인도 수학 올림피아드 문제를 활용한 자동 형식화 벤치마크
📝 원문 정보
- Title: IndiMathBench: Autoformalizing Mathematical Reasoning Problems with a Human Touch
- ArXiv ID: 2512.00997
- 발행일: 2025-11-30
- 저자: Param Biyani, Shashank Kirtania, Yasharth Bajpai, Sumit Gulwani, Ashish Tiwari
📝 초록 (Abstract)
신뢰할 수 있는 자동 형식화는 대형 언어 모델(LLM) 시대에도 여전히 어려운 과제이다. 고품질 학습 데이터의 부족이 주요 병목 현상으로 작용한다. 전문가가 주석을 달려면 수학과 정리 증명 모두에 대한 깊은 전문 지식과 상당한 시간이 필요하다. 우리는 Lean에서 자연어 문제를 형식화하기 위한 AI 기반 인간 보조 파이프라인을 활용해 만든 인간 검증 벤치마크인 INDIMATHBENCH를 소개한다. INDIMATHBENCH는 인도 수학 올림피아드에서 발췌한 312개의 형식화된 Lean 4 정리와 해당 비공식 문제 진술을 쌍으로 구성한다. 카테고리 기반 검색, 반복적인 컴파일러 피드백, 다중 모델 앙상블을 통해 후보 형식화를 생성하고, 전문가가 인터랙티브 대시보드와 자동 품질 요약을 이용해 효율적으로 검증한다. 