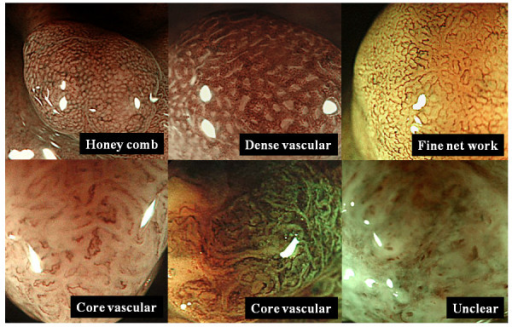
의료 복합 멀티모달 추론 벤치마크 MedCMR
📝 원문 정보
- Title: Med-CMR: A Fine-Grained Benchmark Integrating Visual Evidence and Clinical Logic for Medical Complex Multimodal Reasoning
- ArXiv ID: 2512.00818
- 발행일: 2025-11-30
- 저자: Haozhen Gong, Xiaozhong Ji, Yuansen Liu, Wenbin Wu, Xiaoxiao Yan, Jingjing Liu, Kai Wu, Jiazhen Pan, Bailiang Jian, Jiangning Zhang, Xiaobin Hu, Hongwei Bran Li
📝 초록 (Abstract)
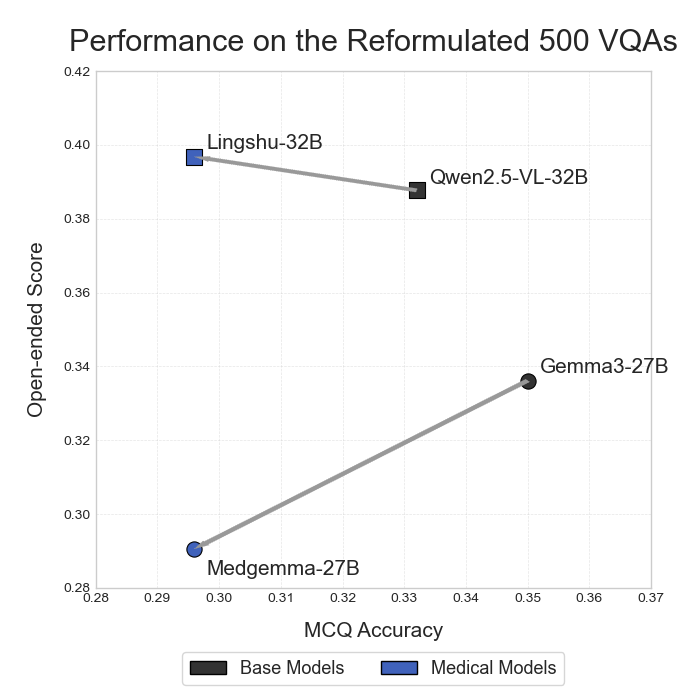
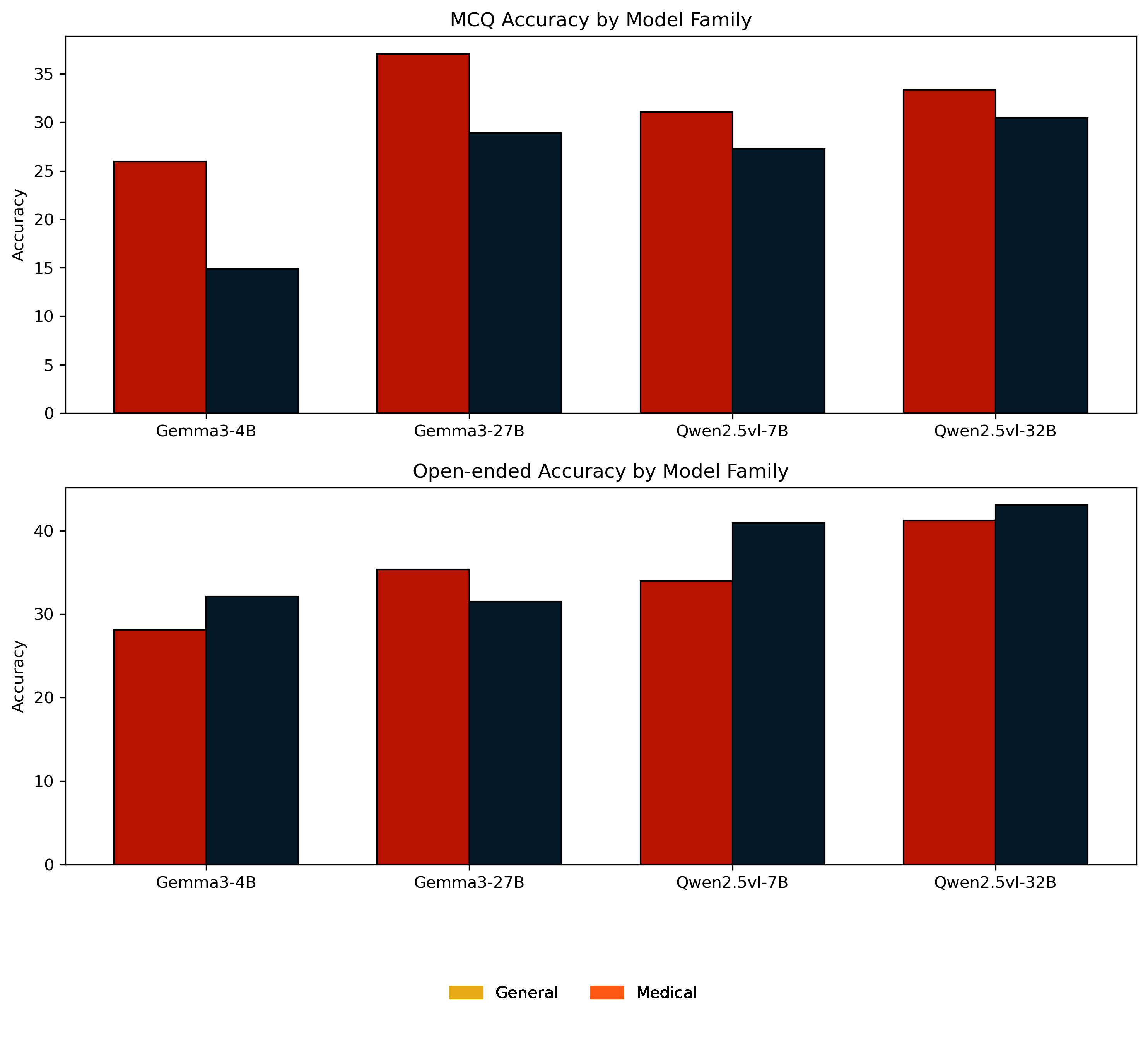
