경량형 대형 언어 모델을 활용한 금융 텍스트 감성 분류 최적화
📝 원문 정보
- Title: Fine-tuning of lightweight large language models for sentiment classification on heterogeneous financial textual data
- ArXiv ID: 2512.00946
- 발행일: 2025-11-30
- 저자: Alvaro Paredes Amorin, Andre Python, Christoph Weisser
📝 초록 (Abstract)
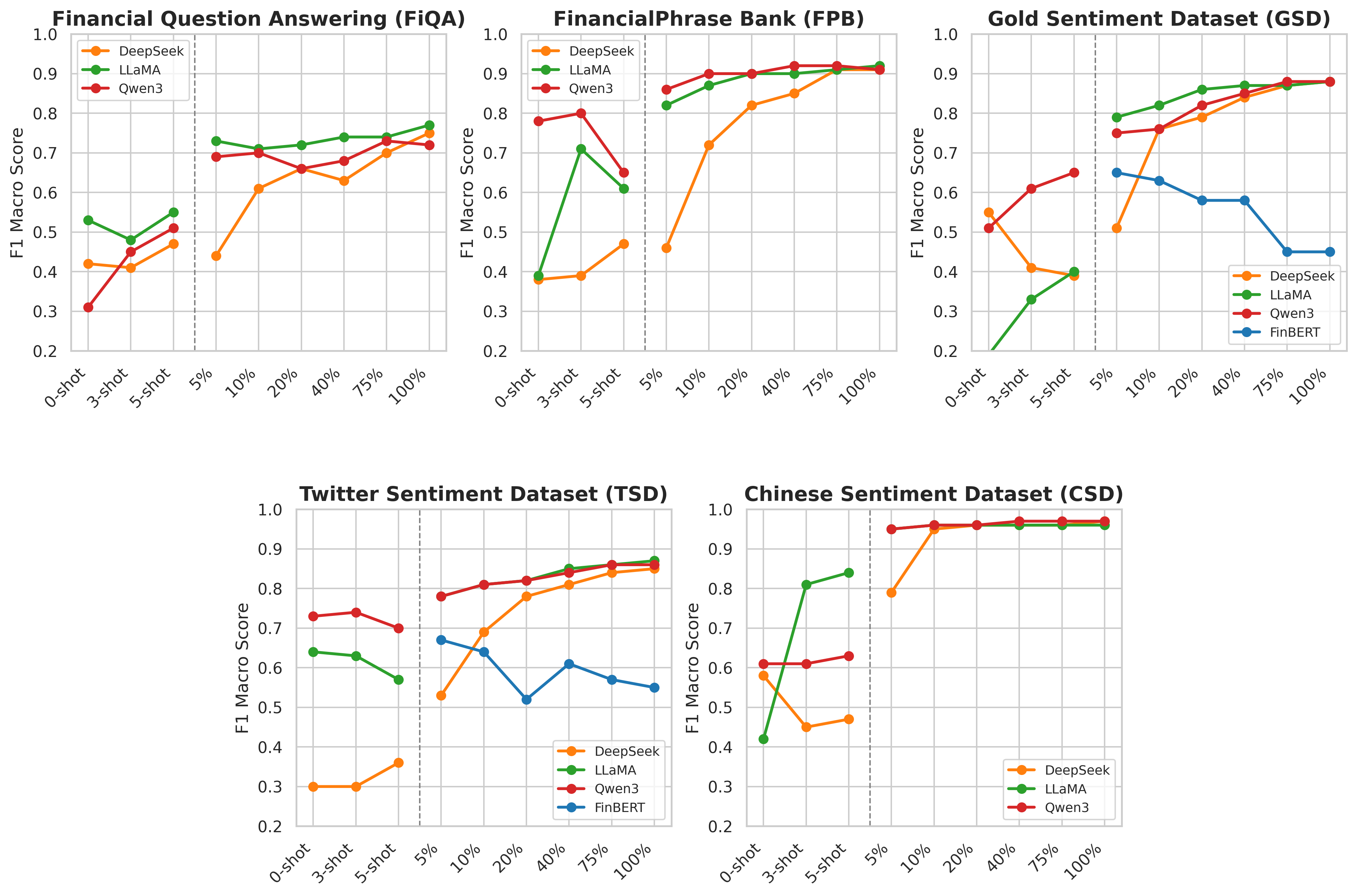
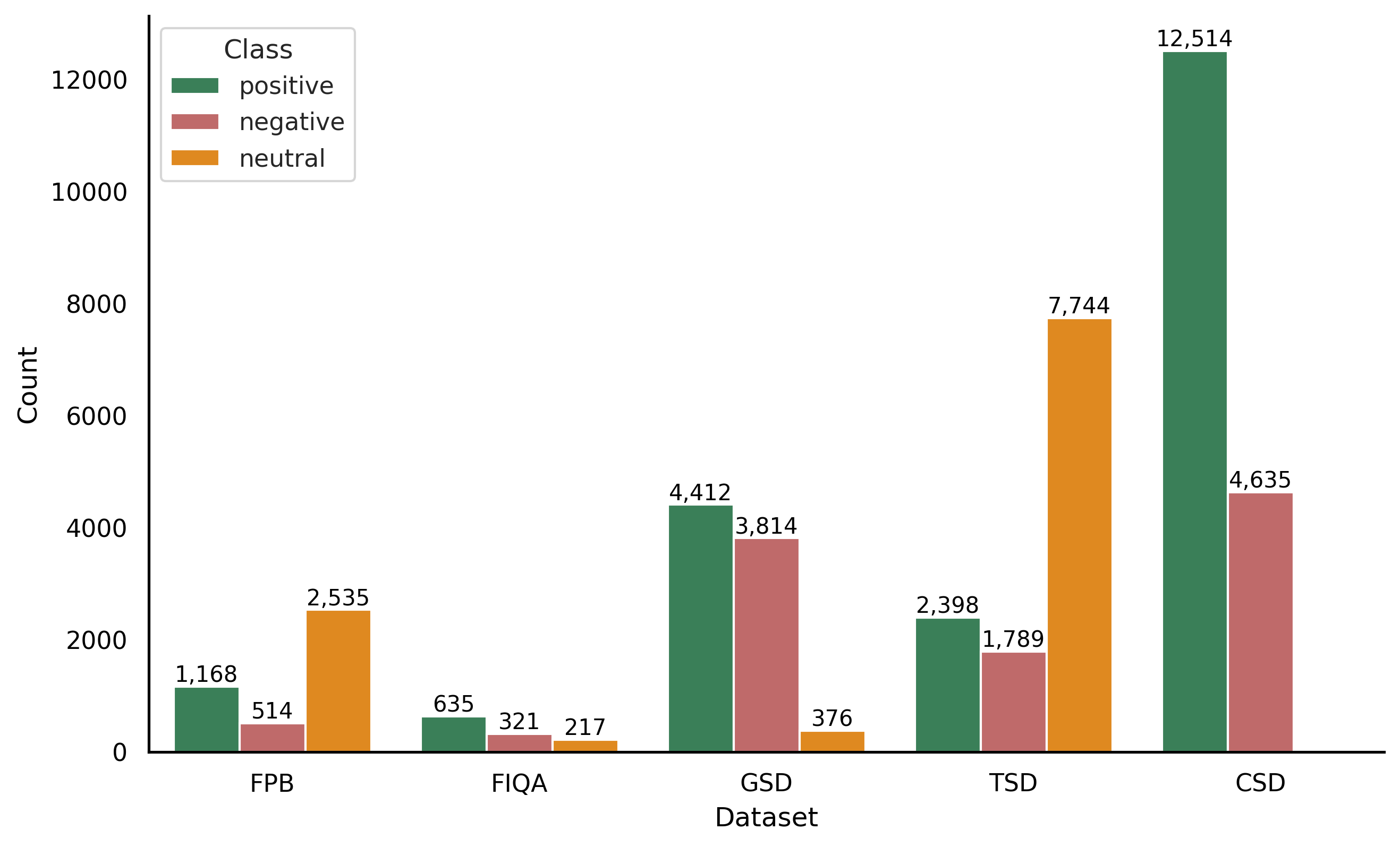
대형 언어 모델(LLM)은 트위터, 뉴스, 보고서 등 다양한 금융 텍스트에서 신호를 포착하는 데 중요한 역할을 하지만, 높은 연산 비용과 제한된 데이터로 인해 접근성이 낮다. 