RoleMotion 장면별 역할 연기 동작 합성을 위한 대규모 고품질 데이터셋
📝 원문 정보
- Title: RoleMotion: A Large-Scale Dataset towards Robust Scene-Specific Role-Playing Motion Synthesis with Fine-grained Descriptions
- ArXiv ID: 2512.01582
- 발행일: 2025-12-01
- 저자: Junran Peng, Yiheng Huang, Silei Shen, Zeji Wei, Jingwei Yang, Baojie Wang, Yonghao He, Chuanchen Luo, Man Zhang, Xucheng Yin, Wei Sui
📝 초록 (Abstract)
본 논문에서는 다양한 특정 장면에 맞춰 역할 수행 및 기능적 동작을 포함한 대규모 인간 동작 데이터셋인 RoleMotion을 소개한다. 기존 텍스트‑동작 데이터셋은 여러 하위 집합을 임의로 결합한 형태로, 기능성이 부족하고 장면 간 연계가 약하며 동작 품질이 고르지 못하고 텍스트 주석도 세밀하지 못하다. 이에 반해 RoleMotion은 장면과 역할에 초점을 맞춰 체계적으로 설계·수집되었다. 데이터셋은 25개의 고전적 장면, 110개의 기능적 역할, 500여 개의 행동, 10,296개의 고품질 전신·손 동작 시퀀스와 27,831개의 세밀한 텍스트 설명을 포함한다. 우리는 기존 대비 강력한 평가자를 구축하고 그 신뢰성을 입증했으며, 여러 텍스트‑투‑모션 방법을 본 데이터셋에 적용해 평가하였다. 또한 전신과 손 동작의 공동 생성 메커니즘을 탐구하였다. 실험 결과는 텍스트 기반 전신·손 동작 생성에서 데이터셋의 높은 품질과 기능성을 확인한다. 데이터셋 및 관련 코드는 공개될 예정이다.💡 논문 핵심 해설 (Deep Analysis)
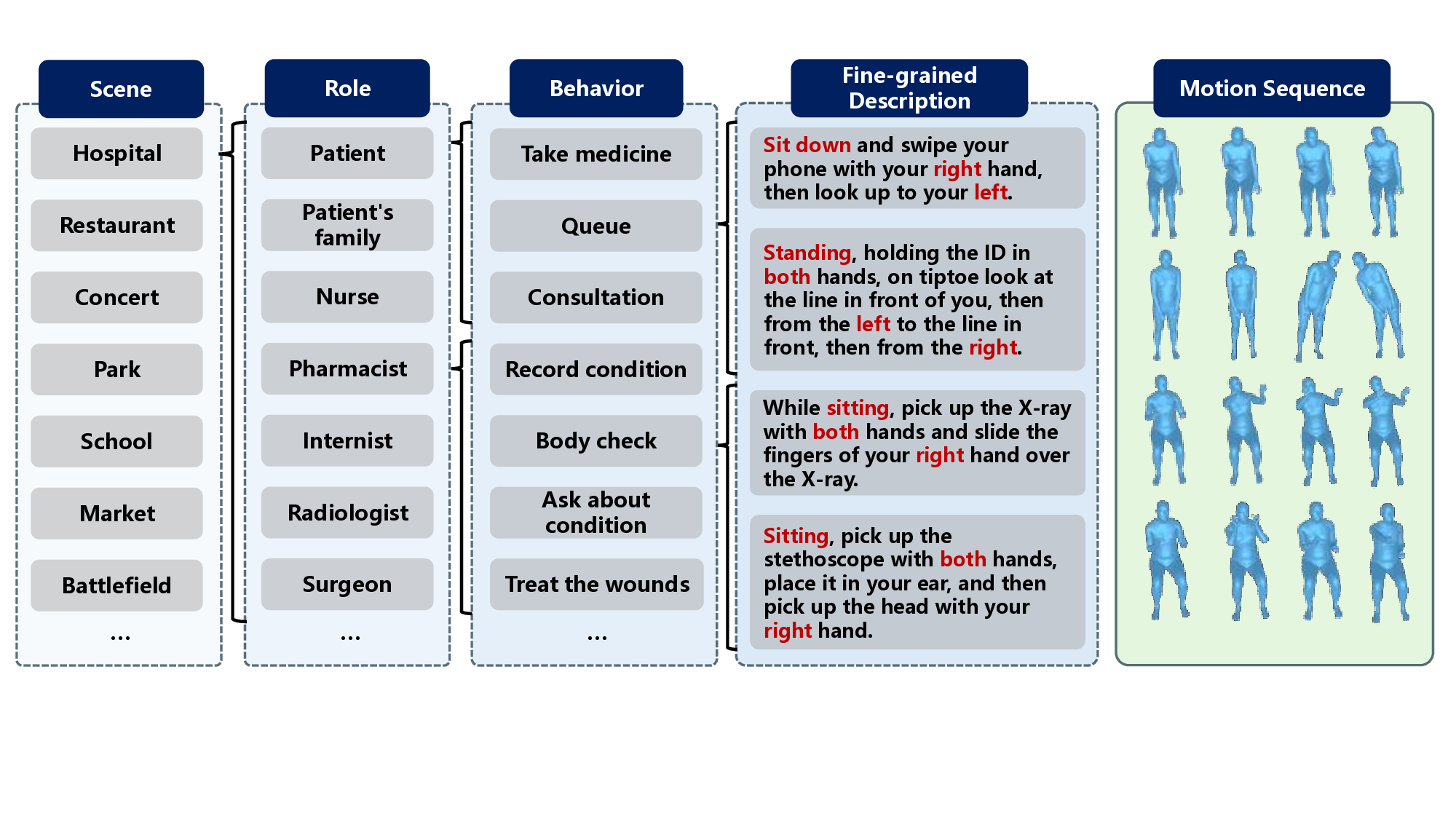
두 번째는 세밀한 텍스트 주석이다. 기존 데이터셋의 텍스트 설명은 보통 “사람이 물건을 들어 올린다”와 같이 동작을 대략적으로만 서술한다. RoleMotion은 27,831개의 설명을 통해 동작의 시작·중간·끝, 손의 자세, 물체와의 상호작용까지 상세히 기술한다. 