다중 에이전트 언어 습득 시뮬레이션을 통한 지식 기반 언어 모델 구축
📝 원문 정보
- Title: A Knowledge-Based Language Model: Deducing Grammatical Knowledge in a Multi-Agent Language Acquisition Simulation
- ArXiv ID: 2512.02195
- 발행일: 2025-12-01
- 저자: David Ph. Shakouri, Crit Cremers, Niels O. Schiller
📝 초록 (Abstract)
본 논문은 MODOMA 시스템을 이용한 초기 연구를 제시한다. MODOMA는 성인 에이전트와 아동 에이전트 두 언어 모델 간의 상호작용을 기반으로 한 비지도 언어 습득 실험을 수행할 수 있는 다중‑에이전트 실험실 환경이다. 통계적 절차와 규칙 기반 절차를 모두 활용하지만, 최종 습득 결과는 지식 기반 언어 모델이며, 이는 목표 언어의 새로운 발화문을 생성·구문 분석하는 데 사용할 수 있다. 시스템은 완전하게 매개변수화되어 있어 연구자는 실험의 모든 측면을 제어할 수 있으며, 습득된 문법 지식은 명시적으로 표현되어 언제든지 조회 가능하다. 따라서 본 시스템은 계산 언어 습득 실험에 새로운 가능성을 제공한다. 논문에 제시된 실험에서는 성인 에이전트가 생성한 훈련·시험 데이터에 포함된 예시 수가 달라짐에 따라, 딸(아동) 에이전트가 기능적 범주와 내용 범주를 성공적으로 습득하고 표현함을 보여준다. 흥미롭게도 인간이 만든 데이터에서 관찰되는 패턴과 유사한 현상이 기계 생성 데이터에서도 나타났다. 이러한 절차를 통해 아동 에이전트가 이산적인 문법 범주를 성공적으로 습득했으며, 이는 MODOMA 접근법이 언어 습득 모델링에 타당함을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
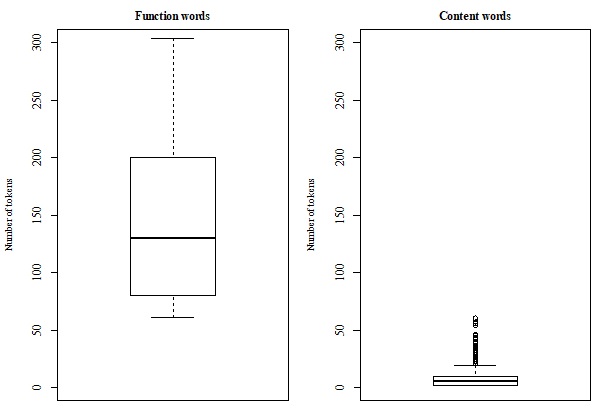
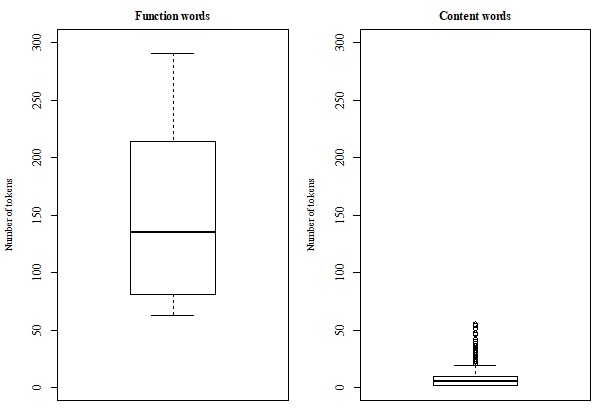
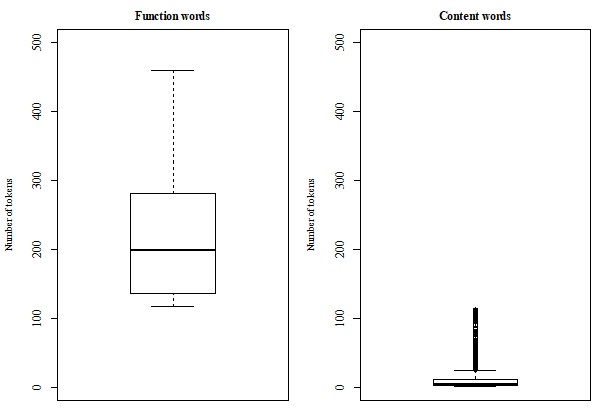
실험 결과는 특히 ‘예시 수’가 변할 때 나타나는 학습 곡선이 인간 아동의 언어 습득 곡선과 유사함을 보여준다. 적은 수의 예시(예: 10~20문)에서는 기능 범주만 부분적으로 형성되고, 예시가 증가함에 따라 내용 범주와 복합 구조가 점진적으로 정교해진다. 이는 ‘입력 양’과 ‘범주 형성’ 사이의 비선형 관계를 시뮬레이션이 재현했다는 의미이며, 기존 연구에서 제시된 ‘임계량(critical mass)’ 가설을 컴퓨터 모델 차원에서 검증한 셈이다.
또한, MODOMA가 생성한 데이터가 인간이 만든 코퍼스와 유사한 통계적 특성을 보였다는 점은, ‘기계‑생성 데이터’가 인간 언어 습득 연구에 유효한 대체 자료가 될 수 있음을 시사한다. 이는 실험 비용과 윤리적 제약을 크게 낮출 수 있는 가능성을 열어준다. 다만 현재 시스템은 ‘성인 에이전트’가 이미 완전한 문법 지식을 가지고 있다는 전제하에 작동한다는 한계가 있다. 향후 연구에서는 성인 에이전트 자체를 학습시키거나, 다중 세대(성인‑청소년‑아동) 모델을 도입해 세대 간 전이 메커니즘을 탐구할 필요가 있다.
요약하면, MODOMA는 언어 습득을 ‘통계‑규칙‑지식’ 삼위일체로 접근함으로써, 실험적 재현성, 결과의 해석 가능성, 그리고 인간 언어학과의 직접적인 비교를 동시에 달성한다. 이는 계산 언어학, 인지 과학, 그리고 교육 기술 분야에서 새로운 연구 패러다임을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리