구조화된 지식 탐색으로 언어 모델 생성 해석성 강화
📝 원문 정보
- Title: Towards Improving Interpretability of Language Model Generation through a Structured Knowledge Discovery Approach
- ArXiv ID: 2511.23335
- 발행일: 2025-11-28
- 저자: Shuqi Liu, Han Wu, Guanzhi Deng, Jianshu Chen, Xiaoyang Wang, Linqi Song
📝 초록 (Abstract)
지식‑강화 텍스트 생성은 내부·외부 지식원을 활용해 생성 텍스트의 품질을 높이는 것을 목표로 한다. 대형 언어 모델은 일관되고 유창한 텍스트를 생성하는 뛰어난 능력을 보여주지만, 생성 결과의 해석 가능성이 부족해 실용성에 큰 제약을 만든다. 특히 신뢰성과 설명 가능성이 요구되는 지식‑강화 생성 작업에서는 이러한 해석성 부족이 치명적이다. 기존 방법들은 데이터 특성에 맞춘 도메인‑특화 지식 검색기를 사용해 범용성에 한계를 보인다. 이를 극복하고자 우리는 고수준 엔터티와 저수준 지식 삼중항으로 구성된 이중 계층 구조를 직접 활용하는 작업‑불변 구조화 지식 사냥꾼을 설계한다. 구체적으로, 구조화 지식 표현 학습을 위해 지역‑전역 상호작용 방식을 도입하고, 관련 지식 삼중항과 엔터티를 선택하는 백본으로 계층형 트랜스포머 기반 포인터 네트워크를 사용한다. 강력한 생성 능력을 가진 언어 모델과 높은 충실도를 가진 지식 사냥꾼을 결합함으로써 모델 출력 과정을 사용자가 이해할 수 있는 높은 해석성을 제공한다. 