인도어 관광 질문응답 시스템: 도메인 적응 파운데이션 모델 활용
📝 원문 정보
- Title: Tourism Question Answer System in Indian Language using Domain-Adapted Foundation Models
- ArXiv ID: 2511.23235
- 발행일: 2025-11-28
- 저자: Praveen Gatla, Anushka, Nikita Kanwar, Gouri Sahoo, Rajesh Kumar Mundotiya
📝 초록 (Abstract)
본 연구는 힌디어 관광 분야, 특히 문화·영적 중심지인 바라나시를 대상으로 한 추출형 질문응답(QA) 시스템의 최초 종합적 구축을 시도한다. 가느가, 크루즈, 푸드코트, 공중화장실, 쿤드, 박물관, 일반, 아슈람, 사원, 여행 등 10개 하위 도메인을 목표로 하며, 힌디어에 특화된 QA 자원이 부족한 현실을 해결하고자 한다. 7,715개의 힌디어 QA 쌍을 직접 수집·구성한 뒤, Llama 제로샷 프롬프트를 이용해 27,455개의 추가 쌍을 생성하였다. BERT와 RoBERTa 기반 파운데이션 모델을 SFT와 파라미터 효율성을 높인 LoRA 방식으로 미세조정하여 성능을 비교하였다. 