데이터셋 양자화 기반 적응형 압축으로 보는 새로운 프루닝 패러다임
📝 원문 정보
- Title: Adaptive Dataset Quantization: A New Direction for Dataset Pruning
- ArXiv ID: 2512.05987
- 발행일: 2025-11-28
- 저자: Chenyue Yu, Jianyu Yu
📝 초록 (Abstract)
본 논문은 자원 제한이 있는 엣지 디바이스에서 대규모 데이터셋의 저장·통신 비용을 감소시키기 위해, 샘플 내부의 중복 정보를 제거하는 새로운 데이터셋 양자화 기법을 제안한다. 기존의 데이터셋 프루닝·디스틸레이션이 샘플 간 중복에 초점을 맞추는 반면, 제안 방법은 각 이미지의 불필요하거나 정보량이 낮은 부분을 낮은 비트로 표현하면서 핵심 특징은 보존한다. 먼저 선형 대칭 양자화를 통해 각 샘플별 초기 양자화 범위와 스케일을 계산하고, 이후 적응형 양자화 할당 알고리즘을 도입해 전체 압축 비율을 일정하게 유지하면서 정밀도가 요구되는 샘플에 더 높은 비트를 할당한다. 주요 기여는 (1) 제한된 비트 수로 데이터셋을 표현해 저장량을 크게 줄인 최초의 시도, (2) 데이터셋 수준에서 적응형 비율을 할당하는 양자화 알고리즘 제안, (3) CIFAR‑10/100 및 ImageNet‑1K에 대한 광범위한 실험을 통해 동일 압축 비율 하에서 기존 양자화·프루닝 방법보다 학습 성능을 더 잘 유지함을 입증한 점이다.💡 논문 핵심 해설 (Deep Analysis)
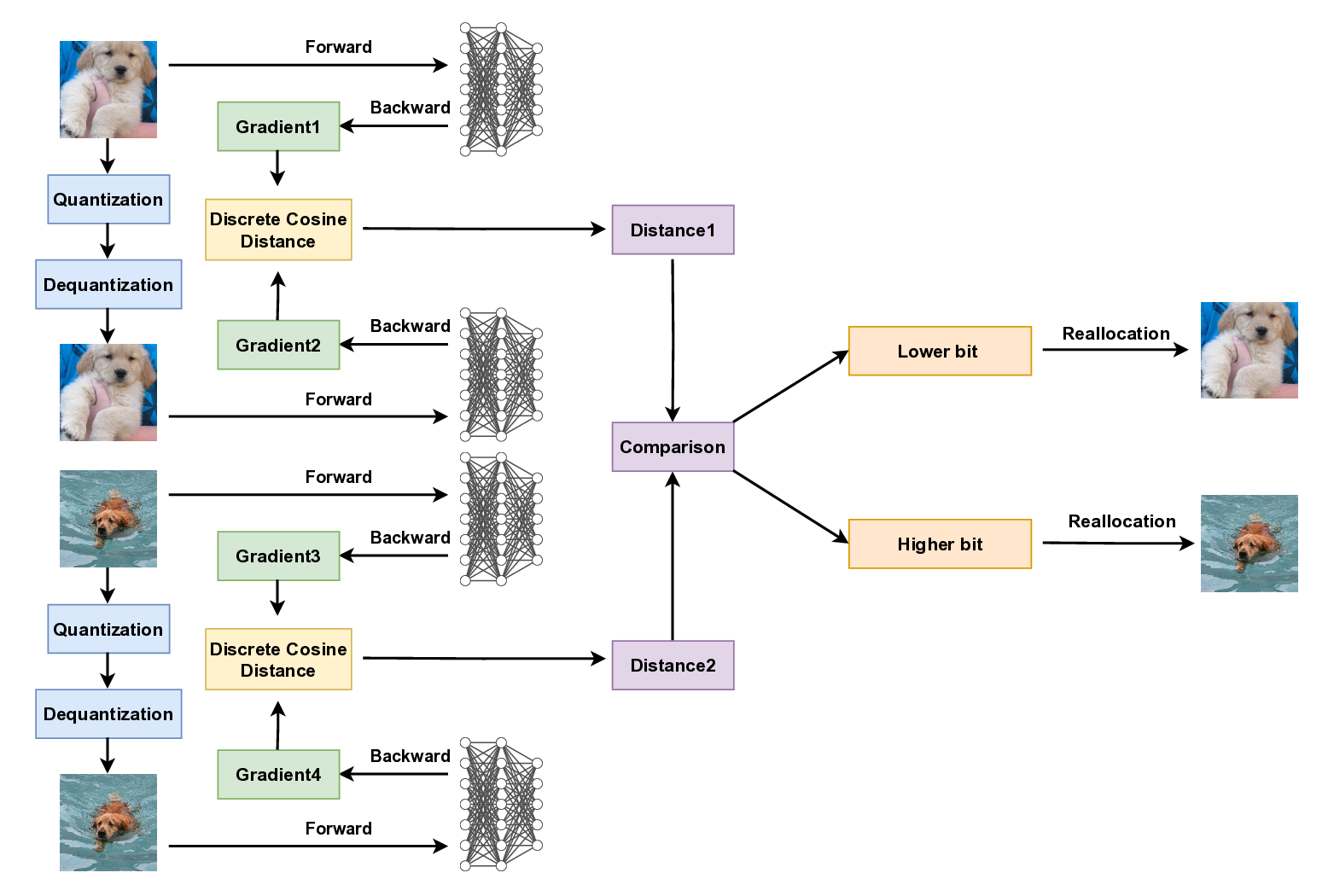
그 다음 도입된 적응형 양자화 할당 알고리즘은 전체 데이터셋에 대해 고정된 총 압축 비율(예: 8배, 16배)을 유지하면서, 각 샘플에 할당되는 비트 수를 동적으로 조정한다. 구체적으로, 이미지의 복잡도·시각적 정보량·학습 기여도 등을 정량화한 메트릭을 기반으로 “정밀도 요구도”를 평가하고, 높은 요구도를 가진 샘플에 더 많은 비트를, 낮은 요구도를 가진 샘플에 적은 비트를 배정한다. 이는 전통적인 균일 양자화가 모든 샘플에 동일한 비트 수를 적용해 정보 손실을 균등하게 만들던 것과는 달리, 손실을 “정보가 중요한 부분”에 집중시켜 전체 학습 성능 저하를 최소화한다는 장점을 가진다.
