기계 학습 삭제의 프라이버시 위협과 텔레포테이션 방어: WARP의 실효성 분석
📝 원문 정보
- Title: Teleportation-Based Defenses for Privacy in Approximate Machine Unlearning
- ArXiv ID: 2512.00272
- 발행일: 2025-11-29
- 저자: Mohammad M Maheri, Xavier Cadet, Peter Chin, Hamed Haddadi
📝 초록 (Abstract)
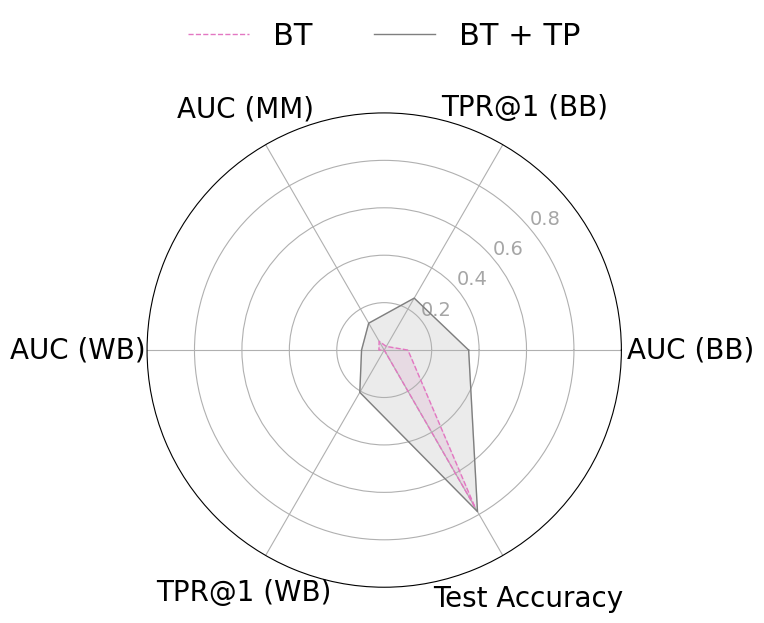
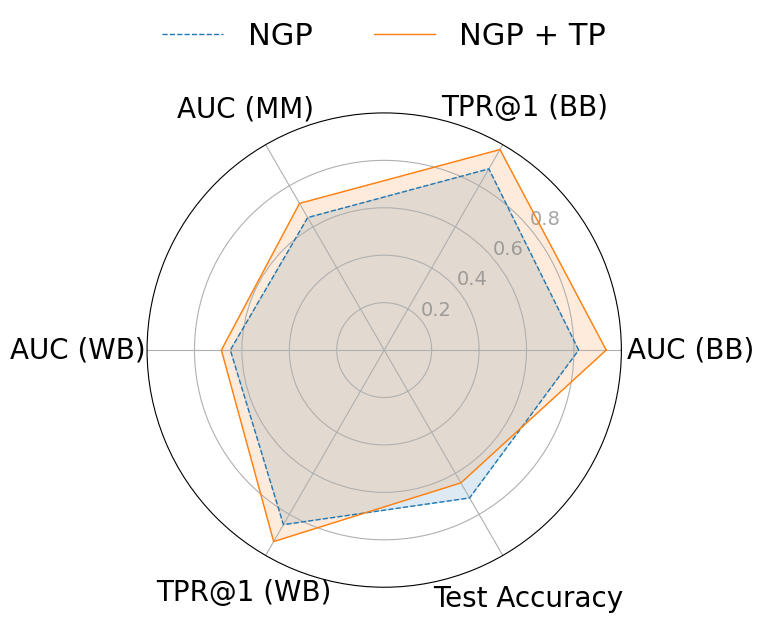
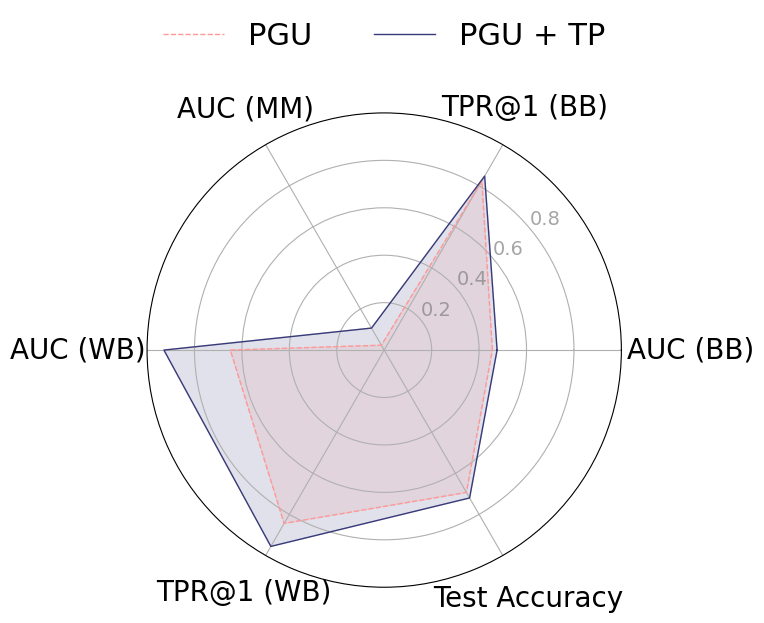
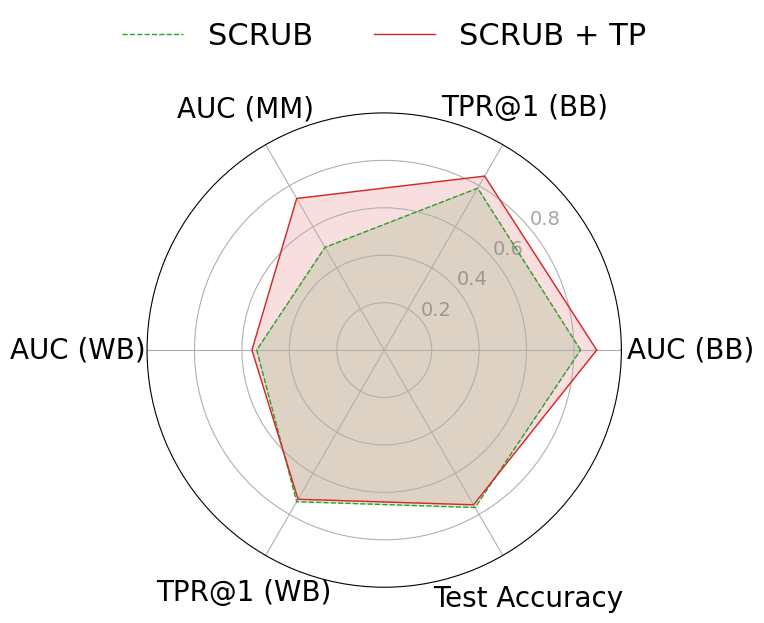
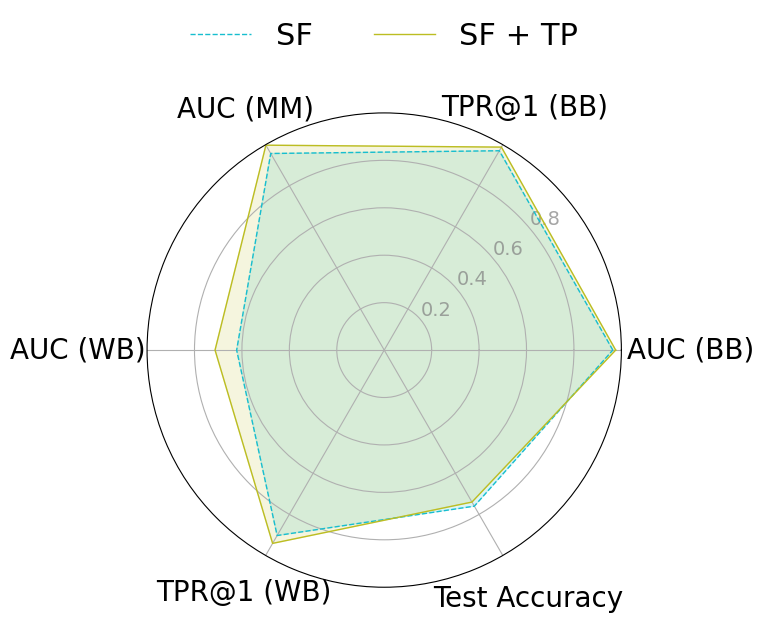
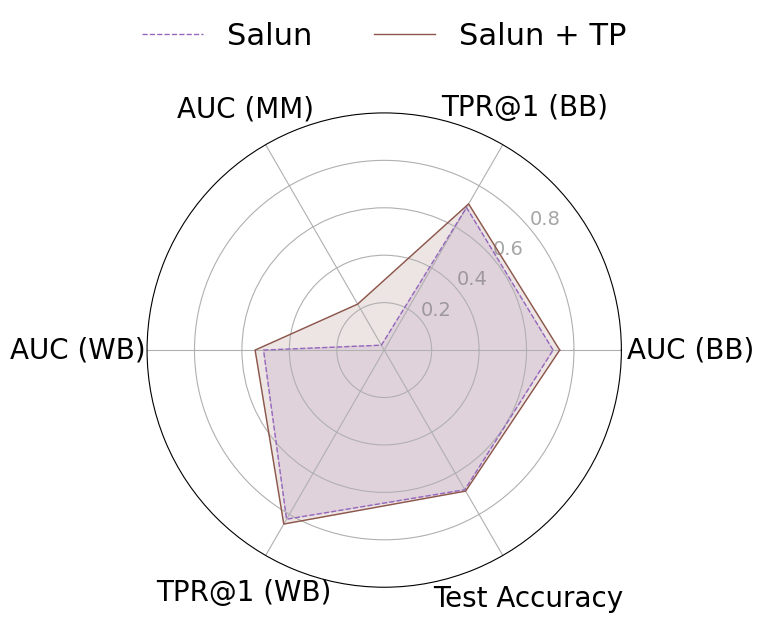
근사 기계 삭제(approximate machine unlearning)는 훈련된 모델에서 특정 데이터 포인트의 영향을 효율적으로 제거함으로써 전체 재학습 없이도 실용적인 대안을 제공한다. 그러나 삭제 전후 모델에 접근할 수 있는 공격자는 두 모델 간 차이를 이용해 멤버십 추론이나 데이터 복원을 수행할 수 있는 프라이버시 위험을 초래한다. 본 연구는 이러한 취약성이 (1) 삭제 대상 샘플의 큰 그래디언트 크기와 (2) 삭제된 파라미터가 원래 모델과 매우 근접해 있다는 두 요인에서 비롯된다는 점을 밝힌다. 