다양한 힌디어‑BERT 변형을 포함한 실험 결과, LoRA 기반 미세조정이 파라미터 98 %를 절감하면서도 85.3 %의 F1 점수로 경쟁력을 보였으며, RoBERTa‑SFT가 문화적 용어를 다루는 데 있어 BERT 변형보다 우수함을 확인하였다. 이 연구는 힌디어 관광 QA 시스템의 베이스라인을 제시하고, 저자원 환경에서 LoRA의 효용성을 강조한다.💡 논문 핵심 해설 (Deep Analysis)
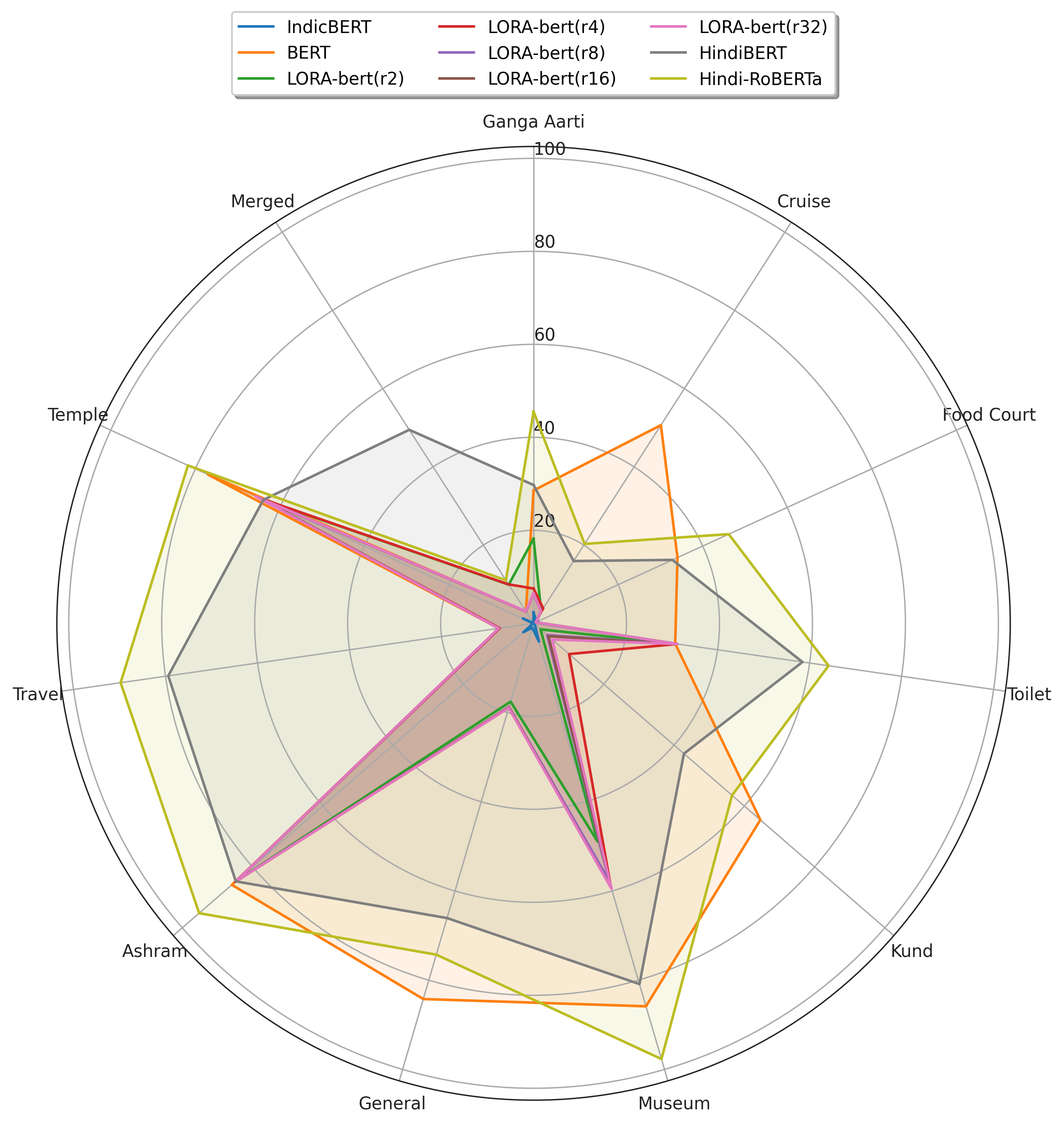
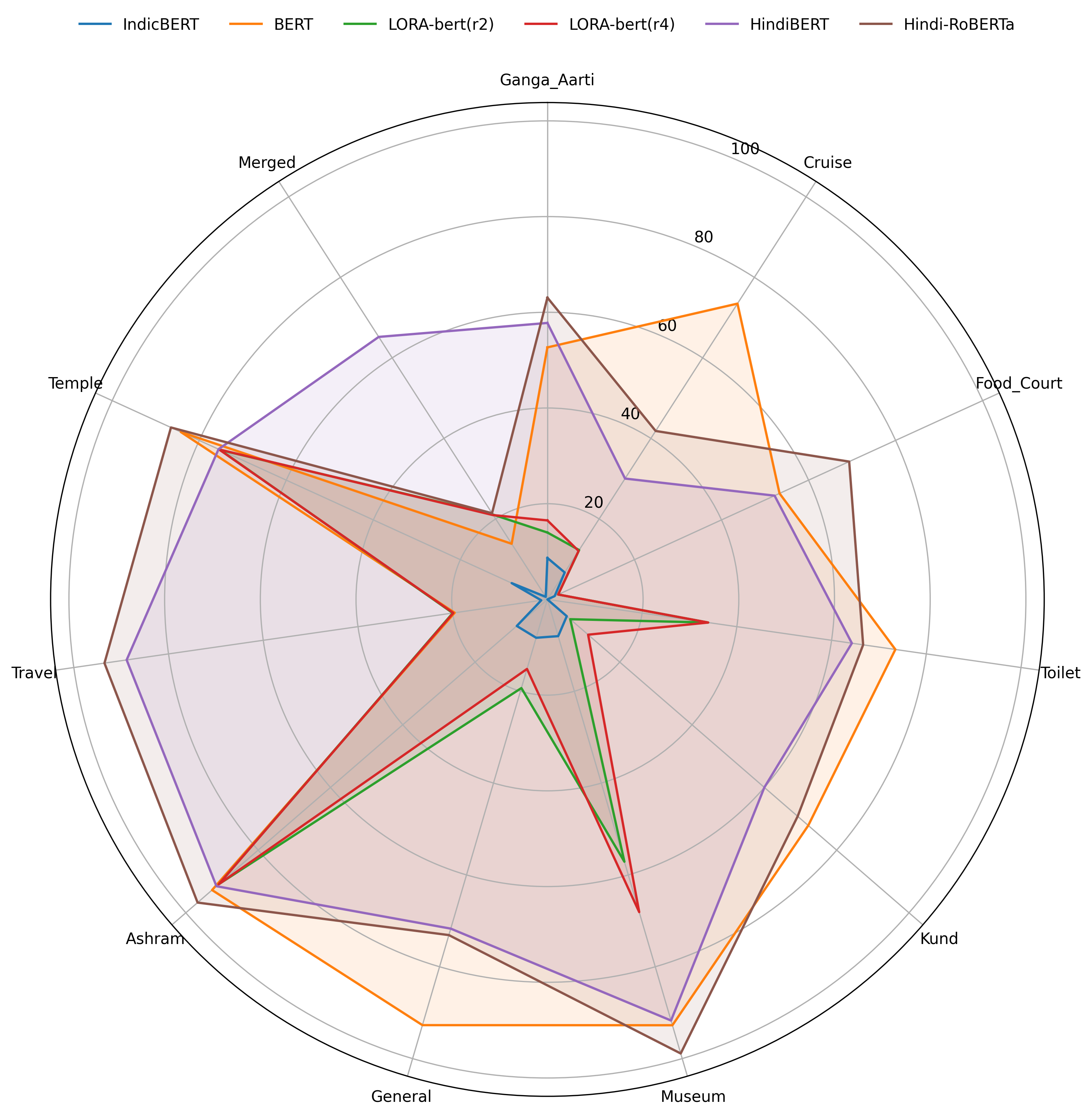
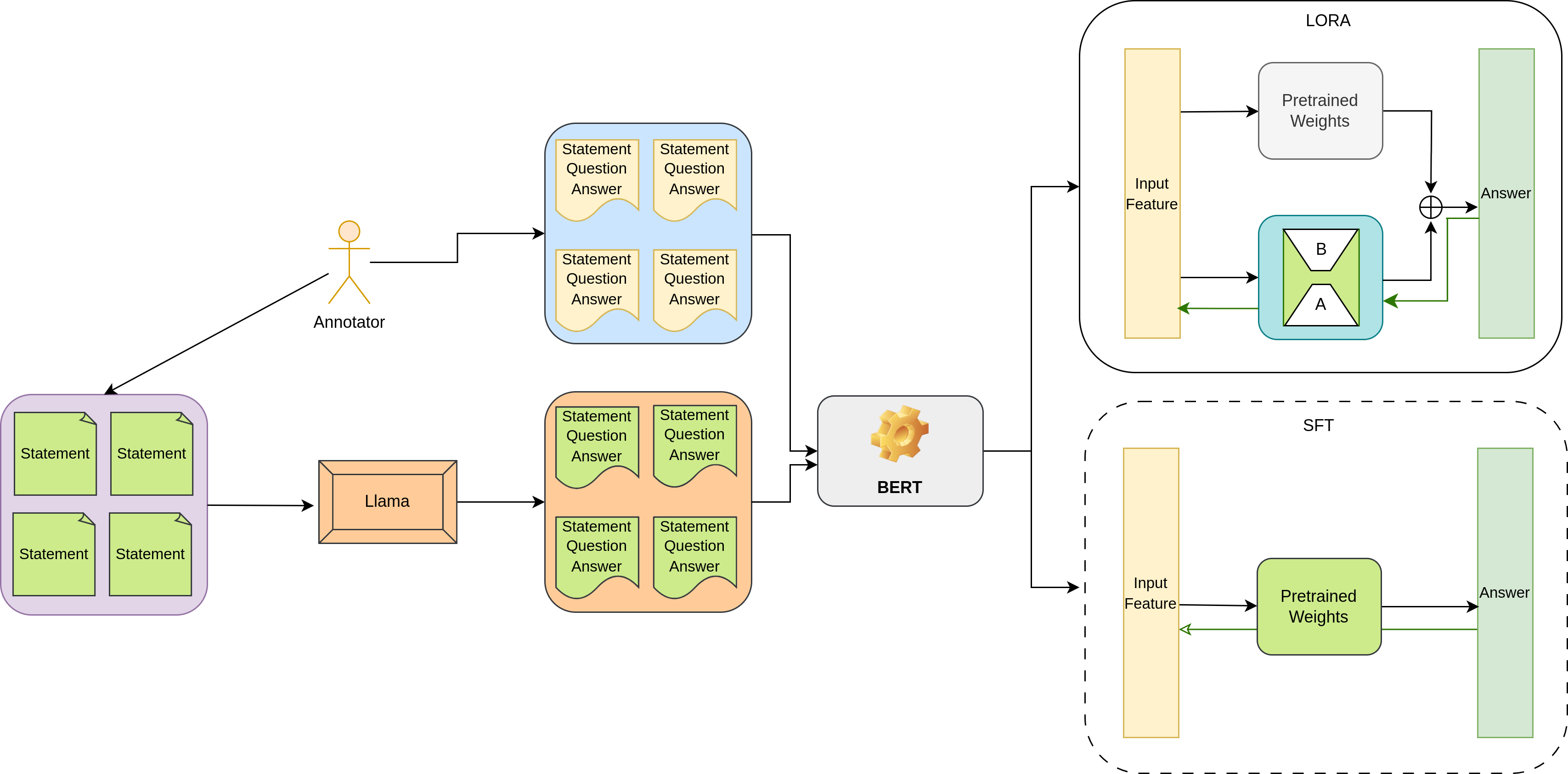
두 번째 난관은 모델 선택과 미세조정 전략이다. 저자들은 BERT와 RoBERTa 두 가지 파운데이션 모델을 선택했으며, 각각에 대해 전통적인 Supervised Fine‑Tuning(SFT)과 Low‑Rank Adaptation(LoRA)를 적용하였다. LoRA는 기존 가중치를 고정하고 소수의 저랭크 매트릭스만 학습함으로써 파라미터 효율성을 크게 높인다. 