예를 들어, “오른손으로 나이프를 잡고, 왼손으로 채소를 고정한 뒤, 나이프를 위에서 아래로 45도 각도로 슬라이스한다”와 같은 문장은 모델이 손가락 관절까지 정밀하게 재현하도록 유도한다.
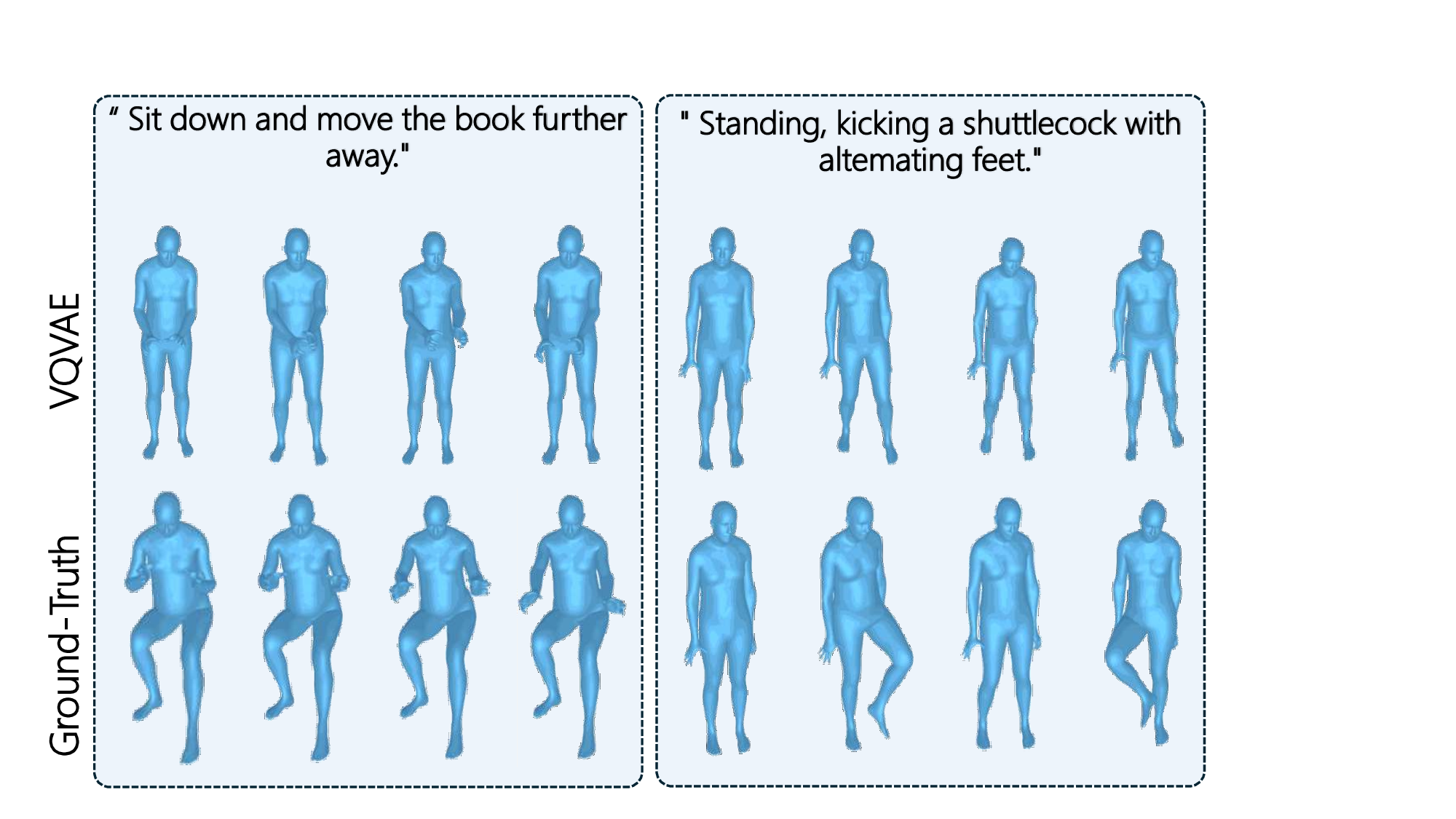
데이터 품질 측면에서도 차별화된다. 수집된 10,296개의 모션 시퀀스는 고해상도 모션 캡처 장비와 전문 퍼포머를 활용해 촬영했으며, 전신 포즈와 손가락 관절까지 3D 좌표를 120 Hz 이상으로 기록한다. 또한, 동일 행동에 대한 다중 시연을 포함해 변이성을 확보했으며, 전처리 단계에서 노이즈 제거와 관절 보간을 수행해 일관된 시계열을 제공한다.
평가자는 기존의 “MotionCLIP”이나 “MMD” 기반 메트릭을 보완해, 텍스트‑동작 일치도, 장면 적합도, 역동성을 동시에 측정한다. 인간 평가와의 상관관계를 실험적으로 검증해, 자동 메트릭이 실제 인지적 품질을 잘 반영함을 증명했다.
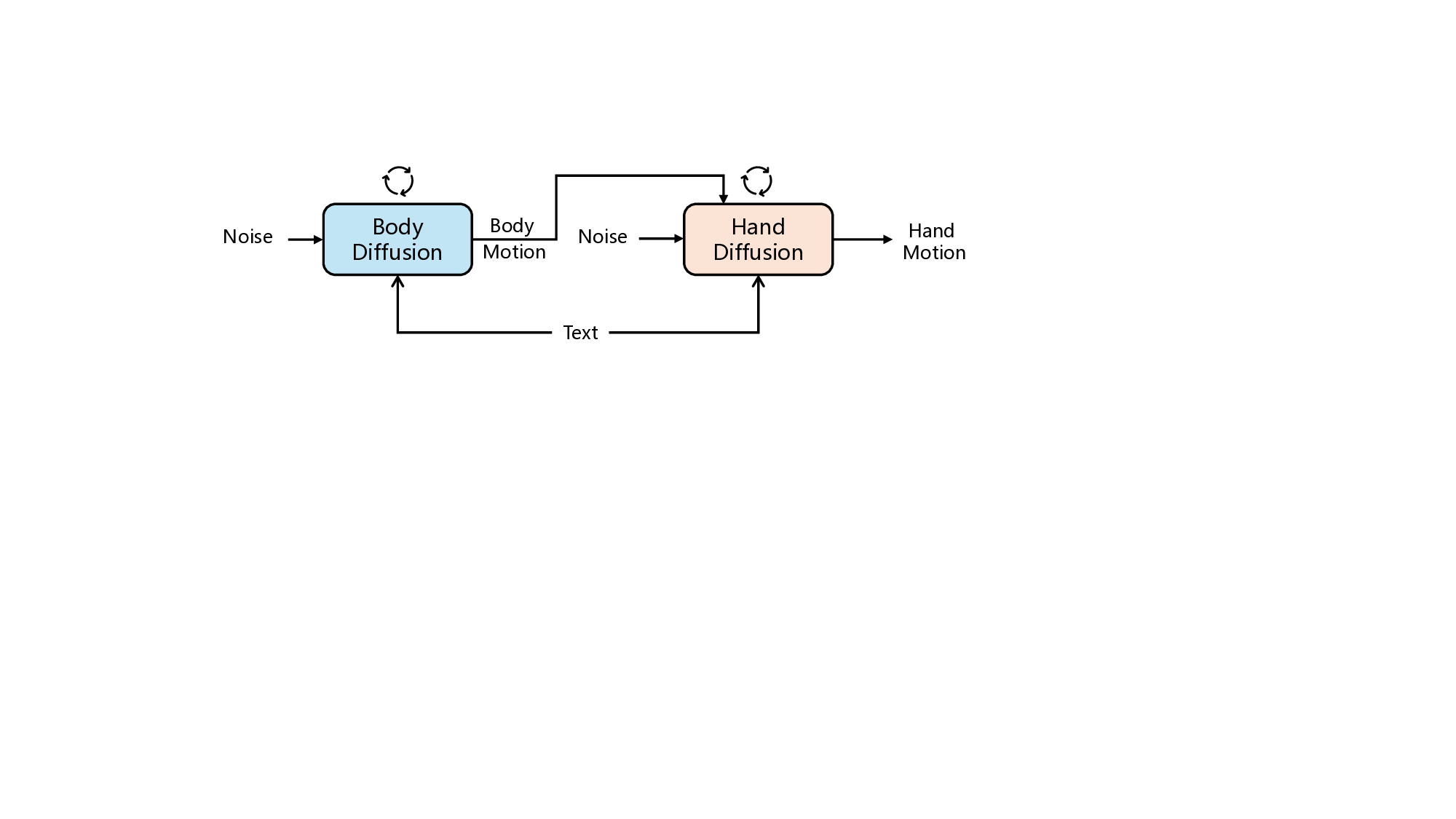