이를 입증하기 위해 삭제 전용 멤버십 추론 및 복원 공격을 설계했으며, NGP, SCRUB 등 최신 삭제 기법도 여전히 공격에 취약함을 실험적으로 확인하였다. 이러한 누수를 완화하기 위해 우리는 WARP라는 플러그‑인 텔레포테이션 방어를 제안한다. WARP는 신경망의 대칭성을 활용해 삭제 대상 샘플의 그래디언트 에너지를 감소시키고 파라미터를 원 모델에서 더 멀리 분산시켜 예측 성능은 유지하면서도 삭제 신호를 은폐한다. 6가지 삭제 알고리즘에 걸쳐 WARP를 적용한 결과, 블랙박스 환경에서 공격자의 AUC를 최대 64 %, 화이트박스 환경에서는 최대 92 %까지 낮출 수 있었으며, 보존 데이터에 대한 정확도는 거의 변하지 않았다. 이 연구는 텔레포테이션이 근사 삭제에서 프라이버시 보호를 강화하는 일반적인 도구임을 입증한다.💡 논문 핵심 해설 (Deep Analysis)

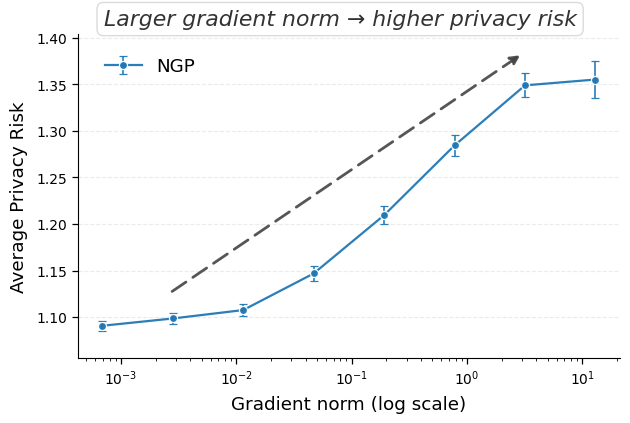
하지만 본 논문이 지적하듯, 근사 삭제는 두 가지 구조적 특성 때문에 프라이버시 위험을 내포한다. 첫째, 삭제 대상 샘플은 일반적으로 손실 함수에 큰 기여를 하며, 따라서 그에 대응하는 그래디언트의 L2 노름이 크다. 이는 모델 파라미터가 해당 샘플의 특성을 강하게 반영한다는 의미이며, 삭제 전후 파라미터 차이가 샘플의 존재 여부를 암시하게 만든다. 둘째, 근사 삭제는 파라미터를 원본 모델과 매우 가깝게 유지하려는 설계 목표가 있다. 즉, 파라미터 공간에서의 이동 거리가 작을수록 모델 성능 저하를 최소화할 수 있지만, 동시에 공격자는 두 모델 간 미세한 차이를 정밀히 측정함으로써 삭제된 샘플을 역추적할 수 있다.
