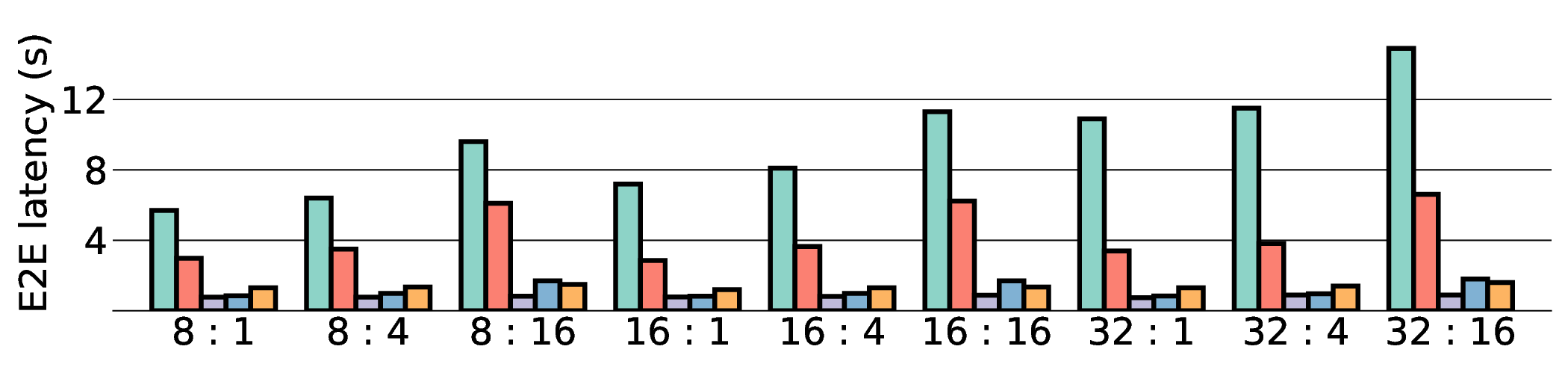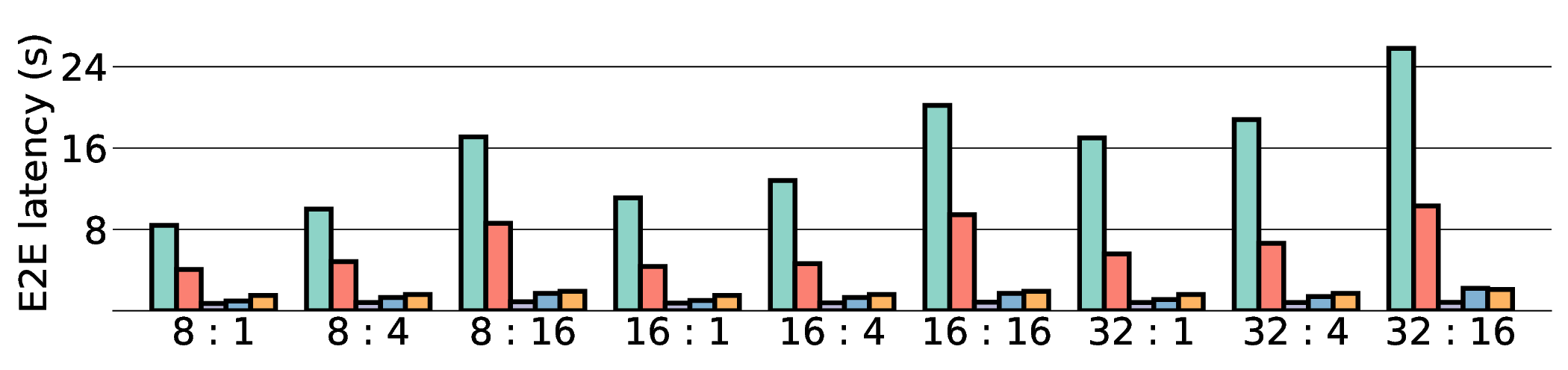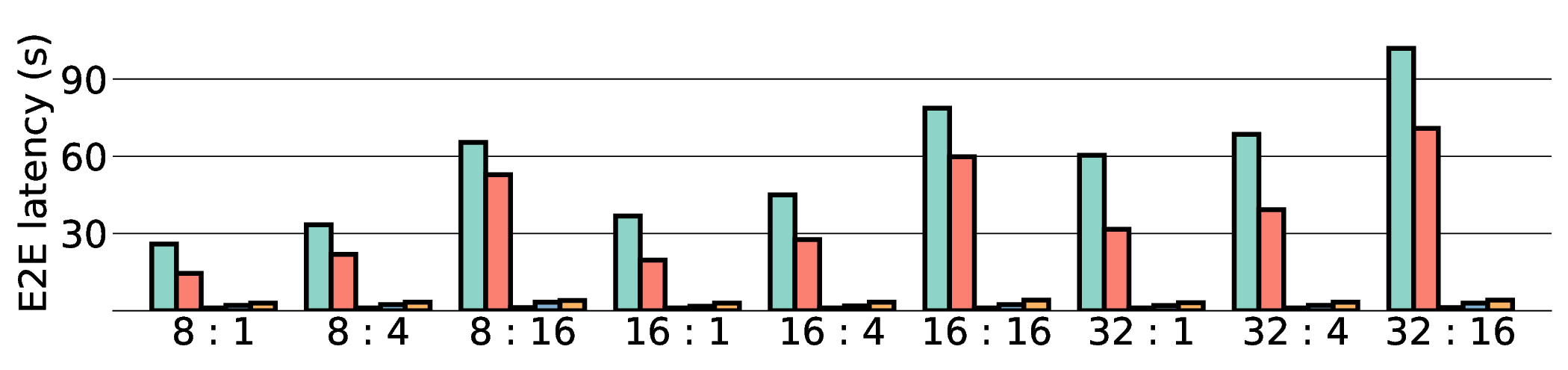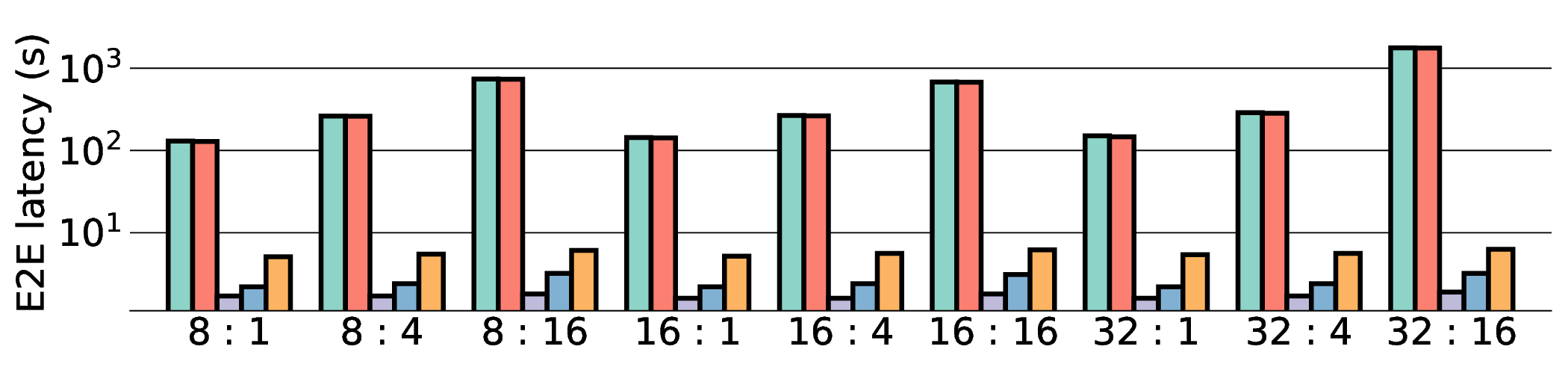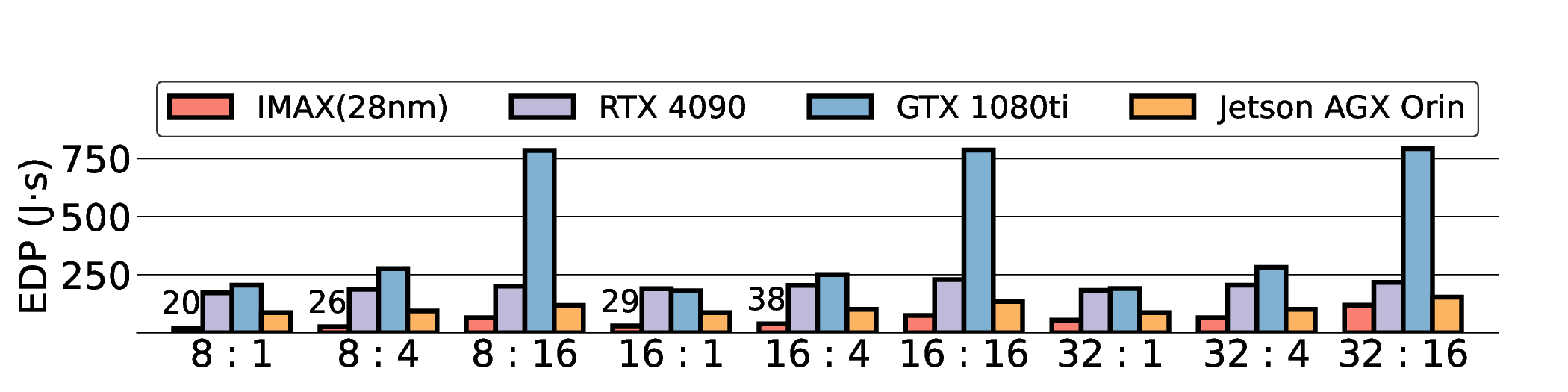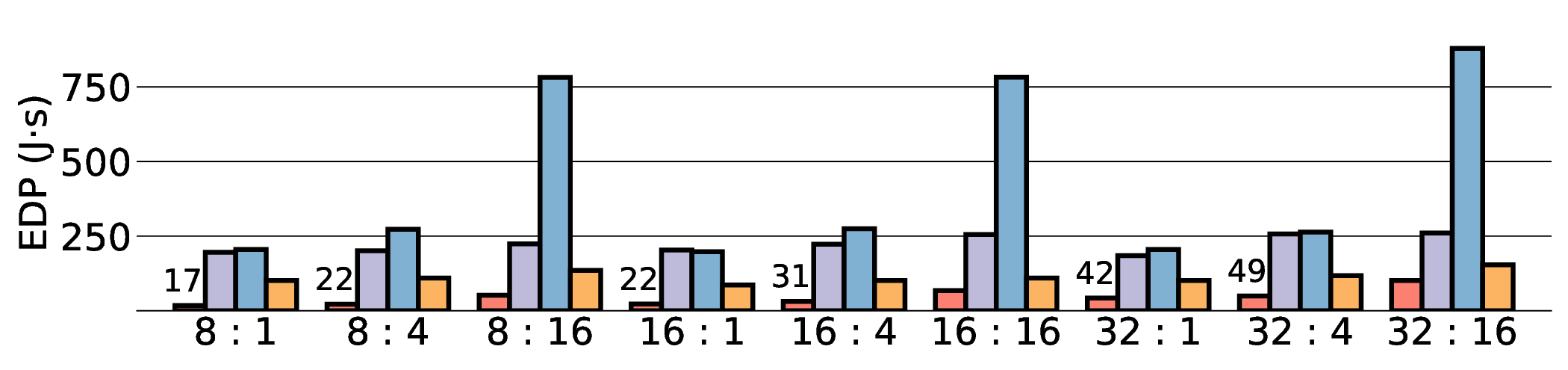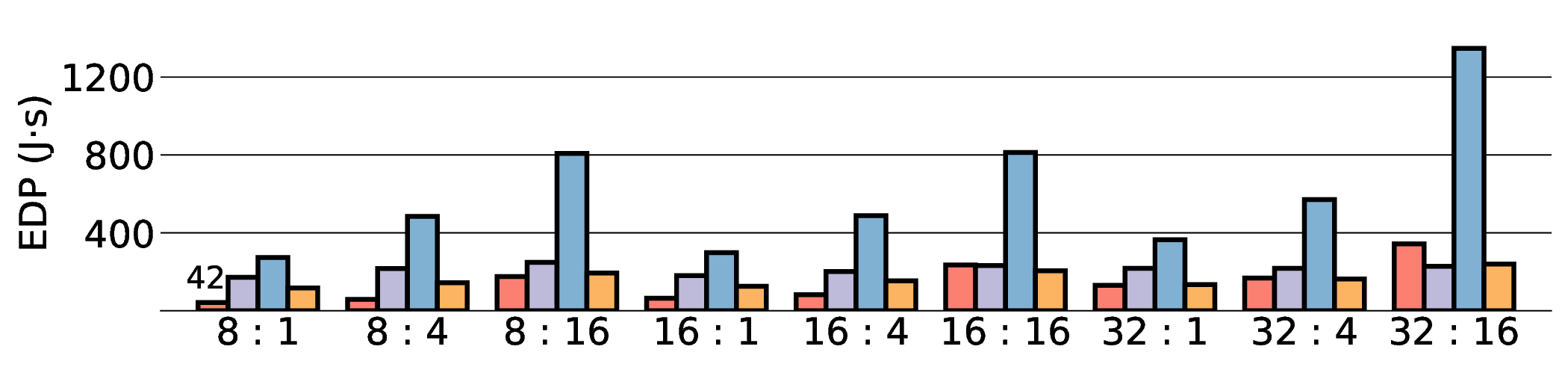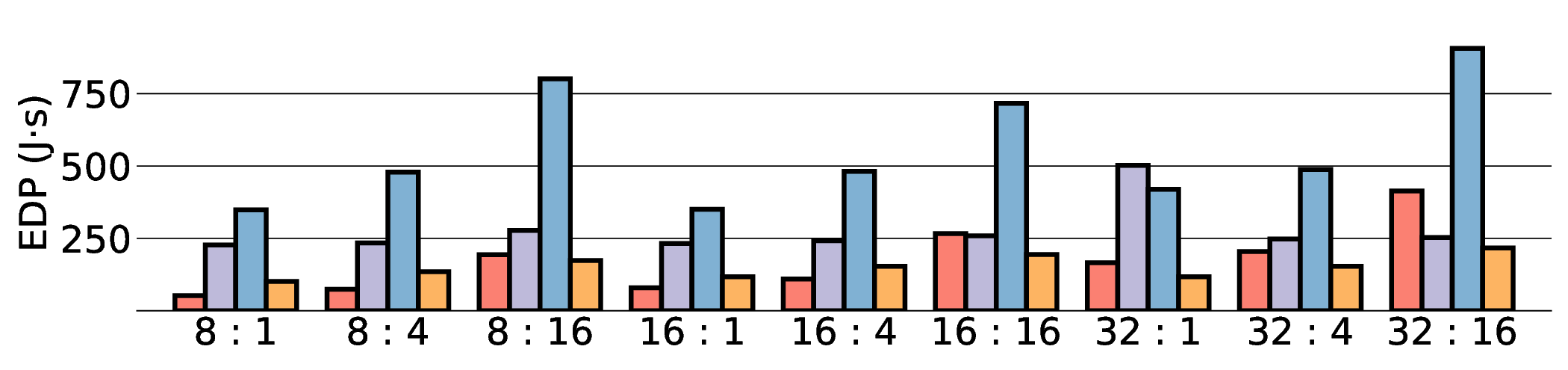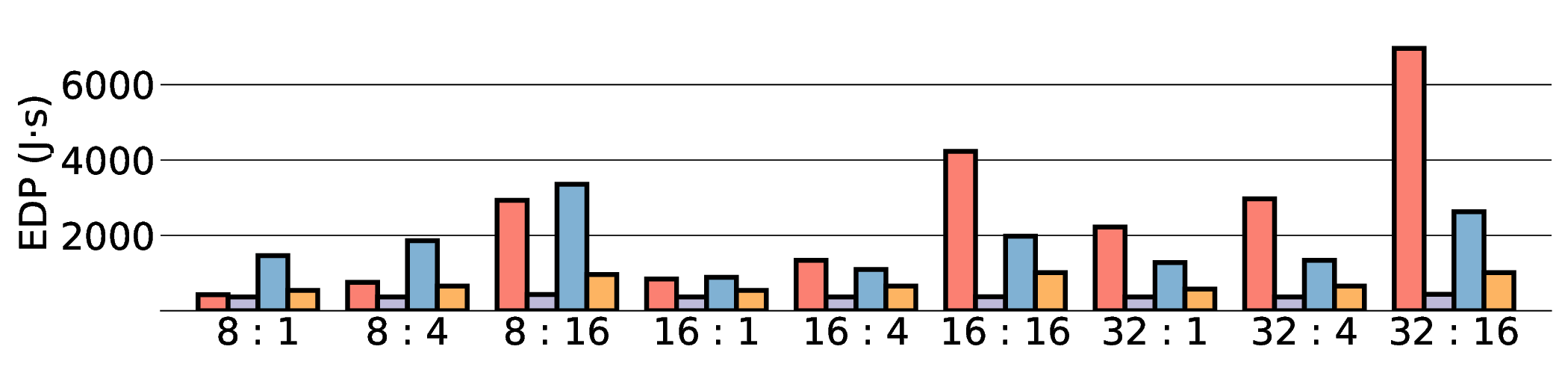