툴 기반 머신러닝 에이전트 평가를 위한 종합 벤치마크와 향상된 계획 전략
📝 원문 정보
- Title: ML-Tool-Bench: Tool-Augmented Planning for ML Tasks
- ArXiv ID: 2512.00672
- 발행일: 2025-11-29
- 저자: Yaswanth Chittepu, Raghavendra Addanki, Tung Mai, Anup Rao, Branislav Kveton
📝 초록 (Abstract)
자율적인 머신러닝(ML) 에이전트가 데이터 전처리, 특성 엔지니어링, 모델 선택, 하이퍼파라미터 최적화 등 엔드투엔드 데이터 사이언스 워크플로우를 수행하도록 하는 것은 인공지능 분야의 주요 과제이다. 기존 연구는 대형 언어 모델(LLM)을 이용한 직접 코드 생성에 초점을 맞추었지만, 툴을 활용하는 접근법이 더 높은 모듈성 및 신뢰성을 제공한다. 그러나 현재 툴 사용 벤치마크는 도구 선택이나 인자 추출에 국한돼 ML 에이전트가 필요로 하는 복합적인 계획 능력을 평가하지 못한다. 본 연구는 61개의 특화된 툴과 Kaggle의 15개 탭형 ML 과제를 활용한 포괄적인 벤치마크를 제안한다. 이 벤치마크는 메모리 내 명명 객체 관리 기능을 도입해 에이전트가 중간 결과를 자유롭게 명명·저장·불러올 수 있게 한다. 실험 결과 ReAct 스타일 접근법은 복잡한 파이프라인에 대한 유효한 툴 시퀀스를 생성하는 데 한계를 보였으며, LLM 기반 평가를 이용한 트리 탐색 방법도 상태 점수의 일관성 부족으로 성능이 저조했다. 이를 극복하기 위해 (1) 구조화된 텍스트 피드백을 포함한 결정적 보상 설계와 (2) 문제를 연속적인 하위 과제로 분해하는 두 가지 간단한 전략을 제안한다. GPT‑4o 기반 구현에서 제안 방법은 ReAct 대비 모든 Kaggle 과제의 중앙값 성능을 16.52 퍼센타일 포지션 향상시켰다. 본 연구는 향후 보다 강력한 툴 기반 계획 ML 에이전트 개발을 위한 기반을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
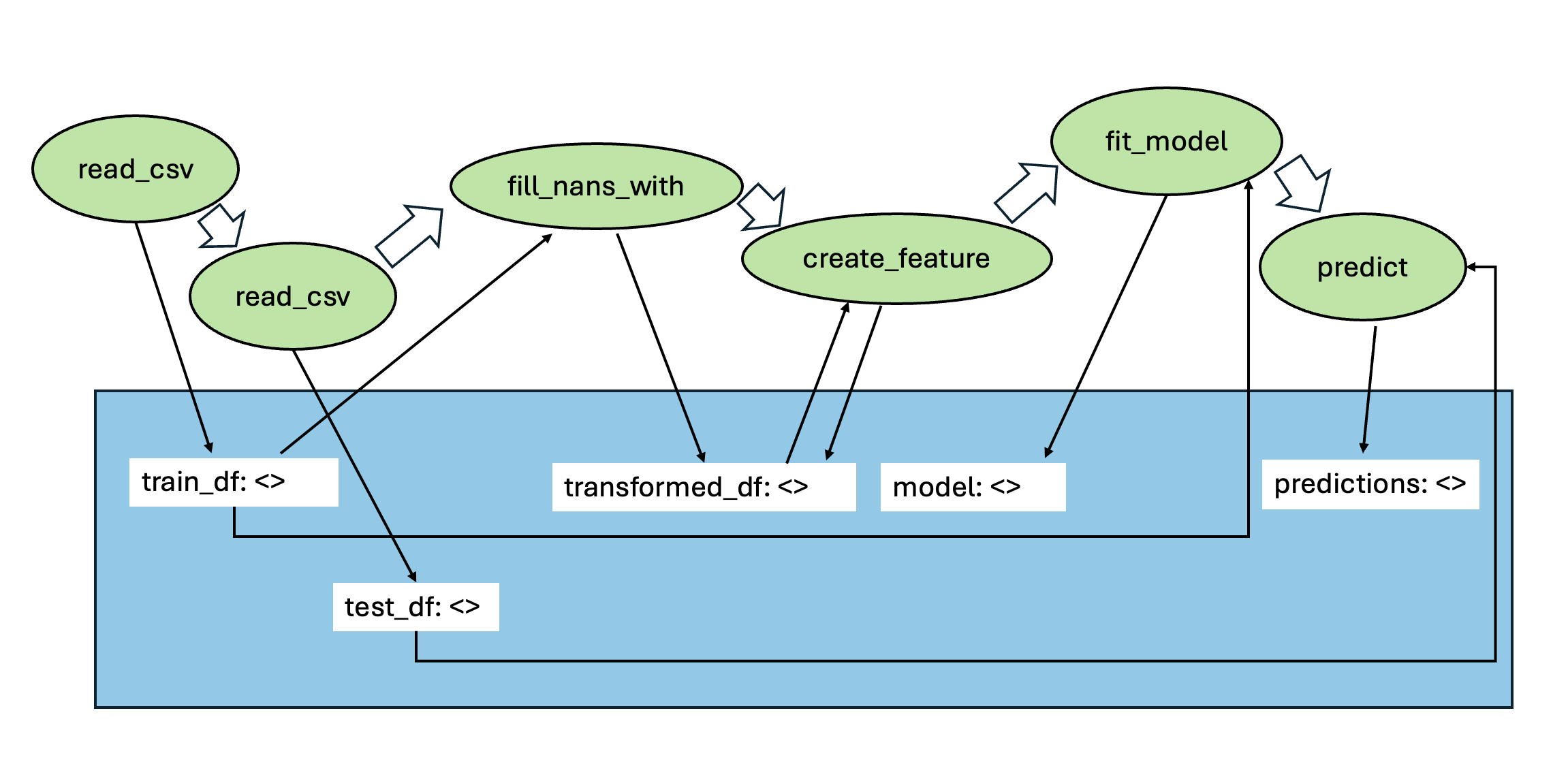
벤치마크 구성 역시 신중했다. 61개의 특화된 툴은 데이터 전처리(예: 스케일링, 인코딩), 피처 엔지니어링(예: 차원 축소, 파생 변수 생성), 모델링(예: XGBoost, LightGBM) 및 평가(예: 교차 검증, 메트릭 계산) 등 실제 Kaggle 대회에서 흔히 사용되는 기능을 포괄한다. 15개의 Kaggle 탭형 과제는 난이도와 도메인이 다양해 에이전트의 일반화 능력을 시험한다. 이러한 다양성은 단순히 “툴을 올바르게 호출했는가”를 넘어 “전체 파이프라인을 최적화했는가”를 평가하도록 만든다.
