마인드파워: 비전‑언어 모델 기반 로봇의 이론‑정신(Theory‑of‑Mind) 추론 구현
📝 원문 정보
- Title: MindPower: Enabling Theory-of-Mind Reasoning in VLM-based Embodied Agents
- ArXiv ID: 2511.23055
- 발행일: 2025-11-28
- 저자: Ruoxuan Zhang, Qiyun Zheng, Zhiyu Zhou, Ziqi Liao, Siyu Wu, Jian-Yu Jiang-Lin, Bin Wen, Hongxia Xie, Jianlong Fu, Wen-Huang Cheng
📝 초록 (Abstract)
마인드파워는 로봇 중심의 프레임워크로, 인식·정신 추론·의사결정·행동을 통합한다. 다중모달 입력을 받아 환경과 인간의 상태를 먼저 인식한 뒤, 자체와 타인의 정신 상태를 모델링하는 ToM(Theory‑of‑Mind) 추론을 수행한다. 최종적으로 추론된 정신 상태에 기반해 의사결정과 행동을 생성한다. 또한, 정신 상태 추론을 강화하도록 설계된 새로운 최적화 목표인 Mind‑Reward를 도입하여 학습 효율성을 높인다.💡 논문 핵심 해설 (Deep Analysis)

-
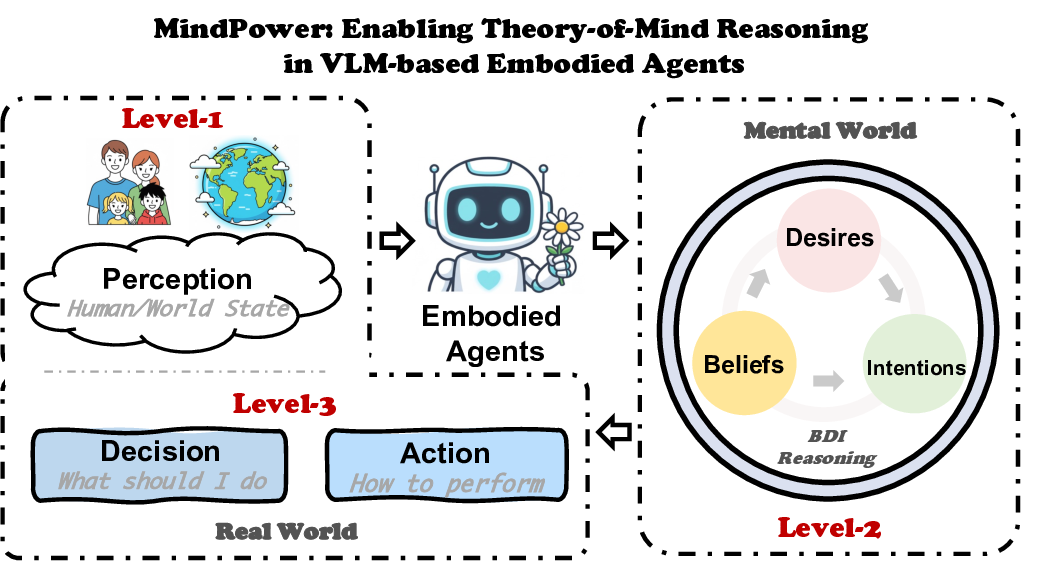
Perception (인식) 모듈: 멀티모달 센서(카메라, 마이크, 깊이 센서 등)에서 얻은 데이터를 VLM에 입력해 환경 맵과 인간의 행동·표정·음성 특징을 추출한다. 여기서 중요한 점은 VLM이 텍스트와 이미지를 동시에 처리함으로써 ‘사람이 무엇을 보고 있는가’, ‘어떤 감정을 표현하고 있는가’를 자연어 형태로 변환한다는 것이다.
