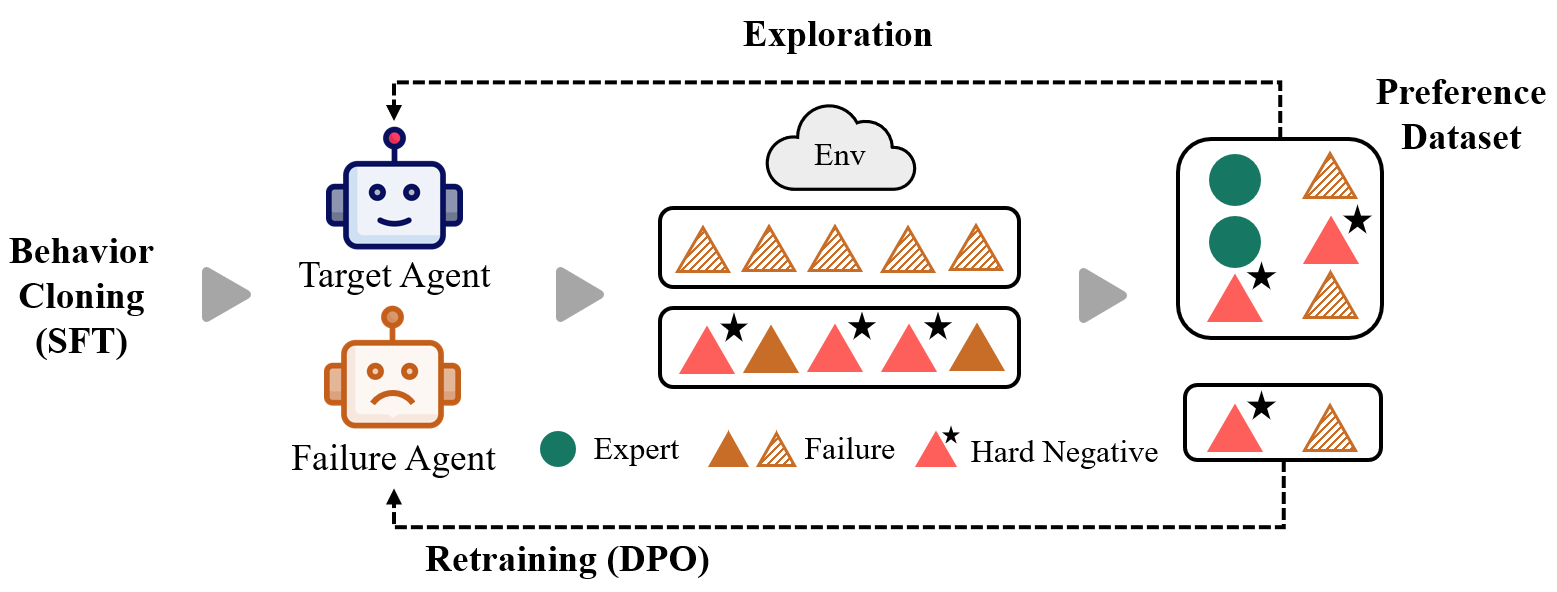
자기 개선 에이전트를 위한 실패 기반 하드 네거티브 공동 진화 프레임워크
📝 원문 정보
- Title: Co-Evolving Agents: Learning from Failures as Hard Negatives
- ArXiv ID: 2511.22254
- 발행일: 2025-11-27
- 저자: Yeonsung Jung, Trilok Padhi, Sina Shaham, Dipika Khullar, Joonhyun Jeong, Ninareh Mehrabi, Eunho Yang
📝 초록 (Abstract)
최근 대형 기반 모델의 발전으로 작업 특화 에이전트가 가능해졌지만, 고품질 학습 데이터의 부족과 비용 때문에 성능이 제한되고 있다. 