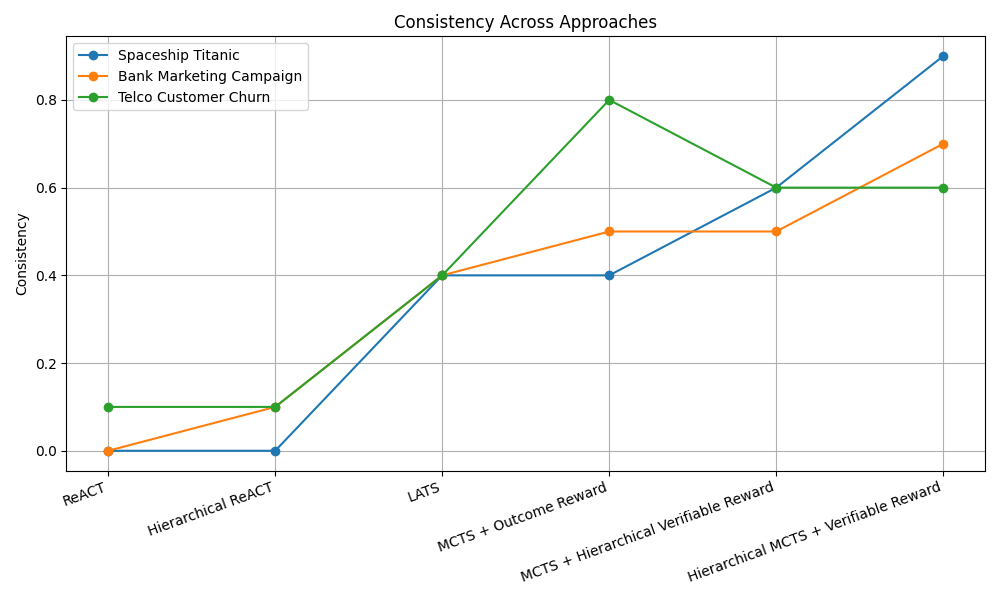
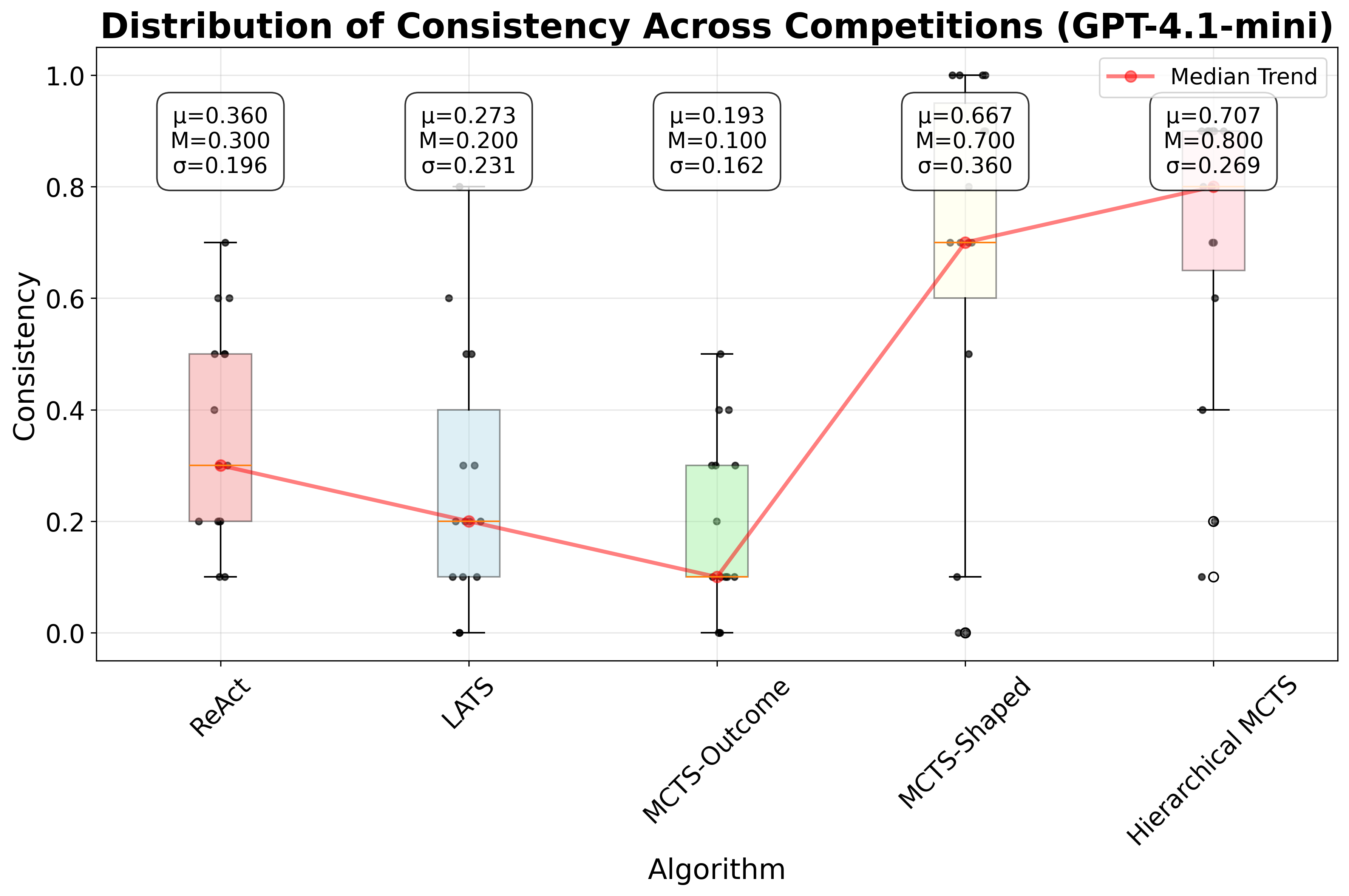
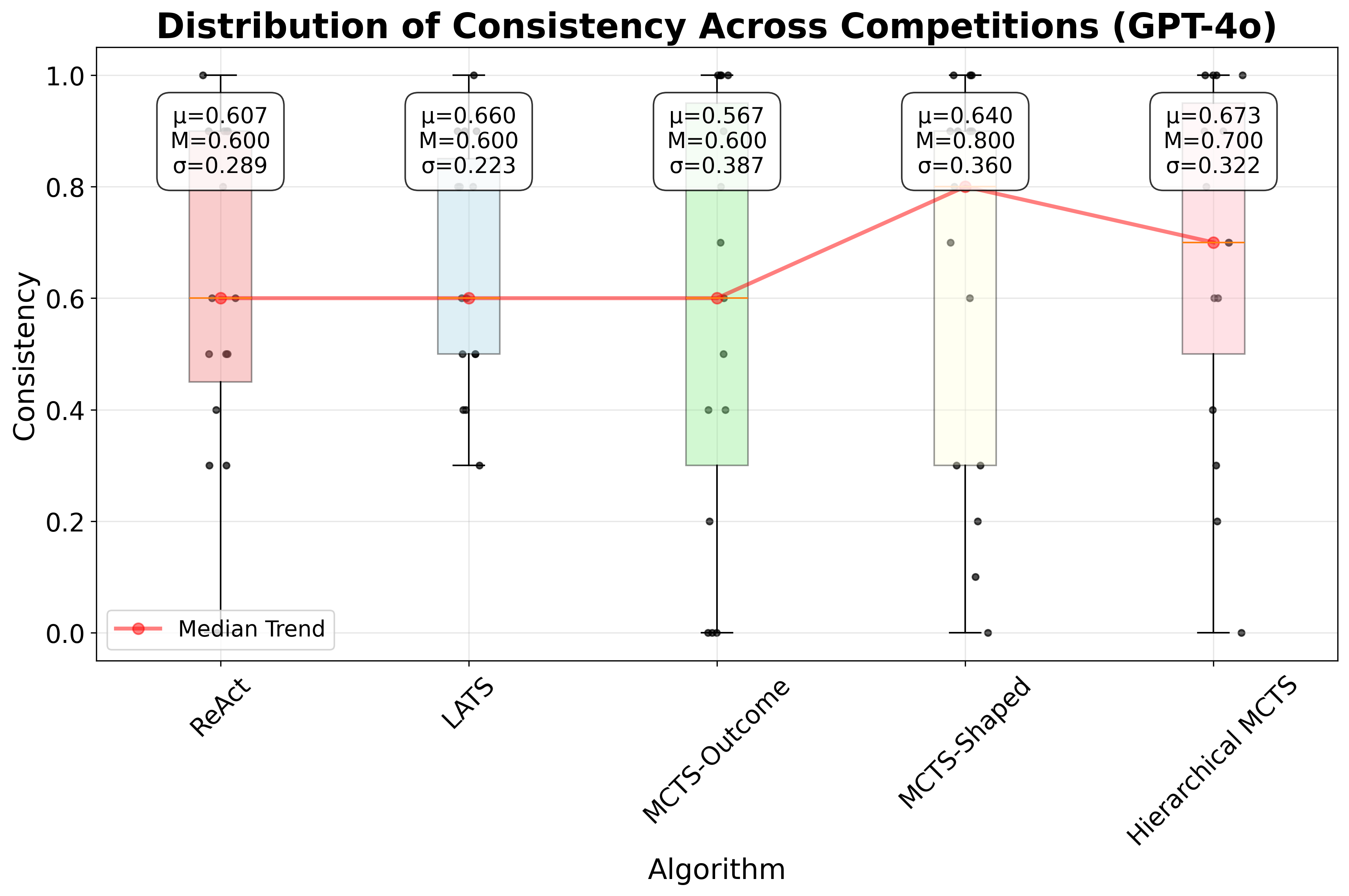