-
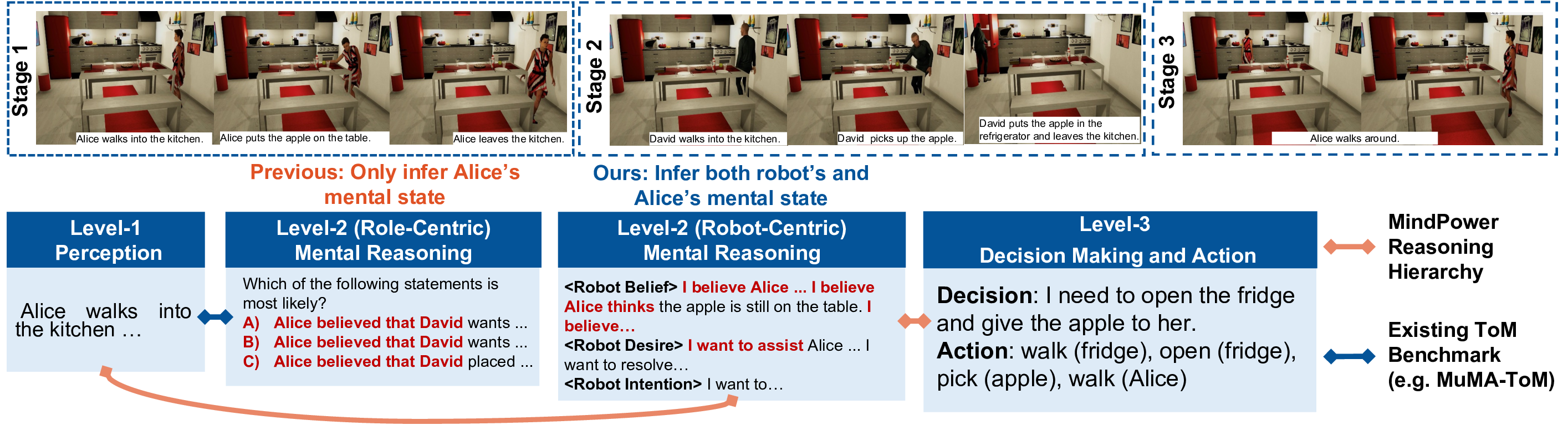
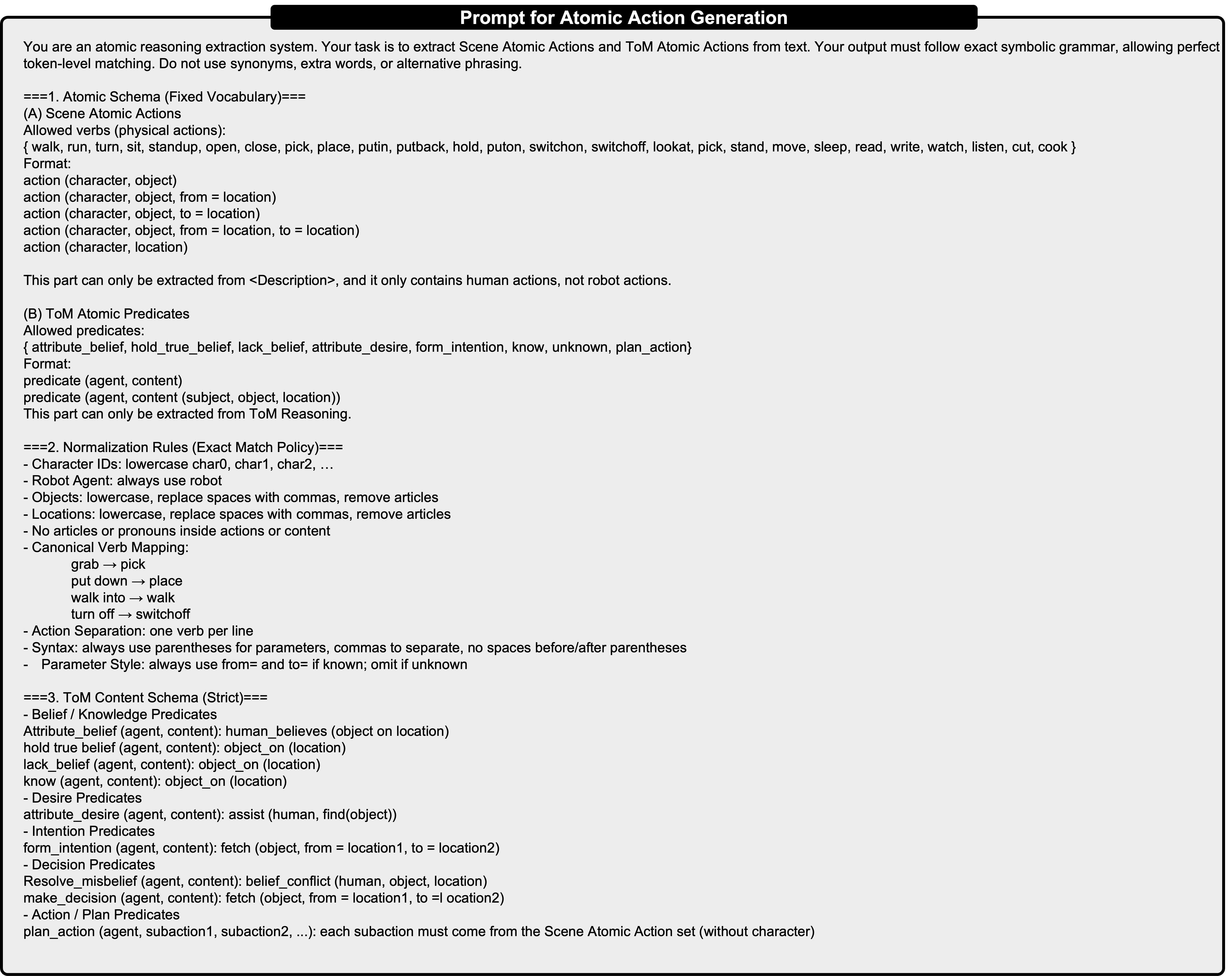
Mental Reasoning (정신 추론) 모듈: 인식 결과를 바탕으로 ToM 그래프를 구성한다. 그래프 노드는 ‘에이전트 자신’, ‘관찰된 인간1’, ‘관찰된 인간2’ 등이며, 각 노드에 ‘신념(belief)’, ‘욕구(desire)’, ‘의도(intent)’와 같은 정신 상태 변수를 할당한다. 논문은 이 과정을 Transformer 기반의 인코더‑디코더 구조로 구현했으며, 손실 함수에 인간의 실제 의도 라벨(가능한 경우)과 일치하도록 하는 ‘Mind‑Reward’를 추가한다.
-
Decision Making (의사결정) 모듈: 추론된 정신 상태를 정책 네트워크에 전달한다. 정책은 강화학습(RL) 혹은 행동 계획(planning) 방식으로 구현될 수 있는데, 마인드파워는 특히 ‘상호협조적 행동(cooperative action)’을 목표로 하는 경우, 상대방의 욕구를 만족시키는 보상을 추가한다. 이는 기존 RL 보상에 ‘사회적 보상(social reward)’을 더한 형태이며, Mind‑Reward와의 시너지 효과를 기대한다.
-
Action (행동) 모듈: 최종 정책에 따라 로봇 팔, 이동, 음성 출력 등 물리적 행동을 실행한다. 여기서 중요한 점은 행동이 실시간으로 피드백 루프에 들어가 인식‑추론‑결정‑행동 사이클을 지속적으로 갱신한다는 것이다.
Mind‑Reward는 논문의 핵심 기여 중 하나이다. 일반적인 RL에서는 보상이 외부 환경에 의해 정의되지만, Mind‑Reward는 ‘정신 상태와 일치하는 행동’을 보상한다. 구체적으로, 인간이 기대하는 행동(예: 물건을 건네줄 때 손을 내밀면)과 로봇이 실제로 수행한 행동 사이의 거리(예: KL divergence)를 최소화하도록 설계되었다. 이는 로봇이 단순히 목표 위치에 도달하는 것이 아니라, 인간의 내재된 의도를 파악하고 그에 맞는 사회적 행동을 학습하도록 만든다.
