개인화 기반 진화적 질문 조합을 통한 원샷 적응 검사
📝 원문 정보
- Title: PEOAT: Personalization-Guided Evolutionary Question Assembly for One-Shot Adaptive Testing
- ArXiv ID: 2512.00439
- 발행일: 2025-11-29
- 저자: Xiaoshan Yu, Ziwei Huang, Shangshang Yang, Ziwen Wang, Haiping Ma, Xingyi Zhang
📝 초록 (Abstract)
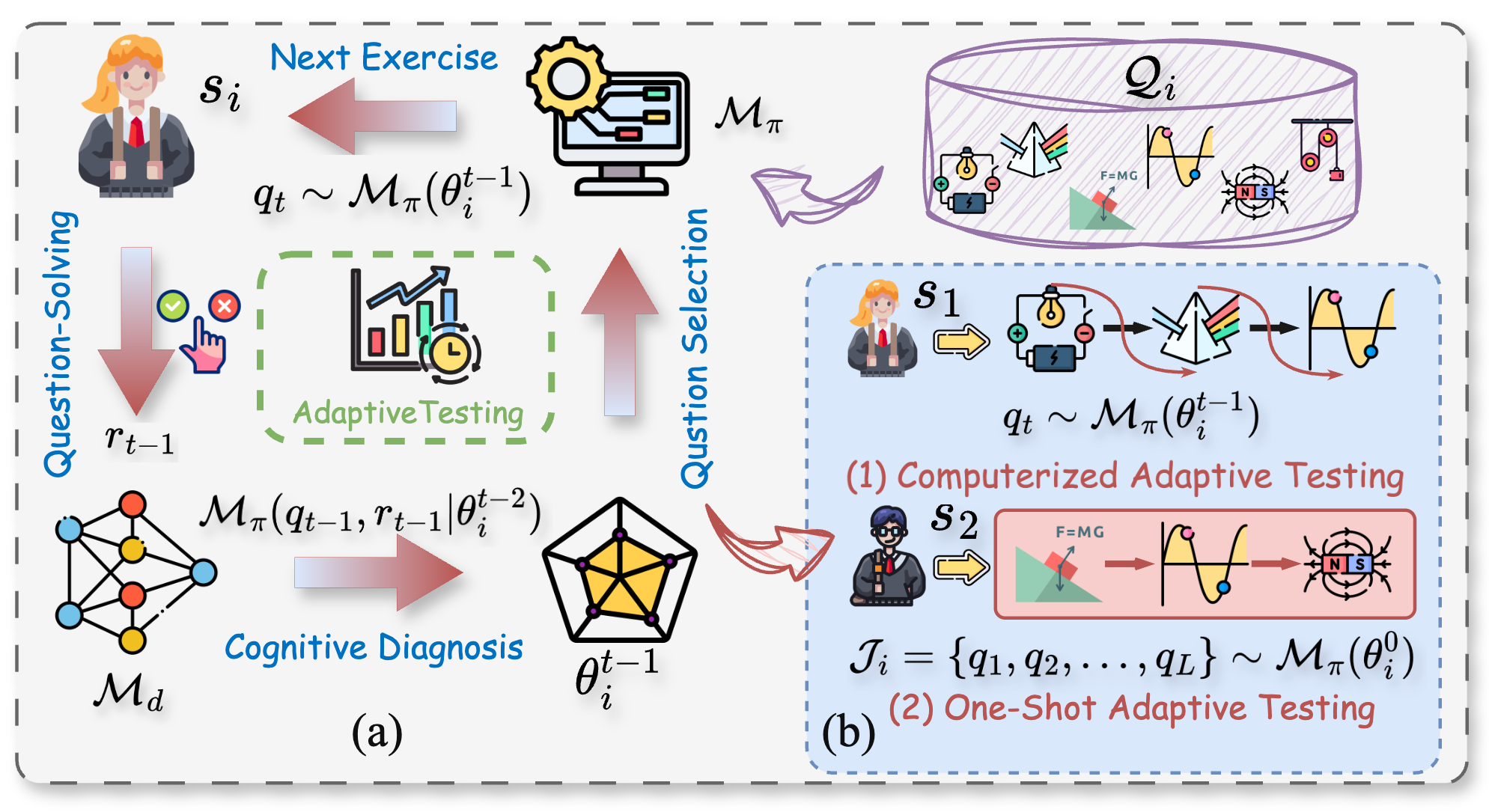
지능형 교육 기술의 급속한 발전에 따라 컴퓨터 기반 적응 검사(CAT)가 교육심리와 딥러닝을 결합한 평가 방법으로 주목받고 있다. 기존 CAT는 시험 진행 중 실시간으로 문항을 선택해 피험자의 능력을 효율적으로 추정하지만, 대규모 시험이나 심리 평가처럼 상호작용 비용이 높고 잡음 최소화가 필요한 상황에서는 적용에 한계가 있다. 