제로오버헤드 인트로스펙션으로 비용과 보상을 동시에 예측하는 ZIPRC
📝 원문 정보
- Title: Zero-Overhead Introspection for Adaptive Test-Time Compute
- ArXiv ID: 2512.01457
- 발행일: 2025-12-01
- 저자: Rohin Manvi, Joey Hong, Tim Seyde, Maxime Labonne, Mathias Lechner, Sergey Levine
📝 초록 (Abstract)
대형 언어 모델은 추론 능력이 뛰어나지만, 성공을 예측하고 이를 달성하기 위해 필요한 계산량을 사전에 파악하는 등 자기 성찰 능력이 부족합니다. 인간은 실시간 자기 성찰을 통해 노력 투입량, 여러 번 시도할 시점, 중단 시점, 성공·실패 신호를 결정합니다. 이러한 능력이 없으면 LLM은 지능적인 메타인지 결정을 내리기 어렵습니다. 고정된 샘플 예산을 사용해 비용과 지연 시간을 증가시키는 Best‑of‑N과 같은 테스트‑타임 스케일링 방법은 각 단계에서의 한계 이득을 고려하지 않으며, 신뢰도 신호가 없으면 사용자를 오도하고 더 나은 도구로의 전환을 방해해 신뢰성을 저해합니다. 학습된 검증자나 보상 모델은 신뢰도 추정치를 제공하지만, 별도 모델이나 추가 전방 패스를 필요로 하여 적응형 추론을 가능하게 하지 못하고 추론 비용을 크게 늘립니다. 우리는 ZIP‑RC를 제안합니다. ZIP‑RC는 모델이 토큰을 생성하는 매 순간, 사용되지 않은 로짓을 재활용해 최종 보상과 남은 길이에 대한 공동 분포를 출력합니다—추가 모델, 아키텍처 변경, 혹은 추론 오버헤드 없이 가능합니다. 이 공동 분포를 이용해 기대 최대 보상, 전체 계산량, 그리고 완전 생성 시 지연 시간을 선형 결합한 샘플링 유틸리티를 계산합니다. 