우리는 RotoWireFG 데이터셋의 내부 지식‑강화 표‑텍스트 생성과 KdConv 데이터셋의 외부 지식‑강화 대화 응답 생성 두 과제에서 우리 모델의 효과를 실증하였다. 작업‑불변 모델은 최첨단 방법 및 해당 언어 모델들을 능가하며 벤치마크에서 새로운 기준을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
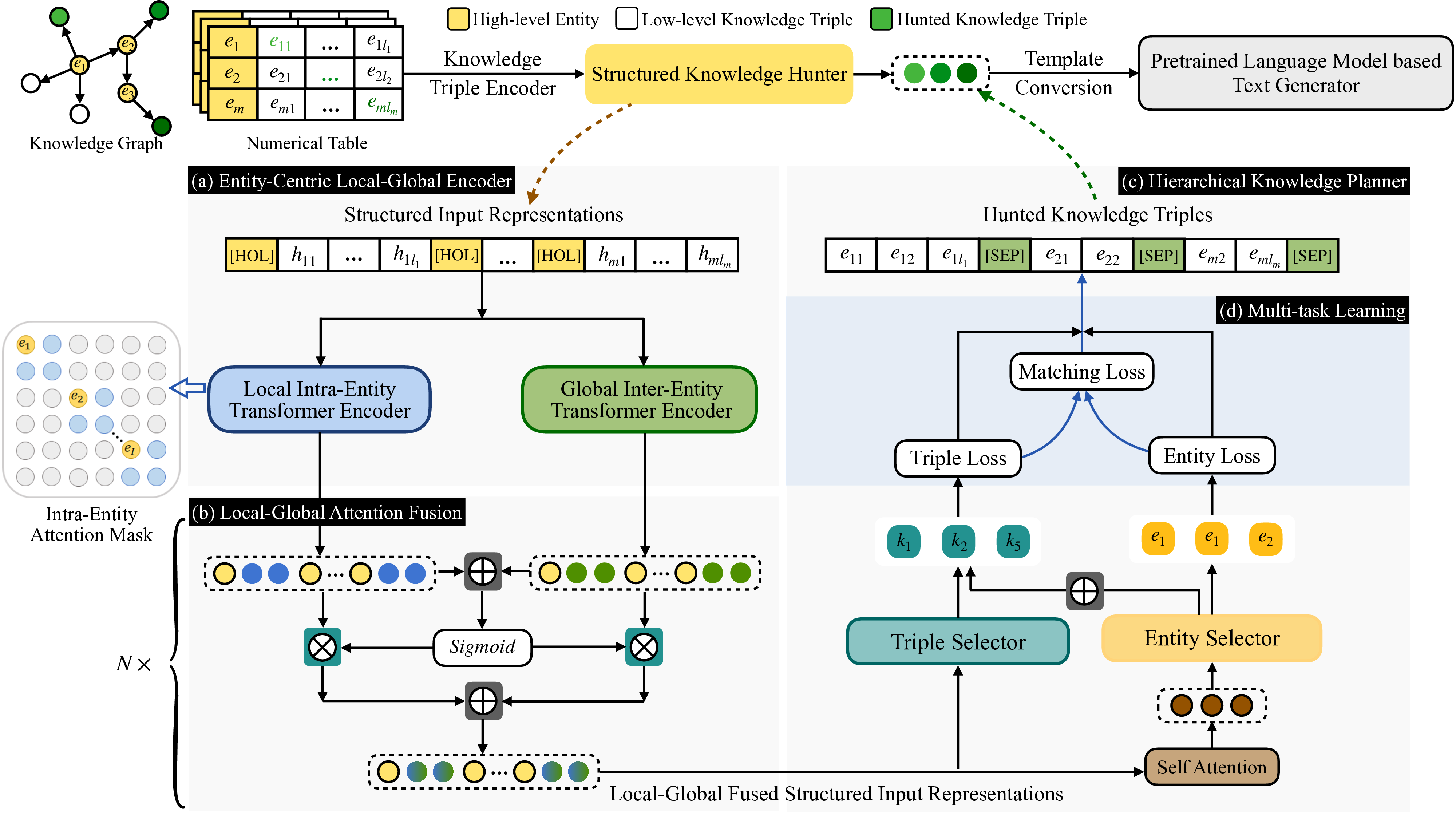
핵심 기술은 크게 두 부분으로 나뉜다. 첫째, 지역‑전역(local‑global) 상호작용 스키마를 도입해 엔터티와 삼중항 사이의 관계를 동시에 학습한다. 이는 개별 삼중항이 가진 미세한 의미와, 엔터티 레벨에서 드러나는 전반적인 맥락을 동시에 고려함으로써, 보다 풍부하고 일관된 지식 표현을 가능하게 한다. 둘째, 계층형 트랜스포머 기반 포인터 네트워크를 백본으로 사용해, 입력 문맥에 가장 적합한 엔터티와 삼중항을 선택한다. 포인터 메커니즘은 기존의 토큰‑레벨 선택 방식보다 더 직관적인 ‘지식 선택’ 과정을 제공하며, 선택된 지식이 실제 텍스트 생성에 어떻게 기여했는지를 추적할 수 있게 한다.
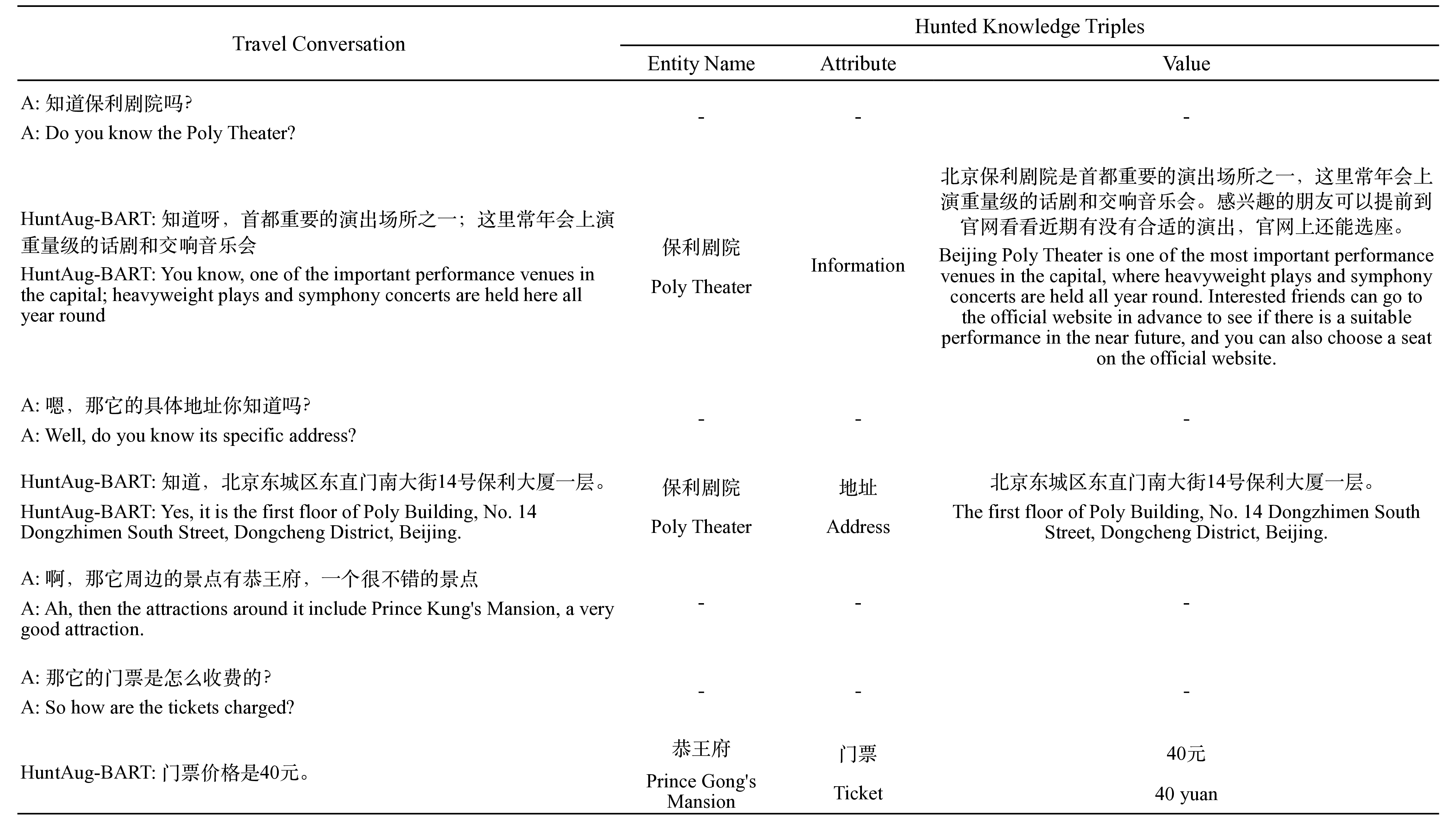
실험은 두 가지 서로 다른 시나리오에서 수행되었다. 첫 번째는 표‑텍스트 생성 작업인 RotoWireFG 데이터셋으로, 여기서는 내부 데이터(통계표)와 텍스트 사이의 정밀한 매핑이 요구된다. 