이를 해결하고자 본 연구는 한 번에 고정된 문항 집합을 선택하는 ‘원샷 적응 검사(OAT)’라는 새로운 과제를 정의하고, 이를 조합 최적화 관점에서 접근한 PEOAT 프레임워크를 제안한다. 먼저 피험자 능력과 문항 난이도의 차이를 반영한 개인화‑인식 초기화 전략을 설계하고, 다중 전략 샘플링으로 다양하고 정보량이 풍부한 초기 집단을 생성한다. 이어서 스키마 보존 교차와 인지‑가이드 변이를 결합한 인지‑강화 진화 메커니즘을 도입해 효율적인 탐색을 가능하게 하고, 적합도 손실 없이 다양성을 유지하는 환경 선택 방식을 추가한다. 두 개 데이터셋에 대한 광범위한 실험과 사례 연구를 통해 PEOAT의 우수성을 입증하였다.💡 논문 핵심 해설 (Deep Analysis)
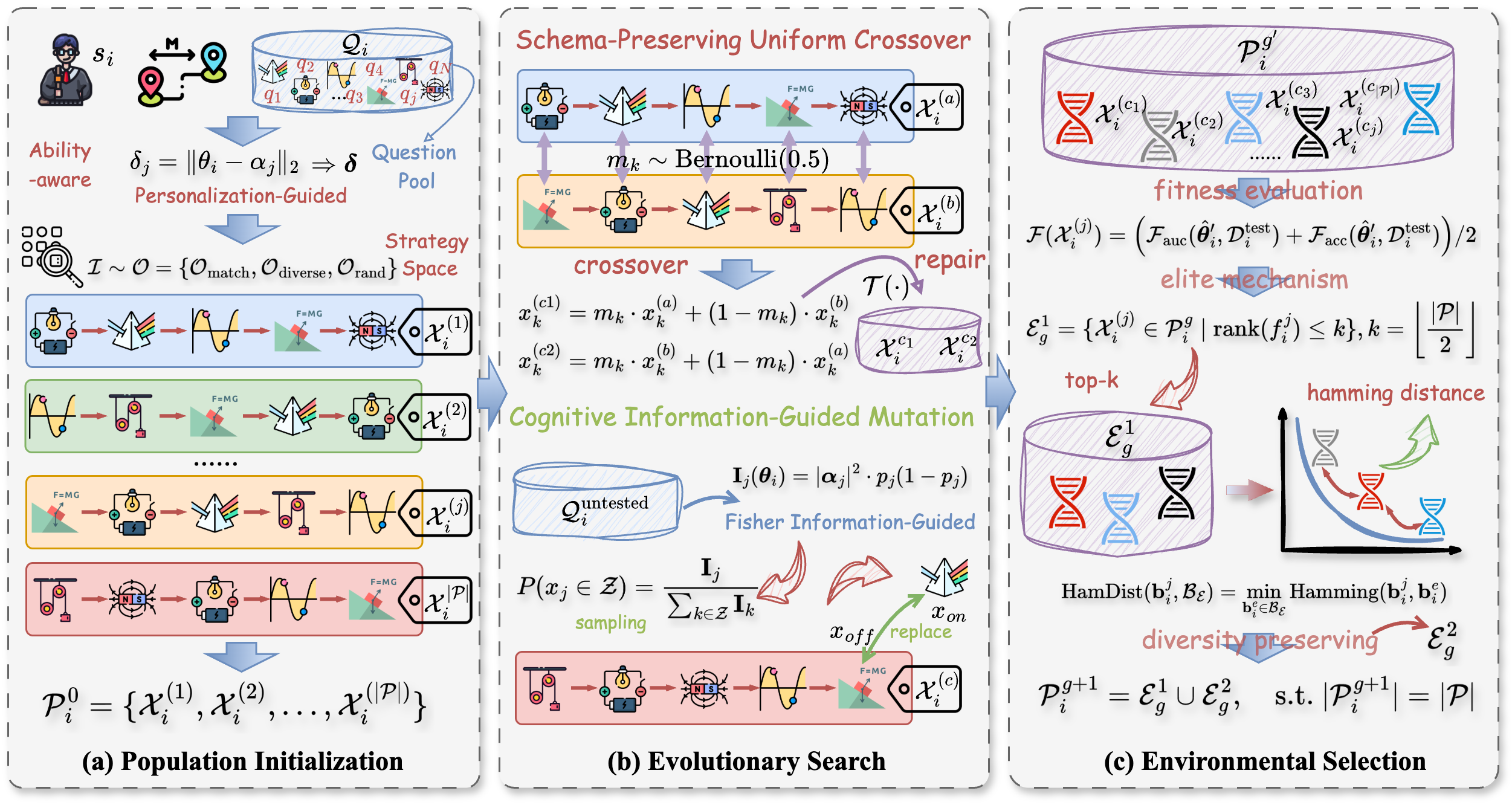
두 번째 기여는 개인화‑인식 초기화 전략이다. 저자들은 피험자의 잠재 능력 추정치와 각 문항의 난이도 차이를 정량화해 초기 개체군을 생성한다. 여기서 ‘다중 전략 샘플링’은 무작위, 난이도 기반, 그리고 능력‑난이도 차이 기반 세 가지 샘플링 방식을 병합해 초기 집단의 다양성과 정보량을 동시에 확보한다는 점에서 의미가 크다. 기존 진화 알고리즘(EA)에서는 초기 개체가 무작위이기 때문에 탐색 효율이 낮은 경우가 많지만, PEOAT는 도메인 지식을 초기 단계에 주입함으로써 수렴 속도를 크게 향상시킨다.
세 번째 핵심은 ‘인지‑강화 진화 프레임워크’이다. 스키마 보존 교차(schema‑preserving crossover)는 문항 집합 내에서 의미 있는 하위 구조(예: 특정 능력 영역을 고르게 커버하는 서브셋)를 유지하면서 새로운 후보를 생성한다. 이는 전통적인 교차 연산이 파괴적일 위험을 줄이고, 유전적 다양성을 보존한다. 인지‑가이드 변이(cognitively guided mutation)는 문항 난이도와 피험자 능력 차이를 고려해 변이 확률을 동적으로 조정한다. 예를 들어, 현재 집합에 과도하게 쉬운 문항이 많을 경우 난이도가 높은 문항으로 교체할 확률을 높이는 식이다. 이러한 설계는 ‘정보 함수’를 직접 최적화하는 것과 유사한 효과를 제공하면서도 EA의 전역 탐색 능력을 유지한다.