추론 단계에서는 이 유틸리티를 최대화하는 메타‑액션을 선택해 어느 접두어까지 계속 생성할지 혹은 새로운 샘플을 시작할지를 결정합니다. 혼합 난이도 수학 벤치마크에서 ZIP‑RC는 동일하거나 낮은 평균 비용으로 다수결 투표 대비 정확도를 최대 12% 향상시키며, 품질·계산·지연 사이의 부드러운 파레토 프론티어를 형성합니다. 실시간 보상‑비용 자기 성찰을 제공함으로써 ZIP‑RC는 모델이 보다 효율적이고 적응적으로 추론하도록 합니다.💡 논문 핵심 해설 (Deep Analysis)
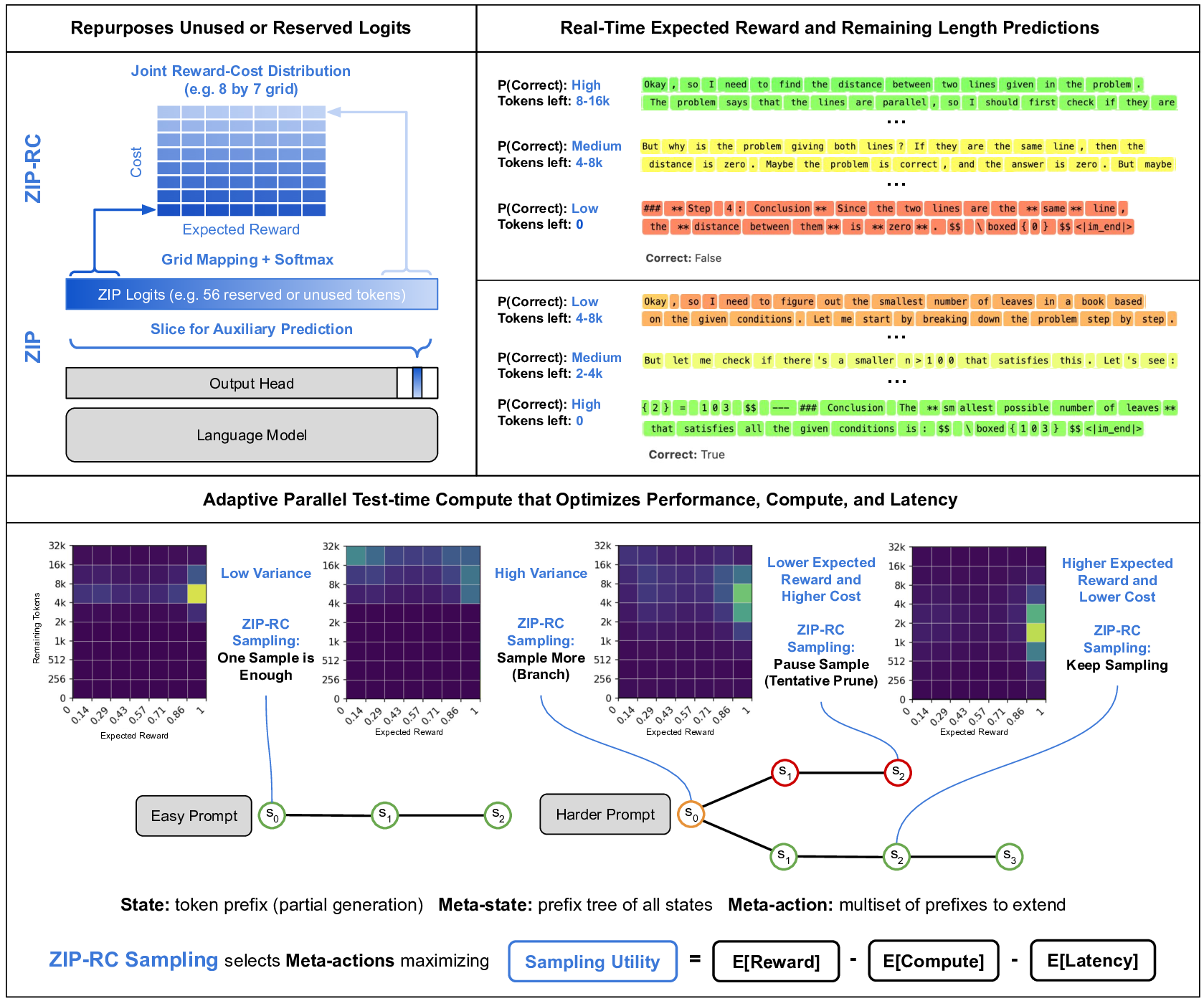
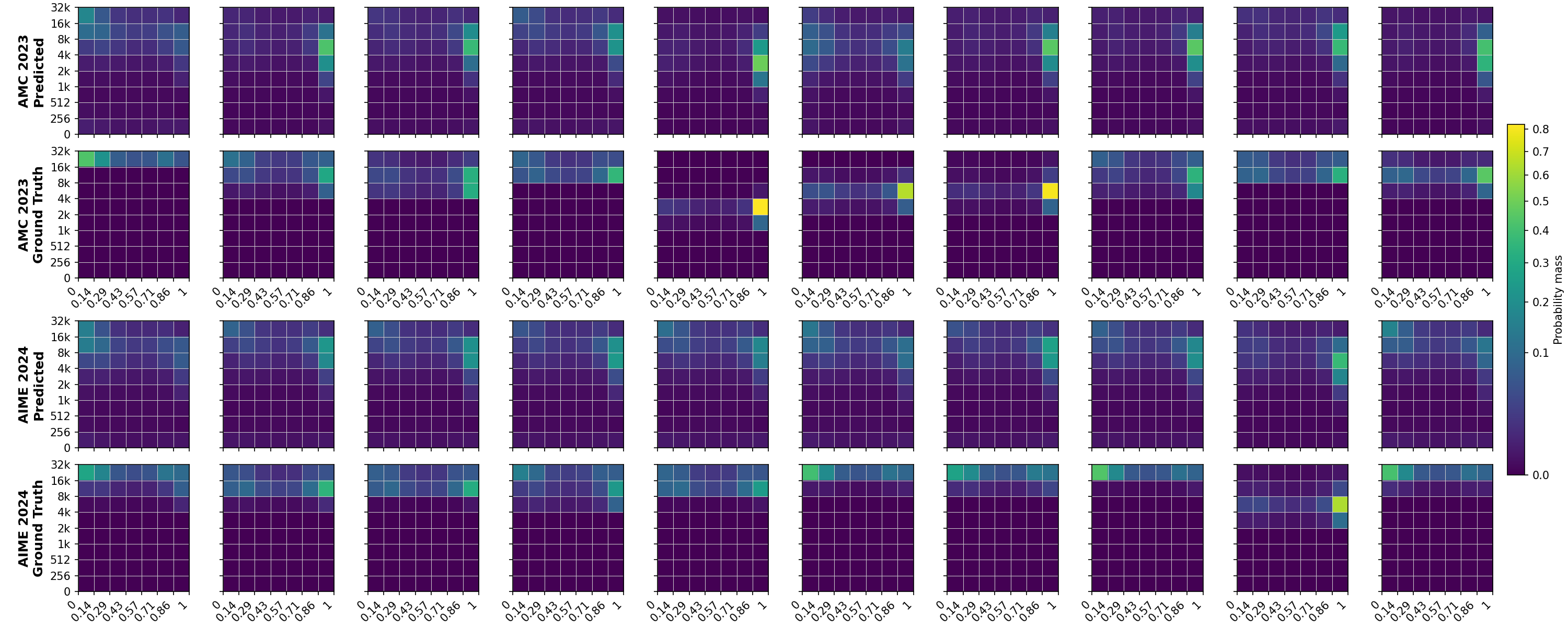
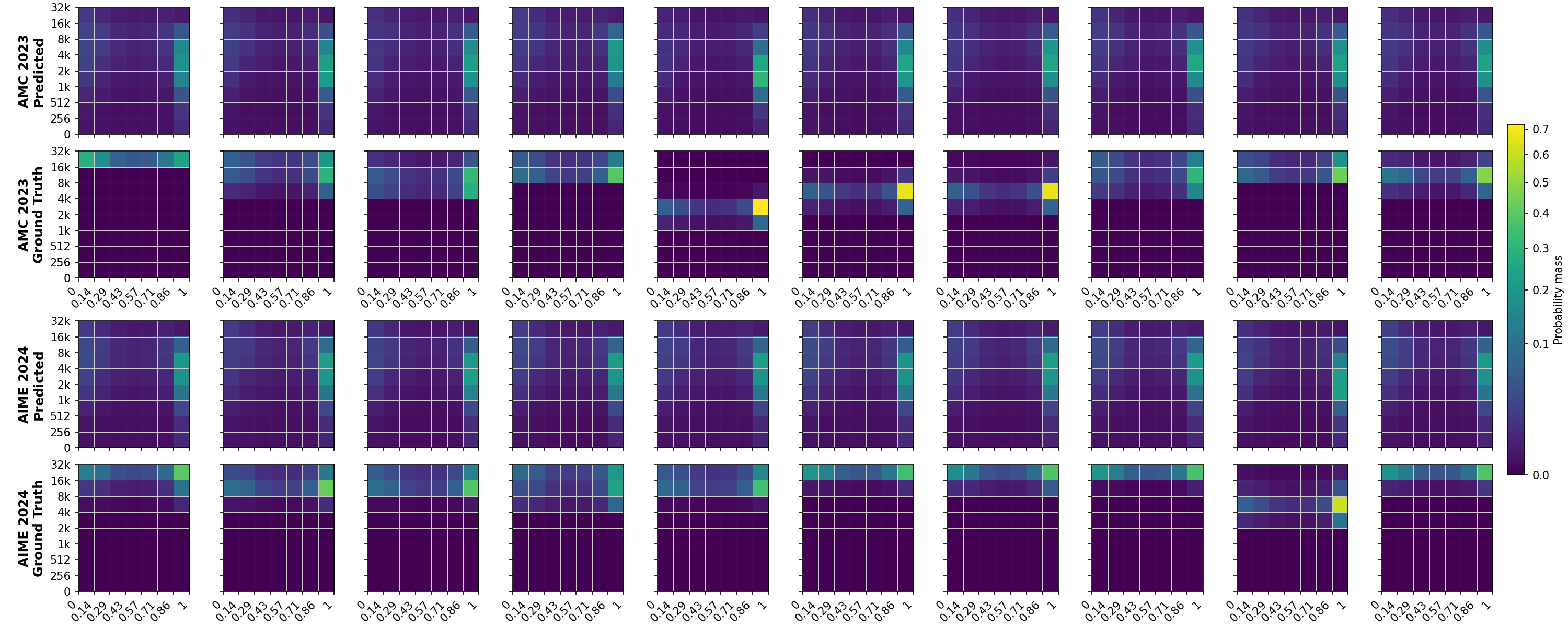