본 연구는 공개된 경량형 LLM인 DeepSeek‑LLM 7B, Llama‑3 8B Instruct, Qwen‑3 8B를 기존 금융 NLP 베이스라인인 FinBERT와 비교하여, 규모·출처·형식·언어가 다른 다섯 개 공개 데이터셋(FinancialPhraseBank, Financial Question Answering, Gold News Sentiment, Twitter Sentiment, Chinese Finance Sentiment)에서 감성 분류 성능을 평가한다. 5 %의 학습 데이터만 사용한 경우에도 Qwen‑3 8B와 Llama‑3 8B가 대부분의 상황에서 최고 성능을 보였으며, 이는 제로샷·few‑shot 설정에서도 동일했다.💡 논문 핵심 해설 (Deep Analysis)
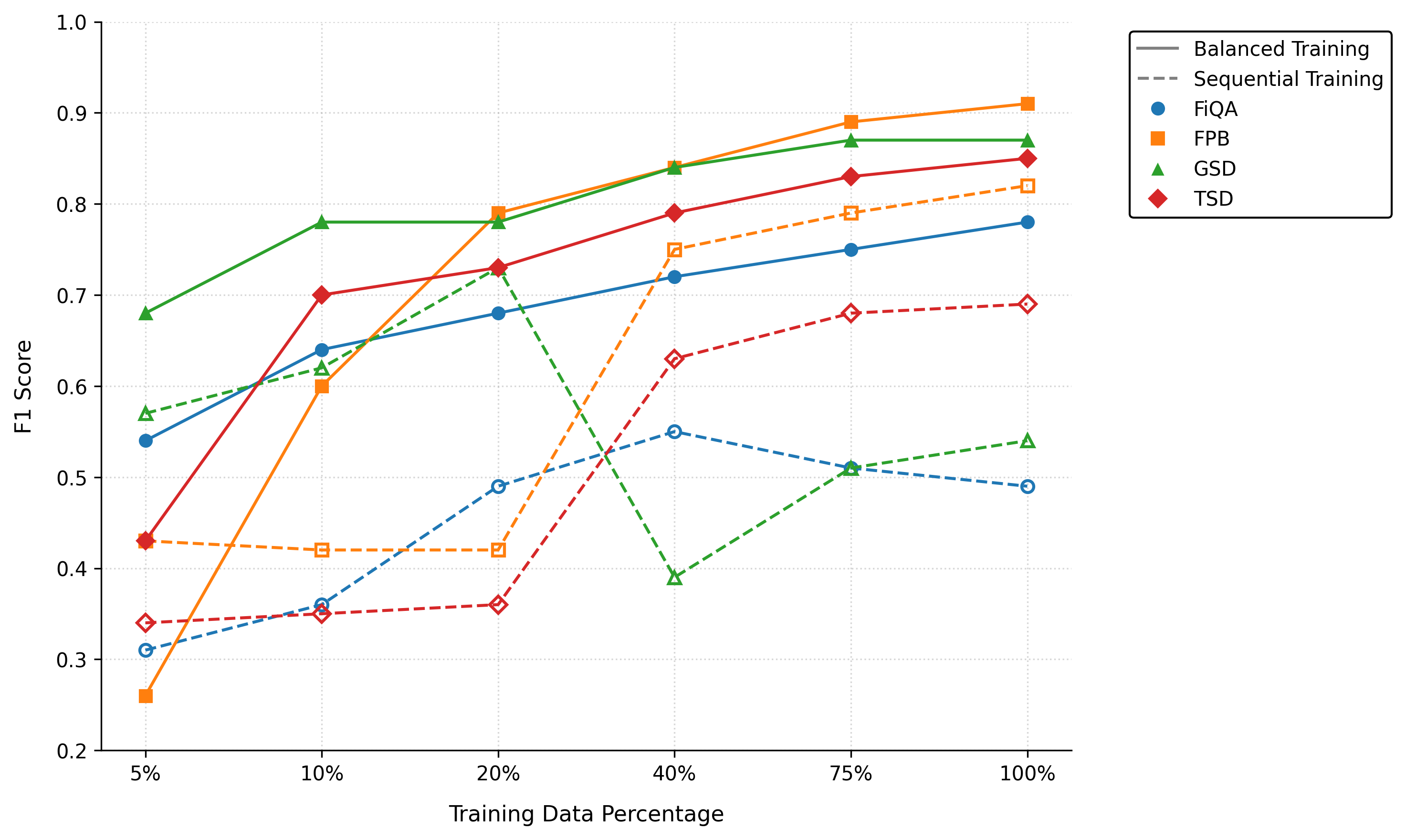