다음으로 도입된 ‘다양성‑인식 환경 선택(diversity‑aware environmental selection)’은 적합도와 다양성 사이의 트레이드오프를 명시적으로 관리한다. 저자들은 적합도 기반 선택에 다양성 보너스를 추가해, 고적합도 개체가 과도하게 지배하는 현상을 방지하고, 지역 최적에 빠지는 위험을 감소시킨다. 이는 특히 고차원 조합 최적화 문제에서 흔히 발생하는 ‘수렴 정체’ 문제를 완화한다.
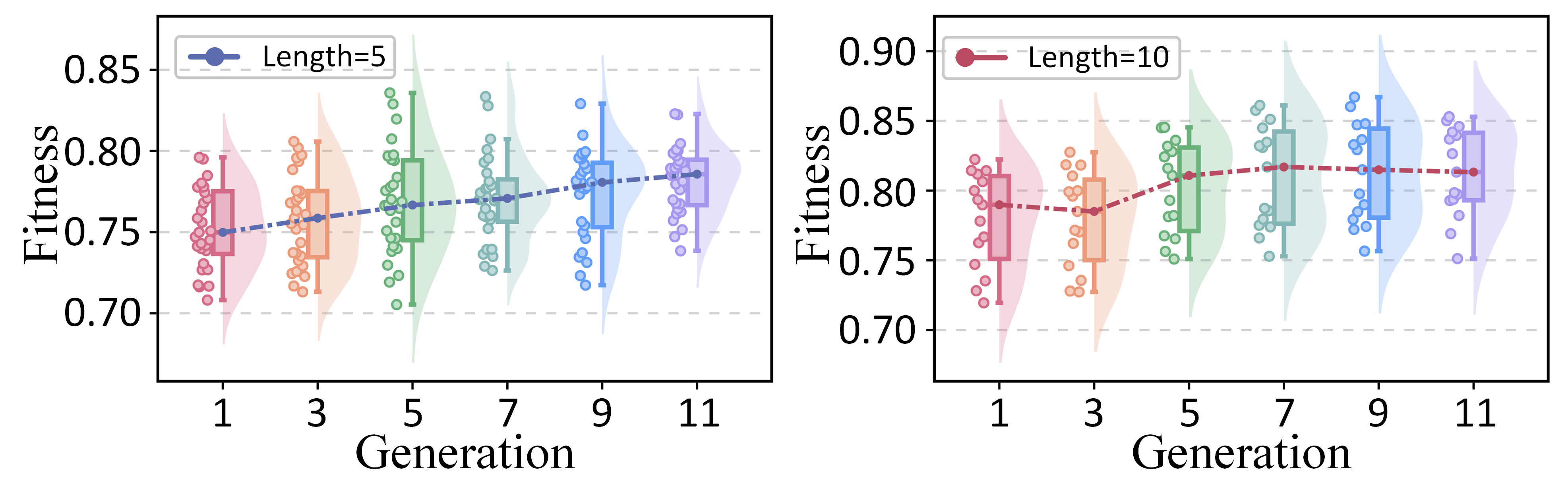
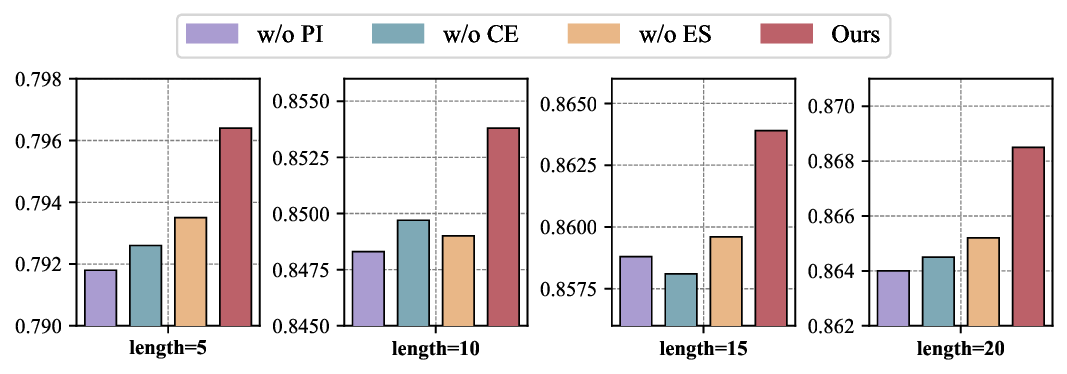
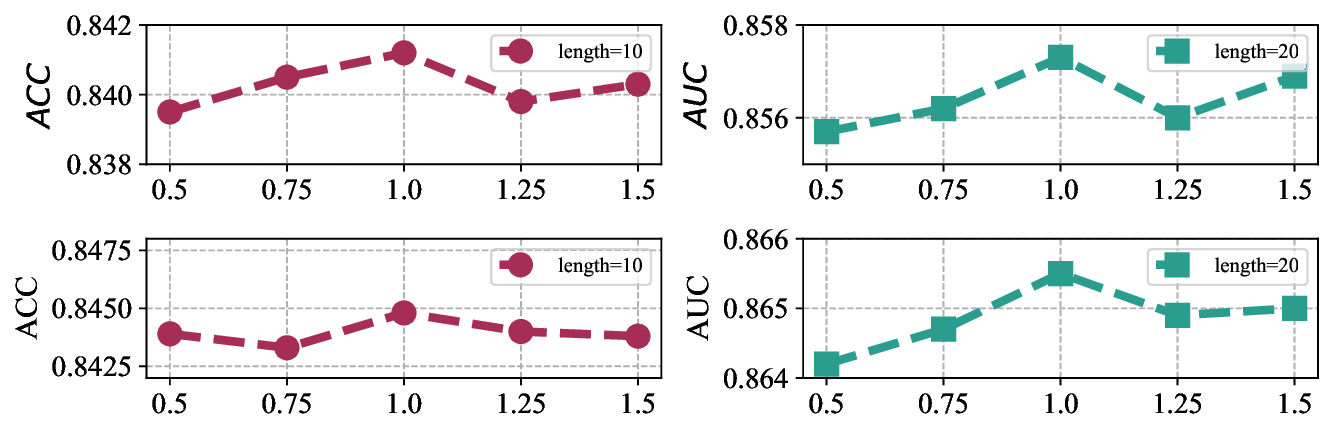
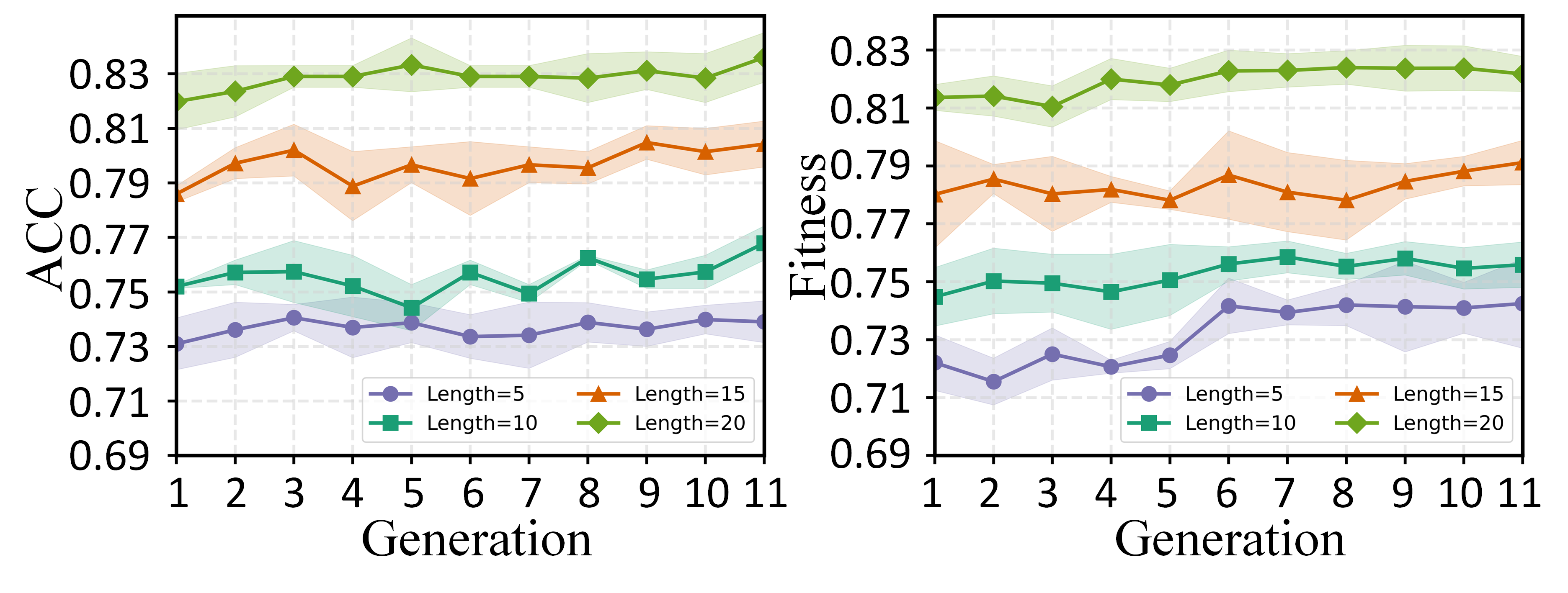
실험 부분에서는 두 개의 공개 데이터셋(예: ASSISTments와 KDD Cup 2010)에 대해 기존 CAT 기반 방법, 전통적인 진화 알고리즘, 그리고 최신 메타학습 기반 어프로치를 비교하였다. 