자기 개선 에이전트는 자체 생성 궤적을 선호 최적화에 활용하고 제한된 실제 감독과 결합함으로써 이 문제를 완화한다. 그러나 자체 예측 궤적에 과도하게 의존하면 일관된 선호 지형을 학습하지 못해 희소한 감독에 과적합하고 개선 폭이 제한된다. 이를 해결하기 위해 보조 실패 에이전트를 도입해 정보성 하드 네거티브를 생성하고, 목표 에이전트와 서로의 실패 궤적을 학습하며 공동 진화하도록 하는 프레임워크를 제안한다. 실패 에이전트는 양쪽 에이전트의 실패 궤적만을 사용해 선호 최적화를 수행해 성공에 가깝지만 여전히 실패인 하드 네거티브를 만든다. 이러한 하드 네거티브를 목표 에이전트의 선호 최적화에 포함하면 선호 지형이 정교해지고 일반화가 향상된다. 웹 쇼핑, 과학적 추론, SQL 과제 등 복잡한 다중 턴 벤치마크에서 수행한 포괄적인 실험 결과, 제안 프레임워크가 더 높은 품질의 하드 네거티브를 생성해 기존 방법 대비 일관된 성능 향상을 보였다. 이는 실패를 그대로 사용하기보다 체계적으로 구조화된 학습 신호로 전환함으로써 자기 개선 에이전트의 학습 효율을 크게 높일 수 있음을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
논문이 제안한 공동 진화(co‑evolution) 메커니즘은 두 에이전트가 서로의 실패를 교환하고, 각각은 상대방의 실패를 학습 데이터로 삼아 자신의 정책을 개선한다는 점에서 혁신적이다. 특히 실패 에이전트가 오직 실패 궤적만을 사용해 선호 최적화를 수행한다는 설계는, 성공 궤적에 대한 과도한 편향을 방지하고, 실패 샘플이 성공에 가까울수록 하드 네거티브의 효용이 극대화된다는 가정을 실증적으로 검증한다.
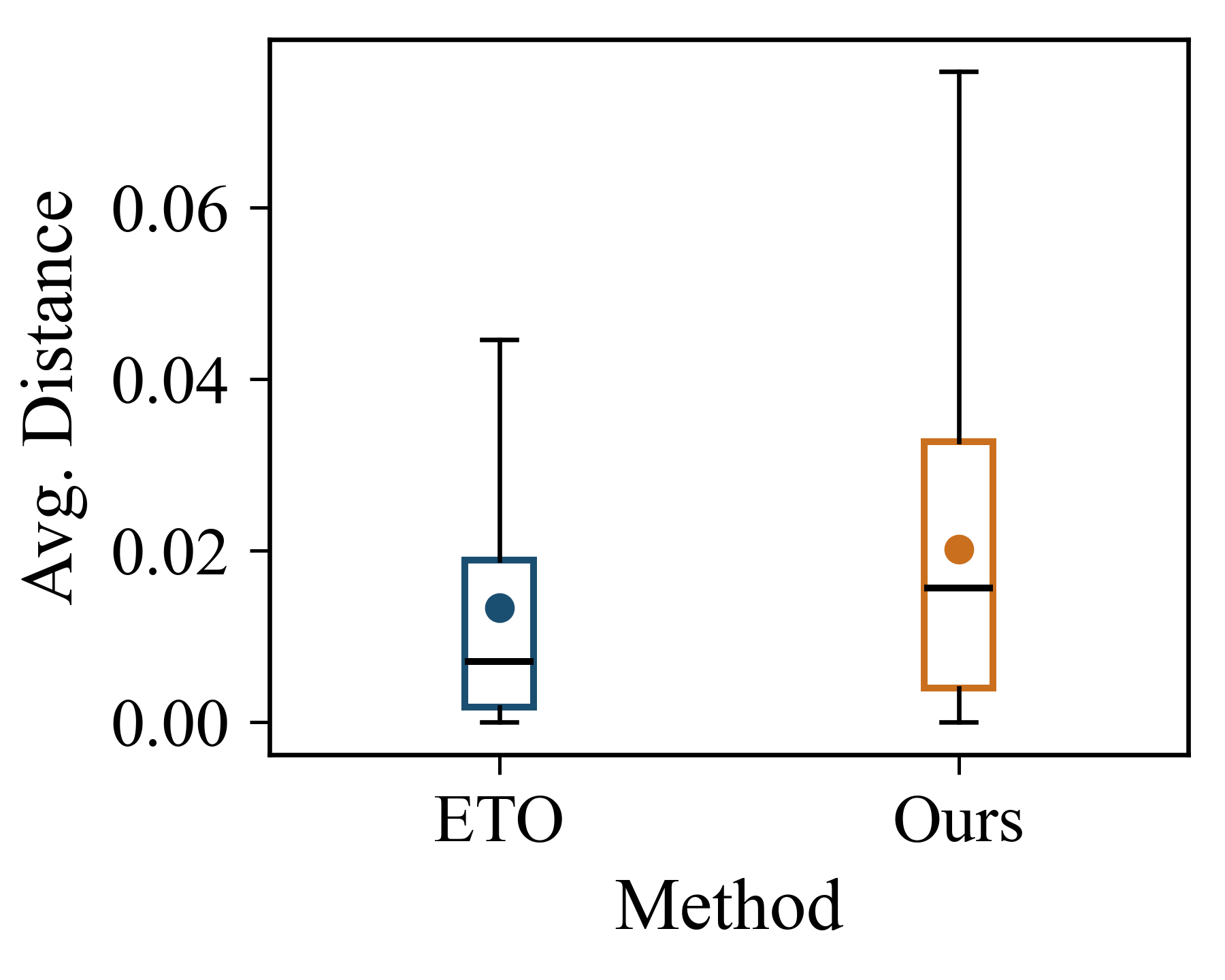
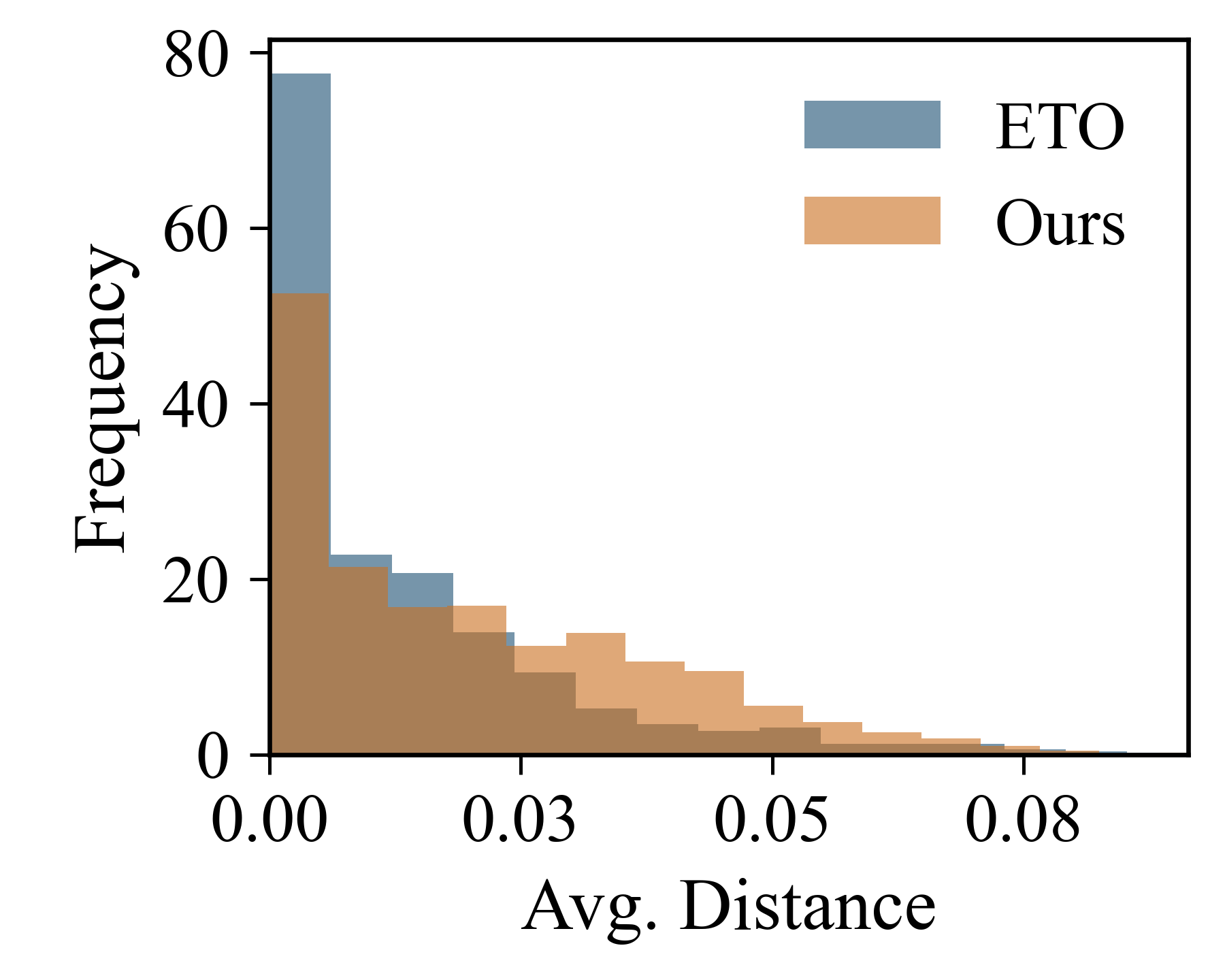
