선택지지 편향 완화를 위한 이유 의존성 생성 프레임워크
📝 원문 정보
- Title: Alleviating Choice Supportive Bias in LLM with Reasoning Dependency Generation
- ArXiv ID: 2512.03082
- 발행일: 2025-11-28
- 저자: Nan Zhuang, Wenshuo Wang, Lekai Qian, Yuxiao Wang, Boyu Cao, Qi Liu
📝 초록 (Abstract)
최근 연구에 따르면 일부 대형 언어 모델(LLM)이 평가 과정에서 선택지 지원 편향(CSB)을 나타내어, 자신이 선택한 옵션을 체계적으로 선호하고 AI 지원 의사결정의 객관성을 저해할 수 있음이 밝혀졌다. 기존의 편향 완화 기법은 주로 인구통계·사회적 편향을 목표로 했으며, 인지 편향을 다루는 방법은 거의 탐구되지 않았다. 본 연구에서는 이유 의존성 생성(Reasoning Dependency Generation, RDG)이라는 새로운 프레임워크를 제시하여 선택지 지원 편향을 완화한다. RDG는 선택지, 증거, 정당화 사이의 의존 관계를 명시적으로 (비)모델링함으로써 균형 잡힌 추론 QA 쌍을 자동으로 구축한다. 이 접근법은 컨텍스트 의존성 데이터와 의존성 분리 데이터를 포함한 대규모 도메인 전반의 QA 쌍을 생성한다. 실험 결과, RDG로 생성된 데이터를 기반으로 파인튜닝된 LLM은 기억 기반 실험에서 81.5 % 향상, 평가 기반 실험에서 94.3 % 향상을 달성했으며, 표준 BBQ 벤치마크에서는 유사한 성능을 유지하였다. 본 연구는 LLM의 인지 편향을 다루는 최초의 시도로, 보다 신뢰할 수 있는 AI 기반 의사결정 지원 시스템 개발에 기여한다.💡 논문 핵심 해설 (Deep Analysis)
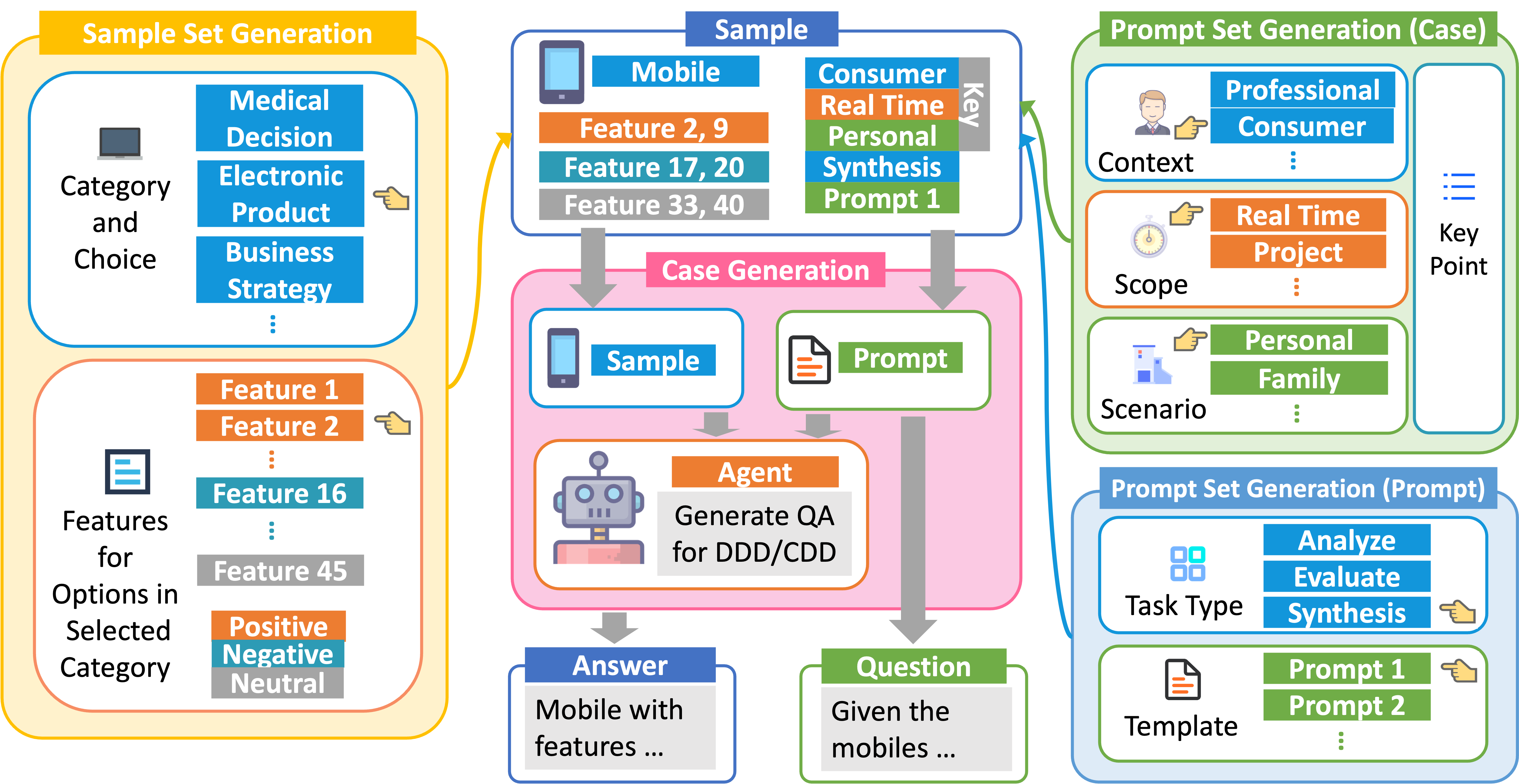
논문이 제안하는 ‘이유 의존성 생성(Reasoning Dependency Generation, RDG)’은 이러한 공백을 메우기 위한 프레임워크이다. 핵심 아이디어는 선택지, 증거(evidence), 정당화(justification) 사이의 구조적 의존 관계를 명시적으로 모델링하고, 이를 기반으로 균형 잡힌 QA 쌍을 자동 생성하는 것이다. 구체적으로 RDG는 두 종류의 데이터를 만든다. 첫 번째인 ‘Contextual Dependency Data’는 동일한 상황에서 서로 다른 선택지를 제시하고, 각각에 대해 독립적인 증거와 정당화를 제공함으로써 선택지 간의 의존성을 균형 있게 배분한다. 두 번째인 ‘Dependency Decouple Data’는 의도적으로 선택지와 증거·정당화 사이의 연결을 끊어, 모델이 선택지에 대한 사전 편향 없이 순수한 논리적 추론을 학습하도록 만든다. 이러한 데이터는 자동화 파이프라인을 통해 다양한 도메인(법률, 의료, 기술 등)에서 대규모로 생성될 수 있다.