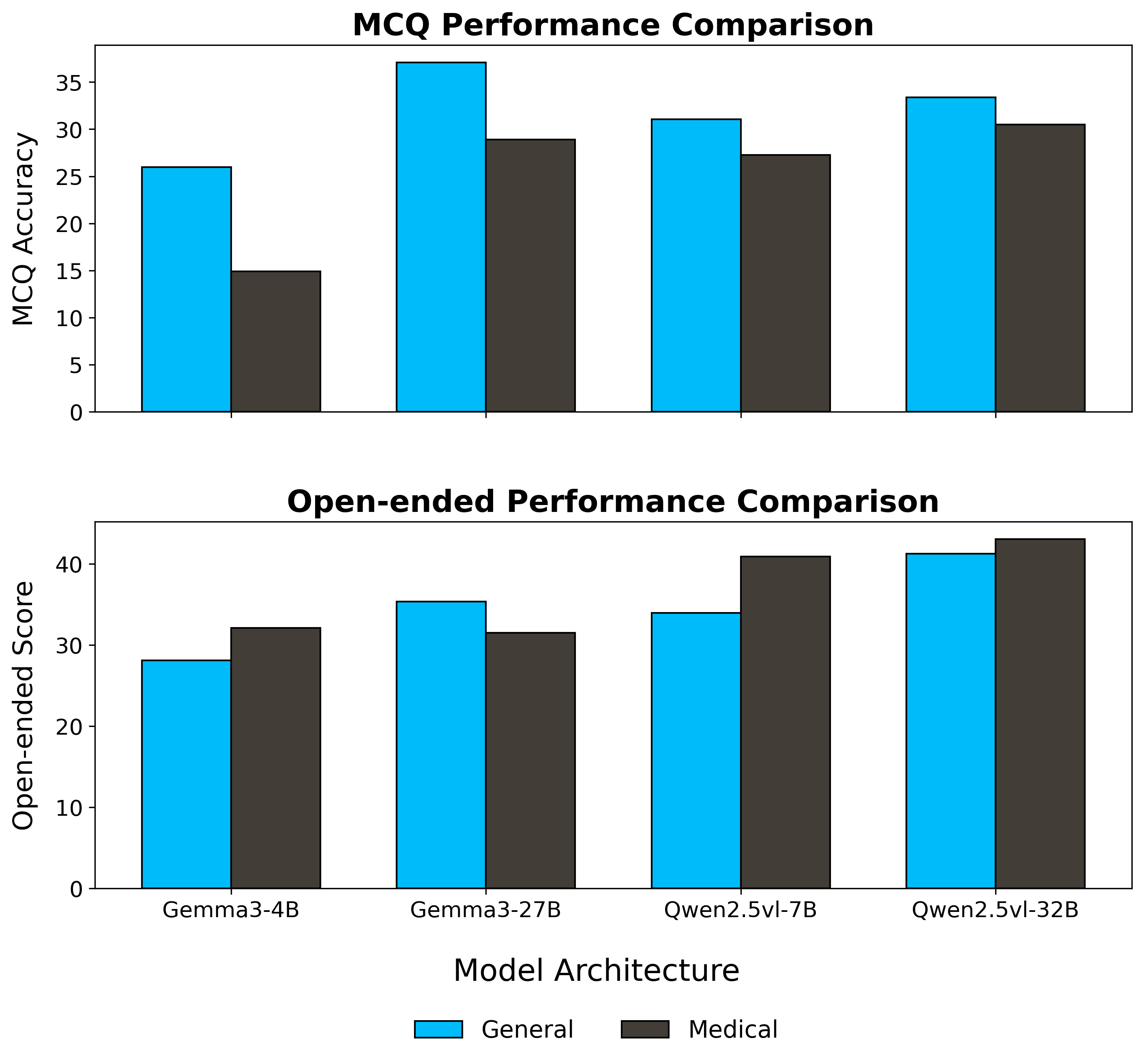
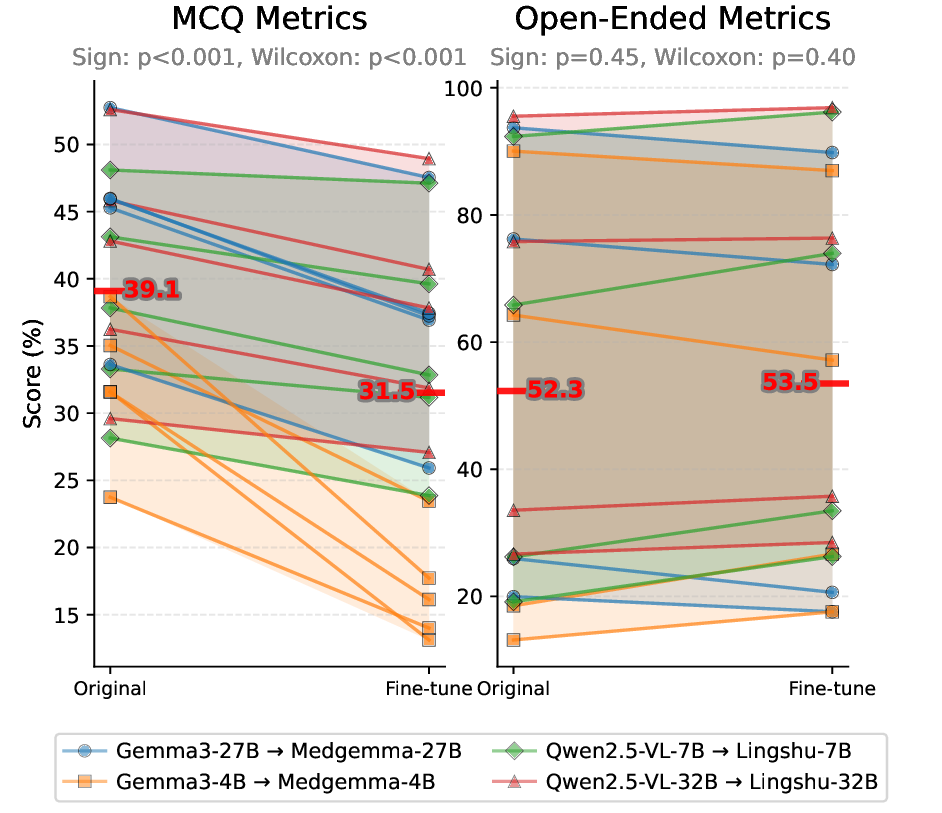
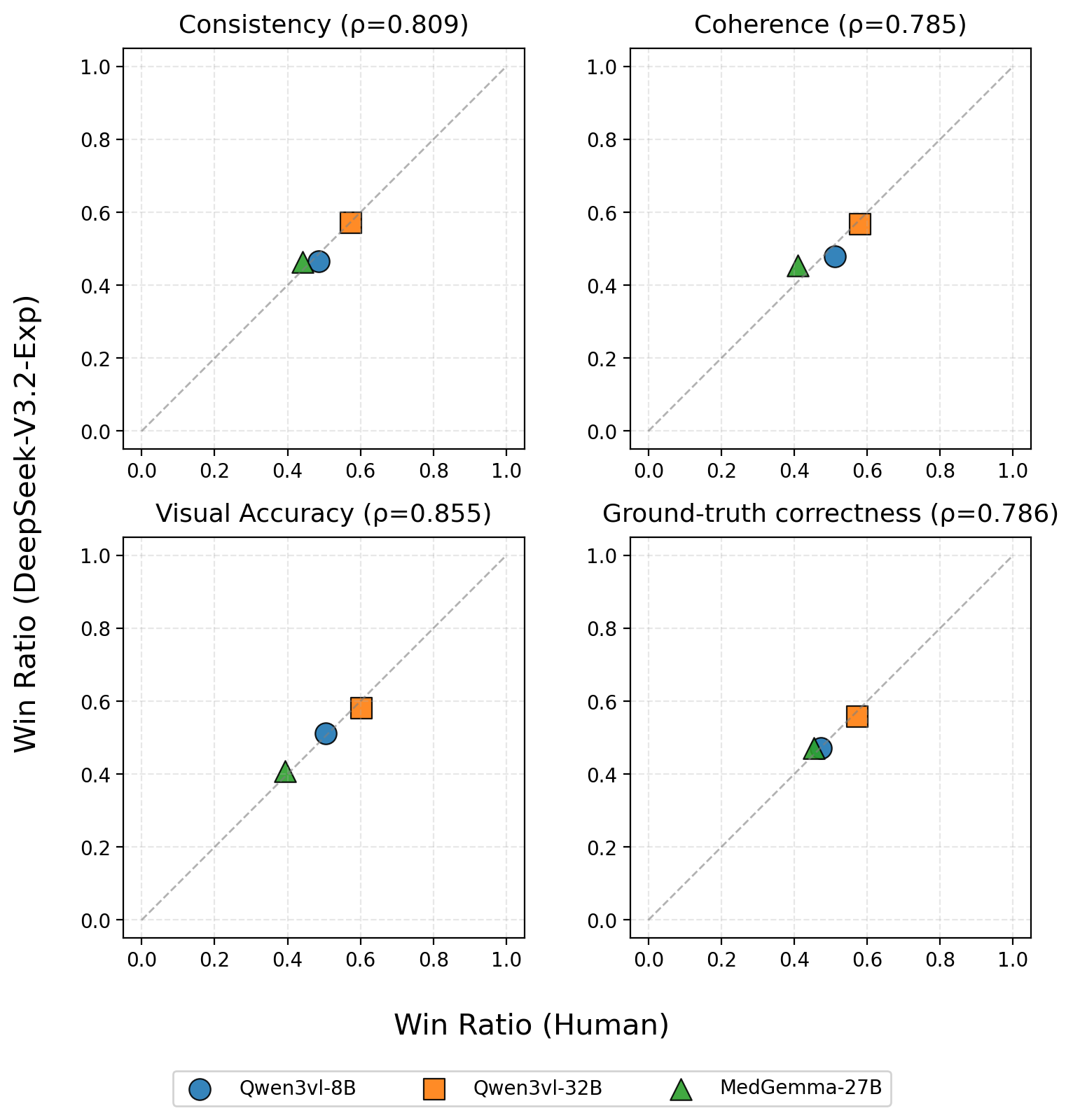
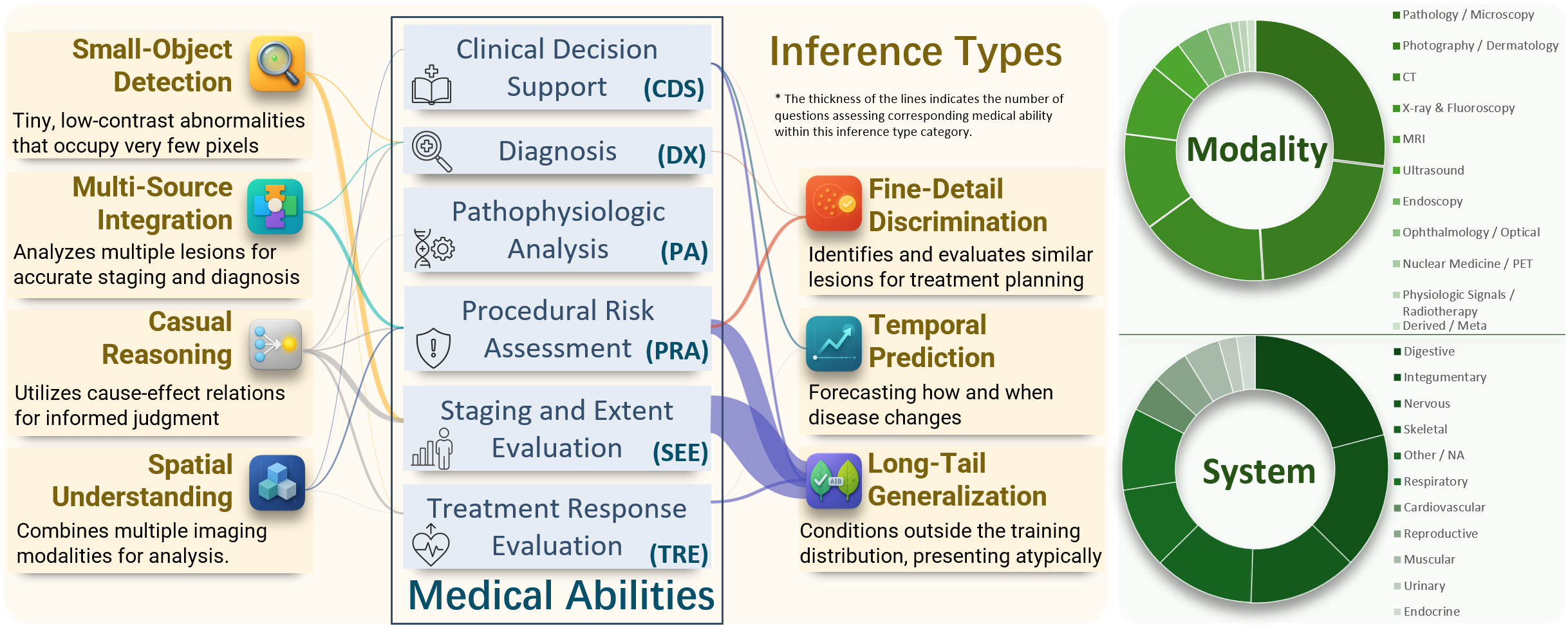
대형 멀티모달 언어 모델(MLLM)이 임상 현장에 점차 도입되고 있으나, 복잡한 의료 추론 능력은 아직 불투명하다. 본 연구는 의료 복합 멀티모달 추론을 정밀하게 평가하기 위해 Med‑CMR 벤치마크를 