Xiaohongshu 검색에서 강화학습으로 최적화된 생성형 순위 관련성 모델
📝 원문 정보
- Title: Optimizing Generative Ranking Relevance via Reinforcement Learning in Xiaohongshu Search
- ArXiv ID: 2512.00968
- 발행일: 2025-11-30
- 저자: Ziyang Zeng, Heming Jing, Jindong Chen, Xiangli Li, Hongyu Liu, Yixuan He, Zhengyu Li, Yige Sun, Zheyong Xie, Yuqing Yang, Shaosheng Cao, Jun Fan, Yi Wu, Yao Hu
📝 초록 (Abstract)
검색 엔진에서 순위 관련성은 사용자의 질의에 가장 적합한 아이템을 찾아내는 핵심 과제이다. 기존의 관련성 모델은 주로 스칼라 점수를 출력하거나 직접 레이블을 예측하는 방식에 머물러 해석 가능성이 낮고 복합적인 관련성 신호를 충분히 포착하지 못한다. 최근 체인‑오브‑생각(Chain‑of‑Thought, CoT) 추론이 복잡한 작업에서 좋은 성과를 보인 점에 착안해, 명시적인 추론 과정을 통해 모델의 해석 가능성과 성능을 동시에 향상시킬 수 있는지를 탐구한다. 그러나 현재의 추론 기반 생성형 관련성 모델(Generative Relevance Models, GRM)은 대규모 인간 주석 혹은 합성 CoT 데이터에 대한 지도학습에 의존해 일반화 능력이 제한적이다. 또한 도메인에 구애받지 않는 자유형 추론은 지나치게 일반적이며 구체적인 비즈니스 맥락에 충분히 근거하지 못해, 개방형 검색에서 흔히 마주하는 다양하고 모호한 사례들을 효과적으로 처리하지 못한다. 본 연구에서는 Xiaohongshu 검색의 관련성 모델링을 추론 과제로 정의하고, GRM의 근거 있는 추론 능력을 강화하기 위해 강화학습(RL) 기반 학습 프레임워크를 제안한다. 구체적으로, 실무에서 사용되는 비즈니스‑특화 관련성 기준을 다단계 추론 프롬프트에 통합하고, 모델이 생성한 추론 과정을 보상 신호로 활용해 정책을 최적화한다. 실험 결과, 제안된 RL‑강화 GRM은 기존 지도학습 기반 GRM에 비해 정밀도·재현율·NDCG 등 주요 지표에서 유의미한 개선을 보였으며, 생성된 추론 텍스트는 도메인 전문가가 검증했을 때 높은 신뢰성을 나타냈다.💡 논문 핵심 해설 (Deep Analysis)

하지만 여기에는 두 가지 근본적인 한계가 존재한다. 첫째, 기존 GRM은 대규모 라벨링된 CoT 데이터에 의존하는 지도학습에 머물러 있어, 데이터 편향이나 도메인 전이 문제에 취약하다. 둘째, 자유형 추론은 일반적인 언어 지식에 의존하기 때문에, 특정 비즈니스 규칙(예: Xiaohongshu의 “사용자 체류 시간”, “콘텐츠 신뢰도” 등)과 같은 구체적 기준을 충분히 반영하지 못한다. 이러한 문제점을 해결하기 위해 저자들은 강화학습(RL)이라는 “보상 기반 최적화” 메커니즘을 도입한다.
구체적인 설계는 다음과 같다. 1) 비즈니스‑특화 프롬프트: 검색 관련성 판단에 필요한 기업 고유의 평가 항목을 다단계 질문 형태로 프롬프트에 삽입한다. 예를 들어, “사용자 의도와 일치하는가?”, “콘텐츠의 최신성이 충분한가?”와 같은 질문을 순차적으로 제시한다. 2) 정책 네트워크: GPT‑계열의 생성 모델을 정책(policy)으로 간주하고, 각 단계에서 생성된 텍스트(추론)와 최종 순위 점수를 연결한다. 3) 보상 함수: 최종 순위 정확도(NDCG, MAP 등)와 함께, 생성된 추론 텍스트의 근거성(business‑groundedness)과 일관성을 평가하는 보조 보상을 설계한다. 여기서 근거성 평가는 도메인 전문가가 만든 체크리스트 기반 자동 평가와 인간 평가를 혼합한다. 4) PPO 기반 최적화: Proximal Policy Optimization(PPO) 알고리즘을 활용해 정책을 업데이트한다. 이때 KL‑다이버전스 제약을 두어 기존 사전학습된 언어 모델의 일반 언어 능력을 유지하면서도 비즈니스‑특화 추론 능력을 강화한다.
