시각적 근거 학습으로 비전‑언어 추론 혁신
📝 원문 정보
- Title: From Illusion to Intention: Visual Rationale Learning for Vision-Language Reasoning
- ArXiv ID: 2511.23031
- 발행일: 2025-11-28
- 저자: Changpeng Wang, Haozhe Wang, Xi Chen, Junhan Liu, Taofeng Xue, Chong Peng, Donglian Qi, Fangzhen Lin, Yunfeng Yan
📝 초록 (Abstract)
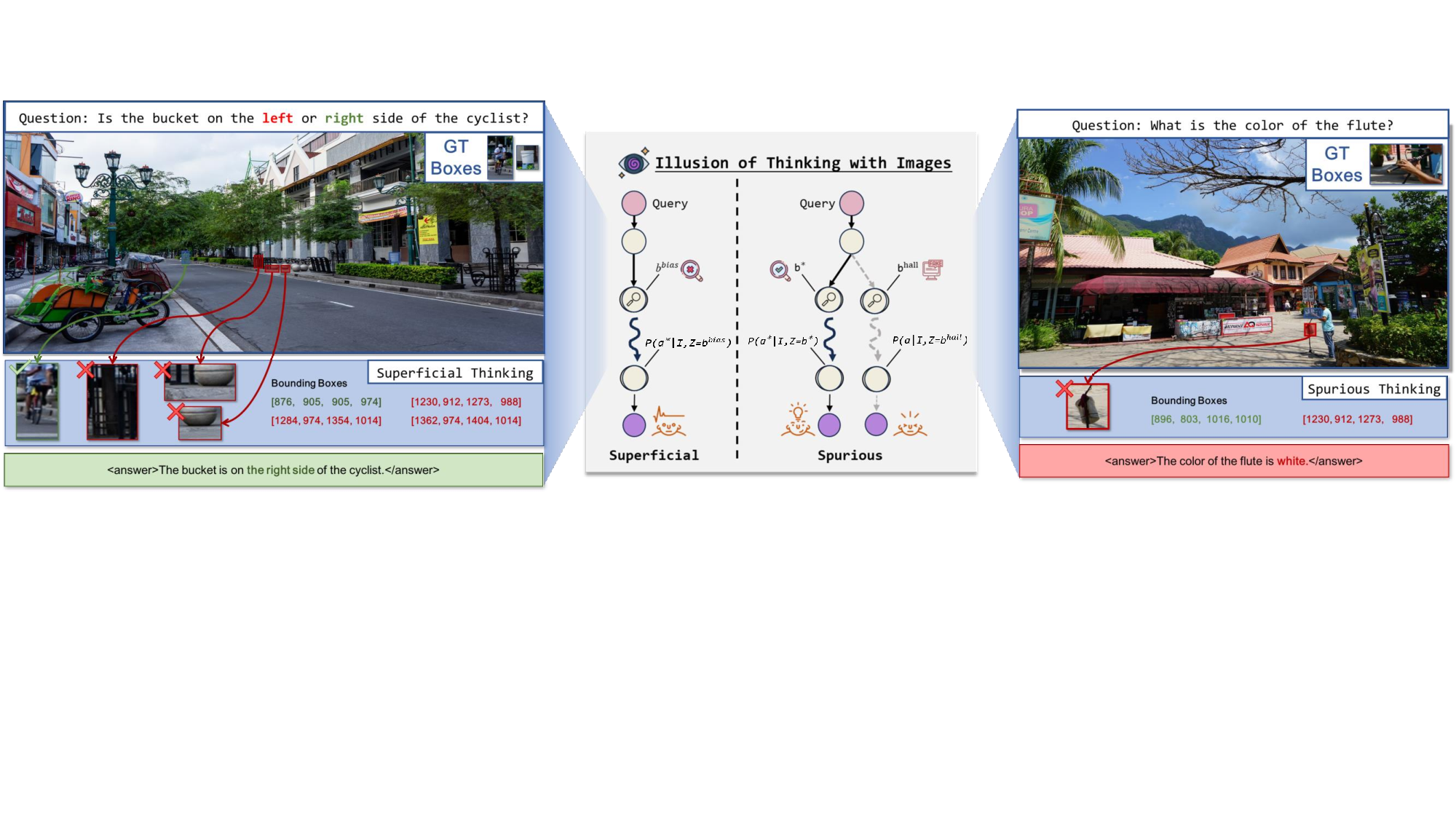
