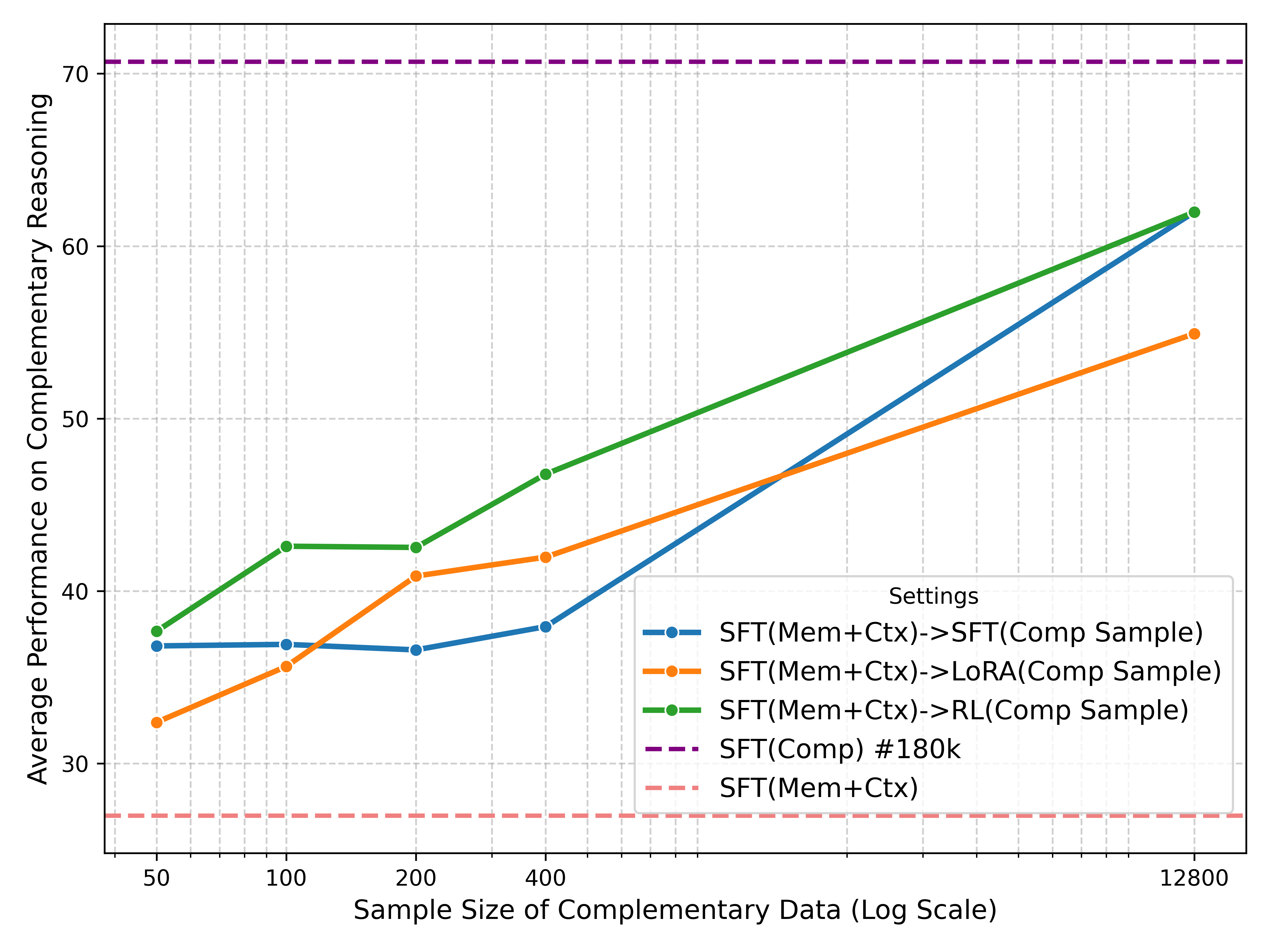
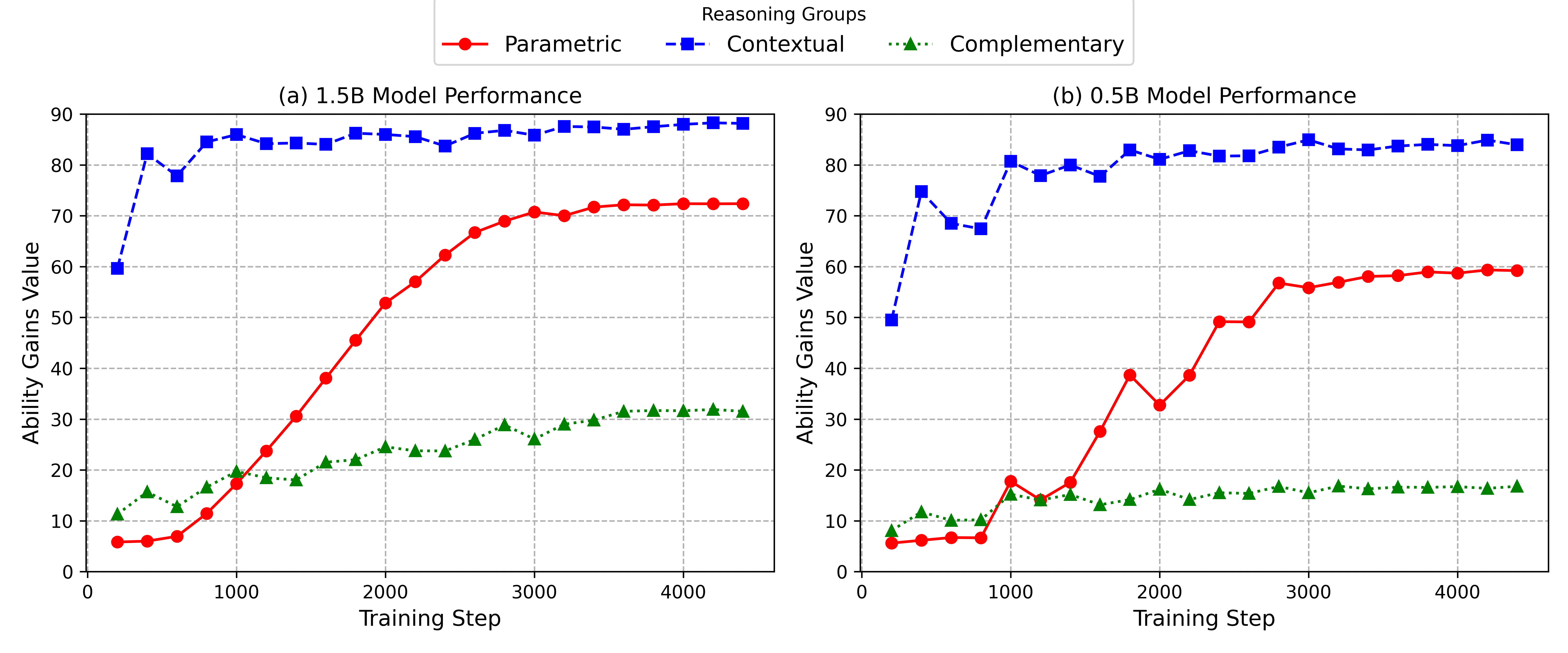
RL 단계에서 저자들은 두 가지 중요한 변수를 조절했다. 첫째, 베이스 모델이 원자적 스킬을 충분히 습득했는지 여부(Parametric + Contextual SFT). 둘째, RL 보상 설계가 복합 목표(두 스킬을 동시에 만족)와 일치하도록 설계했는지 여부다. 실험 결과, 베이스 모델이 원자적 스킬을 마스터하지 않은 경우 RL을 적용해도 성능 향상이 거의 없었다. 반면, 원자적 스킬을 완전히 습득한 모델에 RL을 적용하면, Composition과 Zero‑shot에서 각각 68%와 54%까지 정확도가 크게 상승했다. 이는 RL이 “스킬 합성기” 역할을 수행한다는 강력한 증거다.
또한, 저자들은 RL이 단순히 “확률을 증폭”하는 것이 아니라, 정책 네트워크가 내부 표현을 재구성해 두 원자적 스킬을 효율적으로 연결한다는 메커니즘을 분석했다. 정책 네트워크의 attention map을 시각화한 결과, RL 단계에서 파라메트릭 정보와 컨텍스트 정보를 동시에 참조하는 패턴이 뚜렷이 나타났으며, 이는 SFT 단계에서는 거의 관찰되지 않았다. 즉, RL은 모델이 기존에 학습한 “프리미티브”를 새로운 방식으로 조합하도록 유도한다.
이러한 결과는 두 가지 실용적 시사점을 제공한다. 첫째, 복합 추론 과제를 직접 SFT로 학습시키는 것은 비효율적이며, 오히려 일반화 능력을 저해한다는 점이다. 둘째, 원자적 스킬을 충분히 학습시킨 뒤 RL을 적용하면, 별도 복합 레이블 없이도 모델이 새로운 조합을 스스로 학습할 수 있다. 이는 향후 “멀티모달·멀티스텝·멀티도메인” 복합 작업을 다룰 때, 단계적 학습 파이프라인을 설계하는 데 중요한 가이드라인이 될 것이다.
마지막으로, 코드와 데이터가 공개된 점은 연구 재현성을 높이고, 커뮤니티가 이 프레임워크를 확장해 다른 도메인(예: 과학 논문 요약, 법률 문서 해석 등)에 적용해볼 수 있는 기반을 제공한다. 전체적으로 이 논문은 RL이 LLM의 추론 능력을 어떻게 “합성”하는지를 실험적으로 입증함으로써, RL‑HF에 대한 기존 논쟁에 새로운 방향을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리