제시한다. Med‑CMR은 (1) 의료 멀티모달 추론을 시각 이해와 다단계 추론으로 세분화하여 체계적인 능력 분해를 수행하고, (2) 소물체 탐지·세부 차이 구분·공간 이해 등 세 가지 시각 이해 차원과 시간 예측·인과 추론·희귀 사례 일반화·다중 소스 통합 등 네 가지 임상 시나리오를 포함한 도전적인 과제를 설계했으며, (3) 11개 장기계와 12개 영상 modality에 걸쳐 20 653개의 VQA 쌍을 수집하고 인간 전문가와 모델 보조 검증을 거쳐 임상 진위성을 확보하였다. 18개의 최신 MLLM을 Med‑CMR에 평가한 결과, 상용 모델인 GPT‑5가 다지선다형 질문에서 57.81 %의 정확도와 개방형 질문에서 48.70 점의 점수로 최고 성능을 보였으며, Gemini 2.5 Pro(49.87 % / 45.98 점)와 오픈소스 Qwen3‑VL‑235B‑A22B(49.34 % / 42.62 점)보다 우수했다. 그러나 특화된 의료 MLLM이 강력한 일반 모델을 일관적으로 앞서는 것은 아니며, 희귀 사례 일반화가 주요 실패 요인으로 