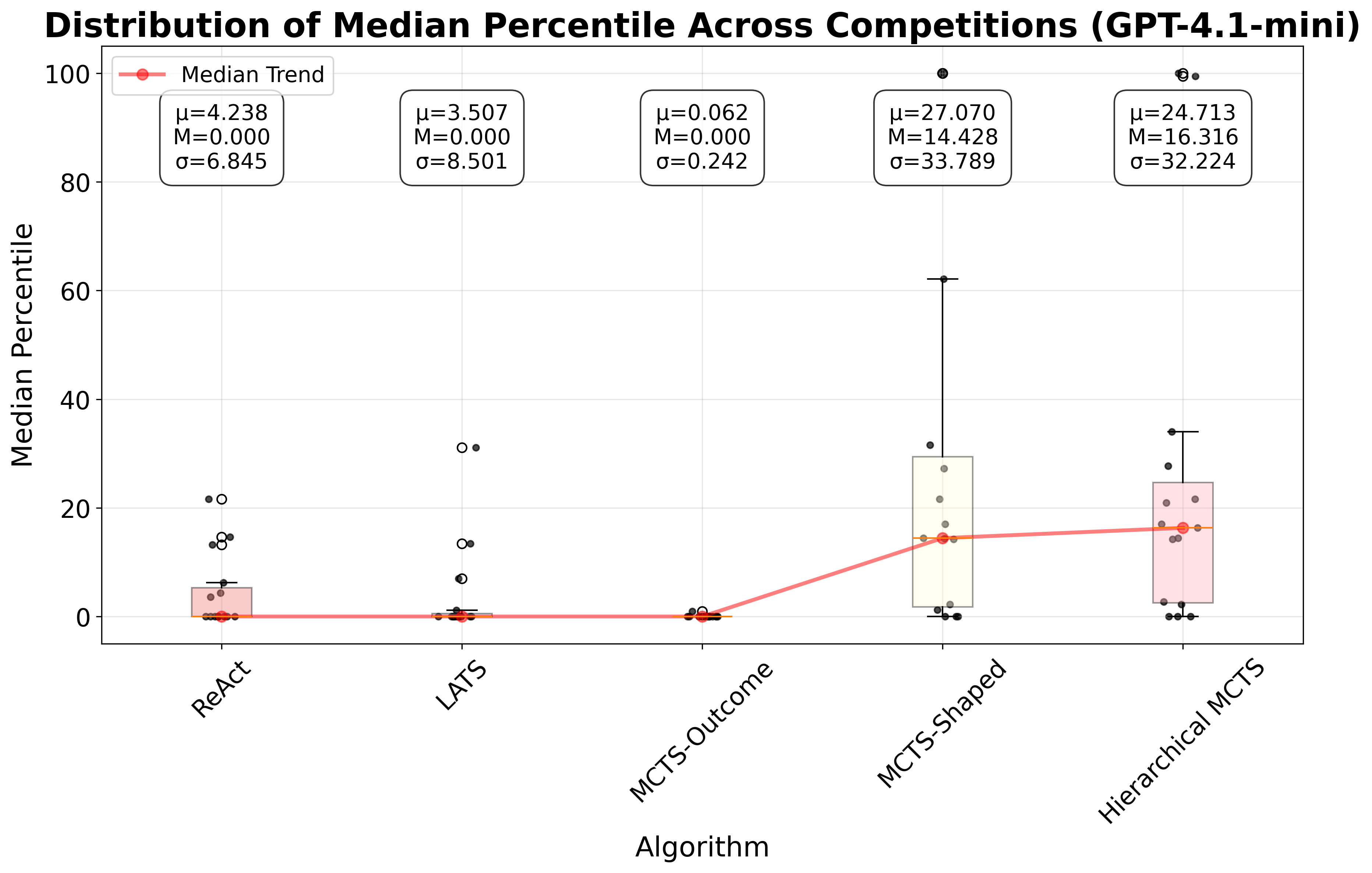
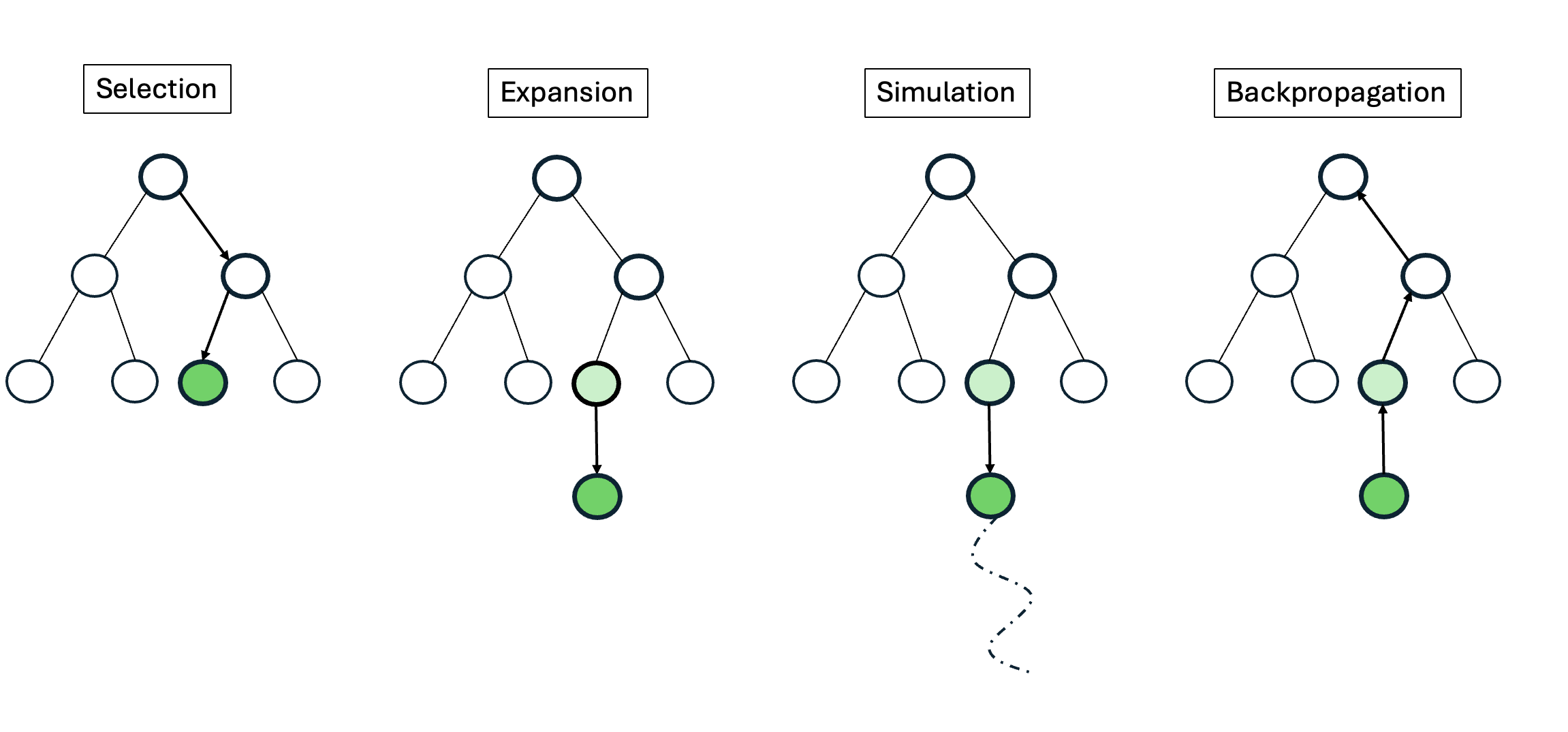
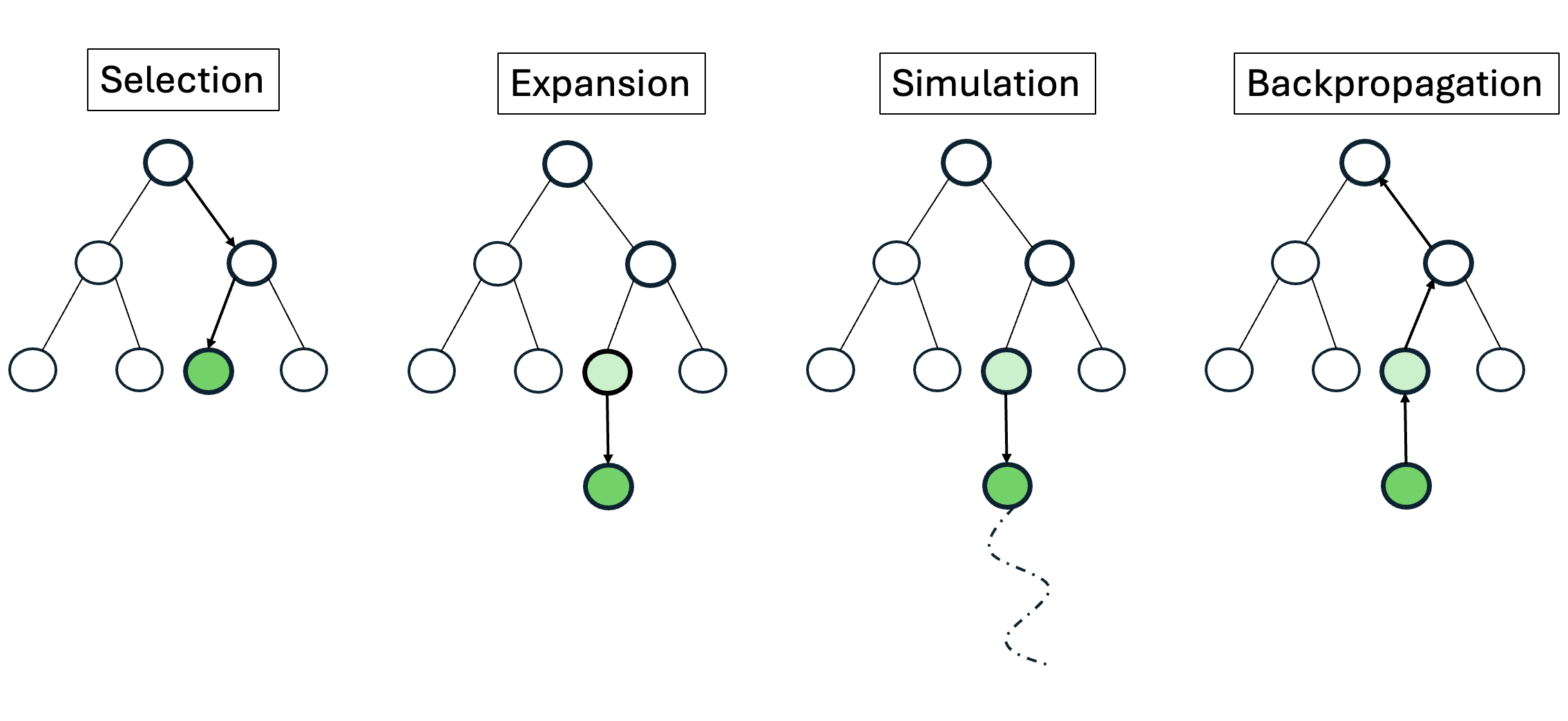
실험에서는 대표적인 ReAct 방식과 LLM 기반 트리 탐색을 비교했는데, 두 방법 모두 유효한 툴 시퀀스 생성률이 낮았다. ReAct는 프롬프트에 따라 순차적으로 툴을 호출하지만, 복잡한 파이프라인에서는 중간 결과를 적절히 관리하지 못해 오류가 누적된다. 트리 탐색은 가능한 행동을 폭넓게 탐색하려 하지만, 상태를 점수화하는 LLM 평가자가 “현재 상태가 좋은가”를 일관되게 판단하지 못해 탐색 효율이 급격히 떨어진다. 즉, 상태 스코어링의 불안정성이 근본적인 병목으로 작용한다는 점을 명확히 보여준다.
