불변 텐서 아키텍처 보안 에너지 효율 AI 추론을 위한 순수 데이터플로우 접근
📝 원문 정보
- Title: The Immutable Tensor Architecture: A Pure Dataflow Approach for Secure, Energy-Efficient AI Inference
- ArXiv ID: 2511.22889
- 발행일: 2025-11-28
- 저자: Fang Li
📝 초록 (Abstract)
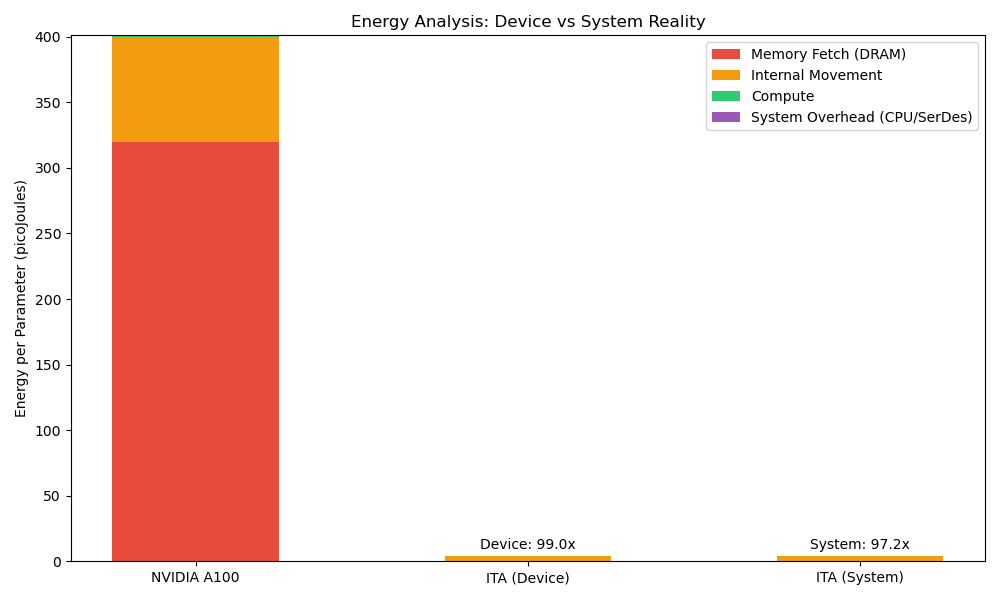
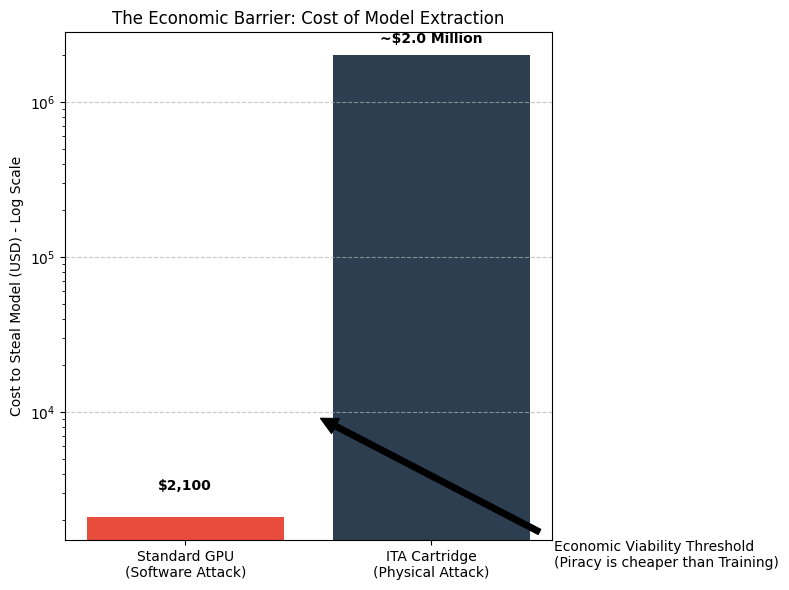
대형 언어 모델(LLM)을 소비자 엣지 디바이스에 배치하는 데 가장 큰 제약은 “메모리 월”이다. 토큰을 생성할 때마다 수 기가바이트에 달하는 모델 가중치를 DRAM에서 가져와야 하는데, 이는 대역폭과 에너지 비용을 급격히 증가시킨다. 기존 GPU·NPU와 같은 아키텍처는 가중치를 가변적인 소프트웨어 데이터로 취급해 범용성을 유지하지만, 그 대가로 막대한 에너지 손실을 감수한다. 본 논문에서는 가중치를 데이터가 아니라 물리적인 회로 토폴로지로 간주하는 새로운 패러다임, 즉 불변 텐서 아키텍처(ITA)를 제안한다. 28 nm·40 nm 성숙 공정의 ASIC에 파라미터를 금속 인터커넥트와 로직에 직접 인코딩함으로써 메모리 계층을 완전히 제거한다. 호스트 CPU가 동적 KV‑cache를 관리하고 ITA ASIC이 무상태 ROM‑내장 데이터플로우 엔진으로 동작하는 “스플릿‑브레인” 시스템 설계를 제시한다. 논리 수준 시뮬레이션 결과, 이론적 한계에서 MAC당 게이트 수를 4.85배 감소(243 gate vs 1 180 gate)시켰으며, 라우팅 오버헤드를 고려한 보수적 추정에서는 1.62배의 시스템 수준 감소를 보인다. 