여러 최첨단 모델을 평가한 결과, 구문적 타당성과 의미적 정확성 사이에 큰 격차가 존재하며, 반복적 정제 후에도 정리 증명 성공률이 낮아 INDIMATHBENCH가 수학적 추론을 위한 도전적인 테스트베드임을 보여준다. INDIMATHBENCH는 https://github.com/prmbiy/IndiMathBench 에서 공개한다.💡 논문 핵심 해설 (Deep Analysis)
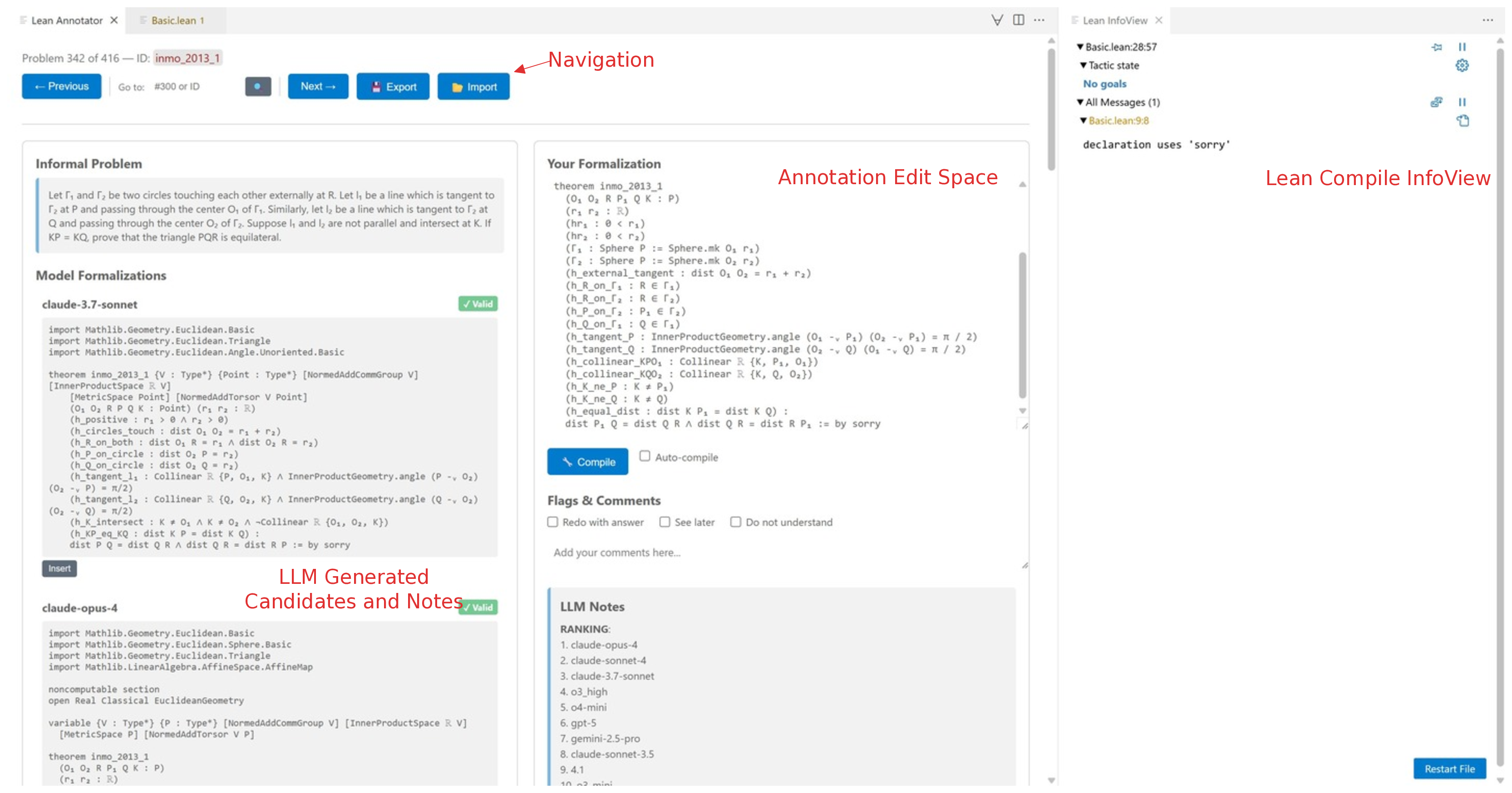
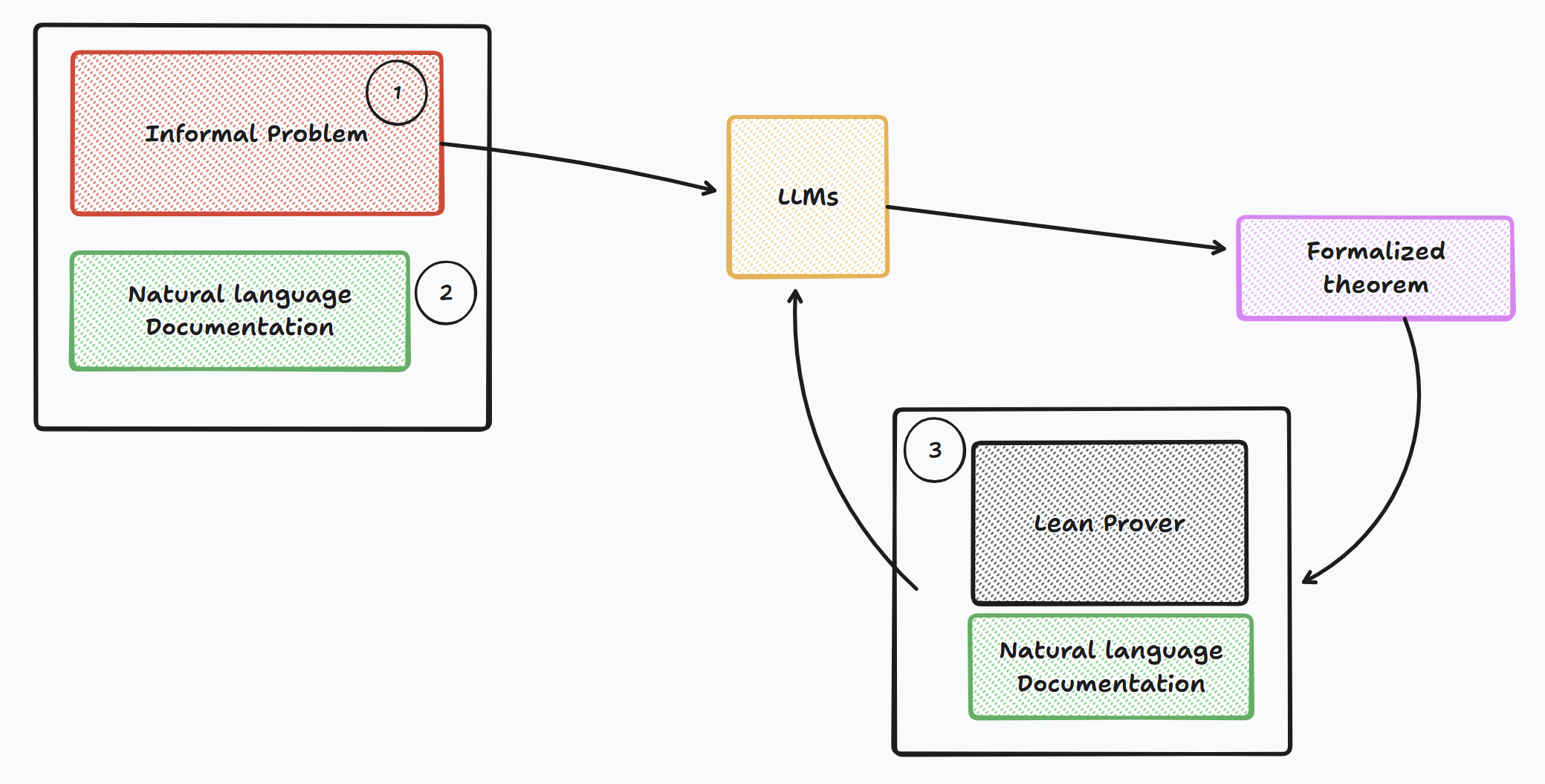
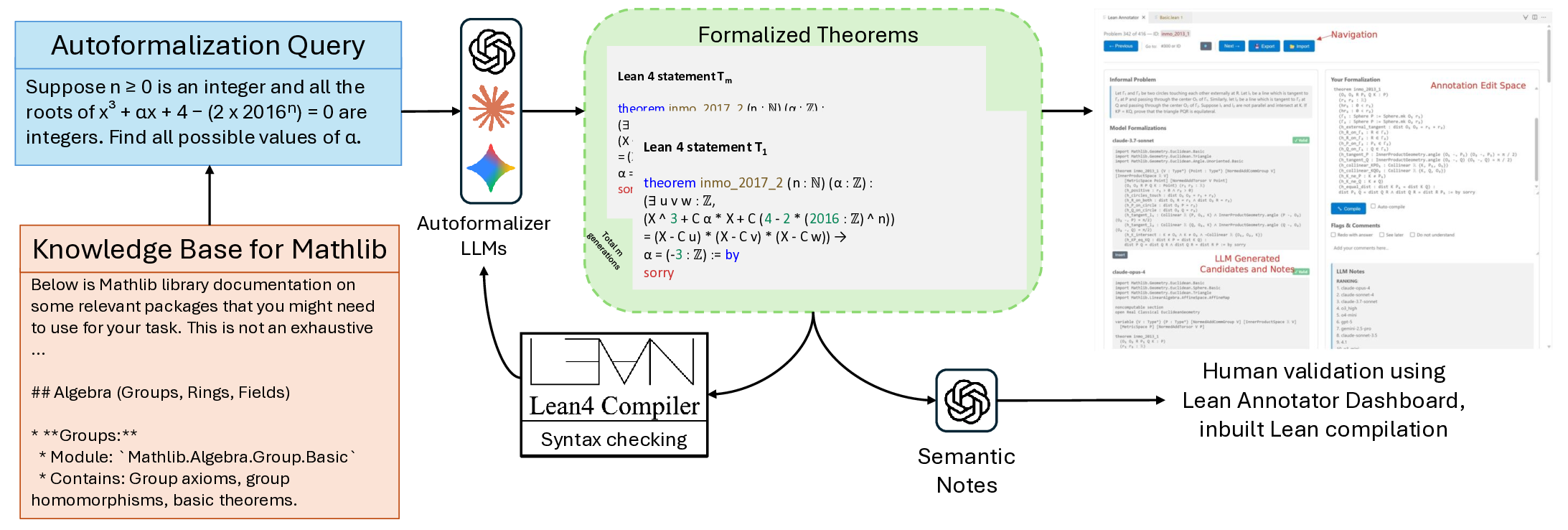
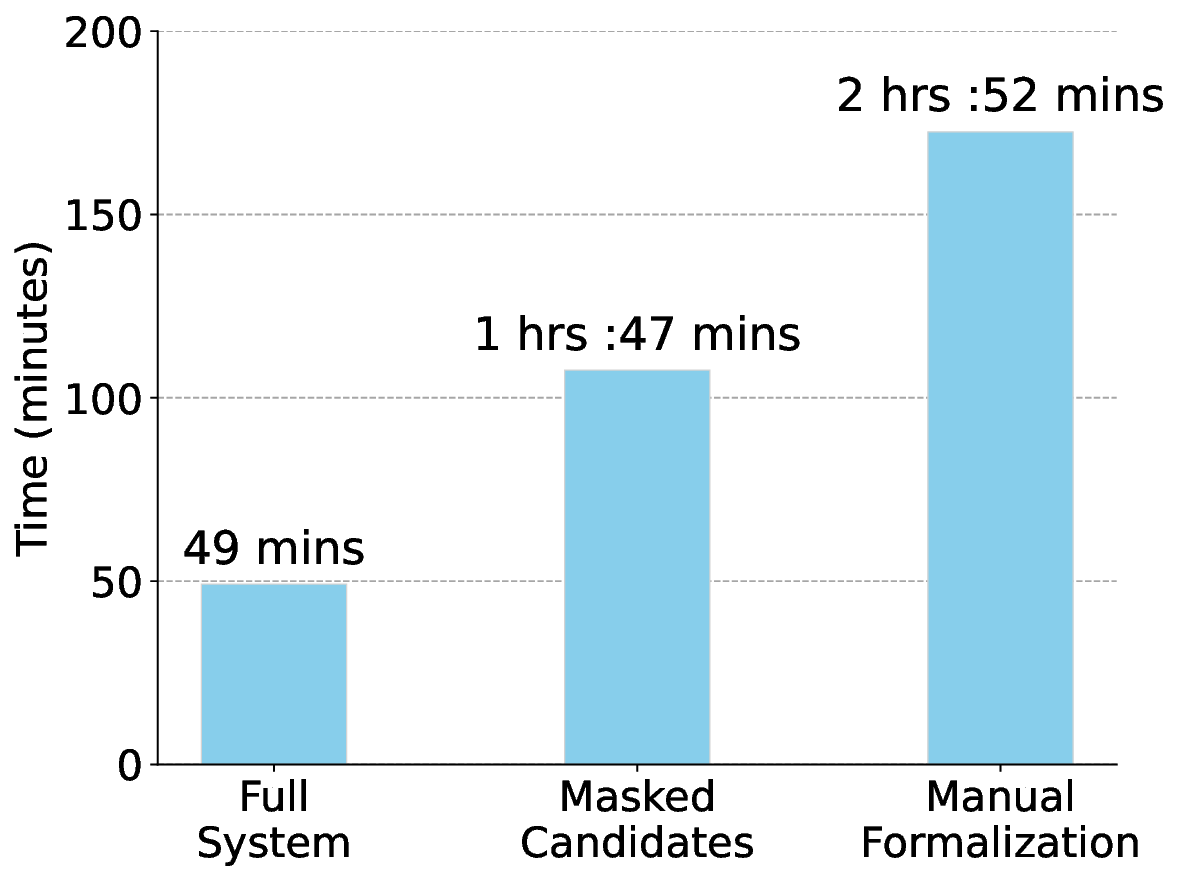
데이터 구축 파이프라인은 크게 네 단계로 구성된다. 첫째, 문제를 카테고리(예: 대수, 기하, 조합)별로 자동 검색하고, 해당 카테고리와 연관된 기존 Lean 정의·정리를 매핑한다. 둘째, 다중 LLM(예: GPT‑4, Claude, LLaMA)과 특화된 수학 모델을 앙상블해 후보 형식화를 생성한다. 셋째, Lean 컴파일러가 제공하는 오류 메시지와 타입 불일치를 피드백 루프로 활용해 후보를 반복적으로 정제한다. 넷째, 인간 전문가가 인터랙티브 대시보드에서 자동 요약(정리 의도, 사용된 정의, 증명 스케치)을 검토하고 최종 승인을 부여한다. 이 과정에서 인간의 검증 비용을 최소화하면서도 형식화 품질을 보장한다는 점이 혁신적이다.