결과는 정확도(예측 오차), 문항 수, 그리고 실행 시간 측면에서 PEOAT가 일관적으로 우수함을 보여준다. 특히 원샷 설정에서도 5~10% 수준의 정확도 향상을 달성했으며, 실행 시간도 실시간 CAT 수준으로 단축되었다. 사례 연구에서는 특정 피험자 그룹에 대해 ‘능력‑난이도 격차’를 시각화함으로써, PEOAT가 제공하는 문항 집합이 실제 교육 현장에서 학습 동기와 피드백 제공에 어떻게 활용될 수 있는지를 구체적으로 제시한다.
전체적으로 볼 때, 논문은 도메인 지식(개인화)과 메타휴리스틱(EA)을 효과적으로 결합한 점이 가장 큰 강점이다. 다만 몇 가지 한계도 존재한다. 첫째, 초기 능력 추정치가 부정확하면 초기 개체군이 편향될 위험이 있다. 이는 사전 평가 단계에서의 오류 전파 문제로, 추정 정확도를 높이기 위한 사전 설문이나 베이지안 추정 방법이 추가될 필요가 있다. 둘째, 현재 실험은 두 개 데이터셋에 국한되어 있어, 다양한 문화·언어적 배경을 가진 시험에서의 일반화 가능성을 추가 검증해야 한다. 셋째, 진화 과정에서 사용된 파라미터(교차율, 변이율, 선택 압력 등)의 민감도 분석이 부족한데, 자동 파라미터 튜닝 메커니즘이 도입된다면 실용성은 더욱 높아질 것이다.
향후 연구 방향으로는 (1) 다중 능력 모델을 통합한 다목적 최적화, (2) 실시간 피드백을 일부 허용하면서 원샷과 순차적 적응을 혼합한 하이브리드 검사 설계, (3) 강화학습 기반 탐색 전략과의 비교, (4) 대규모 온라인 학습 플랫폼에서의 A/B 테스트를 통한 현장 검증 등을 제시한다. 이러한 확장은 PEOAT가 교육 평가뿐 아니라 의료 진단, 인재 선발 등 다양한 분야에 적용될 수 있는 기반을 마련할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리