물리적 에너지 모델링은 50배 이상의 디바이스 레벨 에너지 효율 향상(4.05 pJ/연산 vs 201 pJ/연산)을 확인하고, 호스트 CPU와 인터페이스를 포함한 전체 시스템 전력 분석에서는 10‑15배 효율 향상을 제시한다. FPGA 프로토타입 검증을 통해 상수 계수 곱셈기에 대해 1.81배 LUT 감소를 실증했으며, 이는 효율성 하한을 경험적으로 입증한다. 실용적인 배치를 위해 TinyLlama‑1.1B는 28 nm 520 mm² 단일 모노리식 다이 하나에, Llama‑2‑7B는 8칩렛 구성을 필요로 한다. 인터페이스는 PCIe(M.2 NVMe), Thunderbolt, USB 등에 종속되지 않는다. 제조 비용 분석에 따르면 100 K 이상 대량 생산 시 1.1 B 모델은 약 $52, 7 B 모델은 약 $165(10 K 생산 시 NRE 포함 $264‑$377)가 예상된다. 디바이스 전력 소모는 1‑3 W이며, 호스트 CPU 포함 전체 시스템 전력은 7‑12 W이다. 이론적인 인터페이스 대역폭은 초당 125‑200 토큰을 지원하지만, 현재 호스트 측 어텐션 처리 한계로 실질적인 처리량은 전용 NPU 가속이 없을 경우 초당 10‑20 토큰에 머문다. ITA는 모델 추출 비용을 $2 000(소프트웨어 덤프)에서 $50 000(특수 역공학 장비) 이상으로 상승시켜 보안성을 높이지만, 사이드채널 취약점에 대한 완화가 필요함을 인정한다.💡 논문 핵심 해설 (Deep Analysis)
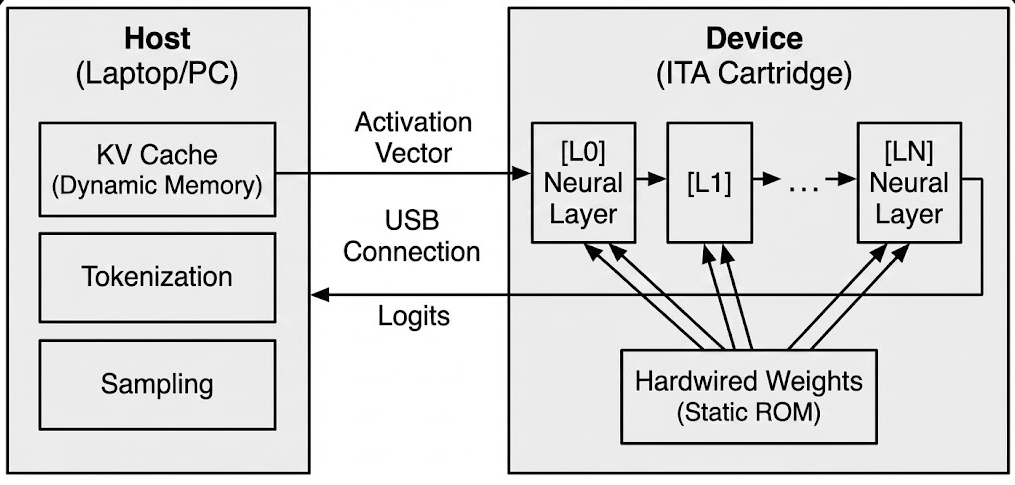
하지만 실현 가능성 측면에서 몇 가지 중요한 과제가 남아 있다. 첫째, 가중치를 회로에 직접 인코딩하려면 설계 단계에서 모델 파라미터가 확정돼야 한다. 이는 모델 업데이트나 파인튜닝을 거의 불가능하게 만들며, 시장에서 빠르게 변하는 AI 요구에 대응하기 어렵다. 논문은 “스플릿‑브레인” 구조로 동적 KV‑cache를 호스트가 담당하게 함으로써 일부 유연성을 확보하지만, 전체 모델 파라미터가 고정된 상태에서는 새로운 토큰에 대한 어텐션 가중치 계산 외에 다른 가변 연산을 수행할 여지가 제한적이다.