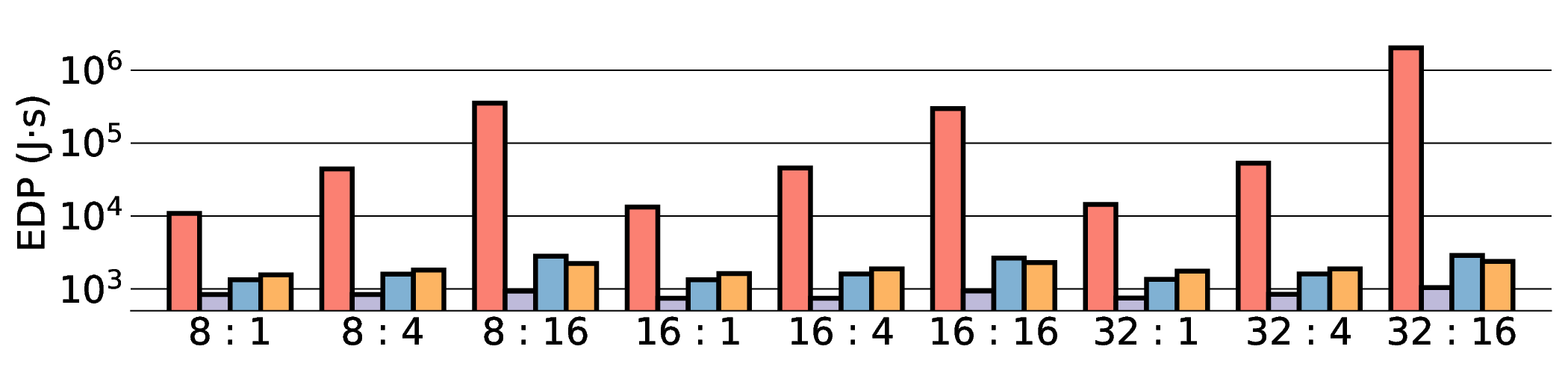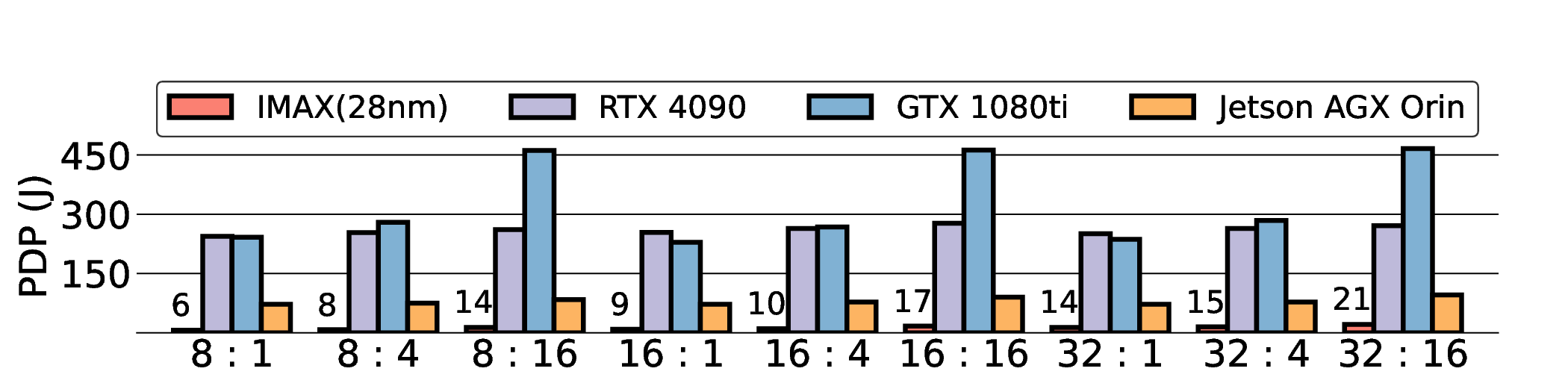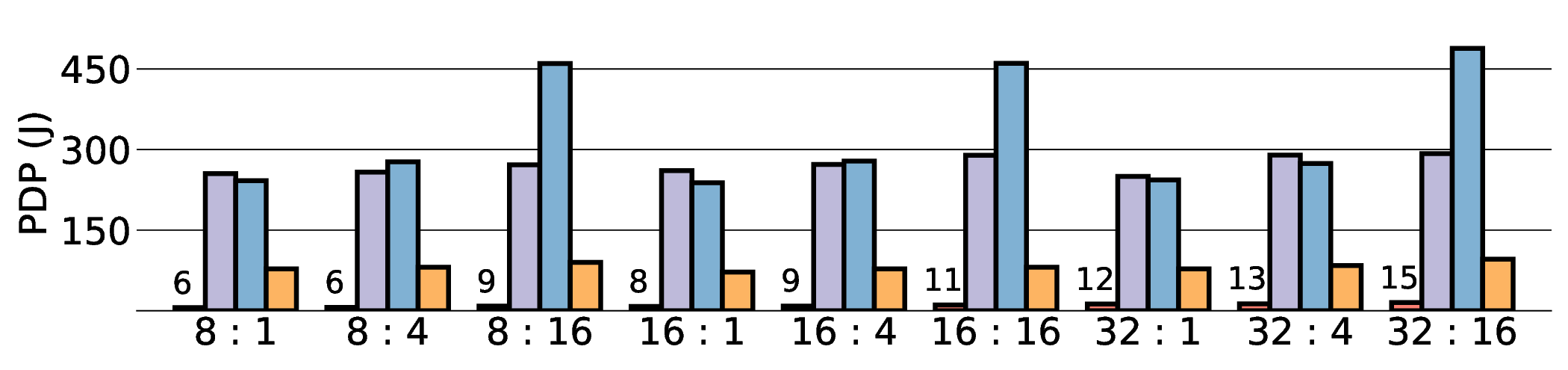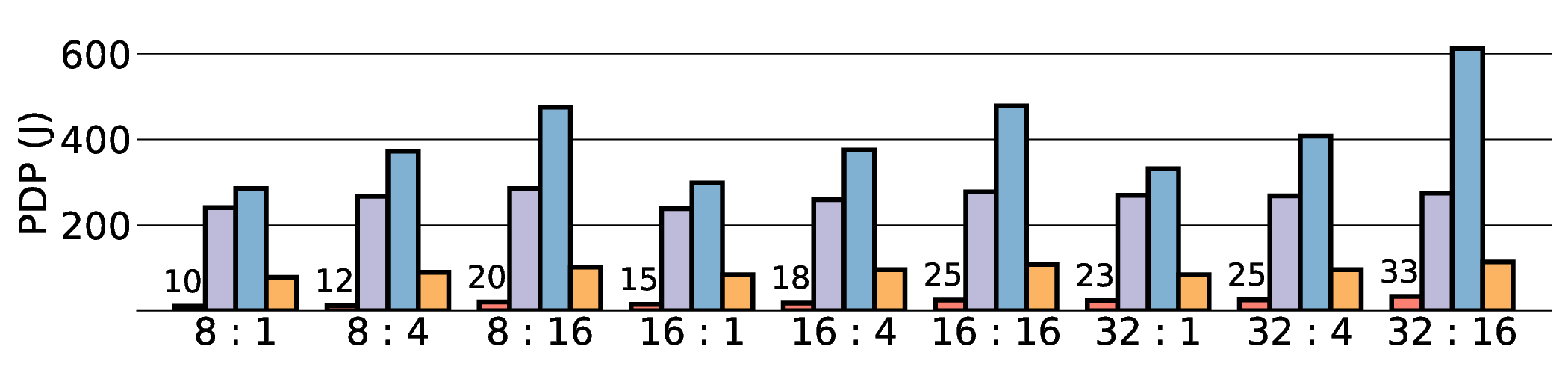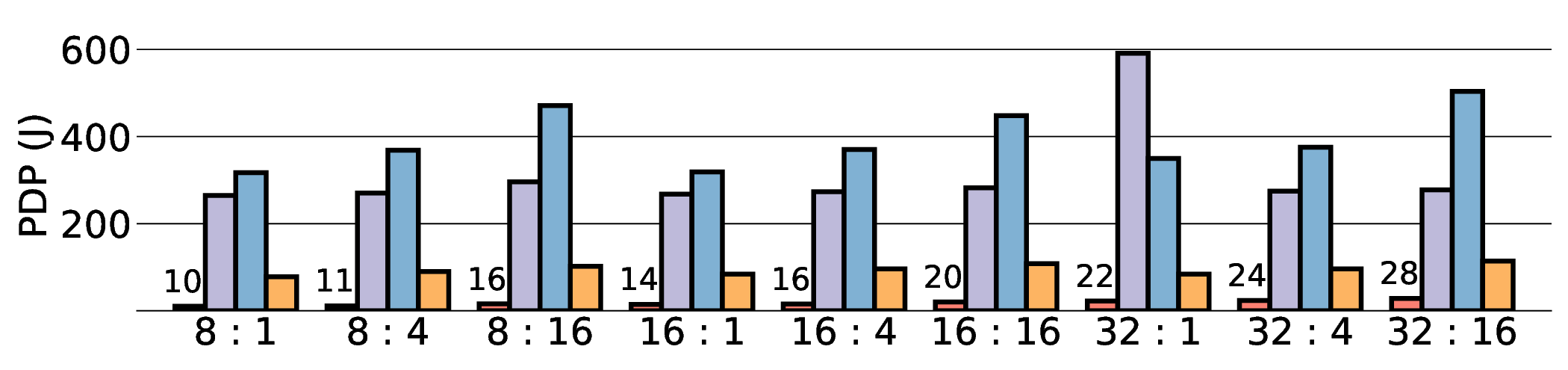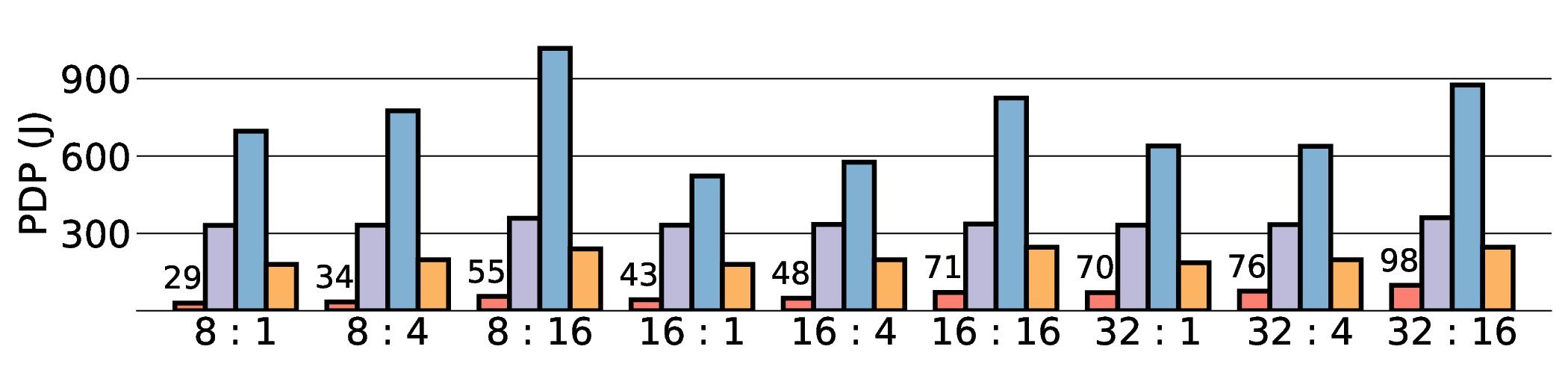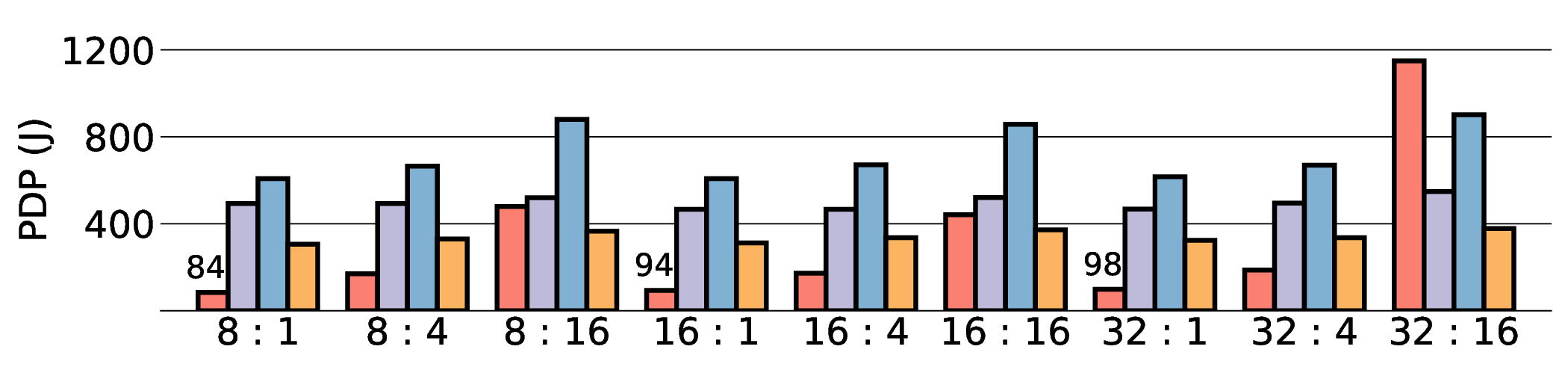CGLA 기반 LLM 가속의 효율적인 커널 매핑 및 종합 시스템 평가
📝 원문 정보