최근 비전‑언어 추론 분야에서는 모델이 이미지와 함께 사고하는 능력이 강조되고 있다. 그러나 기존 프레임워크는 시각적 행동을 선택적 도구로만 취급해 성능은 올리지만, 실제 추론 과정이 시각에 기반하지 못하고 시각적 행동이 의미 없는 형태로 남는다. 이를 ‘시각적 사고의 환상’이라 부른다. 본 연구는 시각적 행동을 선택이 아닌 핵심 추론 원시(primitives)로 재정의하고, 이를 텍스트 체인‑오브‑쓰루의 시각적 대응인 ‘시각적 근거(visual rationalization)’라 명명한다. 이를 바탕으로 Visual Rationale Learning(ViRL)이라는 종단‑to‑종단 학습 패러다임을 제안한다. ViRL은 (1) 실제 근거를 이용한 과정 감독, (2) 단계별 보상 형태의 목표 정렬, (3) 올바른, 중복된, 오류 행동을 구분하는 미세한 신용 할당을 통합한다. 각 행동이 추론 사슬에 의미 있게 기여하도록 함으로써 모델이 ‘올바른 시각적 근거로 올바른 답을 얻는다’는 목표를 달성한다. 순수 강화학습 기반 학습에도 불구하고 ViRL은 인식, 환각, 추론 등 다양한 벤치마크에서 최첨단 성능을 기록한다. 이 작업은 시각적 근거를 작업에 구애받지 않는, 과정‑기반 투명·검증 가능한 비전‑언어 모델 구축을 위한 패러다임으로 제시한다.💡 논문 핵심 해설 (Deep Analysis)
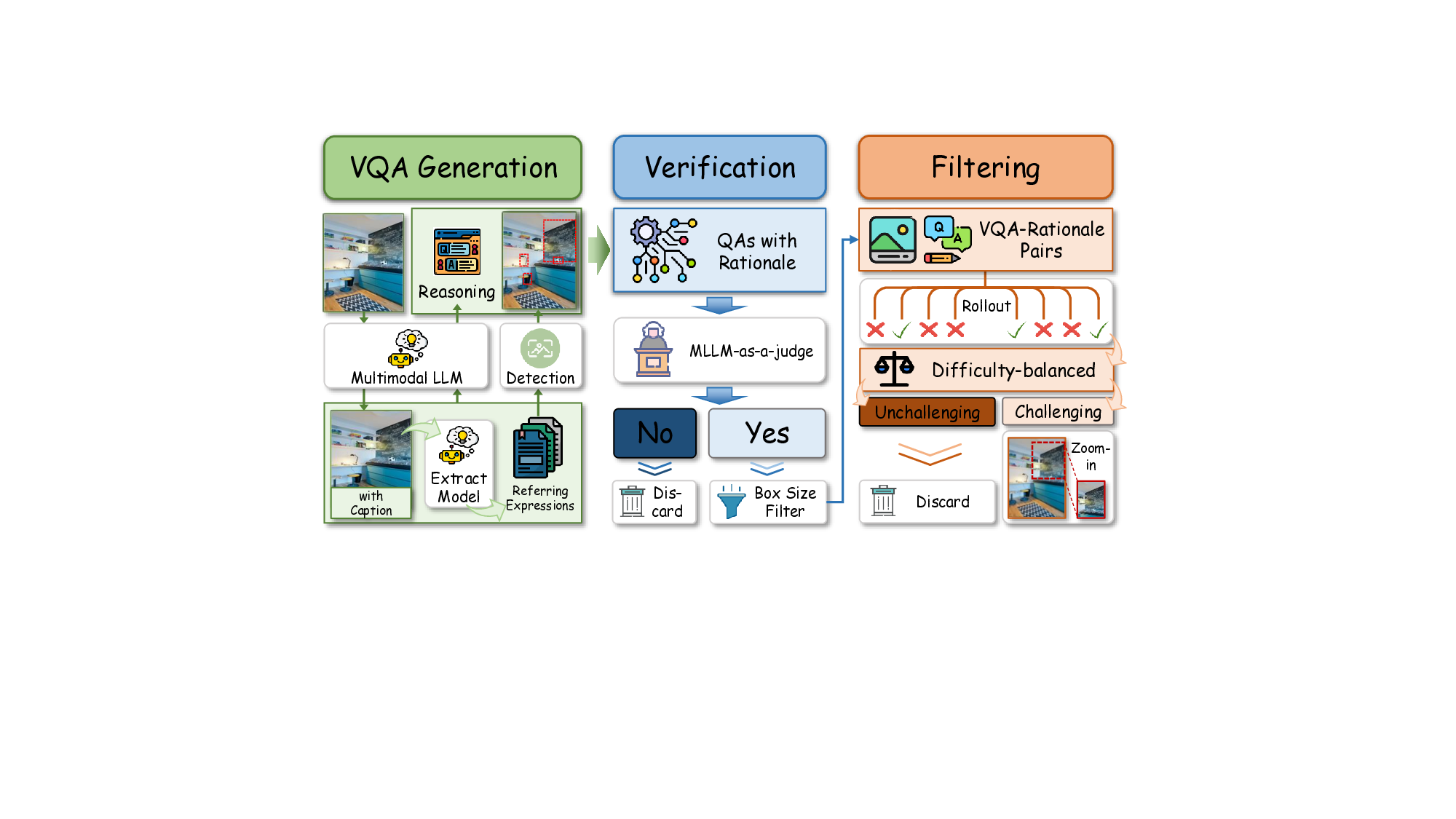
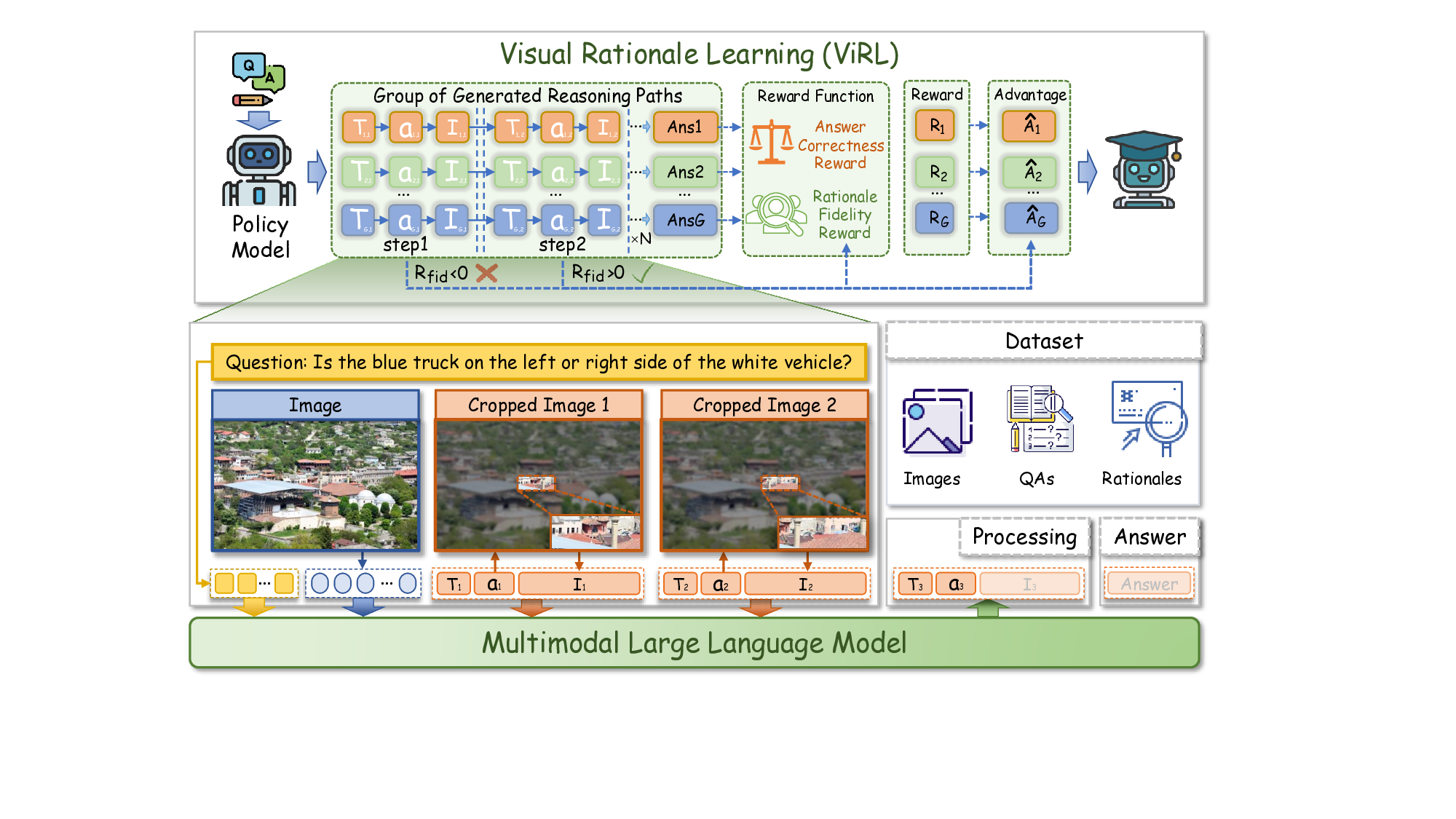