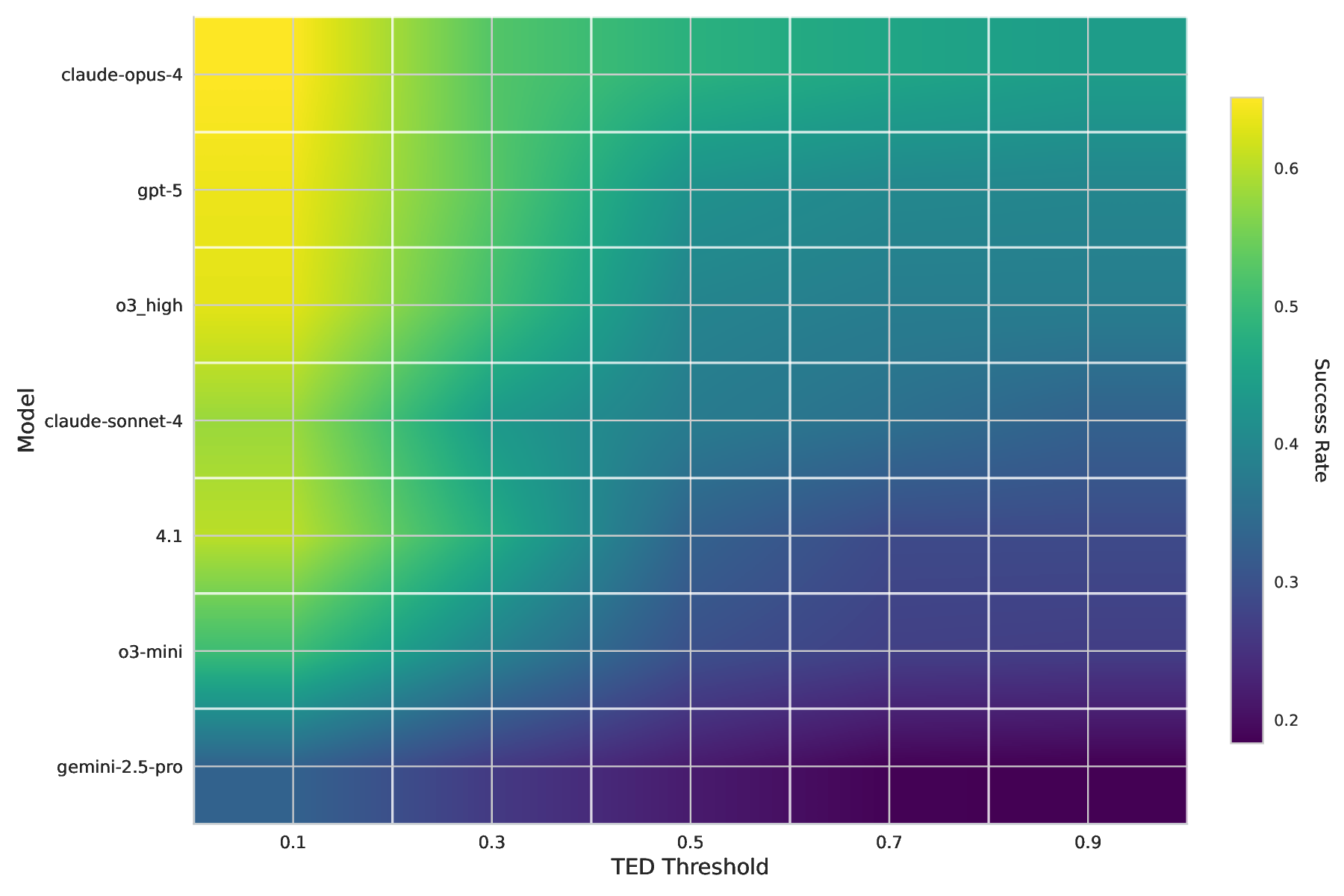
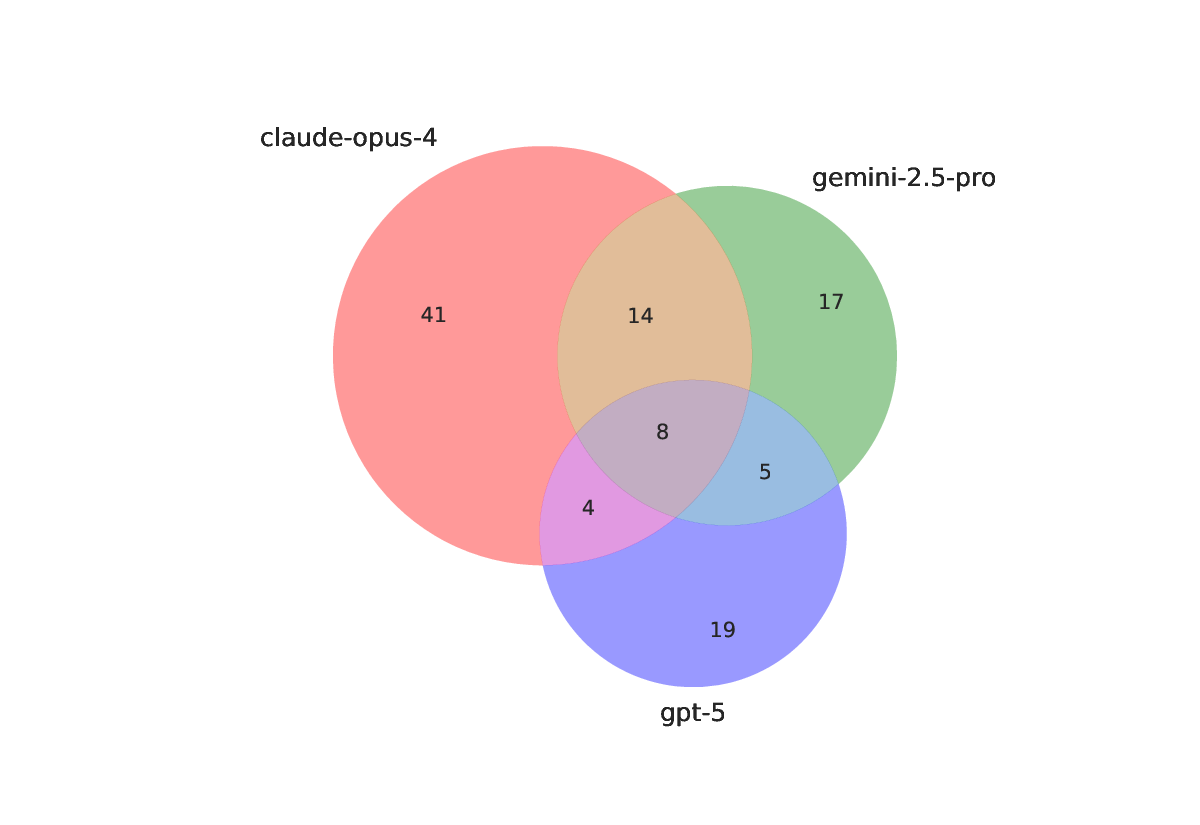
실험 결과는 두 가지 차원을 강조한다. 구문적 타당성(syntactic validity)은 후보가 Lean 컴파일러를 통과했는지를 의미하는데, 최신 모델들은 70 % 이상을 통과시키는 반면, 의미적 정확성(semantic correctness), 즉 원문 문제와 동일한 수학적 의미를 유지하는 비율은 30 % 이하에 머물렀다. 또한, 자동 생성된 증명 스크립트를 기반으로 한 정리 증명 성공률은 10 % 미만으로, 현재 LLM이 복합적인 추론 단계와 정교한 전술 선택을 수행하는 데 한계가 있음을 보여준다. 이러한 격차는 모델이 “문제 이해”와 “증명 전략”을 별도로 학습해야 함을 시사한다.
INDIMATHBENCH는 다음과 같은 연구 방향을 촉진한다. (1) 인간‑기계 협업을 통한 데이터 라벨링 효율성 향상, (2) 형식화 과정에서 발생하는 타입 오류를 학습 신호로 활용하는 메타‑학습, (3) 증명 전술을 자동으로 제안하고 평가하는 강화학습 프레임워크, (4) 다중 언어·다중 문화 수학 문제를 포괄하는 글로벌 벤치마크 구축. 궁극적으로는 자동 형식화와 자동 증명 기술을 통합해, 수학 교육·연구·산업 현장에서 인간 전문가의 부담을 크게 경감시키는 것이 목표다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리