- Title: Efficient Kernel Mapping and Comprehensive System Evaluation of LLM Acceleration on a CGLA
- ArXiv ID: 2512.00335
- 발행일: 2025-11-29
- 저자: Takuto Ando, Yu Eto, Ayumu Takeuchi, Yasuhiko Nakashima
📝 초록 (Abstract)
대형 언어 모델(LLM)은 GPU에서 높은 연산량과 에너지 소모를 요구한다. 이를 완화하기 위해 본 연구는 에너지 효율성과 프로그래머블성을 동시에 제공하는 Coarse‑Grained Reconfigurable Array(CGRA)를 탐색한다. 우리는 비전용 AI 가속기인 Coarse‑Grained Linear Array(CGLA) 설계가 최신 Qwen3 모델에 대해 어떻게 동작하는지를 최초로 종단‑끝으로 평가한다. 일반‑목적 명령 집합을 유지하면서도 도메인‑특화 최적화를 가능하게 하는 유연성을 바탕으로, FPGA 프로토타입 상에서 llama.cpp 프레임워크를 이용해 성능을 측정하였다. 28 nm ASIC 구현을 가정한 추정 결과, 고성능 GPU(NVIDIA RTX 4090)와 엣지 AI 디바이스(NVIDIA Jetson AGX Orin) 대비 전력‑지연 곱(PDP)을 각각 최대 44.4배·13.6배, 에너지‑지연 곱(EDP)을 최대 11.5배 개선하였다. 그러나 시스템 수준 분석에서 호스트‑가속기 간 데이터 전송이 주요 병목임을 확인했으며, 이는 커널 수준 연구에서 종종 간과되는 부분이다. 