이를 해결하기 위해 저자들은 시각적 행동을 “선택적 도구”가 아니라 “핵심 추론 원시(primitives)”로 재구성한다. 즉, 모델이 수행하는 각 시각적 액션(예: 영역 탐색, 객체 강조, 속성 추출 등)이 추론 단계마다 명시적인 근거가 되도록 강제한다. 이 개념을 텍스트 체인‑오브‑쓰루(Chain‑of‑Thought)의 시각적 대응인 ‘시각적 근거(visual rationalization)’라 부른다.
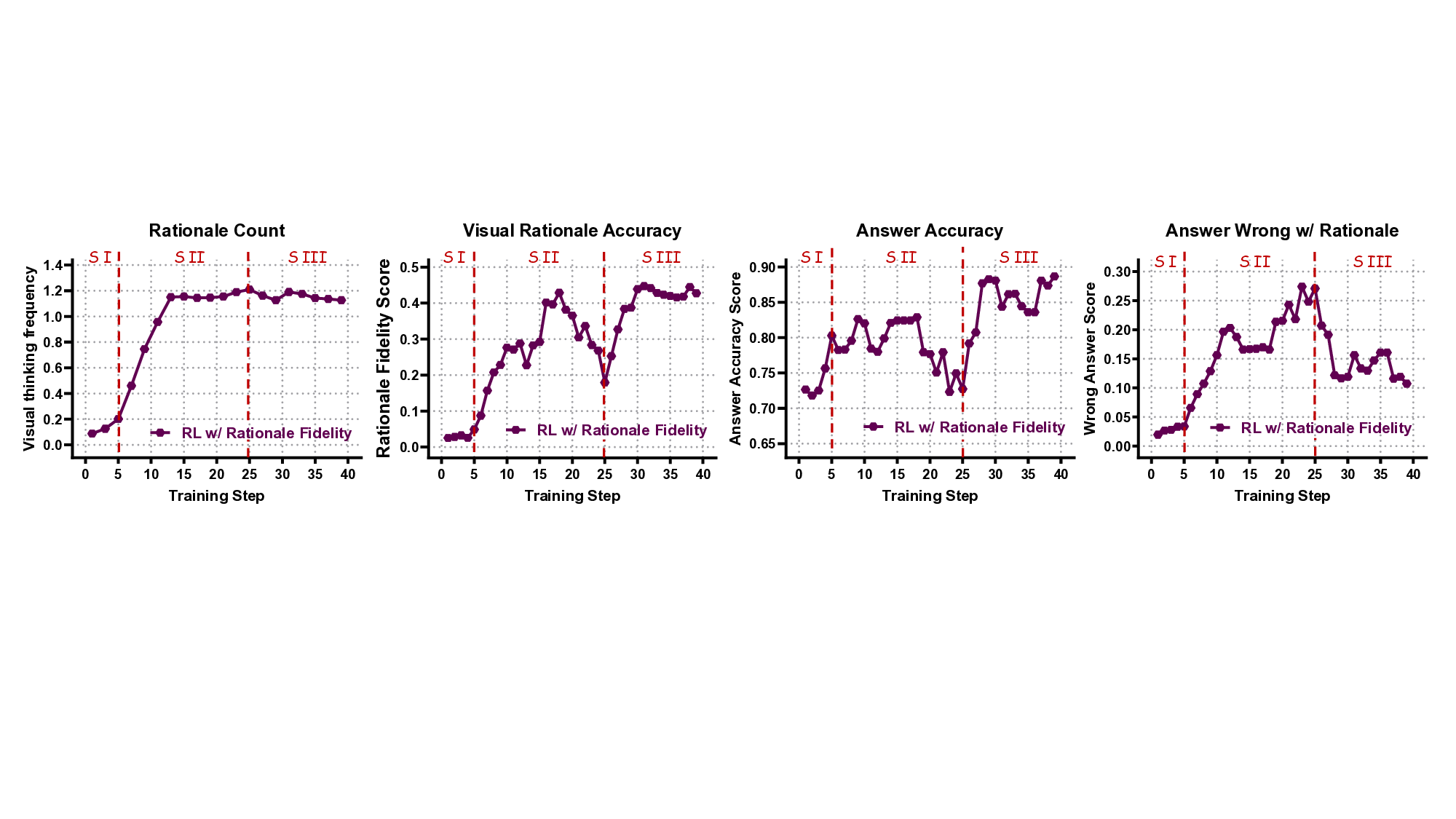
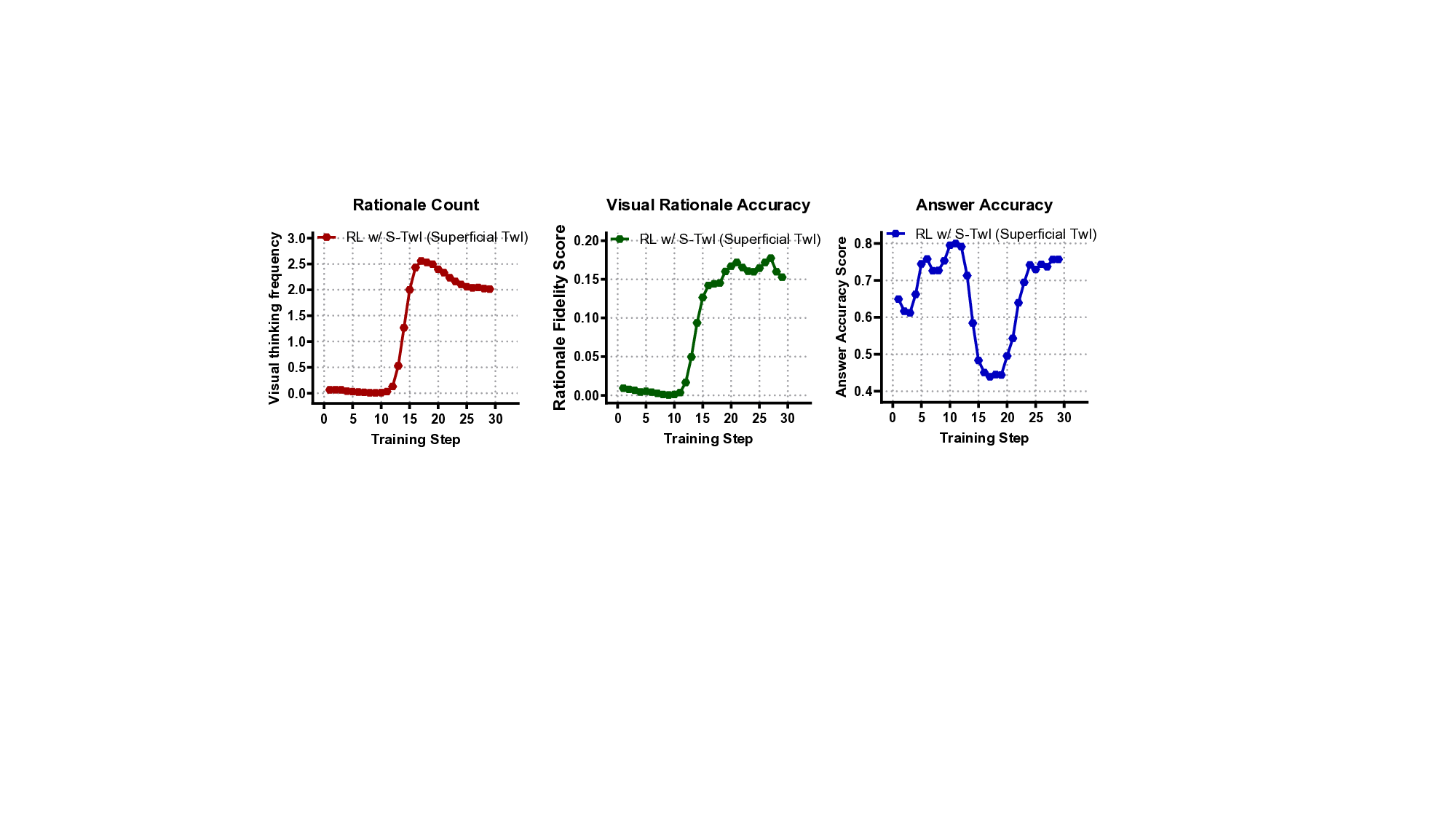
ViRL(Visual Rationale Learning) 프레임워크는 세 가지 핵심 메커니즘으로 구성된다.