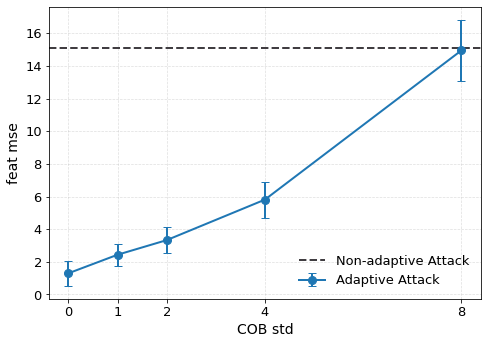
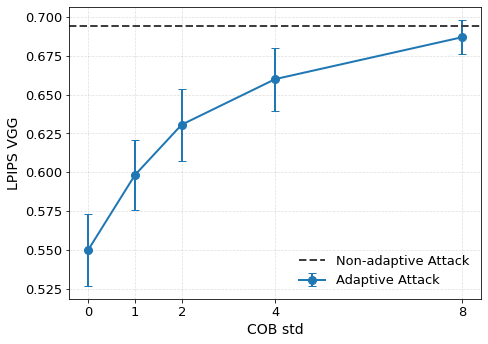
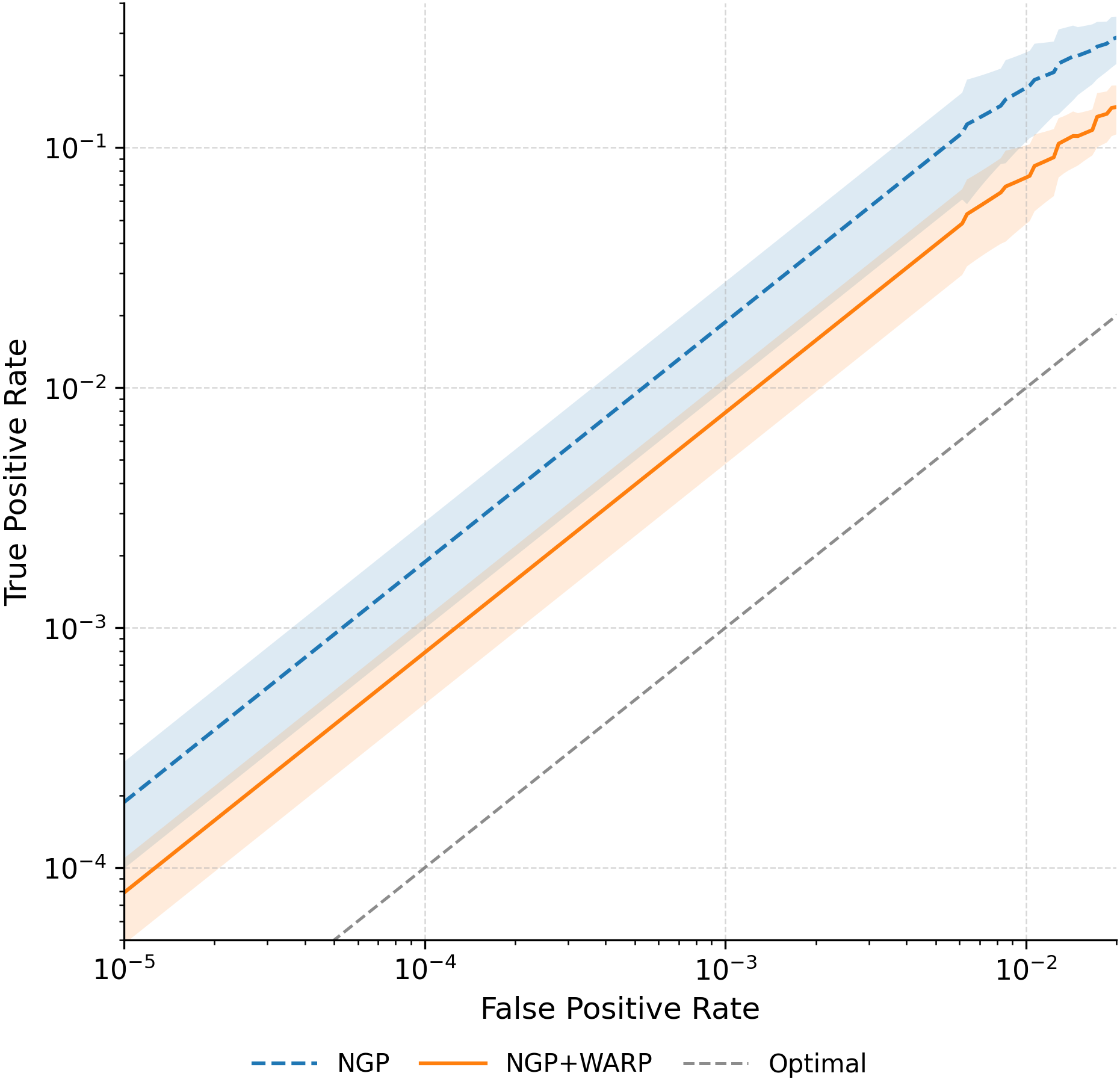
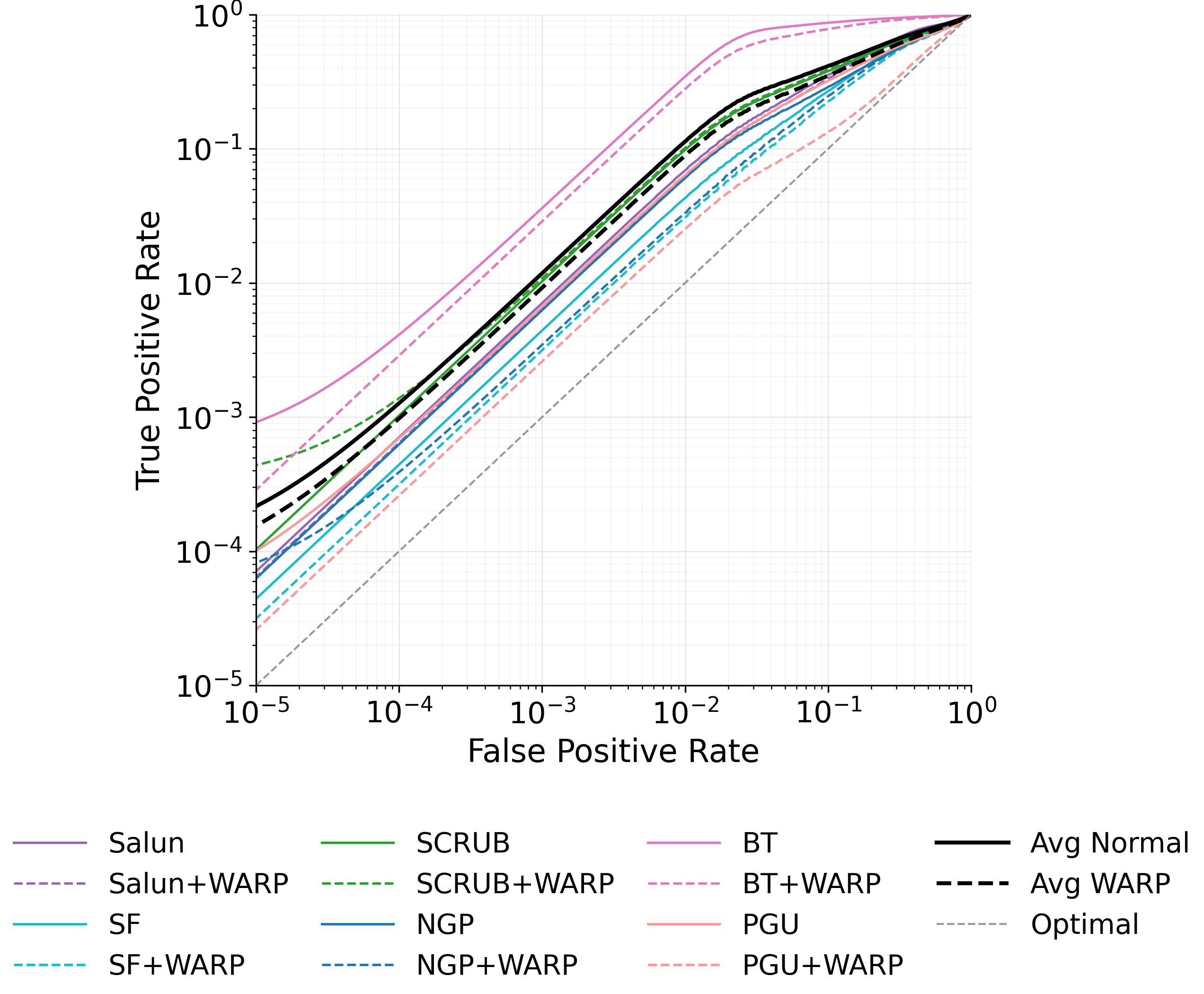
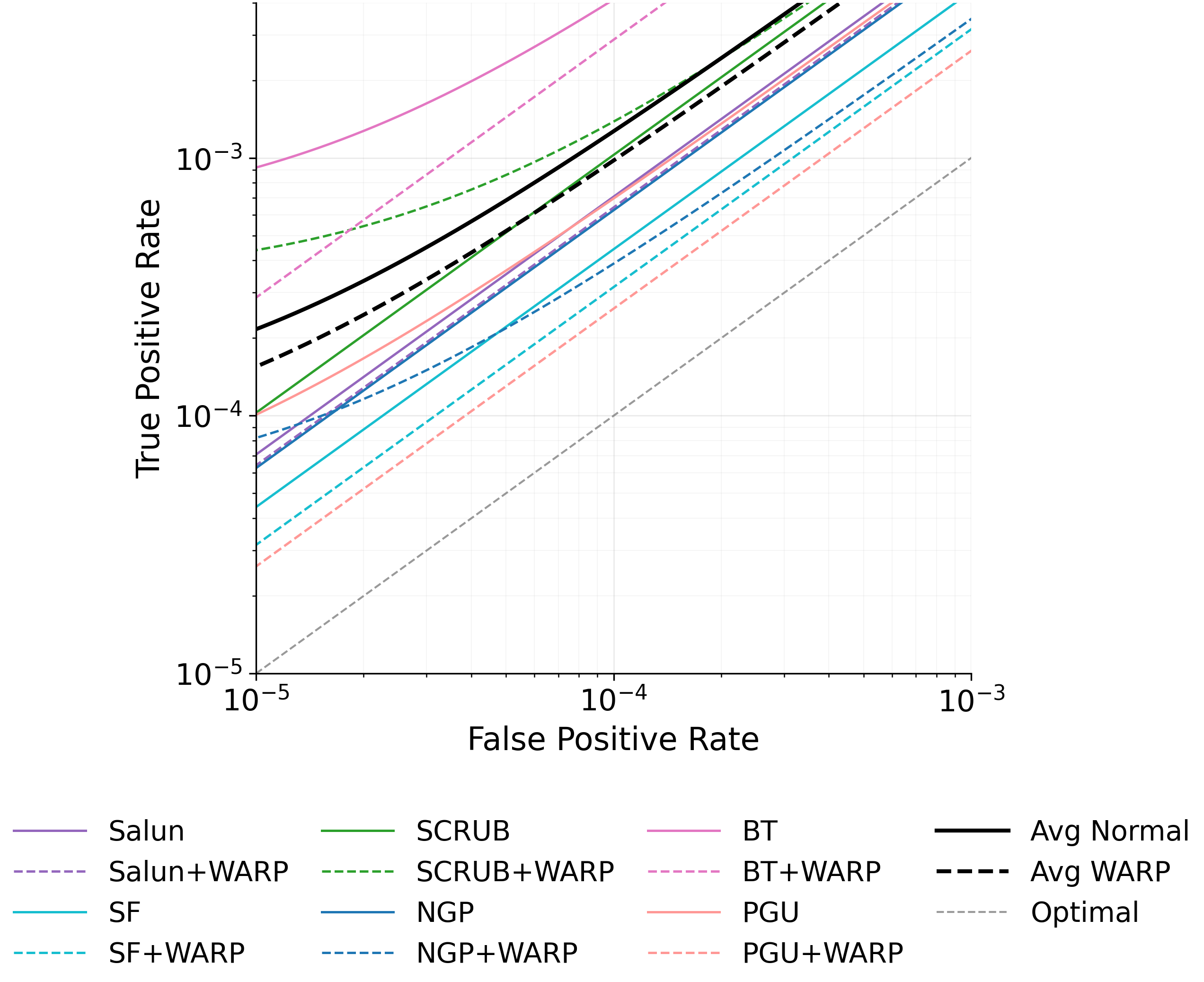
이러한 취약성을 이용한 공격은 크게 두 가지 형태로 구분된다. 멤버십 추론 공격은 삭제 전후 모델의 출력(또는 내부 활성화)을 비교해 특정 샘플이 삭제 대상인지 여부를 판단한다. 