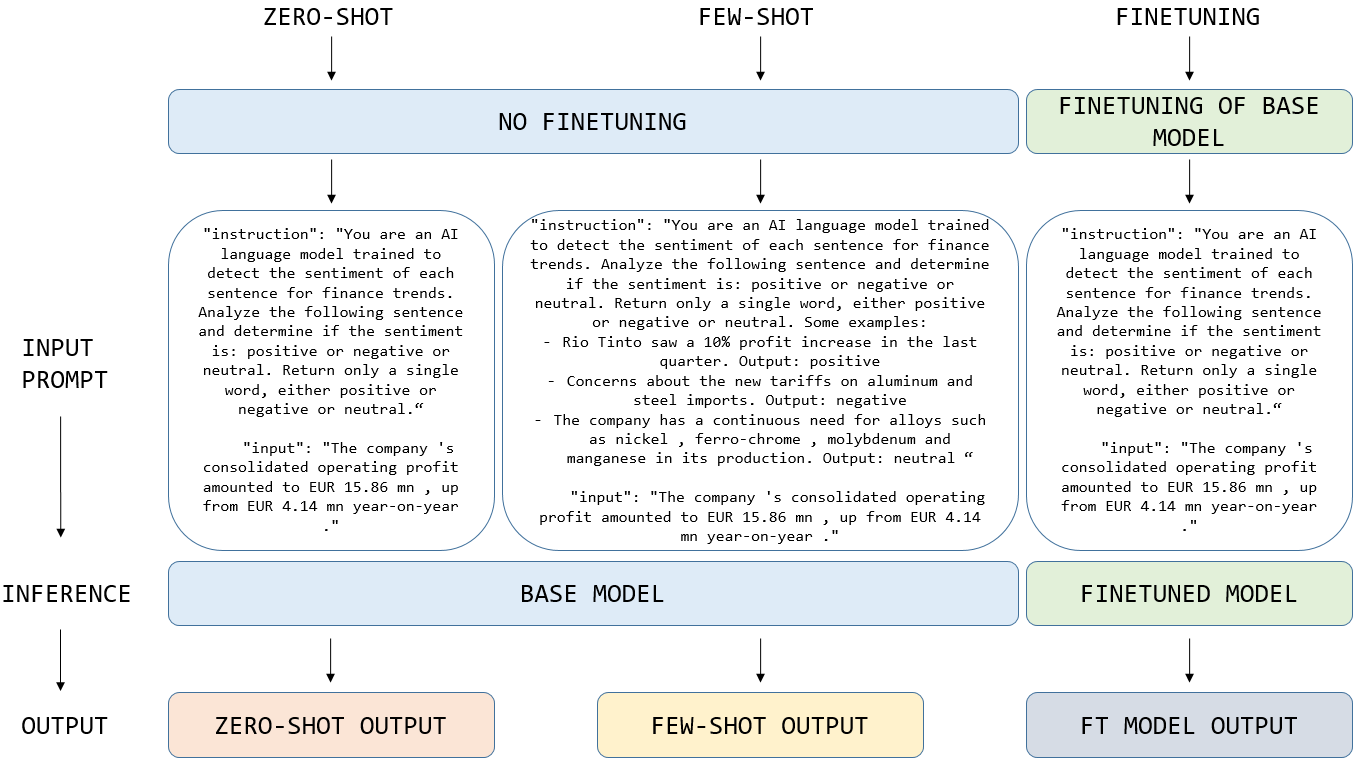
비교 대상인 FinBERT는 금융 도메인에 특화된 BERT 기반 모델로, 기존 연구에서 최고 수준의 성능을 기록했지만, 파인튜닝 시 대규모 GPU 메모리와 장시간 학습이 요구된다. 연구자는 동일한 파인튜닝 파이프라인을 적용해 각 모델을 5 %, 20 %, 100 % 학습 데이터 비율로 학습시켰으며, 제로샷(프롬프트만 제공)과 few‑shot(몇 개의 레이블된 예시 제공) 두 시나리오를 모두 실험했다.
평가 지표는 정확도, F1‑score, 그리고 매크로 평균을 사용했으며, 결과는 Qwen‑3 8B와 Llama‑3 8B가 특히 데이터가 제한된 5 % 상황에서도 FinBERT를 능가함을 보여준다. 특히 다국어 데이터셋인 Chinese Finance Sentiment에서는 Qwen‑3 8B가 현저히 높은 정확도를 기록했으며, 이는 모델이 다국어 사전 학습과 인스트럭션 튜닝을 동시에 수행한 덕분으로 해석된다. 또한, 트위터와 뉴스와 같이 비정형·짧은 텍스트에서는 Llama‑3 8B가 문맥 이해와 감성 추론에서 우수한 성능을 보였다.
이러한 결과는 경량형 LLM이 제한된 컴퓨팅 자원과 적은 라벨 데이터만으로도 금융 텍스트 감성 분석에서 실용적인 성능을 달성할 수 있음을 시사한다. 실무에서는 비용 효율적인 모델 배포가 가능해지며, 학계에서는 오픈소스 모델을 활용한 재현 연구가 활발히 진행될 여지를 제공한다. 다만, 현재 실험은 공개 데이터에 한정됐으며, 실제 거래 환경에서의 실시간 스트리밍 데이터나 고빈도 거래와 연계된 감성 분석에는 추가 검증이 필요하다. 또한, 경량 모델의 파라미터 수가 여전히 수억 수준이므로, 극히 저사양 환경(예: 모바일 디바이스)에서는 추가 압축 기법이 요구될 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리