오리온: 사고 효율을 위한 언어 모델 훈련
📝 원문 정보
- Title: ORION: Teaching Language Models to Reason Efficiently in the Language of Thought
- ArXiv ID: 2511.22891
- 발행일: 2025-11-28
- 저자: Kumar Tanmay, Kriti Aggarwal, Paul Pu Liang, Subhabrata Mukherjee
📝 초록 (Abstract)
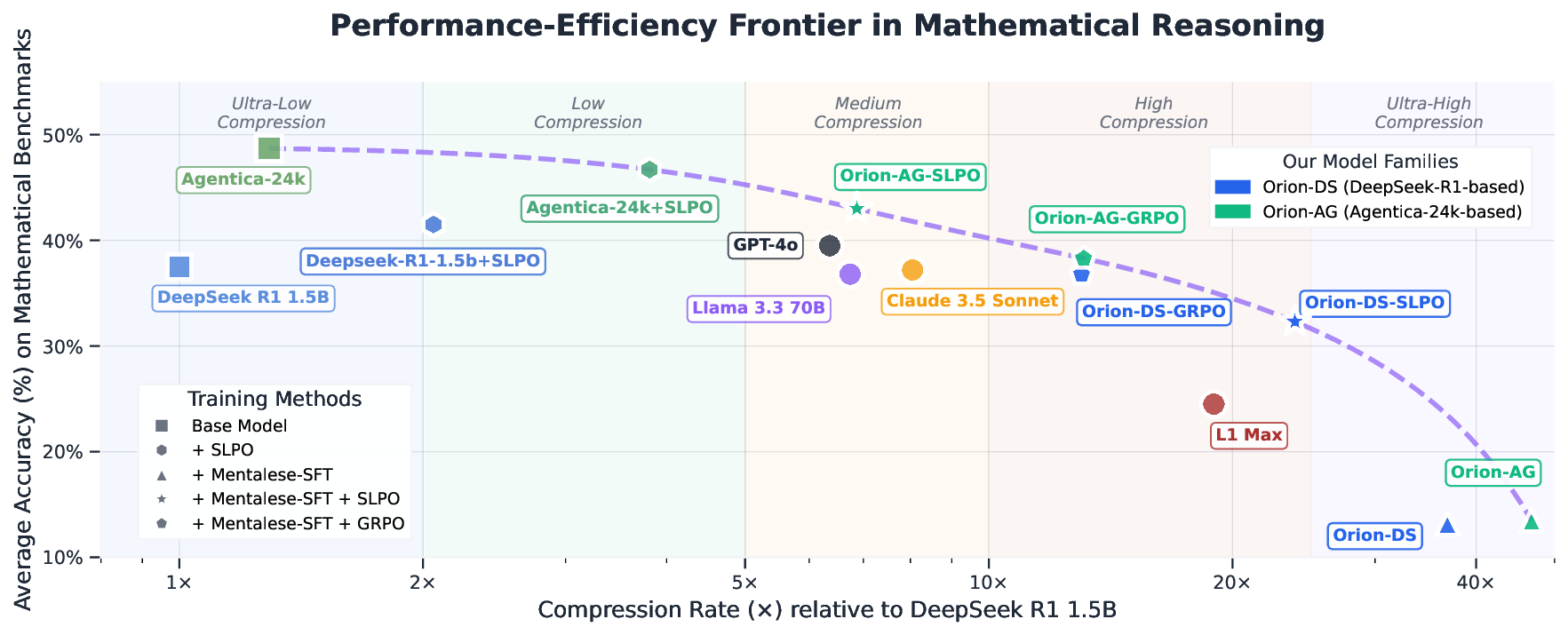
대규모 추론 모델(LRM)은 수학, 코드 생성, 작업 계획 등에서 최첨단 성능을 보이지만, 길고 중복된 “생각” 토큰을 사용해 지연 시간과 비용이 크게 증가한다. 인간의 사고가 상징적이고 조합적인 정신 언어(Mentalese) 위에서 이루어진다는 언어‑사고 가설에 착안해, 우리는 초압축된 구조화 토큰으로 추론을 표현하는 Mentalese 기반 프레임워크를 제안한다. 이를 위해 짧은 길이 선호 최적화(SLPO)라는 강화학습 기법을 도입해, 정확성을 유지하면서도 토큰 수를 최소화하도록 모델을 직접 학습시킨다. ORION 모델은 AIME 2024·2025, Minerva‑Math, OlympiadBench, Math500, AMC 등 수학 벤치마크에서 기존 DeepSeek R1 Distilled 대비 4‑16배 적은 토큰, 최대 5배 낮은 추론 지연, 7‑9배 적은 학습 비용을 달성하면서 90‑98% 수준의 정확도를 유지한다. 또한 Claude와 ChatGPT‑4o를 능가하는 정확도와 2배 이상의 압축률을 동시에 보여준다.💡 논문 핵심 해설 (Deep Analysis)

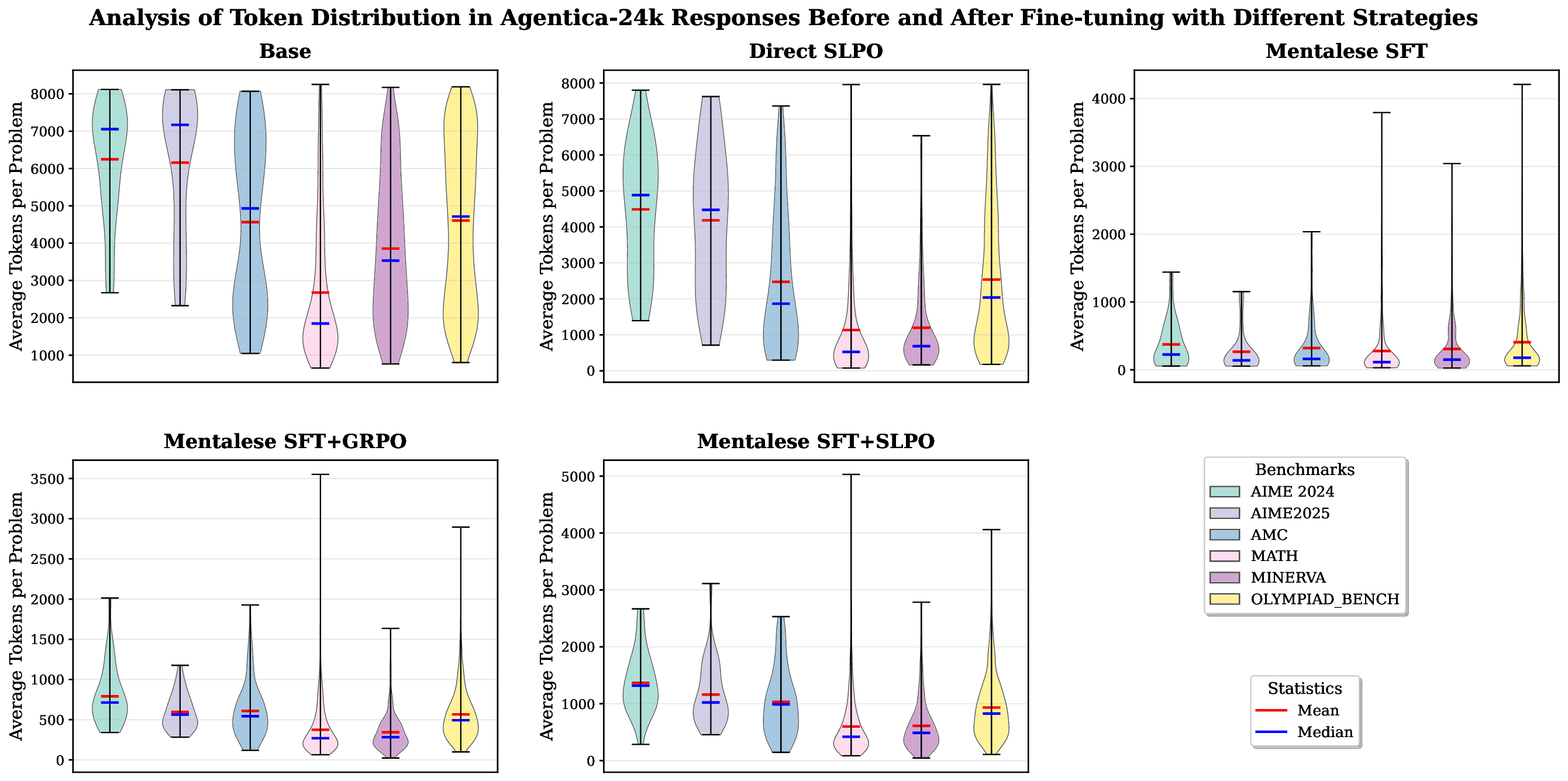