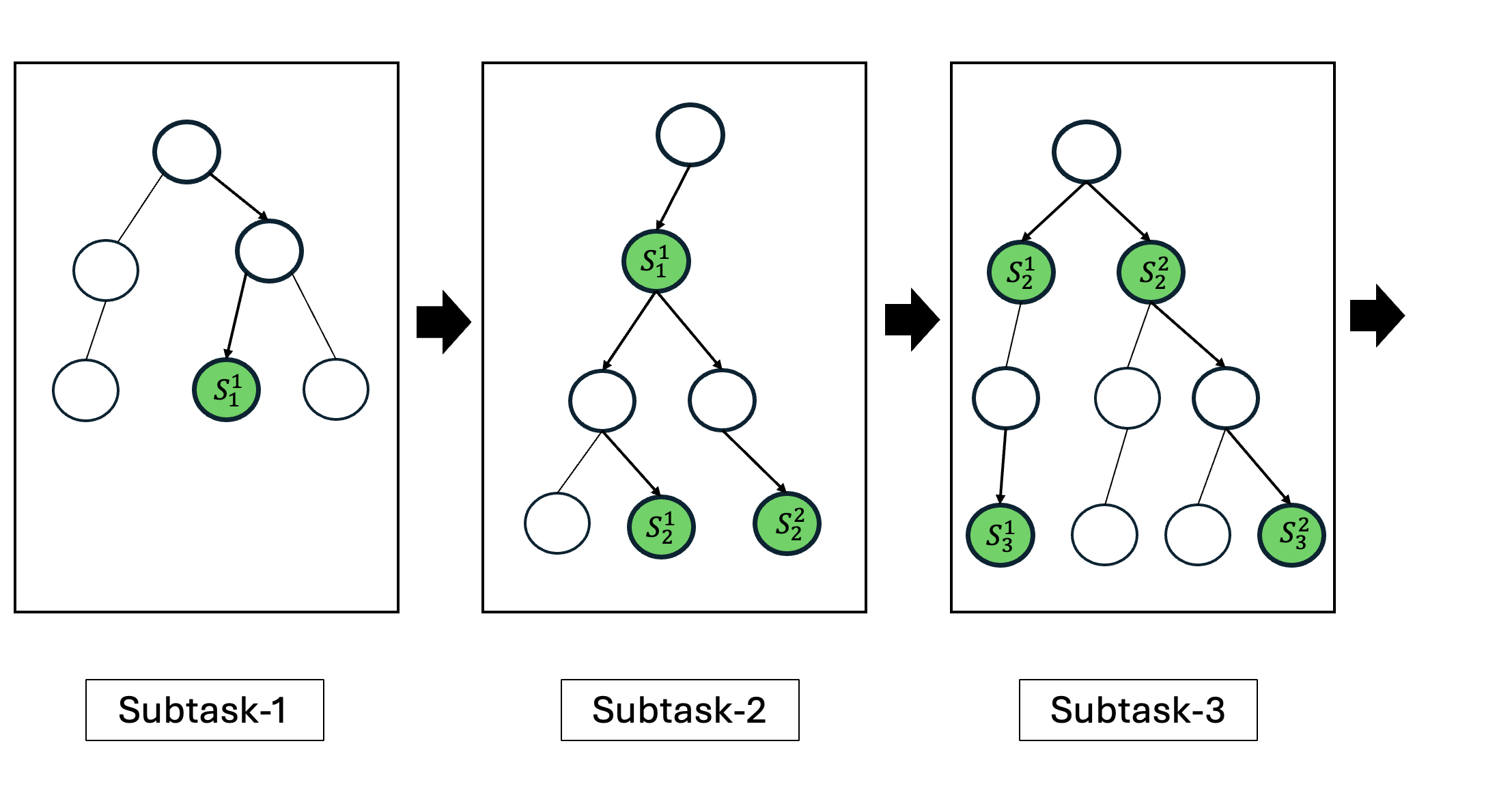
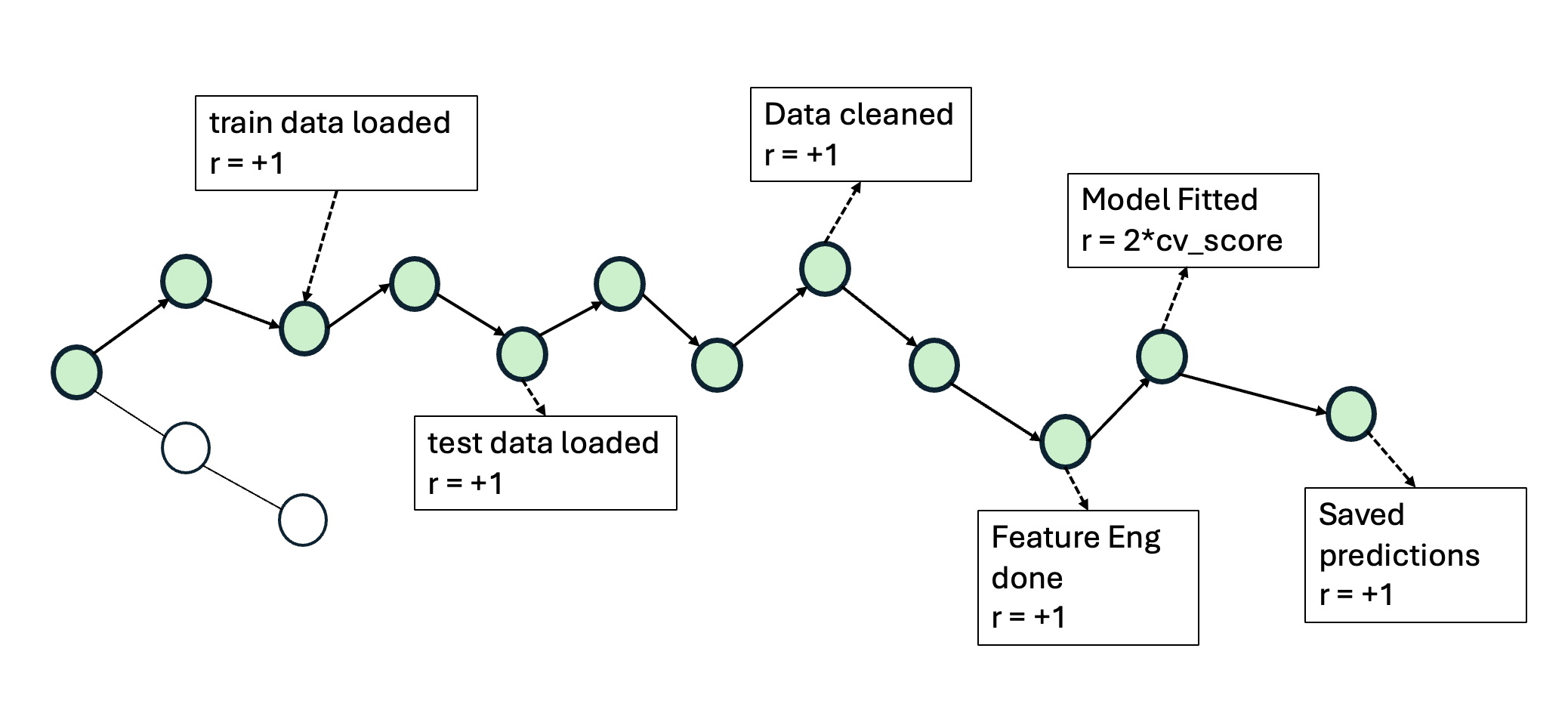
이에 저자들은 두 가지 간단하지만 효과적인 개선책을 제시한다. 첫째, 결정적 보상 설계이다. 툴 호출 결과에 대해 “성공”, “실패”, “경고”와 같은 구조화된 텍스트 피드백을 제공하고, 이를 기반으로 보상을 직접 지정한다. 이렇게 하면 LLM이 상태를 평가하는 과정에서 발생하는 주관적 변동을 최소화하고, 에이전트가 명확한 목표 신호를 받게 된다. 둘째, 문제 분해 전략이다. 전체 ML 파이프라인을 “데이터 전처리 → 피처 엔지니어링 → 모델 학습 → 평가”와 같은 연속적인 서브태스크로 나누고, 각 서브태스크마다 별도의 계획·실행 루프를 적용한다. 이 방식은 복잡성을 단계별로 낮추어 에이전트가 각 단계에서 집중적으로 최적화하도록 만든다.