특히 화이트박스 상황에서는 파라미터 자체를 직접 비교함으로써 높은 정확도를 달성한다. 복원 공격은 삭제 대상 샘플의 그래디언트를 역전시켜 원본 입력을 재구성한다. 논문에서는 기존 최첨단 삭제 기법인 NGP와 SCRUB을 대상으로 실험했으며, 두 기법 모두 공격 성공률이 여전히 높아 실용적인 프라이버시 보호가 부족함을 보여준다.
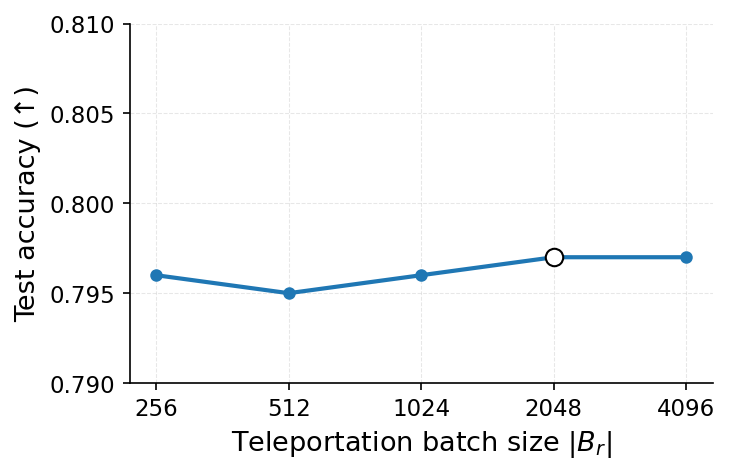
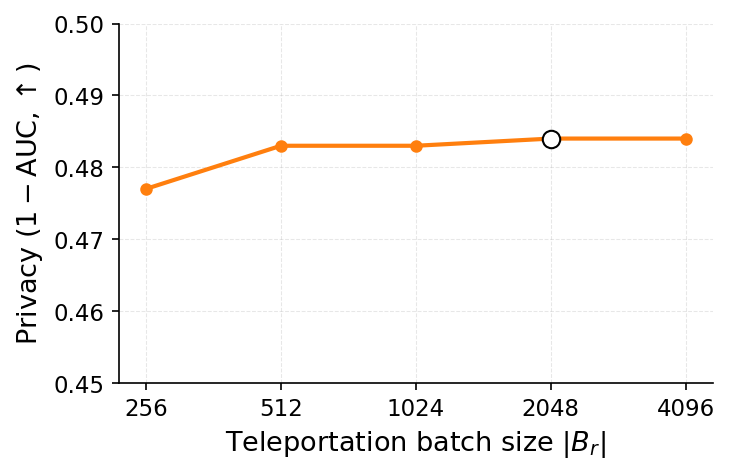
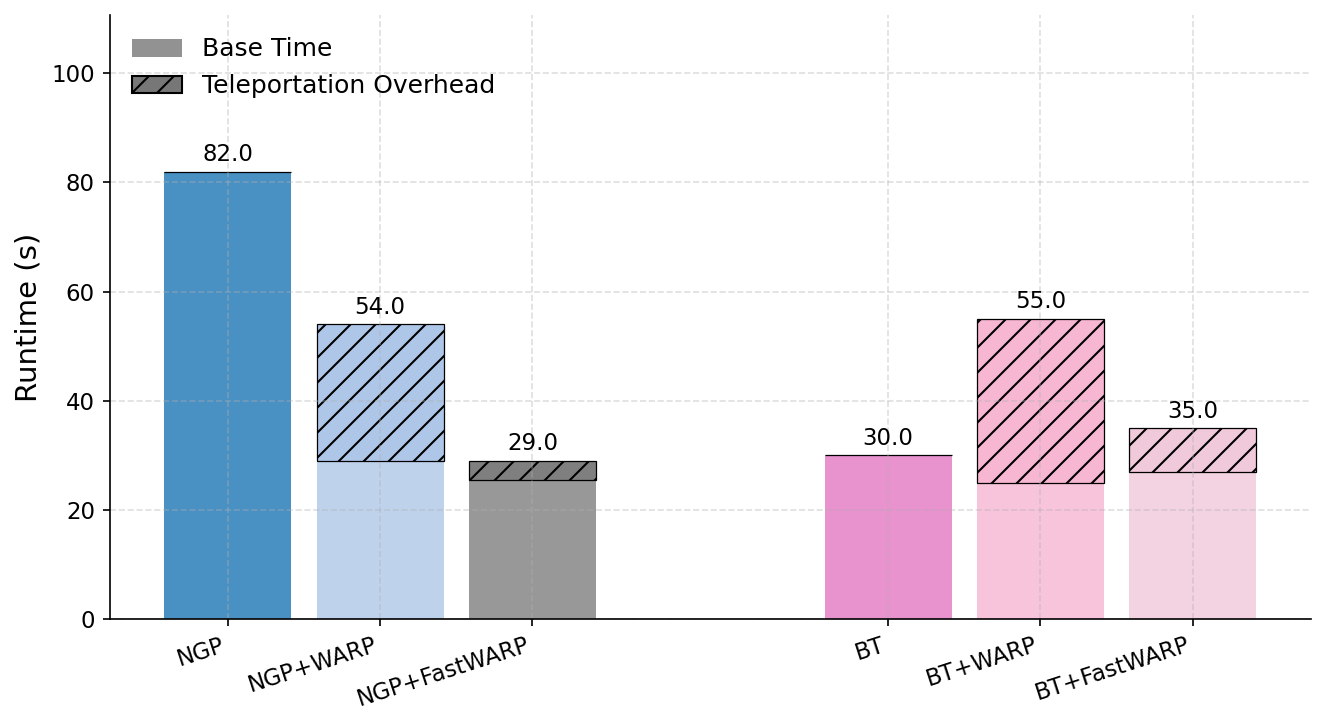
