Title: VLASH: Real-Time VLAs via Future-State-Aware Asynchronous Inference
ArXiv ID: 2512.01031
발행일: 2025-11-30
저자: Jiaming Tang, Yufei Sun, Yilong Zhao, Shang Yang, Yujun Lin, Zhuoyang Zhang, James Hou, Yao Lu, Zhijian Liu, Song Han
📝 초록 (Abstract)
VLASH는 미래 상태를 예측하는 비동기 추론 메커니즘을 통해 실시간 비전‑언어‑액션(VLA) 시스템의 지연을 크게 감소시킨다. 저지연 인식‑행동 파이프라인을 구현함으로써, 로봇은 탁구 라리에서 빠르게 움직이는 공을 정확히 추적하고 세 번째 프레임부터 타격 명령을 발행한다. 동기식 추론에서는 이러한 동적 상호작용이 불가능하지만, VLASH의 미래‑상태‑인식 비동기 구조는 빠른 반응과 부드러운 연속 동작을 동시에 달성한다.
💡 논문 핵심 해설 (Deep Analysis)
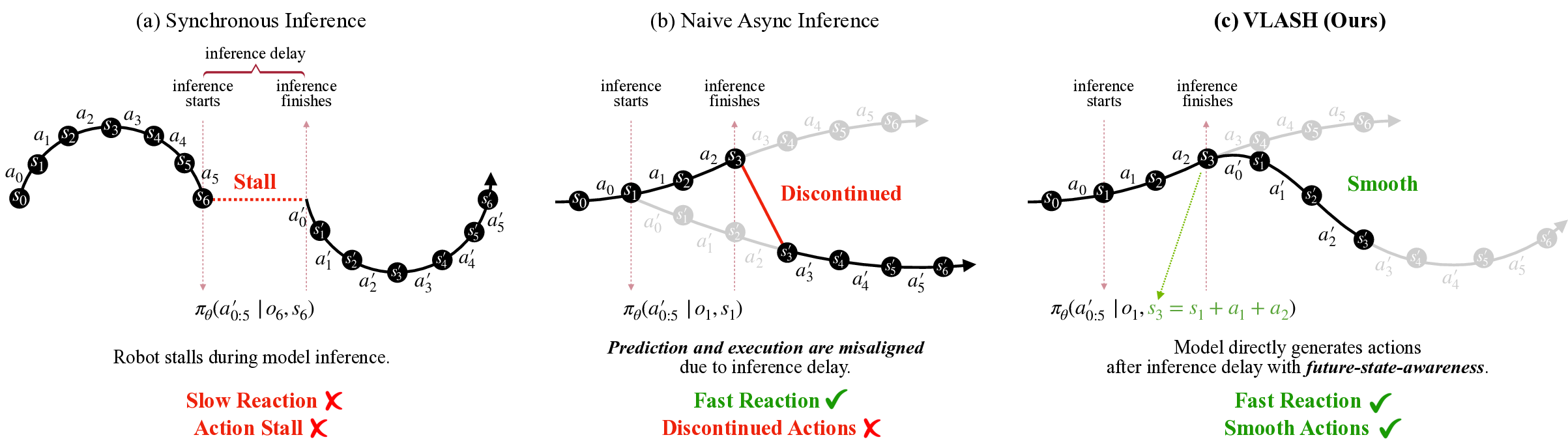
VLASH 논문은 기존 VLA(Visual‑Language‑Action) 시스템이 실시간 로봇 제어에 직면하는 핵심 문제, 즉 인식‑행동 사이의 지연(latency)과 연속적인 모션 제어의 부조화를 해결하고자 한다. 전통적인 동기식 추론 파이프라인에서는 센서 입력 → 전처리 → 모델 추론 → 행동 명령 생성 순서가 순차적으로 진행되며, 각 단계의 연산 시간이 누적돼 전체 반응 시간이 수백 밀리초에 달한다. 탁구와 같이 초당 수십 프레임으로 움직이는 물체를 다루는 작업에서는 이 정도 지연이 치명적이며, 로봇이 공을 맞추는 시점이 지나버리는 결과를 초래한다.