이에 대한 대안으로 학습된 검증자나 보상 모델을 별도로 두는 접근법이 있었지만, 이는 두 번째 모델을 추가로 실행해야 하므로 추론 비용이 배가되고, 파이프라인이 복잡해진다. ZIP‑RC는 이러한 단점을 근본적으로 해소한다. 핵심 아이디어는 “예약된 로짓(reserved logits)”을 활용한다는 점이다. LLM이 다음 토큰을 예측하기 위해 수행한 전방 패스에서, 사용되지 않은 로짓 공간을 재활용해 보상과 남은 토큰 수에 대한 확률 분포를 동시에 추정한다. 즉, 하나의 전방 패스가 두 가지 정보를 제공하므로, 추가 연산 없이도 “이 토큰 이후에 얻을 기대 보상은 얼마인가?”, “남은 길이는 얼마나 될 것인가?”를 실시간으로 알 수 있다.
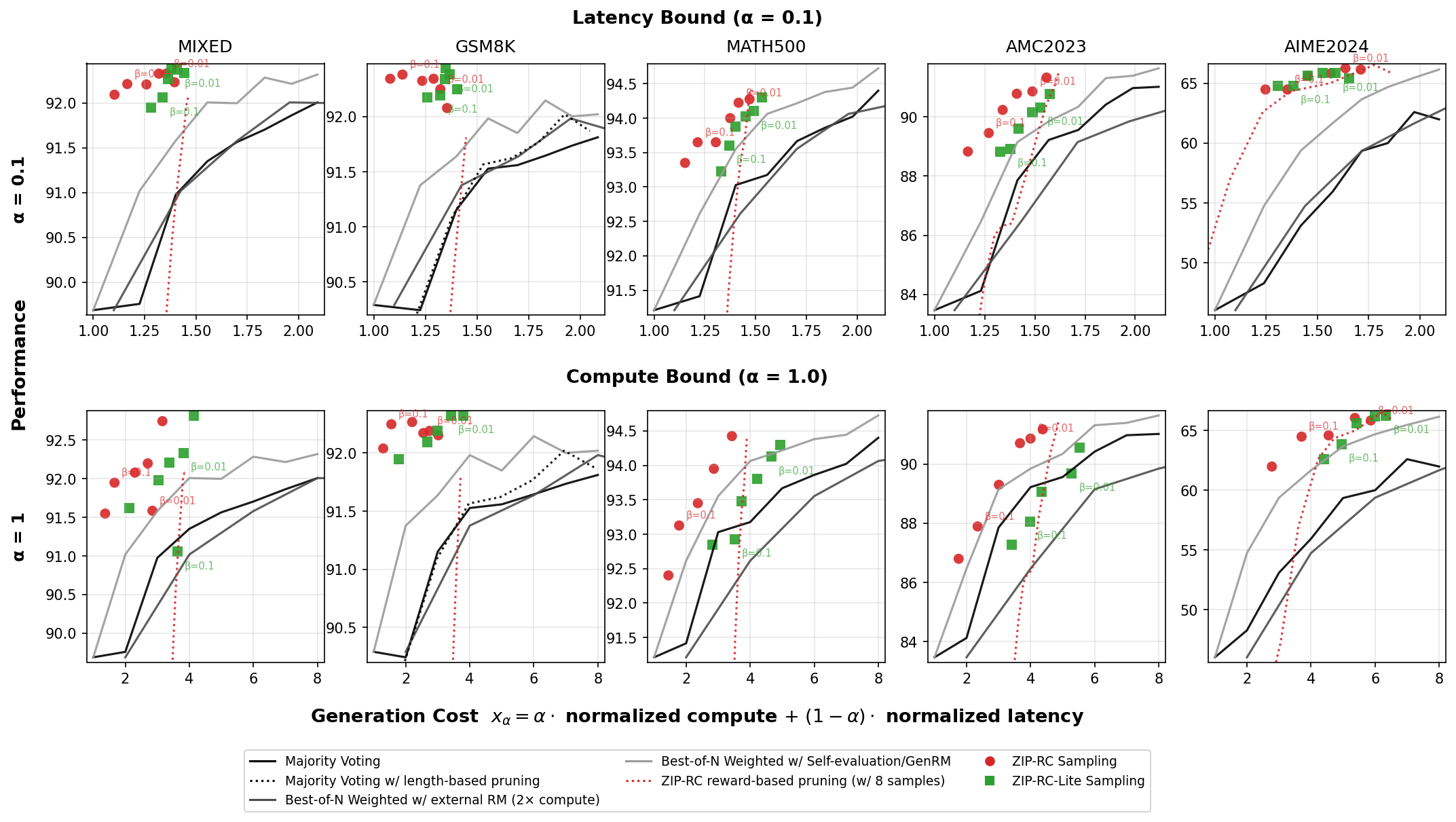