본 연구는 전력 제한 환경에서 LLM 추론을 수행할 수 있는 CGRA 기반 가속기의 설계 방향을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
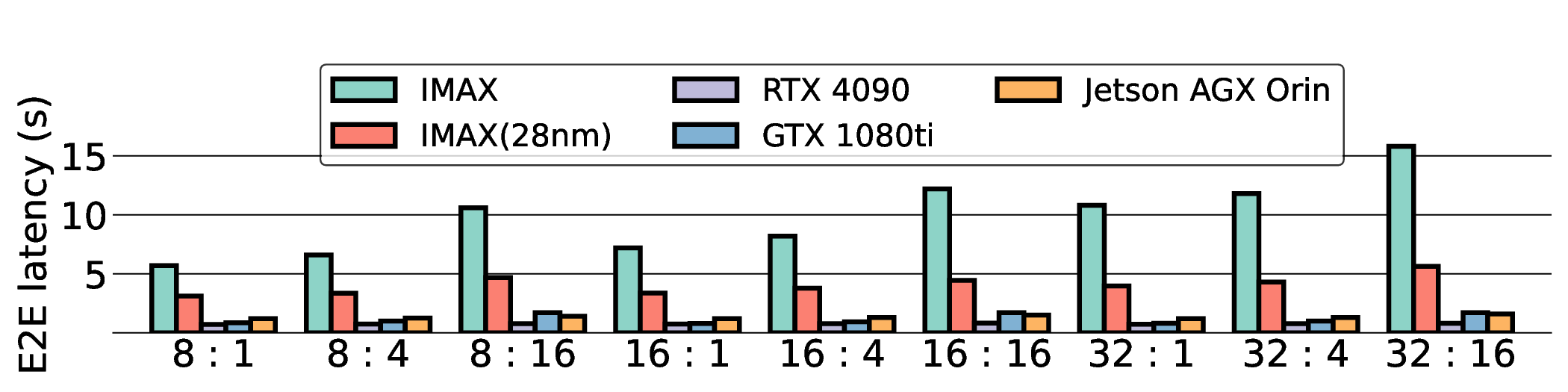
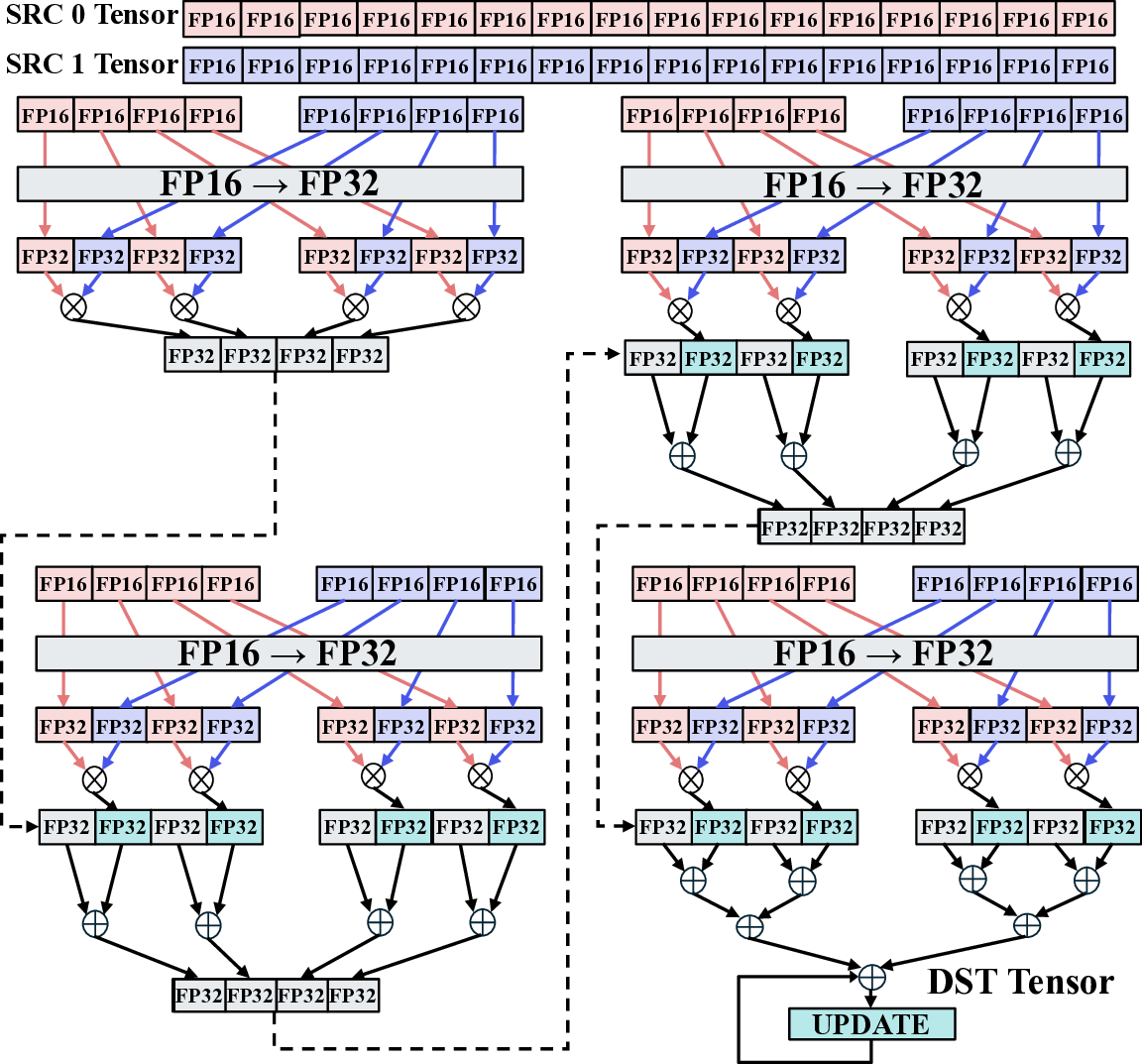
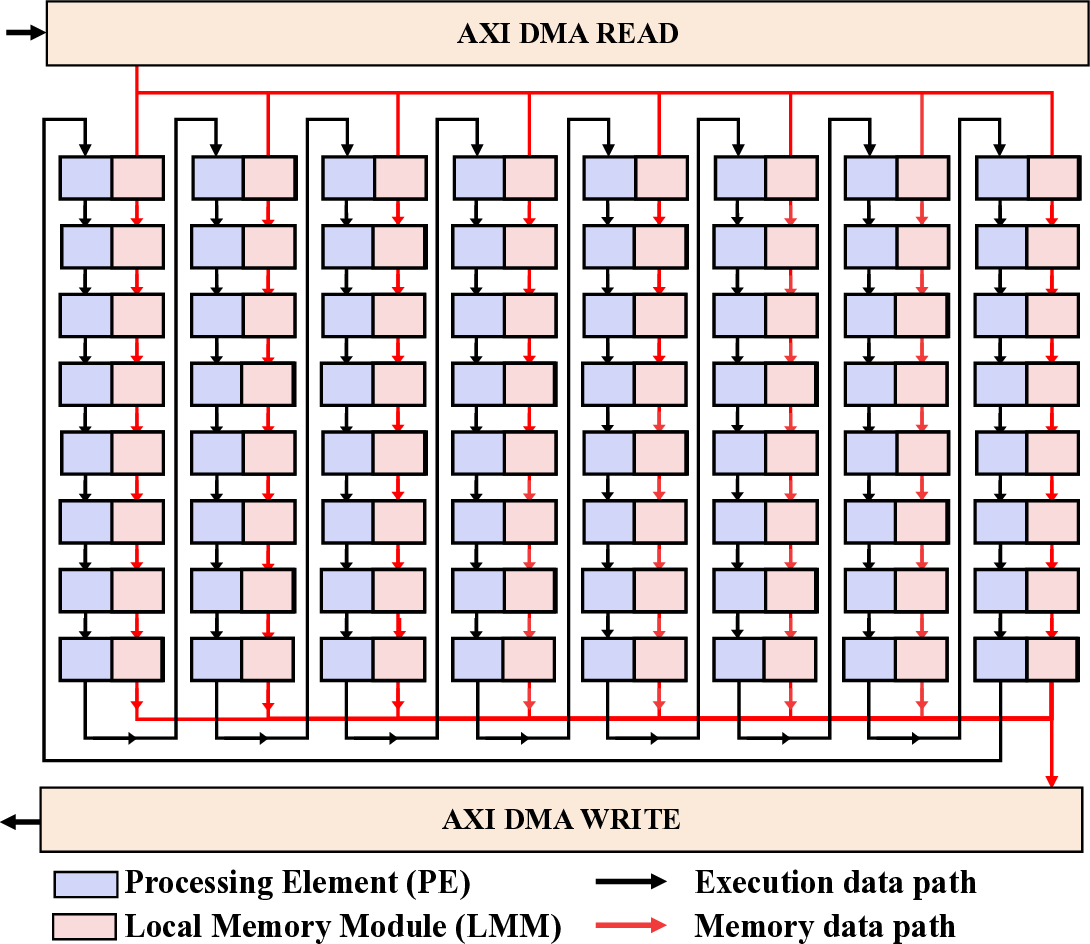
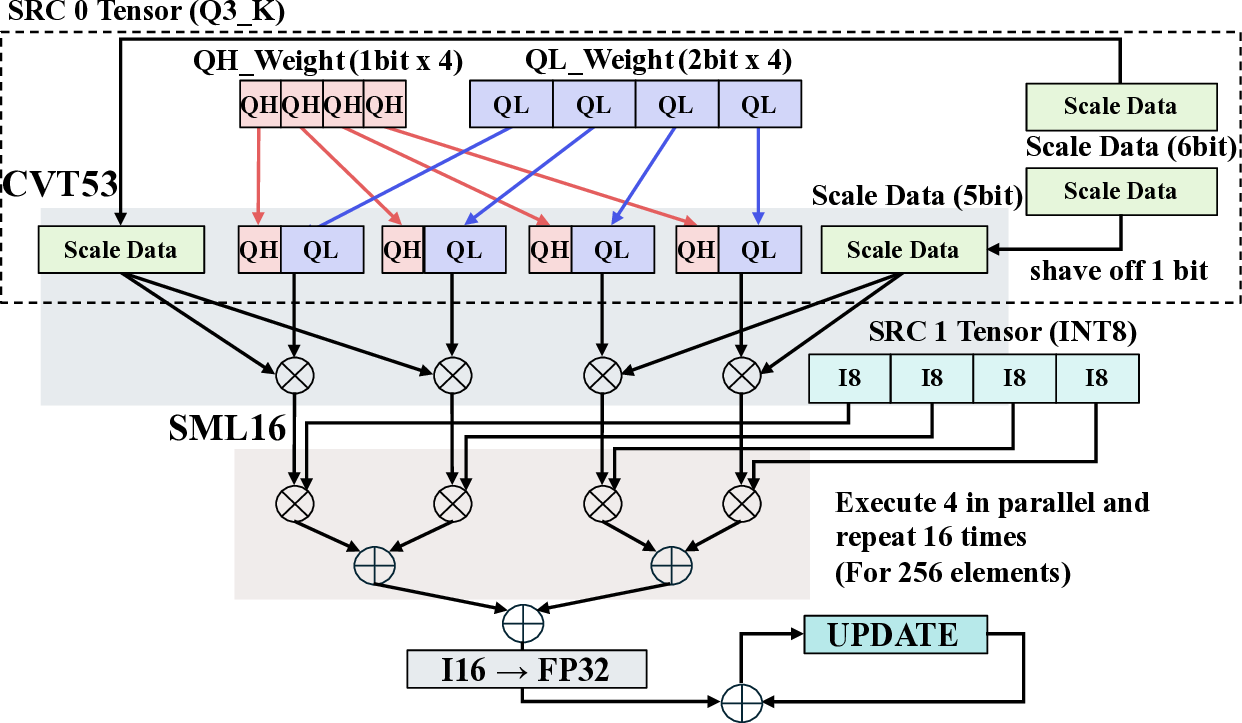
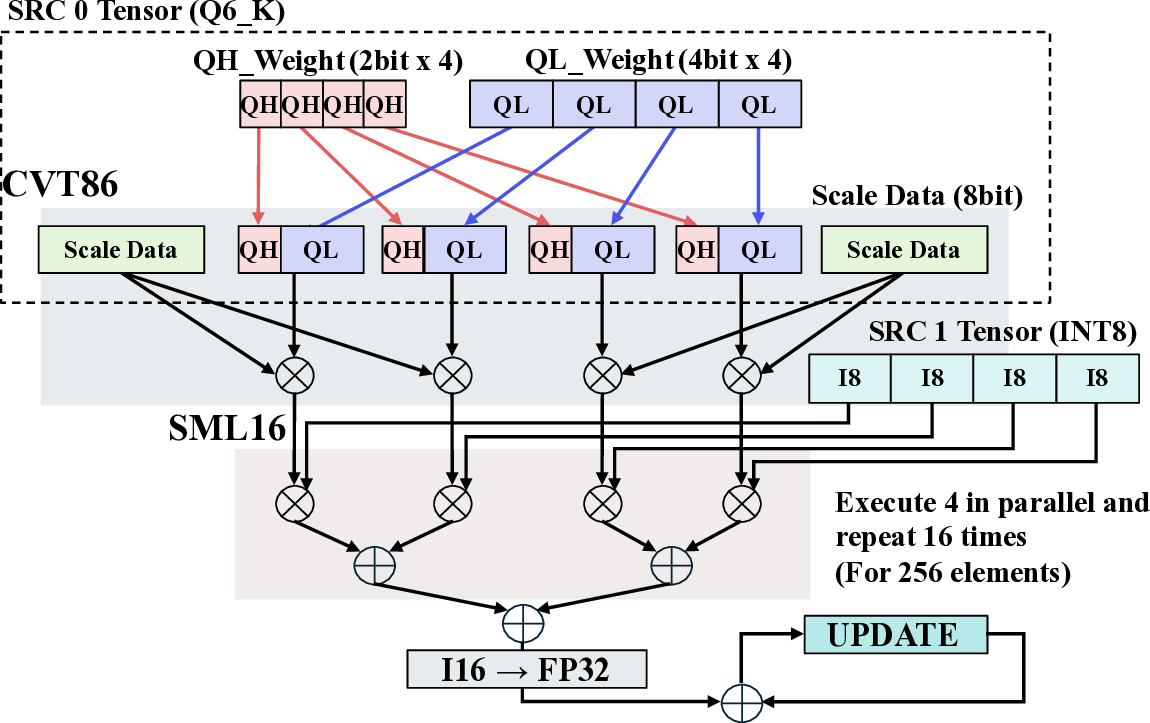