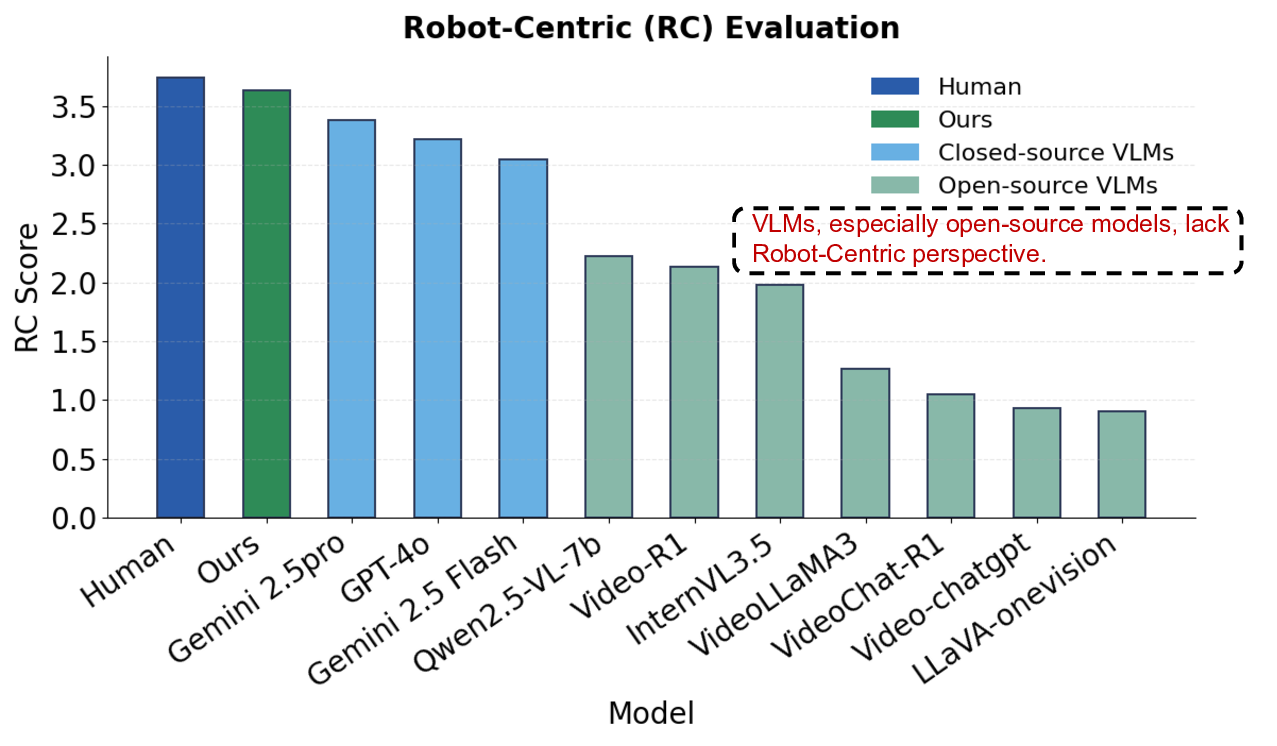
장점으로는 (1) 인간‑로봇 상호작용에서 자연스러운 협업을 가능하게 하는 고차원 인지 모델 제공, (2) VLM의 강력한 멀티모달 이해 능력을 ToM 추론에 직접 연결, (3) Mind‑Reward를 통한 학습 효율성 및 안정성 향상이 있다.
한계는 아직 실험이 제한된 시뮬레이션 환경에 머물러 있다는 점이다. 실제 물리 로봇에 적용할 경우 센서 노이즈, 실시간 연산 비용, 인간의 복잡한 정신 상태(예: 모호한 의도, 다중 목표) 등을 처리해야 한다. 또한, ToM 그래프의 변수 설계가 도메인에 따라 크게 달라질 수 있어 일반화가 어려울 수 있다.
향후 연구는 (1) 실시간 추론을 위한 경량화 모델 개발, (2) 인간 피드백을 통한 온라인 Mind‑Reward 조정, (3) 다중 인간 에이전트 상황에서의 협업 ToM 확장, (4) 윤리적·안전성 검증을 포함한 실제 서비스 적용 테스트 등이 제시된다. 전반적으로 마인드파워는 VLM 기반 로봇에 사회적 인지를 부여하는 중요한 첫걸음이며, 향후 인간 중심 로봇 시스템의 설계 패러다임을 바꿀 잠재력을 지닌다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리