나타났다. Med‑CMR은 시각‑추론 통합과 드문 사례에 대한 강인성을 검증하는 스트레스 테스트이자 향후 임상용 MLLM 개발을 위한 엄격한 기준을 제공한다.💡 논문 핵심 해설 (Deep Analysis)

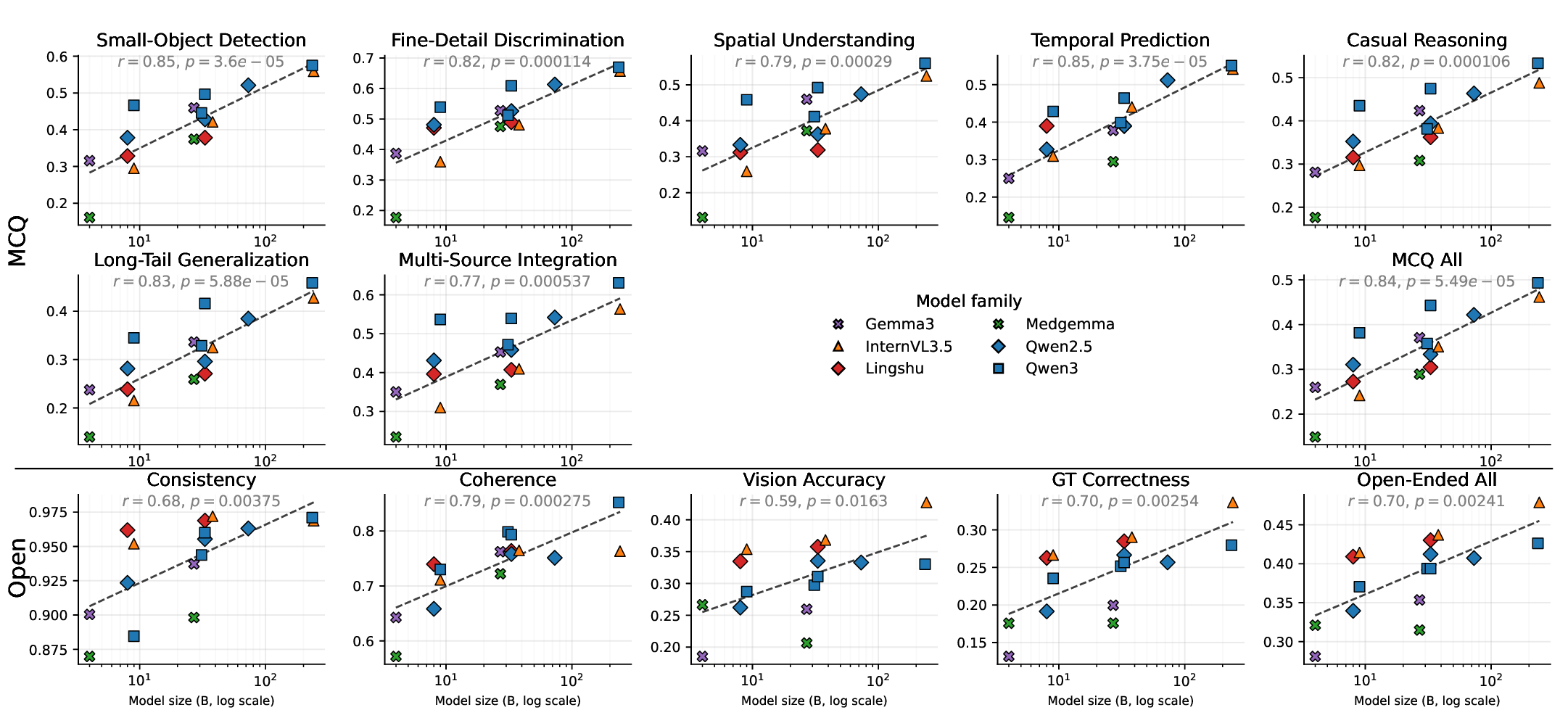
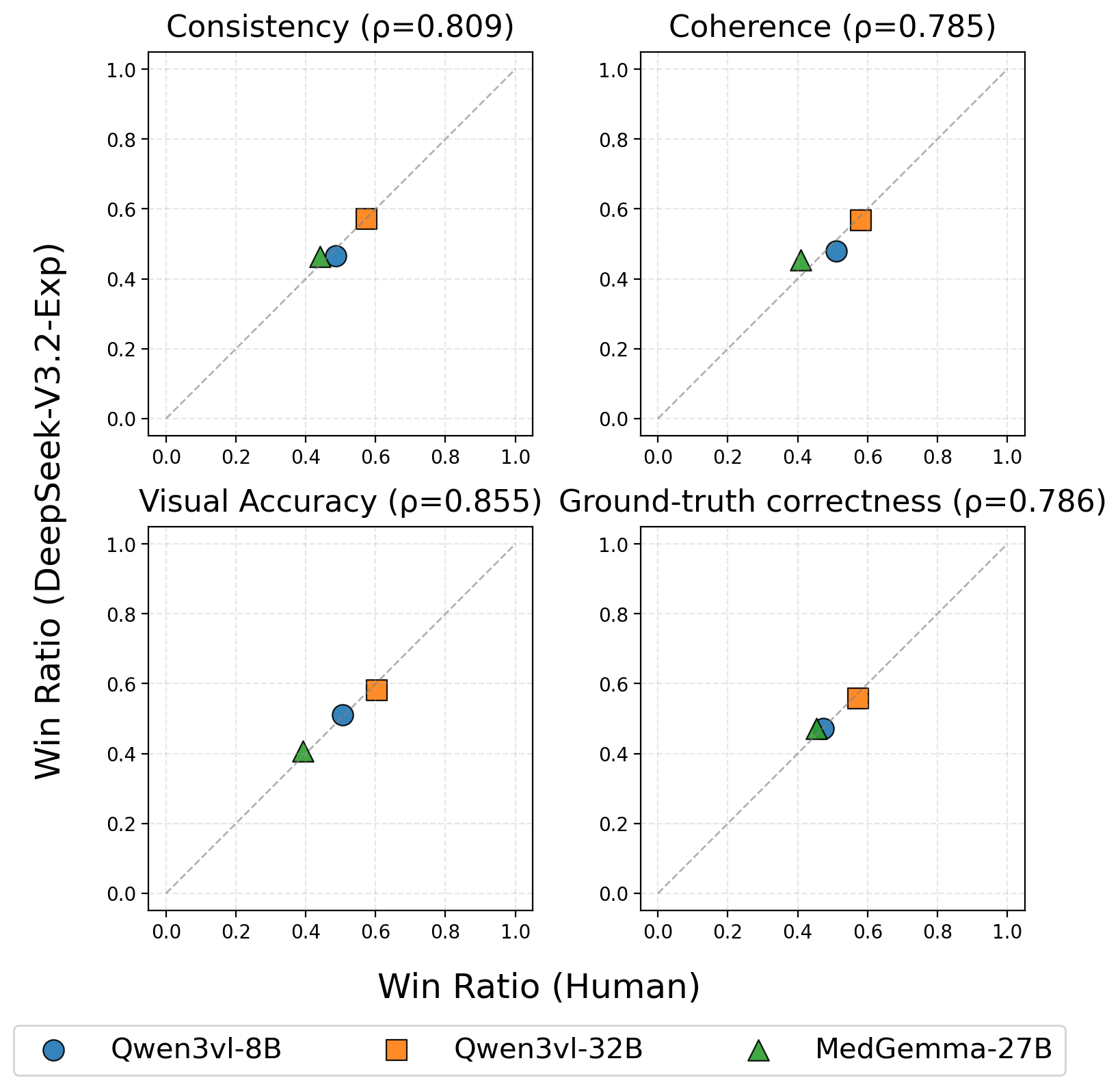
실험 결과는 몇 가지 중요한 인사이트를 제공한다. 가장 눈에 띄는 것은 GPT‑5와 같은 최신 일반 목적 대형 모델이 의료 특화 모델을 능가한다는 점이다. 이는 대규모 사전학습과 광범위한 멀티모달 데이터가 의료 도메인 특화 데이터보다도 강력한 일반화 능력을 부여한다는 가설을 뒷받침한다. 그러나 전체 정확도가 60 %를 넘지 못한다는 점은 현재 MLLM이 임상 현장에서 신뢰할 수 있는 수준에 아직 도달하지 못했음을 시사한다. 특히 ‘희귀 사례 일반화’가 주요 실패 모드로 드러났는데, 이는 데이터 불균형과 드문 질환에 대한 레이블 부족이 모델의 추론 능력을 크게 제한한다는 것을 의미한다.