실험 결과, LoRA‑기반 미세조정이 전체 파라미터의 2 % 이하만 학습하면서도 85.3 %의 F1 점수를 기록, SFT 대비 98 % 파라미터 절감에도 성능 저하가 거의 없음을 입증했다. 이는 특히 리소스가 제한된 현지 기업이나 공공기관에서 실용적인 솔루션으로 활용될 가능성을 시사한다.
또한 모델별 성능 차이를 문화적 용어 처리 관점에서 분석하였다. RoBERTa‑SFT가 “아르티”, “쿤드” 등 힌디어 고유명사와 종교·문화적 개념을 더 정확히 추출했으며, 이는 RoBERTa가 더 깊은 양방향 컨텍스트와 대규모 사전학습 코퍼스를 기반으로 하기 때문으로 해석된다. 반면, 힌디어‑BERT 변형은 언어 특화 사전학습 덕분에 기본적인 어휘 이해는 뛰어나지만, 도메인 특화된 긴 문맥을 포착하는 데는 한계가 있었다.
평가 지표로는 F1 외에도 BLEU와 ROUGE‑L을 사용해 정밀도와 언어 유창성을 동시에 측정했는데, BLEU 점수는 합성 데이터 비중이 높을수록 상승하는 경향을 보였다. 이는 모델이 학습 데이터의 스타일을 모방하는 경향이 있음을 의미한다. 따라서 실제 현장에서의 적용을 위해서는 정답의 다양성을 확보하고, 인간 평가를 병행하는 것이 필요하다.
마지막으로, 논문의 한계와 향후 과제도 명확히 제시한다. 현재는 추출형 QA에 국한되어 있어 생성형 답변(Generative QA)이나 멀티모달(이미지·음성) 입력을 다루지 않는다. 또한, Varanasi에 특화된 데이터이므로 다른 인도 관광지로의 일반화 검증이 필요하다. 향후 연구에서는 멀티도메인 전이 학습, 사용자 피드백 기반 지속 학습, 그리고 실제 관광 안내 챗봇 서비스와의 연동을 통해 시스템의 실용성을 높일 수 있을 것이다.
요약하면, 이 연구는 저자원 언어·도메인 환경에서 효율적인 파운데이션 모델 활용 방안을 제시하고, LoRA가 파라미터 절감과 성능 유지 양면에서 유망함을 실증하였다. 문화·관광 분야의 특수성을 고려한 NLP 프레임워크 구축에 있어 중요한 선례가 될 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리