실험 설계 역시 설득력 있다. 웹 쇼핑, 과학적 추론, SQL 질의와 같이 다양한 도메인과 다중 턴 상호작용을 요구하는 벤치마크에 적용함으로써 제안 방법의 범용성을 입증하였다. 특히 하드 네거티브의 품질을 정량화하기 위해 성공률 대비 실패 거리, 모델의 불확실성 감소 등 여러 메트릭을 도입한 점은 결과 해석에 신뢰성을 부여한다.
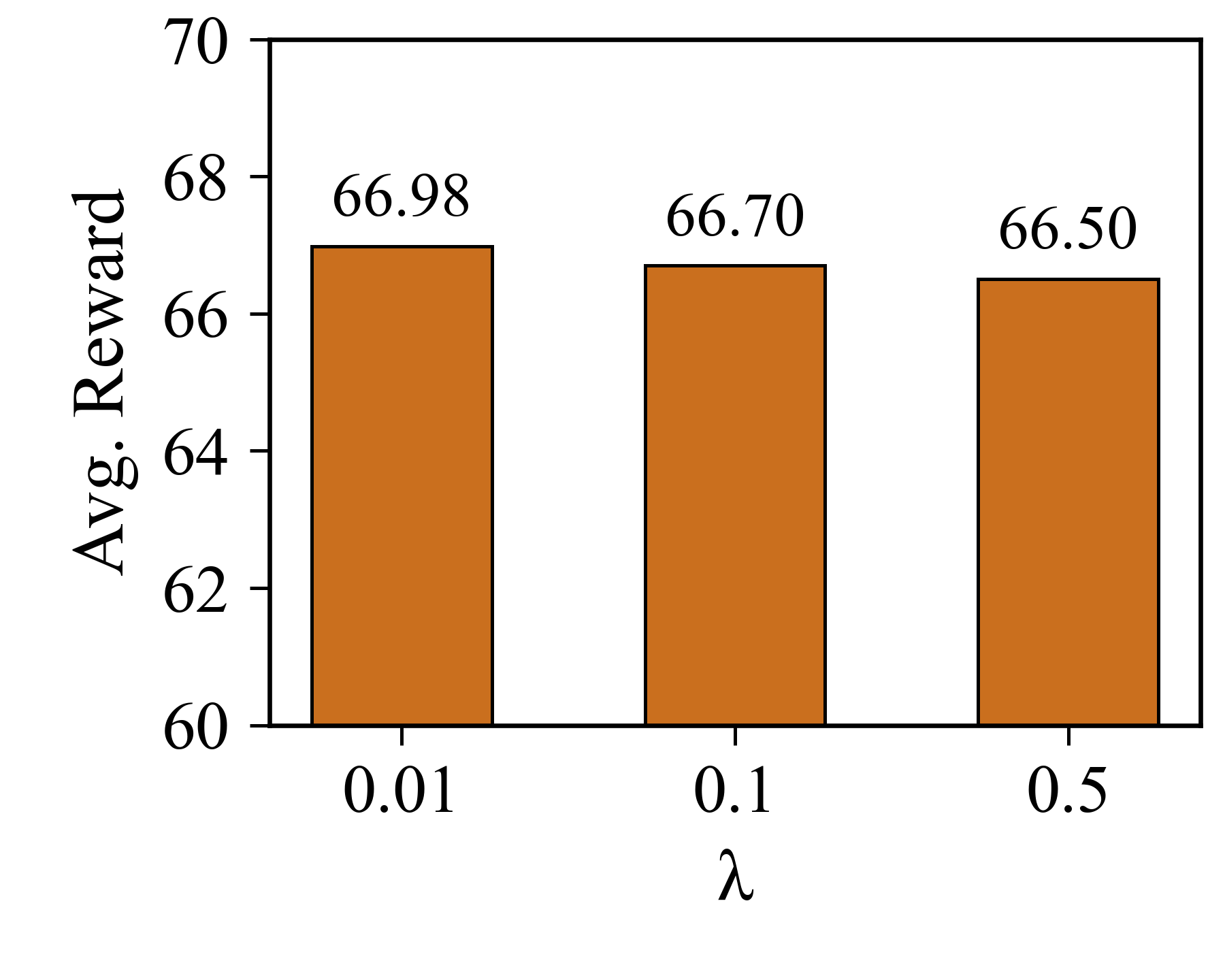
하지만 몇 가지 한계도 존재한다. 첫째, 실패 에이전트가 생성하는 하드 네거티브가 지나치게 어려워지면 목표 에이전트가 학습에 실패할 위험이 있다. 논문에서는 이를 완화하기 위해 일정 비율로 기존 성공 샘플을 혼합했지만, 최적 비율을 자동으로 조정하는 메커니즘이 부족하다. 둘째, 공동 진화 과정에서 두 에이전트가 서로를 과도하게 모방하게 되면 다양성이 감소하고, 결국 탐색 공간이 제한될 수 있다. 이를 방지하기 위한 다양성 유지 전략(예: 엔트로피 정규화) 도입이 필요하다. 셋째, 현재 실험은 제한된 규모의 모델에 국한되었으며, 초대형 언어 모델에 적용했을 때의 계산 비용과 스케일링 효과는 추가 연구가 요구된다.
향후 연구 방향으로는 (1) 하드 네거티브의 난이도를 동적으로 평가·조절하는 적응형 스케줄러, (2) 다중 에이전트 간 협업을 확장해 다양한 역할(예: 탐색자, 검증자)으로 분화시키는 멀티‑에이전트 프레임워크, (3) 인간 피드백과 결합해 실패 샘플의 의미를 정성적으로 보강하는 하이브리드 학습 방식 등을 제안한다. 이러한 확장은 현재 제안된 공동 진화 메커니즘을 더욱 견고하고 실용적으로 만들 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리