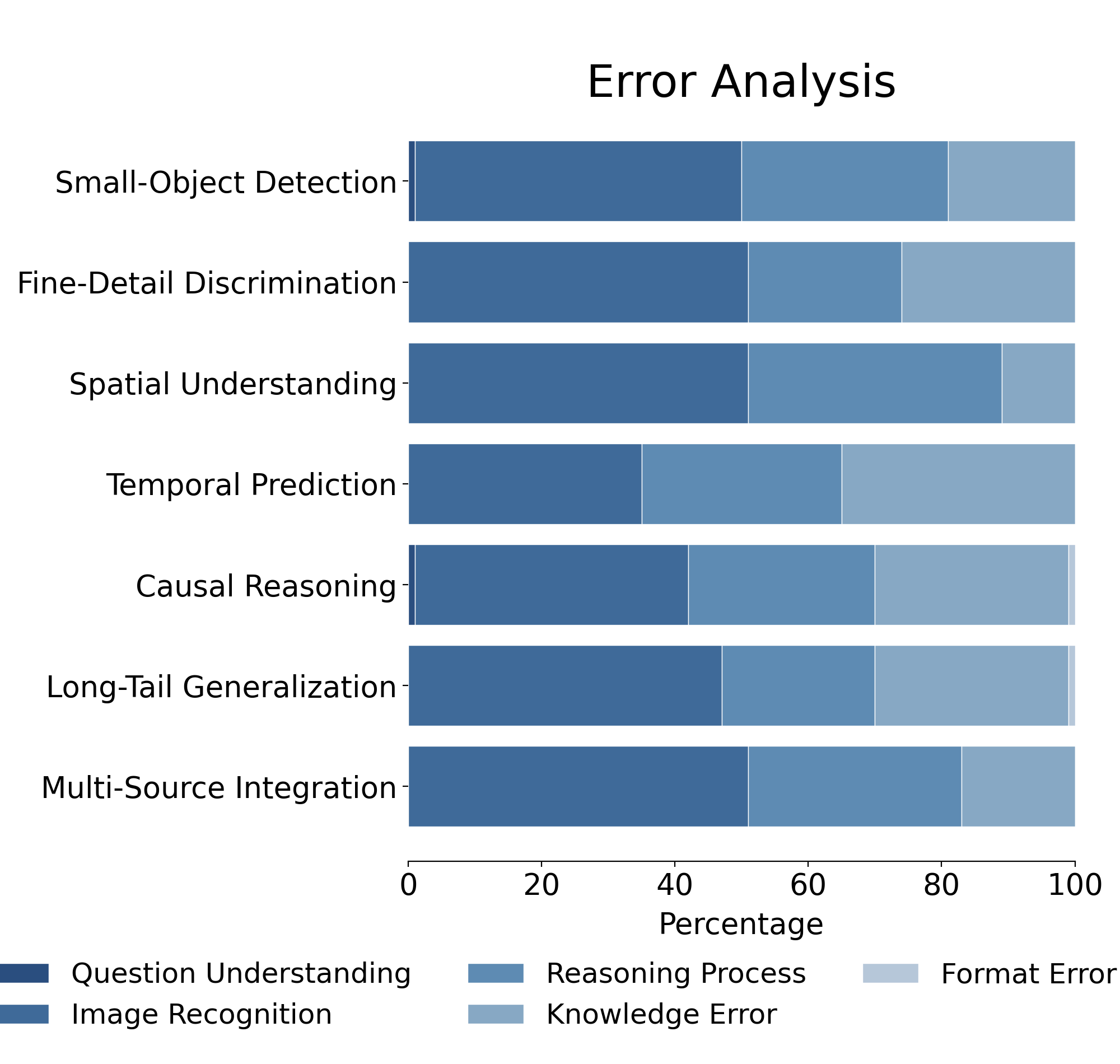
또한, 시각 이해와 추론을 별도로 평가함으로써 모델이 어느 단계에서 오류가 발생하는지 진단할 수 있다. 예를 들어, 작은 병변 탐지에서 낮은 점수를 받은 모델은 이미지 전처리 혹은 고해상도 특징 추출에 한계가 있음을 암시한다. 반면, 다중 소스 통합 과제에서 성능이 저조한 모델은 텍스트‑이미지 간의 의미적 연결 고리를 구축하는 데 어려움을 겪는 것으로 해석될 수 있다. 이러한 세분화된 피드백은 모델 설계자에게 구체적인 개선 방향을 제공한다.
결론적으로 Med‑CMR은 의료 멀티모달 AI의 현재 한계를 명확히 드러내면서, 향후 연구가 집중해야 할 핵심 영역—고해상도 시각 이해, 장기적·인과적 추론, 그리고 희귀 사례에 대한 강인성—을 제시한다. 향후 모델 개발 시 대규모 일반 데이터와 의료 특화 데이터의 효율적인 융합, 그리고 희귀 사례를 위한 데이터 증강 및 메타학습 전략이 필요할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리