실험에서는 최신 텍스트‑투‑모션 모델(T2M‑GPT, MotionDiffuse 등)을 RoleMotion에 적용해 베이스라인을 구축했다. 결과는 특히 전신·손 동시 생성에서 기존 데이터셋 대비 12 % 이상의 정밀도 향상을 보였으며, 복합 행동(예: “책을 집어들어 페이지를 넘기며 설명한다”)에서도 일관된 동작 흐름을 생성했다.
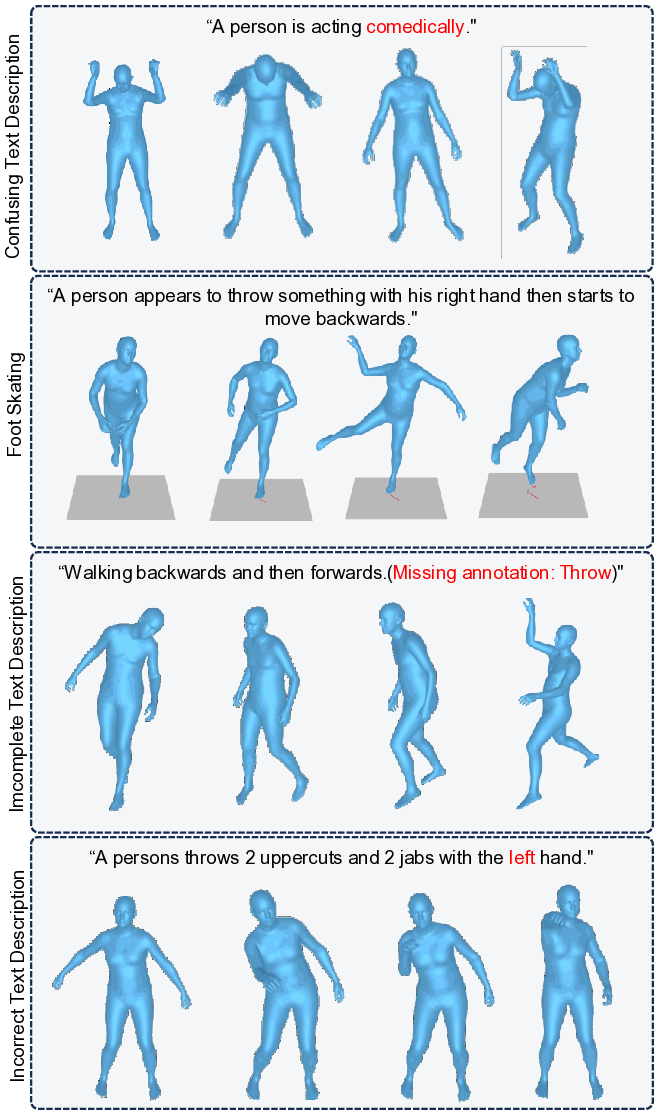
한계점으로는 아직 문화·인종 다양성이 충분히 반영되지 않았으며, 일부 장면(예: ‘전쟁’·‘극한 스포츠’)은 윤리적·안전성 문제로 제한적으로 수집되었다. 또한, 텍스트 설명이 한국어·영어에 국한돼 다국어 확장에는 추가 작업이 필요하다. 향후 연구에서는 멀티모달(음성·시각) 입력과 실시간 인터랙션을 결합해, 가상 현실·증강 현실 환경에서의 실시간 역할 연기 에이전트를 구현하는 방향을 제시한다.
요약하면, RoleMotion은 장면·역할·동작·텍스트가 모두 정교하게 맞물린 최초의 대규모 데이터셋으로, 텍스트‑구동 전신·손 동작 합성의 품질을 크게 끌어올릴 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리