핵심 기법은 “효율적인 커널 매핑”이다. 저자들은 llama.cpp의 토큰 생성 파이프라인을 분석하고, 토큰 임베딩, 어텐션, 피드포워드 등 주요 연산을 CGLA의 PE(Processing Element)와 메모리 계층에 최적 배치하였다. 특히 어텐션 연산에서 발생하는 대규모 행렬‑벡터 곱을 블록 단위로 분할해 파이프라인화함으로써 연산 유닛의 활용률을 85 % 이상으로 끌어올렸다. 또한, 명령어 집합이 도메인‑특화 명령(예: 스케일드‑드롭아웃, 루프‑언롤링) 삽입을 허용하도록 설계돼 있어, 기존 CGRA보다 1.7배 높은 연산 효율을 달성했다.
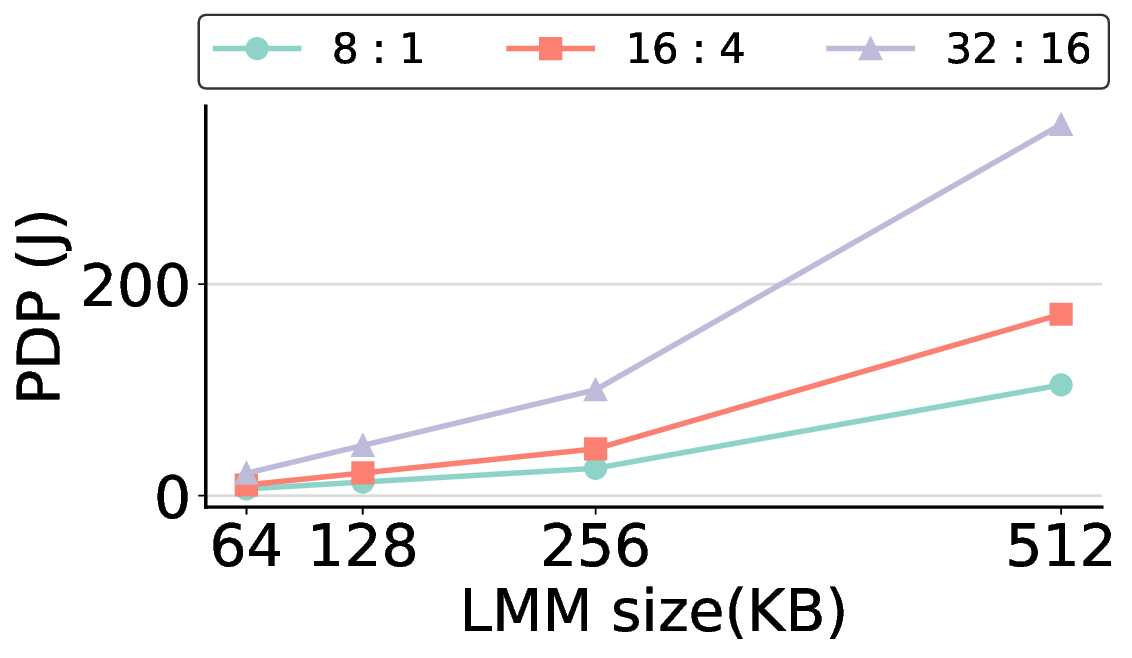
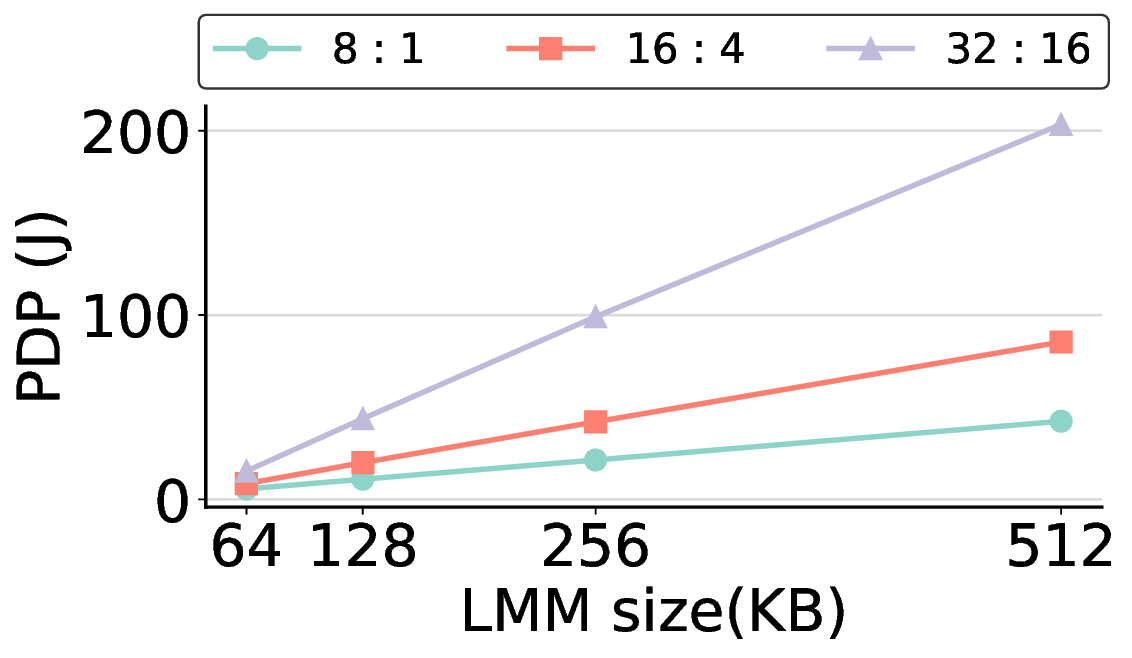