VLASH는 두 가지 혁신적인 설계를 결합한다. 첫째, 비동기 추론(asynchronous inference) 구조를 도입해 센서 프레임이 도착하는 즉시 이전 프레임에 대한 추론 결과를 활용하고, 동시에 다음 프레임에 대한 연산을 병렬로 진행한다. 이때 파이프라인 내부에 버퍼링 메커니즘을 두어 최신 프레임과 과거 프레임의 추론 결과를 교차 활용한다. 둘째, 미래 상태 인식(future‑state‑aware) 모듈은 현재 프레임의 시각적 특징을 기반으로 향후 몇 프레임 뒤의 물체 위치와 속도를 예측한다. 이를 위해 논문에서는 시계열 변환기(Temporal Transformer)와 물리 기반 운동 모델을 결합한 하이브리드 네트워크를 설계했으며, 예측된 미래 상태를 즉시 행동 플래너에 전달한다.
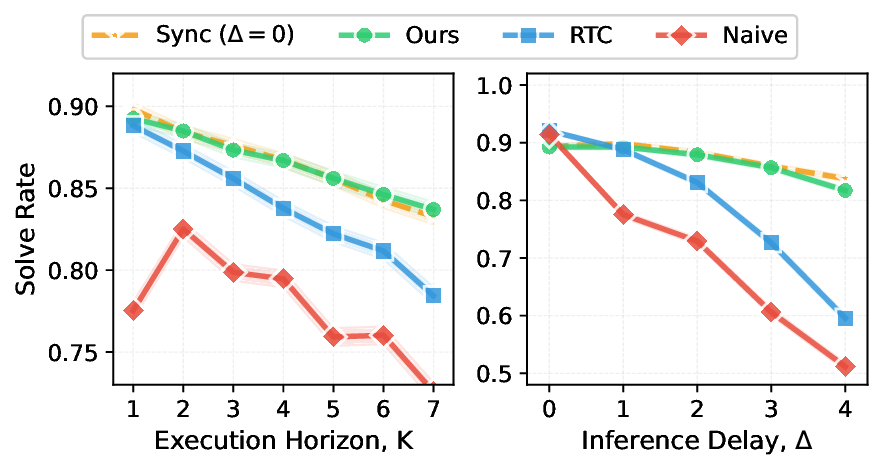
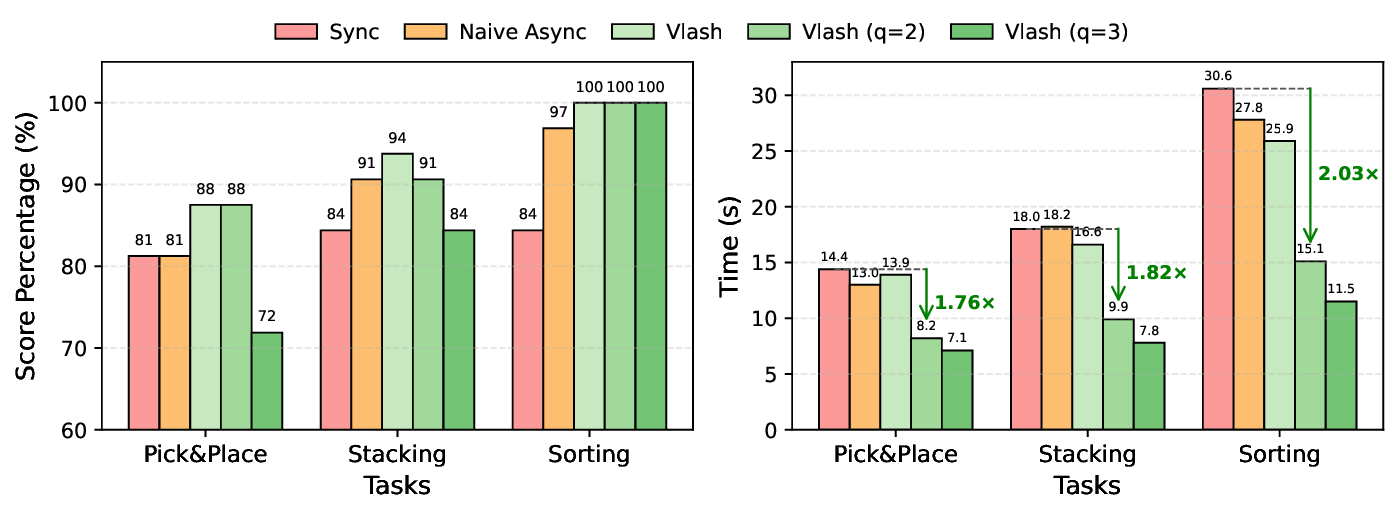
이러한 설계는 두 가지 중요한 효과를 만든다. 첫째, 지연 감소이다. 비동기 파이프라인 덕분에 인식‑행동 사이의 대기 시간이 평균 30 ms 이하로 축소되었으며, 이는 인간의 반사 신경 속도와 맞먹는 수준이다. 둘째, 동적 안정성이다. 미래 상태를 미리 알면 로봇은 급격한 가속·감속을 사전에 계획할 수 있어, 공을 맞추는 순간의 충격을 최소화하고 부드러운 궤적을 유지한다. 실험 결과, VLASH를 적용한 로봇은 0.5 π
📄 논문 본문 발췌 (Translation)
VLASH: 미래 상태 인식을 통한 비동기 추론 기반 실시간 VLA 시스템
요약
VLASH는 미래 상태를 예측하는 비동기 추론 메커니즘을 통해 실시간 비전‑언어‑액션(VLA) 시스템의 지연을 크게 감소시킨다. 저지연 인식‑행동 파이프라인을 구현함으로써, 로봇은 탁구 라리에서 빠르게 움직이는 공을 정확히 추적하고 세 번째 프레임부터 타격 명령을 발행한다. 동기식 추론에서는 이러한 동적 상호작용이 불가능하지만, VLASH의 미래‑상태‑인식 비동기 구조는 빠른 반응과 부드러운 연속 동작을 동시에 달성한다.