이 공동 분포를 바탕으로 논문은 ‘샘플링 유틸리티’를 정의한다. 유틸리티는 (1) 기대 최대 보상, (2) 전체 계산량(Compute), (3) 완전 생성 시 지연(Latency)의 선형 결합으로, 사용자는 각 요소에 가중치를 부여해 자신의 서비스 요구에 맞게 조정한다. 메타‑액션은 현재까지 생성된 접두어를 유지하면서 추가 토큰을 생성할지, 혹은 새로운 후보 샘플을 시작할지를 결정한다. 이 과정은 강화학습이나 베이즈 최적화와 유사한 탐색‑활용 트레이드오프를 실시간으로 수행한다는 점에서 혁신적이다.
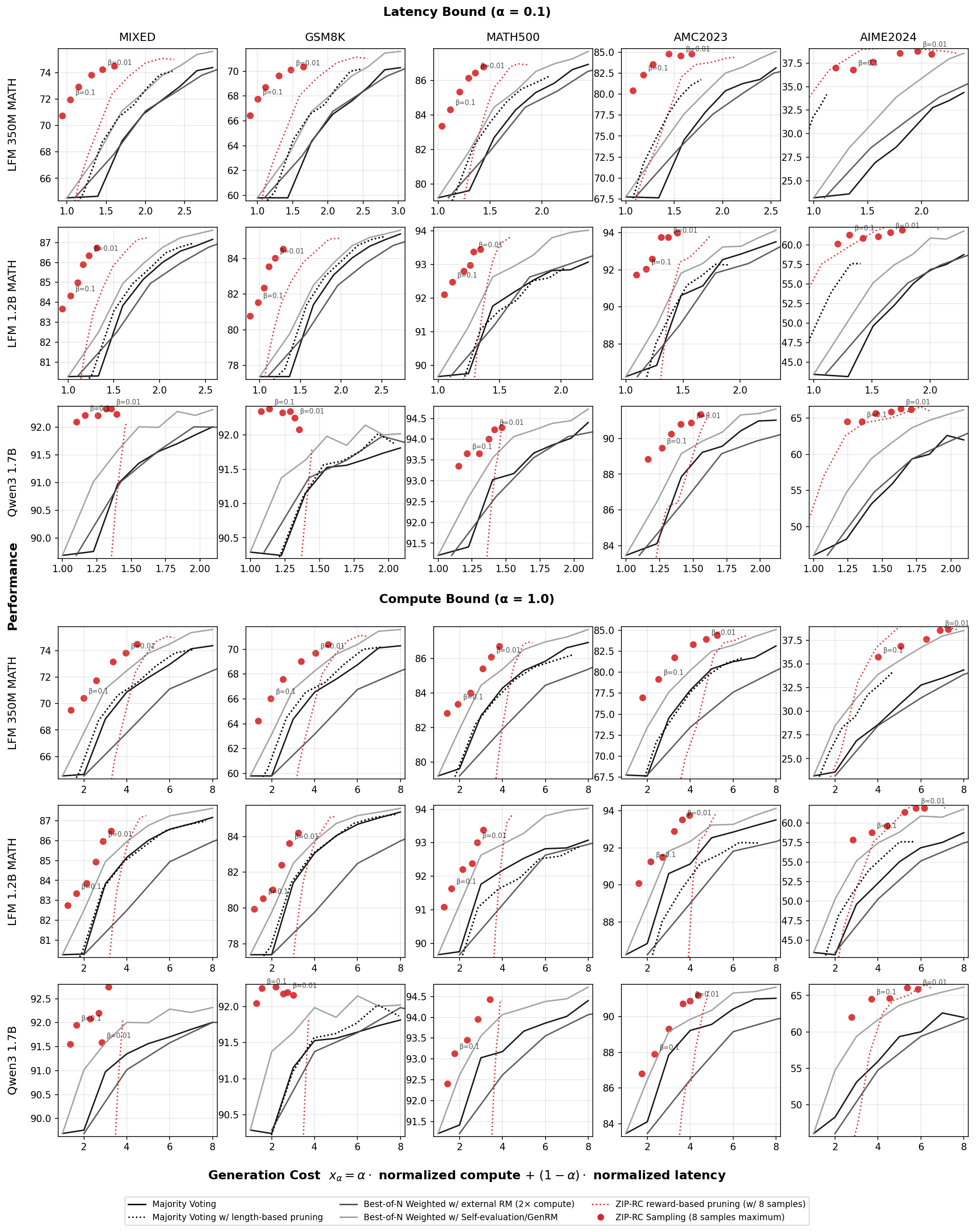
실험에서는 혼합 난이도 수학 문제(MATH, GSM8K 등)에서 ZIP‑RC가 동일하거나 더 낮은 평균 비용으로 다수결 투표(majority voting) 대비 정확도를 최대 12% 향상시켰다. 특히, 비용‑품질 파레토 곡선이 부드럽게 이어지는 것을 확인했는데, 이는 모델이 “이 정도면 충분히 좋은 답을 얻었다”는 판단을 스스로 내릴 수 있음을 의미한다. 이러한 특성은 실시간 서비스에서 비용을 제한하면서도 신뢰할 수 있는 결과를 제공해야 하는 상황에 매우 유용하다.
한계점으로는 현재 구현이 토큰‑레벨 로짓 재활용에 의존하기 때문에, 비트레인(비트레인) 구조나 디코더‑전용 모델에서는 적용이 어려울 수 있다. 또한, 보상 분포를 정확히 추정하기 위해서는 사전에 충분한 보상 라벨링이 필요하며, 라벨 품질에 따라 메타‑액션의 효율성이 크게 좌우될 가능성이 있다. 향후 연구에서는 다양한 모델 아키텍처에 대한 일반화, 보상 라벨링 자동화, 그리고 다중 모달(텍스트·이미지·음성) 상황에서의 확장성을 탐색할 여지가 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리