이를 실현하기 위한 핵심 알고리즘이 ‘짧은 길이 선호 최적화(SLPO)’이다. SLPO는 강화학습 프레임워크 내에서 두 가지 보상을 동시에 최적화한다. 첫 번째는 ‘정답 보상’으로, 모델이 생성한 추론이 정답과 일치하거나 높은 정확도를 보일 때 부여된다. 두 번째는 ‘길이 보상’으로, 동일한 정확도 수준에서 토큰 수가 적을수록 추가 보상이 주어진다. 이러한 다중 목표 최적화는 모델이 “필요한 만큼만 생각하고, 불필요하게 길어지는 경로는 스스로 억제”하도록 학습시킨다. 특히 SLPO는 길이 제한을 고정하지 않고, 문제 복잡도에 따라 동적으로 허용 토큰 수를 조정하도록 설계돼, 단순히 모든 문제를 동일한 압축률로 처리하는 기존 방식보다 유연성을 크게 향상시킨다.
실험 결과는 ORION 모델이 다양한 수학 벤치마크에서 4‑16배 토큰 감소, 최대 5배 추론 지연 감소, 7‑9배 학습 비용 절감을 달성했음에도 불구하고 90‑98% 수준의 정확도를 유지한다는 점에서 그 효용성을 입증한다. 특히 AIME와 같은 고난이도 시험 문제에서도 기존 DeepSeek R1 대비 압축률이 높은 상황에서도 정확도 격차가 미미하거나 오히려 개선된 점은 Mentalese 기반 압축이 단순한 ‘줄이기’가 아니라 ‘핵심 논리 유지’를 성공적으로 구현했음을 시사한다. 또한 Claude와 ChatGPT‑4o와 비교했을 때 정확도에서 5%p 상승과 2배 이상의 압축률을 동시에 달성한 것은 현재 상용 LLM이 직면한 실시간 추론 및 비용 효율성 문제에 대한 실질적인 대안이 될 수 있음을 보여준다.
이러한 결과는 앞으로 LLM이 인간과 유사한 인지 효율성을 갖추는 방향성을 제시한다. 즉, 모델이 내부적으로 고차원 논리 심볼을 활용해 ‘생각’ 자체를 압축하고, 필요 시에만 상세한 전개를 수행함으로써, 실시간 응용(예: 교육, 과학 탐구, 실시간 코딩 보조)에서의 지연과 비용을 크게 낮출 수 있다. 향후 연구에서는 Mentalese 토큰의 설계 원리를 다른 도메인(예: 물리 시뮬레이션, 법률 논증)으로 확장하고, SLPO와 같은 동적 길이 최적화 기법을 멀티모달 모델에 적용하는 방안을 모색할 필요가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리