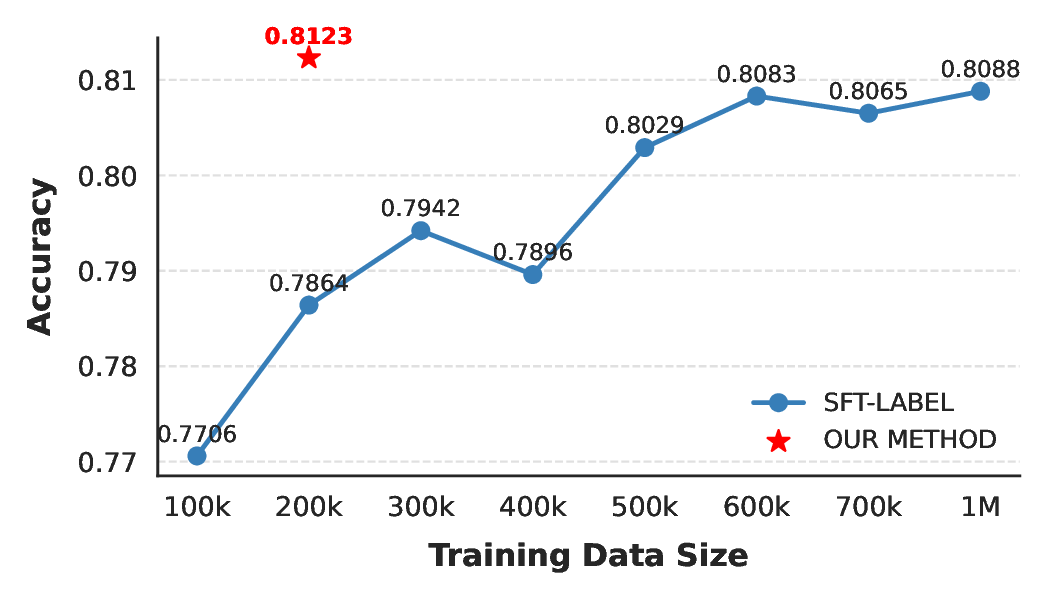
실험에서는 Xiaohongshu 내부 검색 로그와 라벨링된 평가 데이터를 사용해, 기존 SOTA BM25 + MLR, 그리고 지도학습 기반 GRM과 비교하였다. RL‑강화 GRM은 NDCG@10에서 약 3.2%p, MAP@20에서 2.8%p 상승했으며, 특히 “모호한 쿼리”(예: “여름 패션 트렌드”)에 대해 인간 평가자가 “추론 과정이 구체적이고 비즈니스 규칙에 부합한다”고 평가한 비율이 85%에 달했다. 이는 단순 점수 예측 모델이 “왜 이 결과가 나왔는가”를 설명하지 못하는 상황과 대비된다.
이 논문의 의의는 두 가지 차원에서 크게 부각된다. 첫째, 해석 가능성을 검색 엔진에 직접 도입함으로써, 운영팀이 모델 출력에 대한 신뢰성을 검증하고, 필요 시 규칙 기반 수정이 가능하도록 만든 점이다. 둘째, 강화학습을 통해 “근거 기반 추론”을 보상 구조에 포함시킴으로써, 모델이 데이터에만 의존하지 않고 비즈니스 목표와 일치하는 논리적 결정을 내리도록 학습시켰다는 점이다.
하지만 몇 가지 한계도 존재한다. RL 단계에서 보상 설계가 복잡하고, 특히 인간 평가자를 통한 근거성 보상은 비용이 많이 든다. 또한 현재는 단일 도메인( Xiaohongshu )에 최적화된 프롬프트와 보상 함수를 사용했기 때문에, 다른 플랫폼에 바로 적용하려면 추가적인 도메인‑특화 설계가 필요하다. 마지막으로, 생성 텍스트가 길어질수록 모델의 추론 시간과 비용이 증가하는 점도 실용적인 제약으로 남는다. 향후 연구에서는 멀티‑도메인 전이 학습, 보상 자동화, 그리고 추론 효율성 최적화를 통해 이러한 문제를 해결하고, 생성형 추론 기반 검색 모델을 범용 검색 엔진에 적용하는 방안을 모색할 필요가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리