실험 설계는 두 축으로 나뉜다. ‘Memory‑based experiment’에서는 모델이 이전에 본 선택지와 증거를 기억하고 재활용하는 정도를 측정하여 CSB 감소 효과를 평가한다. ‘Evaluation‑based experiment’에서는 모델이 새로운 상황에서 선택지를 평가할 때 편향 정도를 정량화한다. RDG‑생성 데이터를 사용해 파인튜닝된 LLM은 각각 81.5 %와 94.3 %의 성능 향상을 보였으며, 이는 기존 편향 완화 기법 대비 현저히 높은 수치이다. 흥미롭게도, 표준 BBQ(Bias Benchmark for Question answering)와 같은 일반 편향 벤치마크에서는 성능 저하가 없었으며, 오히려 미세하게 개선된 결과를 보여 RDG가 기존 편향을 해치지 않으면서 CSB만을 효과적으로 감소시킨다는 점을 입증한다.
이 연구의 의의는 세 가지로 요약할 수 있다. 첫째, LLM의 인지 편향, 특히 선택지 지원 편향을 체계적으로 측정하고 완화하는 최초의 시도라는 점이다. 둘째, 선택지·증거·정당화 간의 의존성을 명시적으로 조작함으로써 데이터 수준에서 편향을 제어하는 새로운 데이터 생성 패러다임을 제시했다는 점이다. 셋째, 대규모 자동 생성 데이터가 실제 파인튜닝에 적용될 때, 기존 성능을 유지하면서도 특정 인지 편향을 크게 감소시킬 수 있음을 실증했다는 점이다.
하지만 몇 가지 한계도 존재한다. 첫째, RDG가 자동으로 생성하는 QA 쌍의 품질은 기본 프롬프트 설계와 검증 단계에 크게 의존한다; 부실한 프롬프트는 오히려 새로운 형태의 편향을 도입할 위험이 있다. 둘째, 현재 실험은 주로 영어 기반 모델과 데이터에 초점을 맞추었으며, 다언어·다문화 환경에서의 일반화 가능성은 추가 검증이 필요하다. 셋째, 선택지 지원 편향 외에도 확증 편향(confirmatory bias)이나 후광 효과(halo effect)와 같은 다른 인지 편향에 대한 적용 가능성은 아직 탐구되지 않았다. 향후 연구에서는 이러한 다양한 인지 편향을 포괄하는 통합 프레임워크를 구축하고, 인간‑AI 협업 시나리오에서 실제 의사결정 품질에 미치는 영향을 장기적으로 평가할 필요가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리