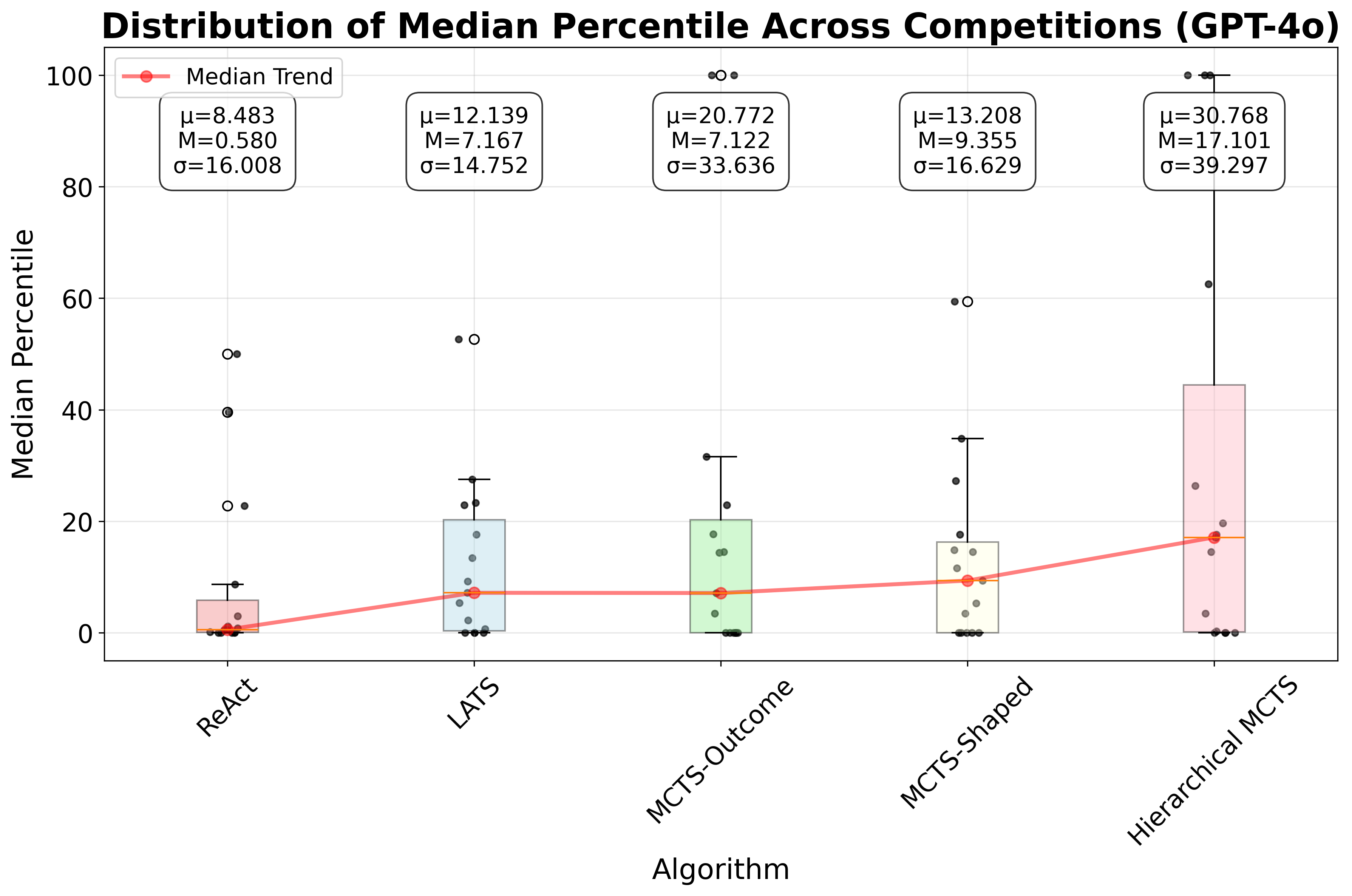
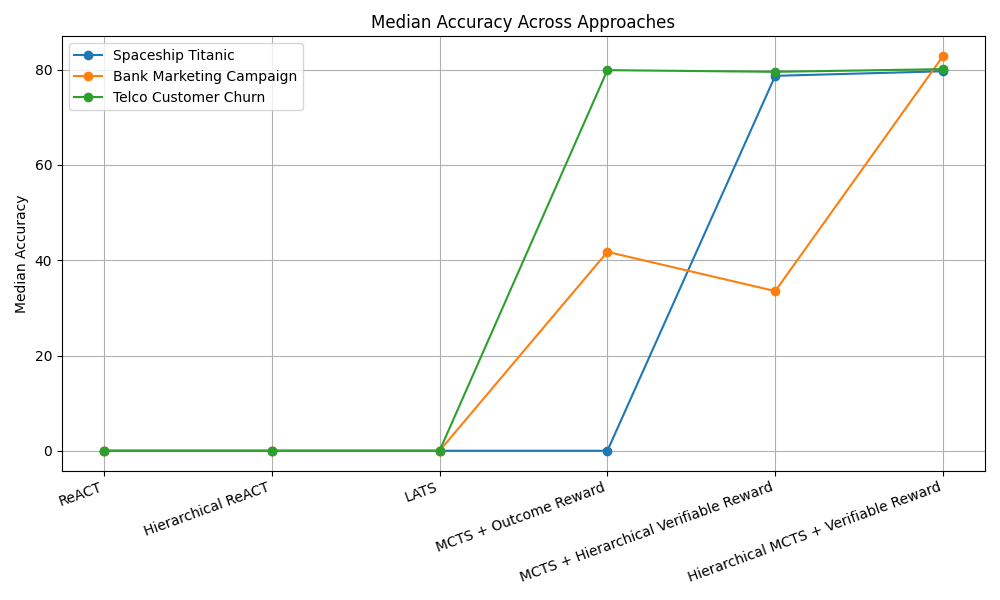
GPT‑4o 기반 구현에서 제안 방법은 ReAct 대비 중앙값 성능을 16.52 퍼센타일 포지션 향상시켰다. 이는 단순히 평균 점수 차이가 아니라, 전체 15개 과제 중 절반 이상에서 현저히 높은 순위를 차지했음을 의미한다. 특히 데이터 전처리와 피처 엔지니어링 단계에서 큰 개선이 관찰됐으며, 이는 명명 객체 관리와 보상 설계가 에이전트에게 “중간 결과를 어떻게 활용할 것인가”에 대한 명확한 지침을 제공했기 때문이다.
전체적으로 이 연구는 툴‑증강형 ML 에이전트가 실제 데이터 사이언스 워크플로우에서 유용하게 쓰이기 위해서는 계획(Planning), 상태 관리(State Management), **명확한 보상 설계(Reward Shaping)**가 필수적이라는 점을 실증한다. 앞으로는 보다 복잡한 멀티모달 데이터, 실시간 스트리밍 환경, 그리고 협업형 에이전트 시나리오까지 확장할 여지가 크다. 또한, 제시된 벤치마크와 평가 프레임워크는 향후 새로운 LLM 기반 툴 사용 전략을 비교·검증하는 표준이 될 가능성이 높다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리