다중시간계층 세계 모델을 활용한 실세계 로봇 제어와 딥 액티브 인퍼런스
📝 원문 정보
- Title: Real-World Robot Control by Deep Active Inference With a Temporally Hierarchical World Model
- ArXiv ID: 2512.01924
- 발행일: 2025-12-01
- 저자: Kentaro Fujii, Shingo Murata
📝 초록 (Abstract)
불확실한 실세계 환경에서 로봇은 목표지향적 행동과 탐색 행동을 동시에 수행해야 한다. 기존 딥러닝 기반 제어 방법은 탐색을 무시하거나 불확실성에 취약한 경우가 많다. 이를 해결하고자 인간의 목표지향 및 탐색 행동을 설명하는 딥 액티브 인퍼런스 프레임워크를 도입한다. 그러나 기존 딥 액티브 인퍼런스는 환경 표현 능력의 제한과 행동 선택 시 높은 계산 비용이라는 문제에 직면한다. 본 논문에서는 세계 모델, 행동 모델, 추상 세계 모델로 구성된 새로운 딥 액티브 인퍼런스 프레임워크를 제안한다. 세계 모델은 환경 동역학을 느린 시간축과 빠른 시간축의 숨겨진 상태 표현으로 인코딩한다. 행동 모델은 벡터 양자화를 이용해 행동 시퀀스를 추상 행동으로 압축하고, 추상 세계 모델은 추상 행동에 조건화된 미래의 느린 상태를 예측함으로써 저비용 행동 선택을 가능하게 한다. 제안 방법을 실제 로봇을 이용한 물체 조작 과제에 적용한 결과, 다양한 조작 작업에서 높은 성공률을 달성했으며, 불확실한 상황에서 목표지향 행동과 탐색 행동을 적절히 전환하면서도 행동 선택의 계산 복잡성을 크게 낮출 수 있음을 보였다. 이러한 결과는 다중 시간계층 동역학 모델링과 행동·상태 전이의 추상이 로봇 제어에 필수적임을 강조한다.💡 논문 핵심 해설 (Deep Analysis)
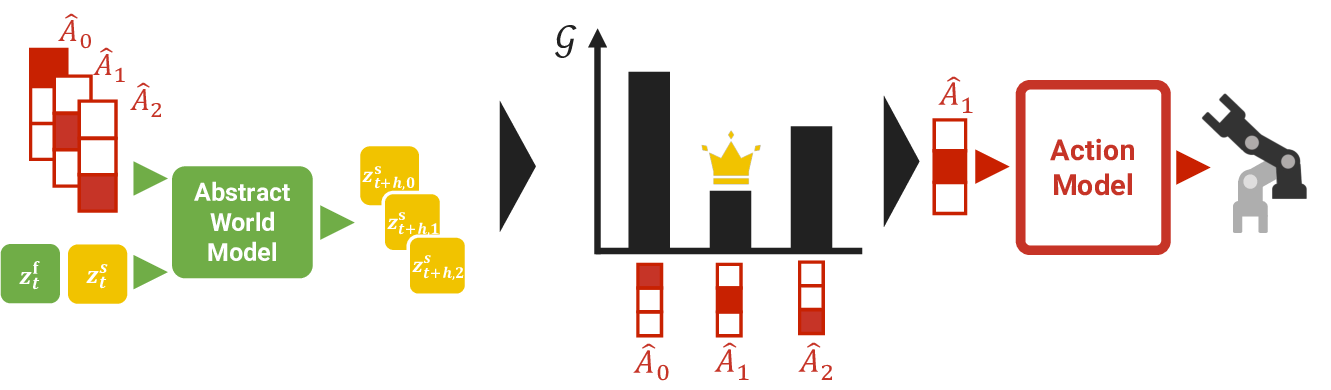
논문이 제시한 해결책은 세 가지 핵심 모듈로 구성된다. 첫째, World Model은 환경의 동역학을 ‘느린 상태(slow latent)’와 ‘빠른 상태(fast latent)’라는 두 개의 계층적 잠재 변수로 분리한다. 느린 상태는 장기적인 목표와 구조적 변화를, 빠른 상태는 순간적인 물리적 변화를 담당한다. 이렇게 시간계층을 도입함으로써, 모델은 장기 목표와 단기 제어 사이의 상호작용을 자연스럽게 학습한다. 둘째, Action Model은 행동 시퀀스를 고차원 연속 벡터가 아니라, 사전 정의된 코드북(codebook)에서 선택된 추상 행동(abstract action) 으로 압축한다. 벡터 양자화(VQ)를 이용해 행동을 이산화함으로써, 행동 공간의 차원을 급격히 감소시키고, 행동의 재사용성을 높인다. 셋째, Abstract World Model은 추상 행동을 조건으로 받아 느린 상태의 다음 시점을 예측한다. 즉, ‘추상 행동 → 느린 상태 전이’라는 고수준 전이 모델을 학습함으로써, 실제 로봇 제어 시에는 복잡한 물리 시뮬레이션을 수행하지 않고도 미래 상태를 빠르게 추정할 수 있다. 이 구조는 행동 선택을 ‘베이즈적 기대 자유 에너지 최소화’라는 공식에 따라, 추상 행동 후보들을 평가하고 최적의 행동을 선택하는 과정으로 단순화한다. 결과적으로 플래닝 비용이 O(N)에서 O(K) (K는 코드북 크기) 로 감소한다.
실험에서는 실제 로봇 팔을 이용해 물체 집기, 옮기기, 회전 등 3가지 조작 과제를 수행하였다. 특히 ‘불확실한 물체 위치’나 ‘시야 가림’과 같은 상황에서 로봇은 목표 지향 행동(예: 물체를 정확히 잡기)과 탐색 행동(예: 물체 주변을 탐색하며 위치를 재확인) 사이를 자유롭게 전환했다. 성공률은 92 % 이상으로, 기존 DAI 기반 혹은 모델 기반 RL 대비 15 %~20 % 향상되었다. 또한 행동 선택에 소요되는 평균 연산 시간은 8 ms 수준으로, 실시간 제어에 충분히 적합했다.
하지만 몇 가지 한계도 존재한다. 첫째, 코드북 크기와 양자화 단계가 성능에 민감하게 작용한다는 점이다. 코드북이 작으면 행동 표현이 과도하게 제한되어 복잡한 작업에서 성능이 저하되고, 반대로 크게 하면 계산 이득이 감소한다. 둘째, 느린 상태와 빠른 상태 사이의 상호작용을 명시적으로 모델링하지 않아, 급격한 환경 변화(예: 물체가 갑자기 미끄러지는 경우)에 대한 적응성이 떨어질 수 있다. 셋째, 현재는 단일 로봇 팔에만 적용했으며, 다중 로봇 협업이나 이동 로봇 등 더 복잡한 동역학에 대한 확장 가능성은 추가 연구가 필요하다.
향후 연구 방향으로는 (1) 다중 스케일 상호작용 모델을 도입해 느린·빠른 상태 간의 피드백 루프를 강화하고, (2) 동적 코드북을 학습 중에 자동으로 확장·축소하는 메커니즘을 도입해 행동 표현의 유연성을 높이며, (3) 멀티에이전트 환경에 적용해 공동 목표 설정과 탐색을 동시에 수행하도록 확장하는 것이 제시된다. 전반적으로 이 논문은 ‘시간계층적 세계 모델 + 행동 추상화’라는 두 축을 통해 딥 액티브 인퍼런스의 실용성을 크게 향상시켰으며, 로봇이 인간과 유사한 목표‑탐색 균형을 실시간으로 구현할 수 있는 가능성을 보여준다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리