- Process Supervision(과정 감독): 기존의 정답 라벨만을 이용한 학습이 아니라, 인간이 제공한 시각적 근거(예: 단계별 마스크, 관심 영역)를 정답으로 사용해 모델이 올바른 시각적 행동 순서를 학습하도록 한다. 이는 행동 수준에서의 지도학습을 강화함으로써 “왜 이 영역을 선택했는가”라는 질문에 답할 수 있게 만든다.
- Objective Alignment(목표 정렬): 강화학습 보상 함수를 단계별 보상(reward shaping) 형태로 설계한다. 즉, 올바른 시각적 행동을 수행하면 즉시 보상이 주어지고, 잘못된 혹은 중복된 행동은 패널티를 부여한다. 이를 통해 최종 정답 정확도뿐 아니라 과정 전체의 효율성도 최적화한다.
- Fine‑Grained Credit Assignment(미세 신용 할당): 행동을 ‘정확(correct)’, ‘중복(redundant)’, ‘오류(erroneous)’ 세 카테고리로 구분하고, 각각에 맞는 보상/패널티를 할당한다. 이 메커니즘은 특히 복합 질문에서 여러 단계의 시각적 조작이 필요할 때, 불필요한 반복을 억제하고 핵심 단계에 집중하도록 만든다.
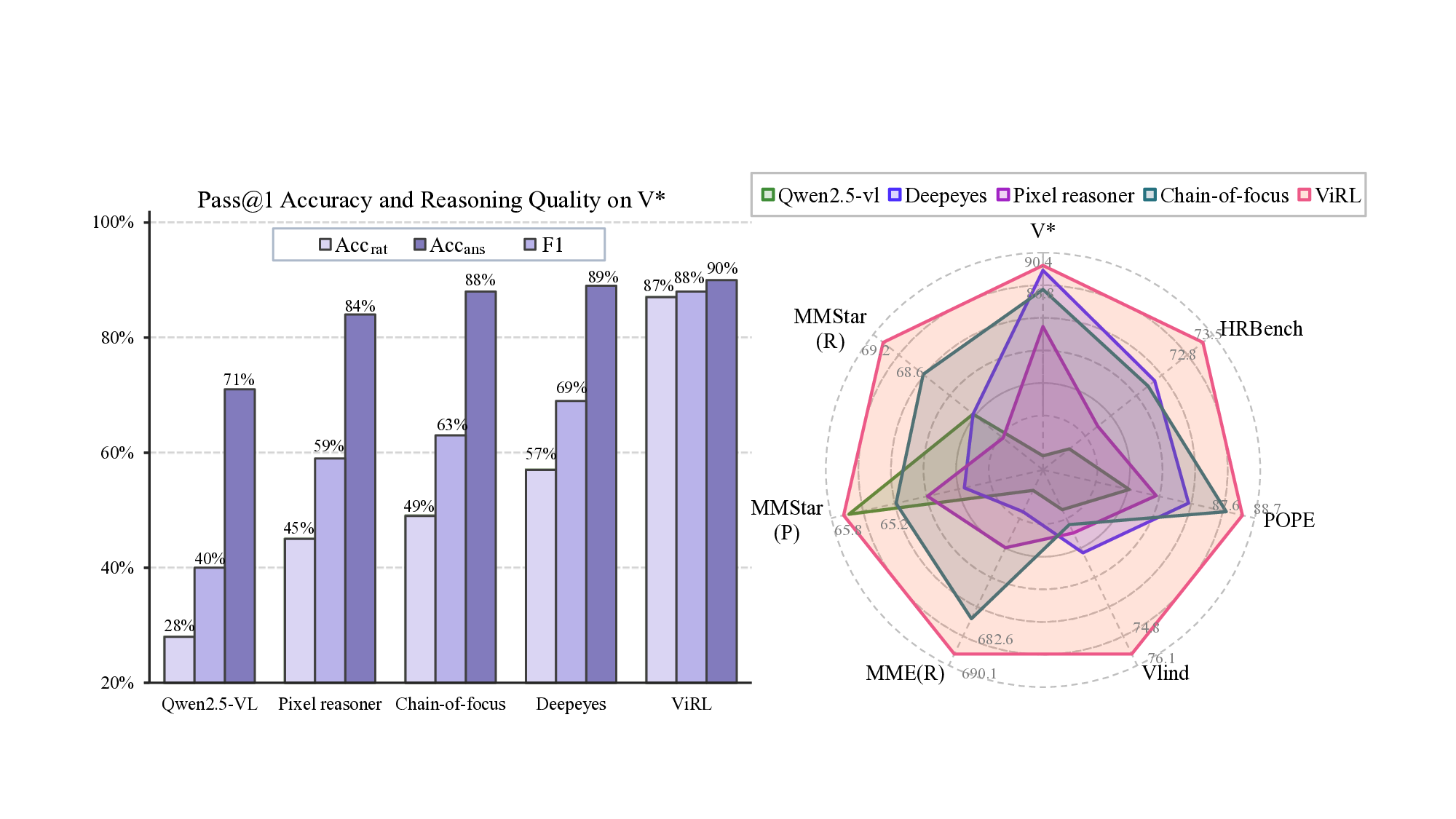
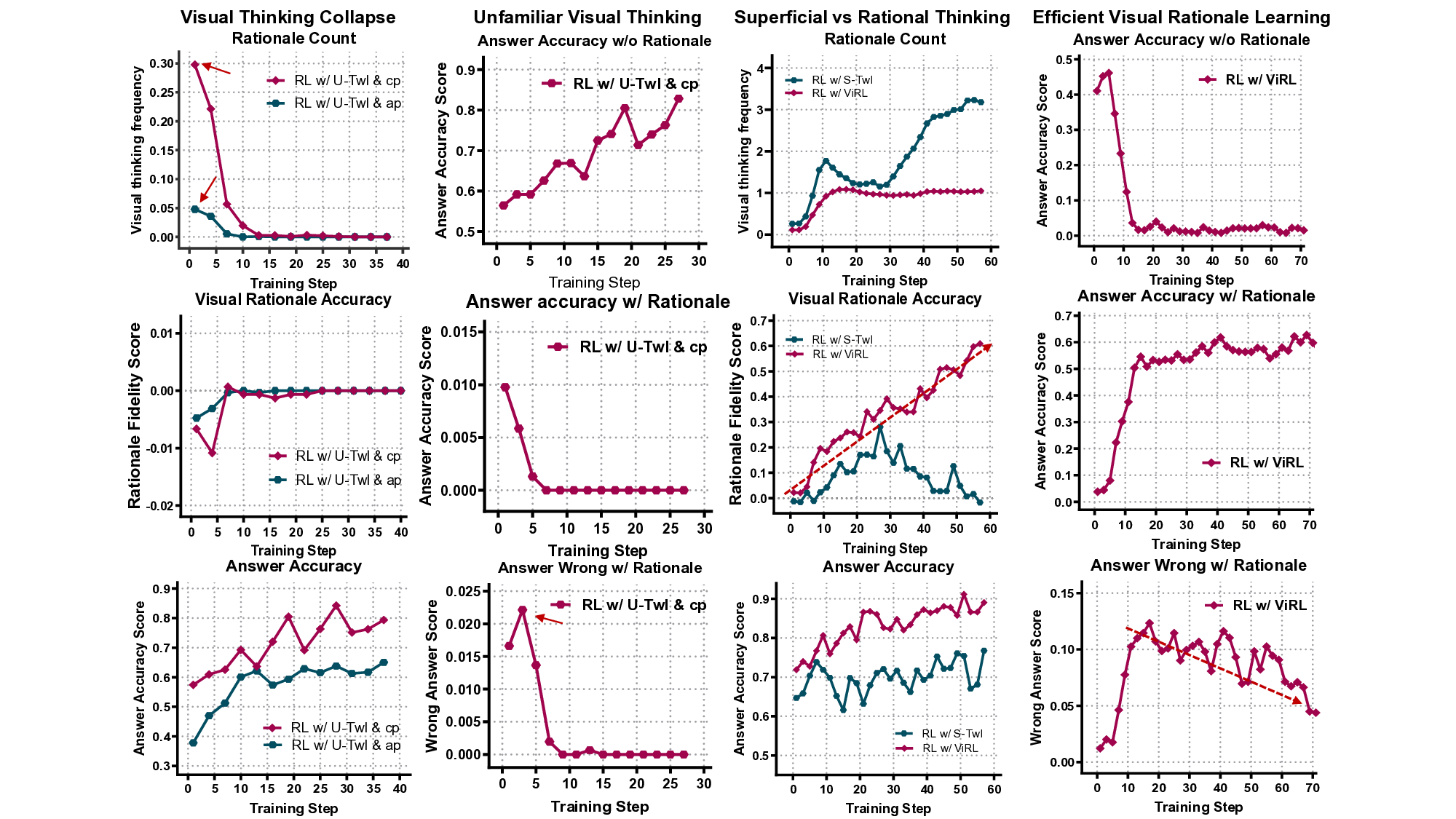
실험 결과는 눈에 띈다. ViRL은 VQA‑X, GQA, VCR 등 인식·추론·환각 방지 측면에서 기존 SOTA 모델을 능가한다. 