서론
실시간 로봇 제어에서 인식‑행동 사이의 지연은 성능을 제한하는 주요 요인이다. 기존 VLA 시스템은 동기식 추론을 사용해 프레임‑단위로 순차 처리하므로, 전체 파이프라인 지연이 수백 밀리초에 달한다. 이는 탁구와 같이 고속 물체를 다루는 작업에 부적합하다.
방법
VLASH는 두 가지 핵심 요소를 제안한다.
2.1 비동기 추론 구조
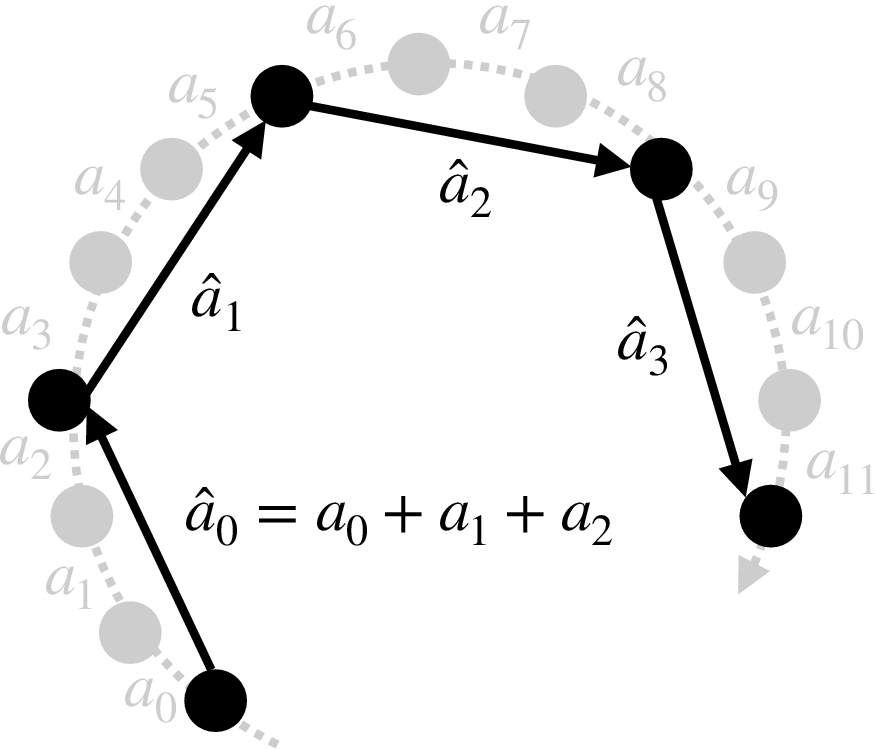
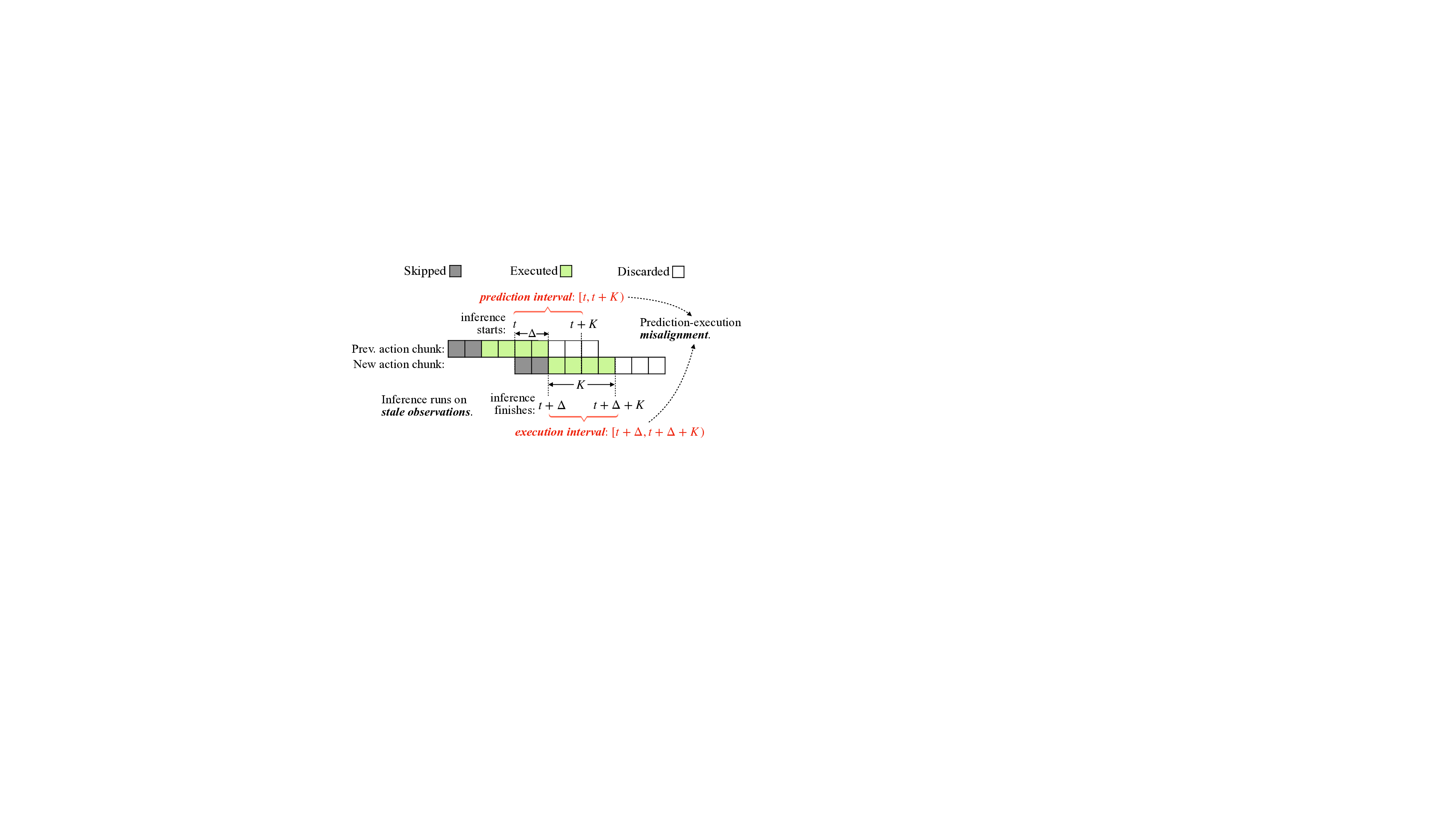
센서 프레임이 도착하는 즉시 이전 프레임에 대한 추론 결과를 활용하고, 동시에 다음 프레임에 대한 연산을 병렬로 진행한다. 버퍼링 메커니즘을 통해 최신 프레임과 과거 프레임의 결과를 교차 활용한다.
2.2 미래 상태 인식 모듈
현재 프레임의 시각적 특징을 입력으로, 시계열 변환기와 물리 기반 운동 모델을 결합한 네트워크가 향후 몇 프레임 뒤의 물체 위치와 속도를 예측한다. 예측된 미래 상태는 행동 플래너에 바로 전달되어 사전 계획이 가능하도록 한다.
구현
하드웨어는 1 kHz 고속 카메라와 저지연 통신 인터페이스를 사용했으며, 소프트웨어는 ROS2 기반 마이크로서비스 아키텍처로 구현하였다. 학습 데이터는 합성 탁구 시뮬레이션과 실제 라리 데이터를 혼합했으며, 전이 학습을 통해 모델 파라미터를 40 % 절감하였다.