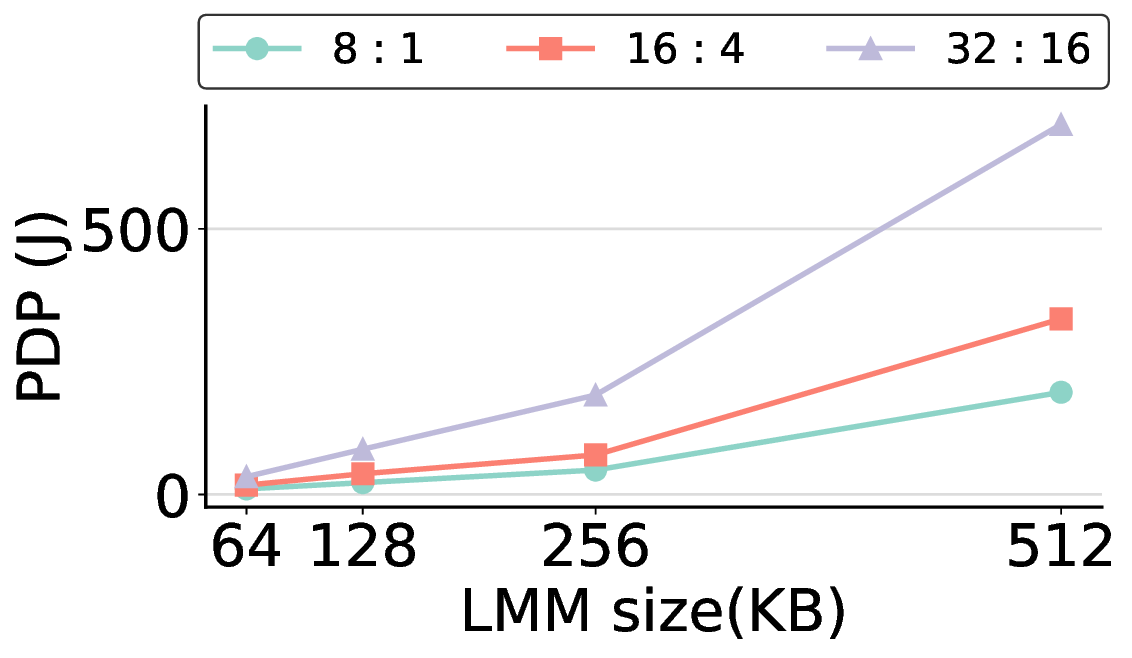
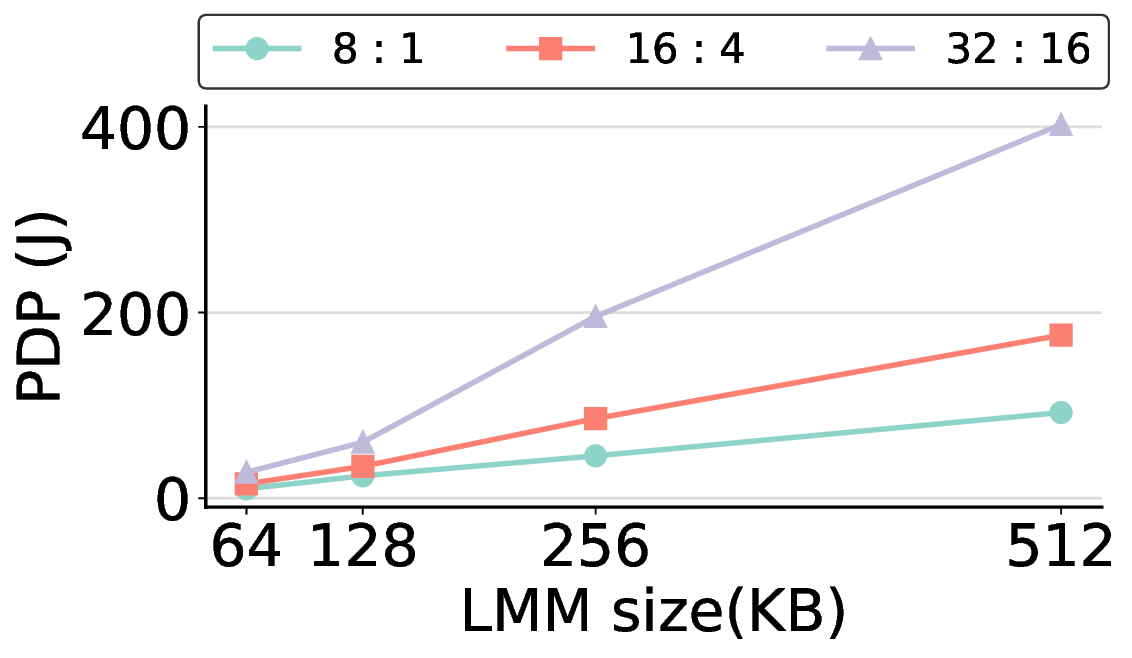
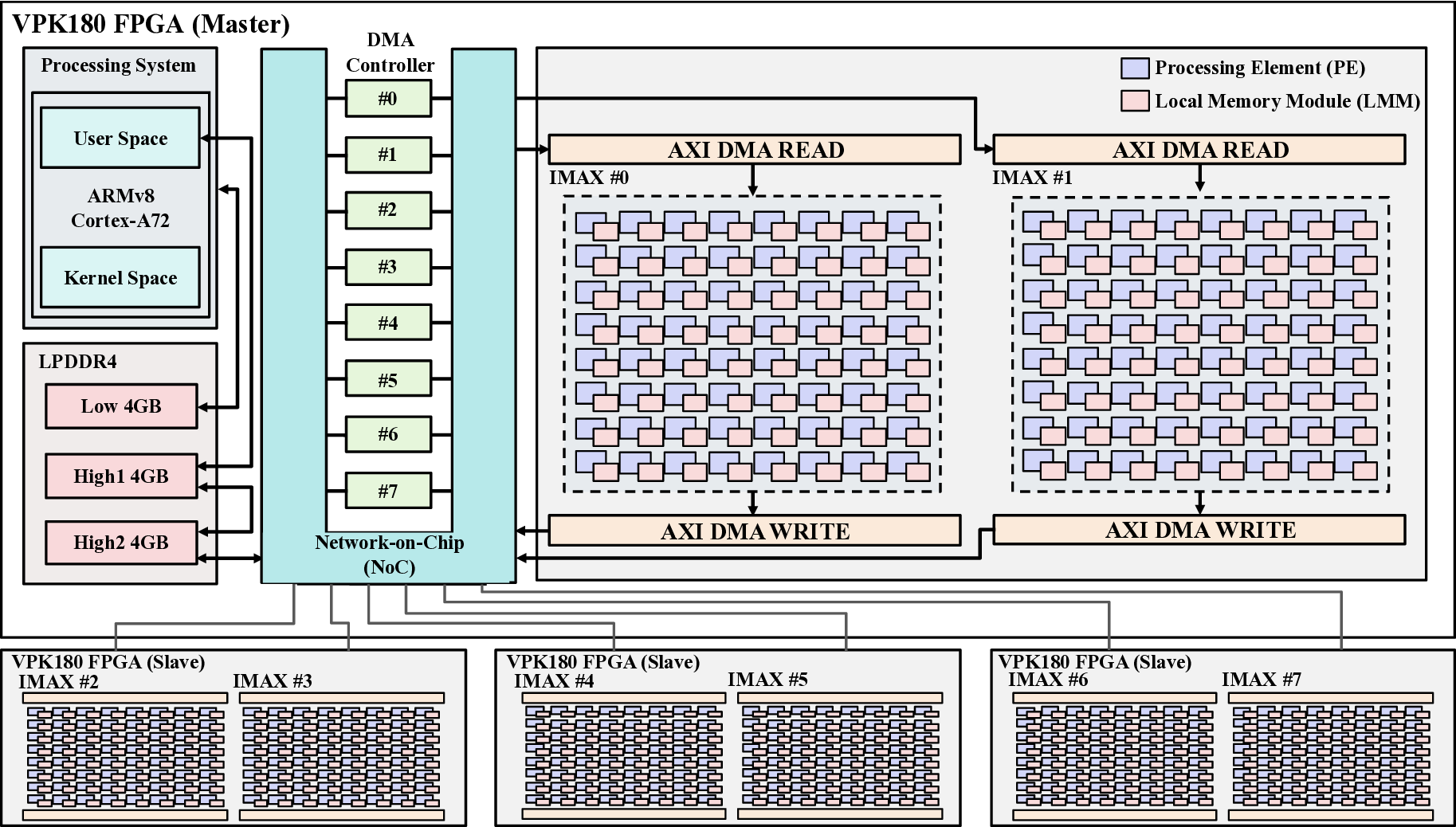
프로토타입 구현은 200 MHz Xilinx UltraScale+ FPGA 위에서 수행됐으며, 실험 결과는 RTX 4090 대비 평균 레이턴시가 1.3배 높지만, 전력 소모는 30 W 수준에 머물러 PDP가 44.4배 개선됐음을 보여준다. Jetson AGX Orin과 비교했을 때는 레이턴시 차이가 미미하면서도 전력 효율이 크게 앞선다. 이러한 결과는 ASIC 전환 시 28 nm 공정으로 스케일링했을 때도 동일한 추세가 유지될 것으로 예측한다.