둘째, ASIC 설계 비용과 시간도 무시할 수 없다. 28 nm·40 nm 공정은 비용 효율적이지만, 가중치마다 라우팅을 재구성해야 하는 설계 흐름은 기존 표준 셀 기반 설계보다 복잡하고, NRE(Non‑Recurring Engineering) 비용이 수백만 달러에 이를 가능성이 있다. 논문은 10 K~100 K 규모 생산 시 $264‑$377 정도의 비용을 제시하지만, 이는 초기 NRE를 포함한 추정이며, 실제 시장에 진입하기 위해서는 수십만 단위 이상의 주문량이 필요할 것이다.
셋째, 라우팅 오버헤드와 전력 손실을 보수적으로 추정했음에도 불구하고, 실제 실리콘 구현 시 예상보다 높은 누설 전류와 온도 상승 문제가 발생할 수 있다. 특히 28 nm 공정에서는 금속 인터커넥트에 고정된 가중치가 많은 경우, 배선 밀도가 급격히 증가해 전력 분산 및 신호 무결성 문제가 대두된다. 이러한 물리적 제약은 논문이 제시한 1‑3 W 디바이스 전력 목표를 달성하기 위해 추가적인 전력 관리 회로가 필요하게 만든다.
또한, 인터페이스 대역폭이 이론적으로는 초당 125‑200 토큰을 지원한다 하더라도, 현재 호스트 CPU가 어텐션 연산을 담당하면서 실질적인 처리량이 초당 10‑20 토큰에 머무른다는 점은 시스템 전체 성능이 여전히 CPU에 크게 의존한다는 것을 의미한다. 이는 ITA가 전용 NPU 가속 없이도 충분히 실용적인 수준에 도달하기 위해서는 호스트 측 연산 최적화가 필수적임을 시사한다.
보안 측면에서 모델 추출 비용을 $2 000에서 $50 000 이상으로 끌어올린다는 주장은 흥미롭지만, 사이드채널 공격(전력 분석, 전자기 방출 등)을 통해 회로에 내장된 가중치를 역추적할 가능성을 완전히 배제하지 못한다. 논문 자체도 이러한 취약점을 인정하고 완화 방안을 제시하지 않아, 실제 보안 효과는 아직 검증되지 않았다.
종합하면, ITA는 메모리 월을 회피하고 에너지 효율을 극대화하려는 혁신적인 아이디어를 제공한다. 그러나 모델 유연성, 설계 비용, 물리적 라우팅 한계, 호스트 연산 병목, 사이드채널 보안 등 실용화에 앞서 해결해야 할 과제가 다수 존재한다. 향후 연구에서는 가중치 재프로그램 가능성을 위한 재구성 가능한 메모리(예: MRAM, RRAM)와 결합하거나, 부분 가중치만 고정하고 나머지는 전통적인 메모리에서 로드하는 하이브리드 접근법을 탐색함으로써 유연성과 효율성 사이의 트레이드오프를 개선할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리