특히 ‘시각적 근거 일관성(visual rationale consistency)’ 지표에서 큰 폭의 개선을 보였으며, 인간 평가에서도 “답변이 시각적 근거와 잘 맞는다”는 높은 점수를 받았다. 이는 모델이 단순히 정답을 맞추는 것이 아니라, 이미지 내부의 구체적 증거를 기반으로 추론한다는 의미다.
학문적·산업적 함의도 크다. 첫째, ViRL은 투명하고 검증 가능한 VL 시스템 구축에 기여한다. 시각적 근거가 명시되면 모델의 오류 원인을 추적하고, 위험한 상황(예: 의료 영상 진단)에서 신뢰성을 확보할 수 있다. 둘째, 과정‑기반 학습은 데이터 효율성을 높인다. 인간이 제공한 근거는 비교적 적은 양으로도 강력한 지도 역할을 하며, 대규모 라벨링 비용을 절감한다. 셋째, 이 패러다임은 다른 멀티모달 영역(예: 오디오‑텍스트, 로봇 제어)에도 확장 가능하다. 시각적 근거를 ‘작업에 구애받지 않는’ 추론 원시로 보는 관점은 멀티모달 인공지능의 일반화와 신뢰성을 동시에 추구하는 새로운 연구 방향을 제시한다.
요약하면, 이 논문은 “시각적 행동을 선택적 도구에서 핵심 추론 원시로 전환”하고, 이를 강화학습 기반의 세밀한 과정 감독·보상·신용 할당 메커니즘과 결합함으로써, 비전‑언어 모델이 진정으로 이미지와 함께 사고하도록 만든다. 이는 향후 투명하고 신뢰할 수 있는 멀티모달 AI 시스템 개발에 중요한 이정표가 될 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리