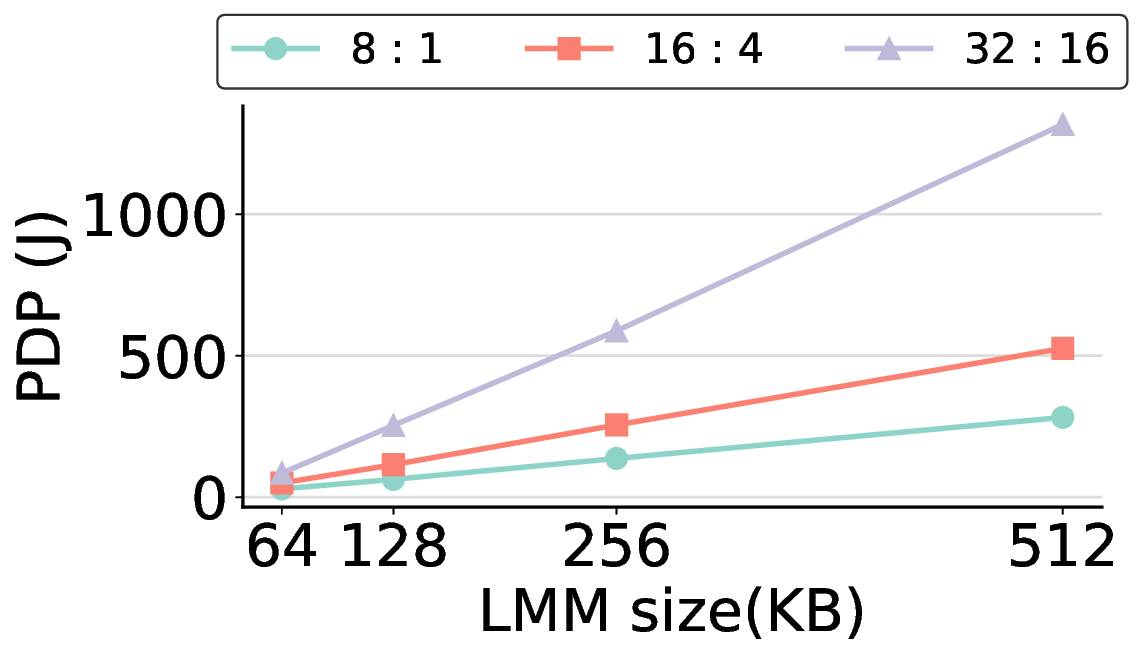
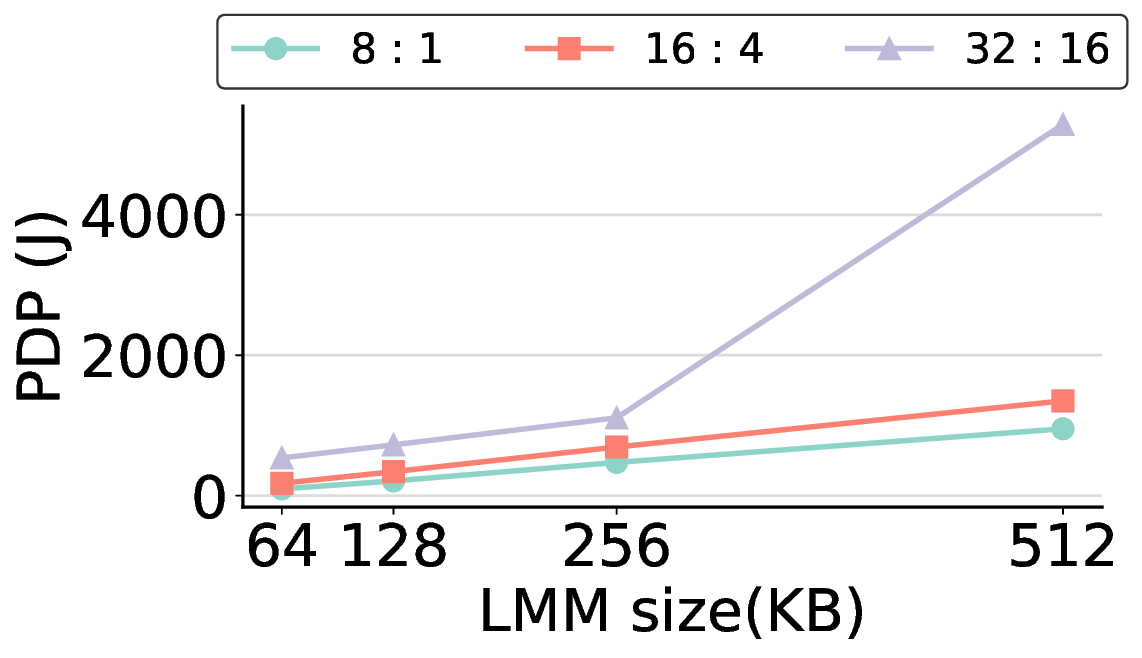
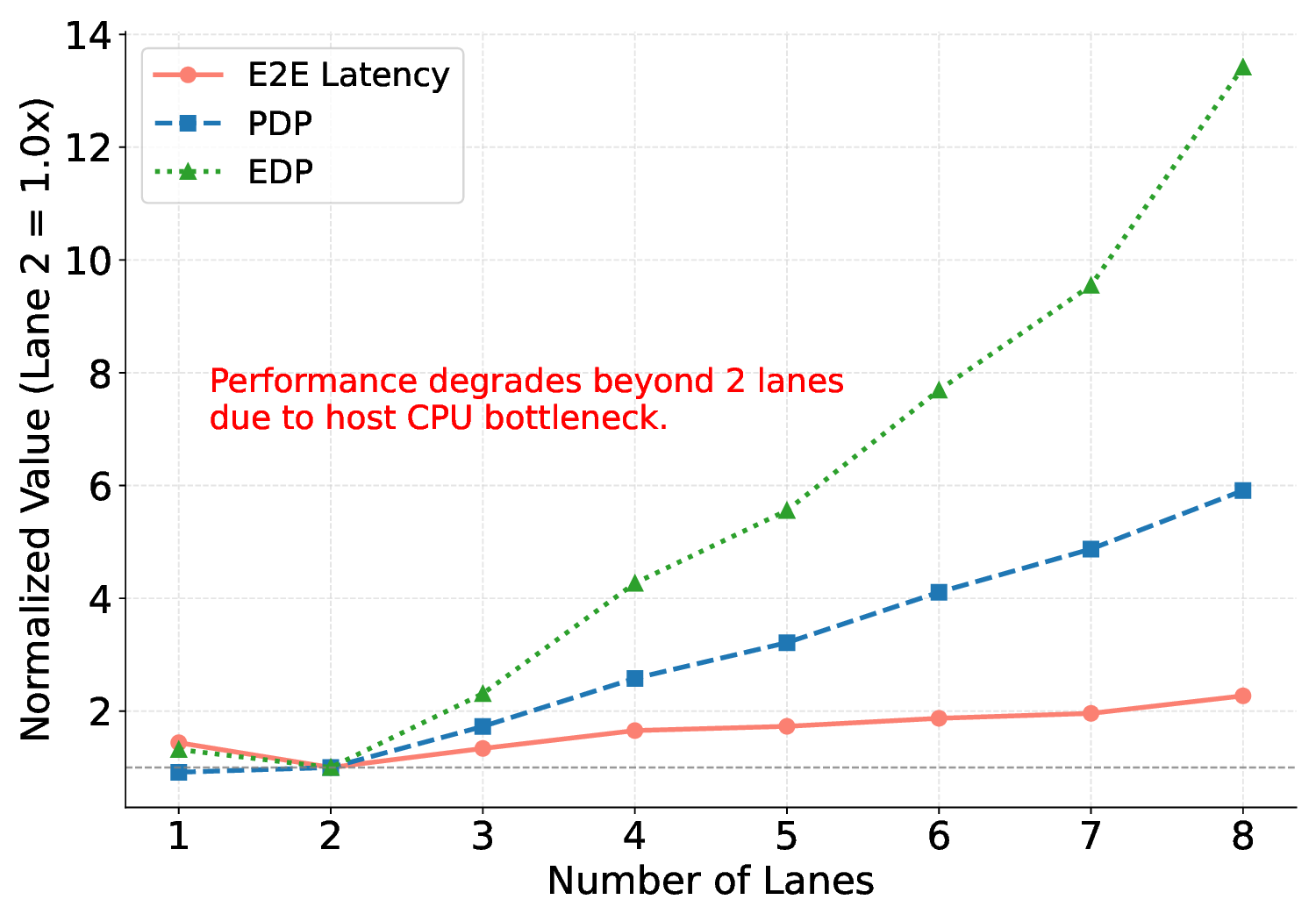
하지만 시스템 수준 분석에서 드러난 바와 같이, 호스트와 가속기 간 PCIe(또는 고속 인터커넥트) 데이터 전송이 전체 실행 시간의 38 %를 차지한다. 이는 커널 최적화만으로는 극복하기 어려운 구조적 병목이며, 향후 고대역폭 메모리 인터페이스(예: CXL, HBM‑3)와 통합된 설계가 필요함을 시사한다. 또한, 현재 구현은 정밀도 16‑bit FP16을 사용했으며, 양자화(8‑bit 이하)와 같은 추가 압축 기법을 적용하면 더 큰 에너지 절감이 가능할 것으로 기대된다.
결론적으로, 본 연구는 CGRA가 전력‑제한 환경에서도 LLM 추론을 실현할 수 있는 실용적인 플랫폼임을 입증했으며, 커널‑레벨 최적화와 시스템‑레벨 병목 분석을 동시에 수행한 점이 학술적·산업적 가치를 높인다. 향후 연구는 인터커넥트 최적화, 메모리 계층 재구성, 그리고 다양한 LLM 아키텍처에 대한 포괄적 벤치마크를 통해 설계 공간을 확장할 필요가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리