이를 해결하기 위해 제안된 WARP(Weight Aware Re‑parameterization via Teleportation)는 ‘텔레포테이션’이라는 새로운 재파라미터화 방식을 도입한다. 핵심 아이디어는 신경망이 갖는 대칭성(예: 가중치 행렬의 행·열 교환, 스케일 변환 등)을 활용해 파라미터를 동일한 함수적 동등성을 유지하면서도 파라미터 공간에서 멀리 이동시키는 것이다. 구체적으로, WARP는 (1) 삭제 대상 샘플에 대한 그래디언트 에너지를 감소시키는 정규화 항을 추가하고, (2) 파라미터를 대칭 변환을 통해 ‘텔레포트’시켜 원본 파라미터와의 거리를 인위적으로 확대한다. 이렇게 하면 삭제된 샘플이 모델에 남긴 신호가 약해져 공격자가 차이를 감지하기 어려워진다.
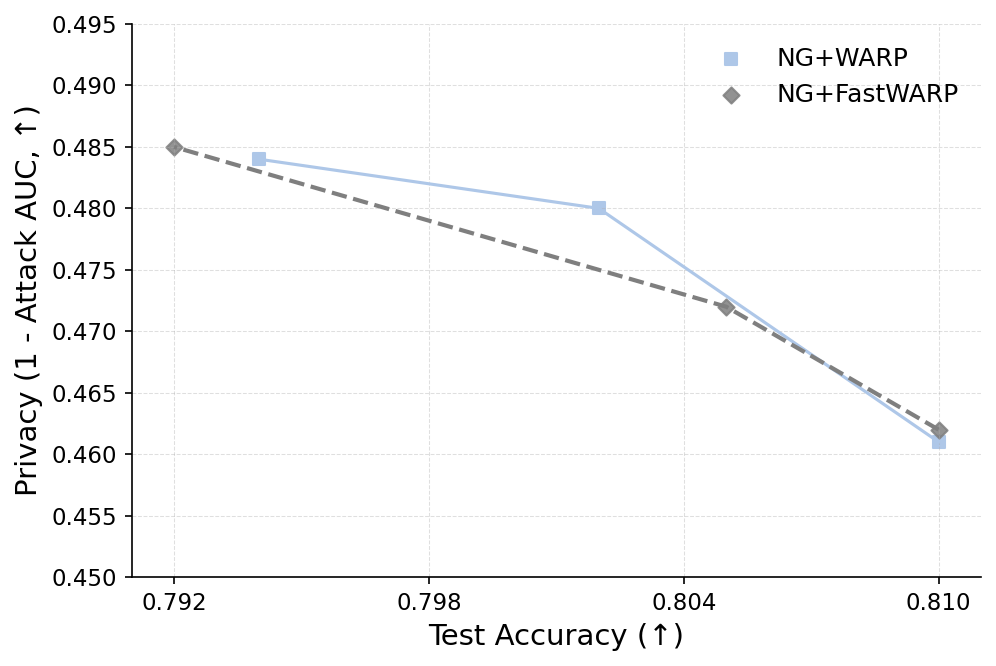
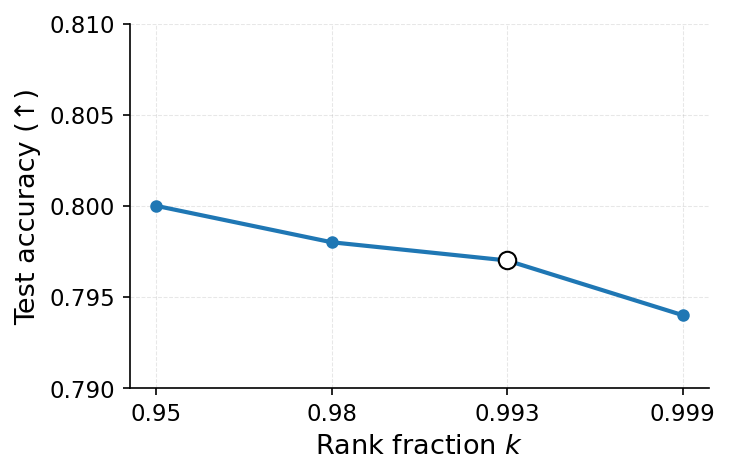
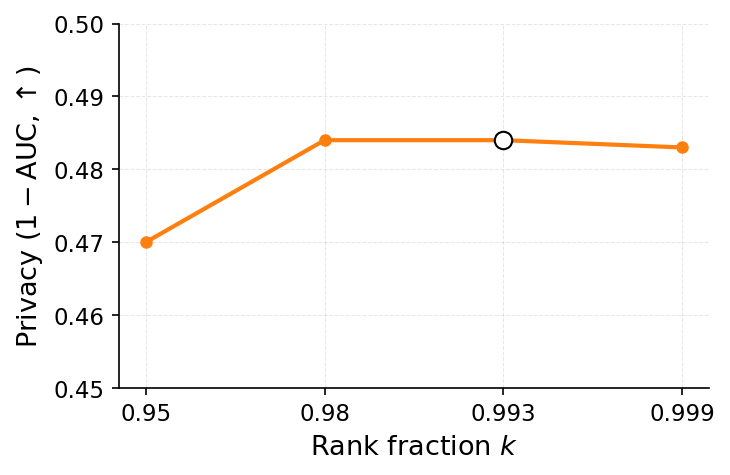
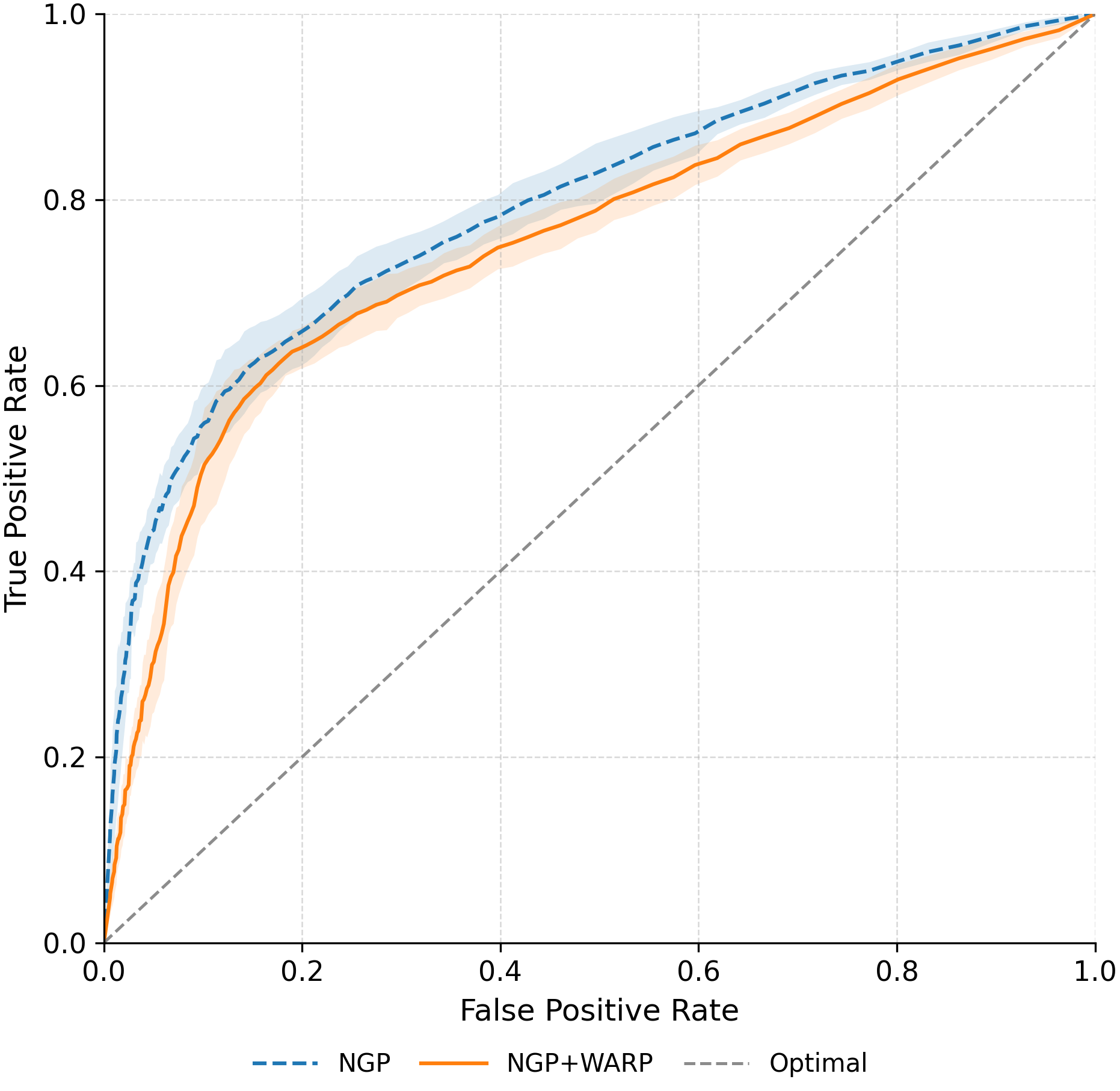
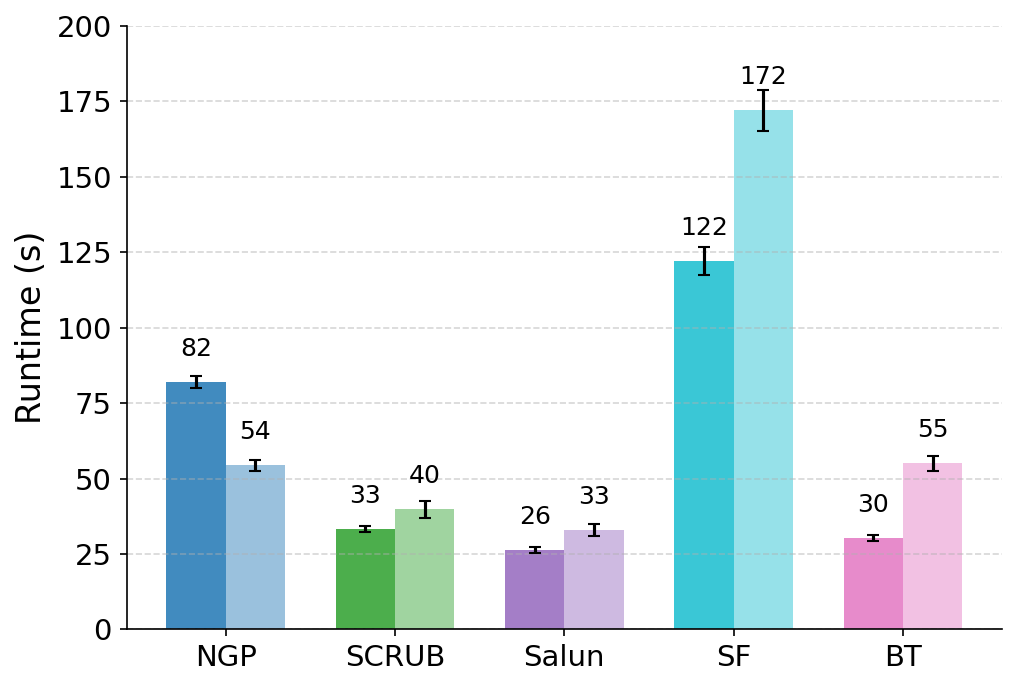
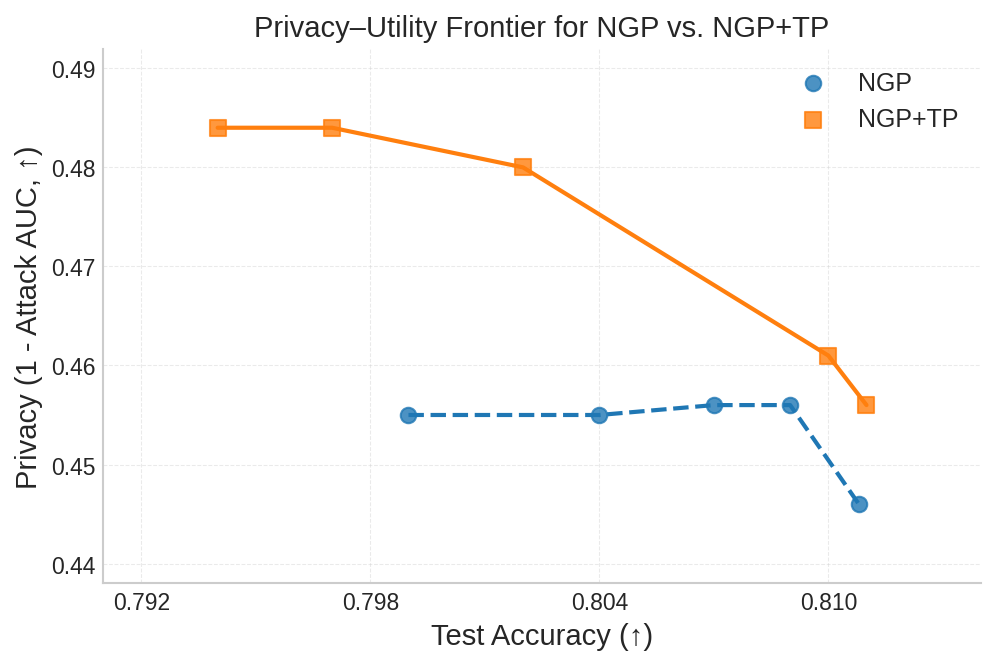