두 번째는 외부 지식을 활용한 대화 응답 생성 작업인 KdConv 데이터셋으로, 여기서는 대화 흐름에 맞는 외부 사실 정보를 적절히 삽입하는 것이 핵심이다. 두 데이터셋 모두에서 제안 모델은 기존 최첨단 방법보다 높은 BLEU, ROUGE, 그리고 특히 지식 충실도(Faithfulness) 지표에서 우수한 성능을 보였다.
해석 가능성 측면에서도, 선택된 엔터티·삼중항 리스트를 출력함으로써 사용자는 ‘왜 이 문장이 생성됐는가’를 명시적으로 확인할 수 있다. 이는 특히 의료·법률·금융 등 고신뢰성이 요구되는 분야에서 중요한 장점이다. 그러나 몇 가지 한계도 존재한다. 첫째, 구조화된 지식이 충분히 풍부하지 않은 도메인에서는 사냥꾼이 선택할 후보가 제한되어 성능 저하가 발생할 수 있다. 둘째, 포인터 네트워크의 선택 과정이 여전히 ‘soft’하게 이루어지기 때문에, 완전한 투명성을 제공한다는 점에서는 한계가 있다. 셋째, 현재는 엔터티와 삼중항을 별도로 학습하지만, 이들을 통합된 그래프 형태로 다루어 보다 복합적인 관계를 모델링하는 방안은 추후 연구가 필요하다.
향후 연구 방향으로는 (1) 비구조화된 텍스트에서 자동으로 엔터티·삼중항을 추출하는 프리트레이닝 기법, (2) 선택된 지식과 생성 토큰 사이의 정량적 기여도를 측정하는 해석 메트릭, (3) 멀티모달(이미지·표) 지식과의 연계 등을 제시한다. 이러한 확장은 현재 모델을 더욱 범용적이고, 다양한 실제 응용에 적용 가능하도록 만들 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리