실험 부분에서는 CIFAR‑10/100, ImageNet‑1K라는 서로 다른 규모와 복잡성을 가진 데이터셋에 대해 다양한 압축 비율(2×64×)을 적용하고, 동일한 비율을 가진 기존 양자화·프루닝 베이스라인과 비교하였다. 결과는 압축 비율이 16× 이상일 때도, 제안 방법이 Top‑1 정확도에서 평균 12%p(percentage point) 정도 우수함을 보여준다. 특히, 이미지넷 수준에서 32× 압축에도 불구하고 원본 데이터셋 대비 0.5%p 이하의 정확도 손실만을 기록한 점은 실용적인 엣지 학습 시나리오에 큰 의미를 가진다. 또한, 메모리 사용량과 전송량이 크게 감소함에도 불구하고, 학습 속도 자체는 크게 변하지 않아, 양자화·프루닝이 동시에 이루어지는 기존 파이프라인보다 효율적이다.
하지만 몇 가지 한계도 존재한다. 첫째, 적응형 비트 할당을 위한 “정밀도 요구도” 메트릭이 논문에서는 비교적 단순히 이미지의 통계적 특성(분산·엔트로피)으로 정의돼 있어, 실제 downstream task(예: 객체 검출, 세그멘테이션)와의 연관성을 충분히 반영하지 못할 가능성이 있다. 둘째, 양자화 스케일을 샘플 별로 독립적으로 저장해야 하는데, 이는 메타데이터 오버헤드가 전체 압축률에 미치는 영향을 정량적으로 분석하지 않아, 극단적인 고압축 상황에서 오히려 효율이 떨어질 위험이 있다. 셋째, 현재 실험은 주로 이미지 분류에 국한돼 있어, 비전 외의 도메인(예: 음성, 시계열)에서의 일반화 가능성은 아직 검증되지 않았다.
향후 연구 방향으로는 (1) task‑aware 정밀도 요구도 추정 방법을 도입해, 특정 응용에 최적화된 비트 할당 전략을 개발하고, (2) 메타데이터 압축 기법(예: 클러스터링 기반 스케일 공유)과 결합해 전체 압축 효율을 더욱 끌어올리는 방안, (3) 비전 외 분야와 멀티모달 데이터셋에 대한 적용 가능성을 탐색하는 것이 제시된다. 전반적으로, 이 논문은 데이터셋 자체를 “양자화 가능한 객체”로 재정의함으로써, 저장·전송 비용이 제한된 환경에서 대규모 학습을 가능하게 하는 중요한 전환점을 제공한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리