실험 결과는 설득력 있다. 6가지 서로 다른 근사 삭제 알고리즘에 WARP를 적용했을 때, 블랙박스 멤버십 추론의 AUC가 평균 64 % 감소하고, 화이트박스 상황에서는 최대 92 %까지 감소했다. 이는 공격자의 판단력이 거의 무작위 수준에 가까워졌음을 의미한다. 동시에 보존 데이터에 대한 정확도는 0.2 % 이하로 변동하지 않아 실용적인 성능 저하가 없었다. 이러한 결과는 ‘텔레포테이션’이 단순한 방어 메커니즘을 넘어, 근사 삭제와 프라이버시 보호 사이의 트레이드오프를 효과적으로 완화시키는 일반적인 도구임을 시사한다.
요약하면, 본 논문은 근사 삭제가 내재한 프라이버시 위험을 체계적으로 분석하고, 기존 방법들의 한계를 실증적으로 보여준다. 그리고 WARP라는 플러그‑인 방어를 통해 파라미터 재배치와 그래디언트 억제를 동시에 달성함으로써, 삭제된 데이터의 흔적을 크게 희석시킨다. 앞으로의 연구는 텔레포테이션을 다양한 모델 아키텍처와 데이터 도메인에 적용하고, 방어와 공격 간의 지속적인 ‘군비 경쟁’ 구도를 탐구하는 방향으로 나아가야 할 것이다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리