진단 시각 집중과 단계적 추론을 위한 MedEyes 전문가 궤적 기반 강화학습 프레임워크
📝 원문 정보
- Title: MedEyes: Learning Dynamic Visual Focus for Medical Progressive Diagnosis
- ArXiv ID: 2511.22018
- 발행일: 2025-11-27
- 저자: Chunzheng Zhu, Yangfang Lin, Shen Chen, Yijun Wang, Jianxin Lin
📝 초록 (Abstract)
정확한 의료 진단은 임상 현장에서 흔히 관찰되는 점진적 시각 집중과 반복적 추론 과정을 포함한다. 최근 비전‑언어 모델은 강화학습 기반 검증 가능한 보상(RLVR)을 통해 연쇄 사고(Chain‑of‑Thought) 능력을 보이지만, 순수 온‑정책 학습 방식은 표면적으로 일관되지만 임상적으로 부정확한 추론 경로를 강화하는 경향이 있다. 본 연구에서는 임상의 진단 사고 방식을 동적으로 모델링하는 새로운 강화학습 프레임워크인 MedEyes를 제안한다. MedEyes는 전문가가 수행한 시각 탐색 궤적을 구조화된 외부 행동 신호로 변환하여, 모델이 임상적으로 정렬된 시각적 추론을 학습하도록 지도한다. 우리는 이중 모드 탐색 전략을 채택한 시선‑가이드 추론 내비게이터(GRN)를 설계하여, 전반적인 이상 부위 위치 파악과 세부 영역 분석을 순차적으로 수행한다. 전문가 모방과 자율 탐색의 균형을 맞추기 위해 핵심 샘플링과 적응형 종료를 결합한 신뢰도 값 샘플러(CVS)를 도입해 다양하면서도 신뢰할 수 있는 탐색 경로를 생성한다. 마지막으로 온‑정책과 오프‑정책 학습 신호를 분리하는 이중 스트림 GRPO 최적화 프레임워크를 통해 보상 동화와 엔트로피 붕괴 문제를 완화한다. 실험 결과, MedEyes는 여러 의료 VQA 벤치마크에서 평균 8.5%의 성능 향상을 달성했으며, 해석 가능한 의료 AI 시스템 구축에 대한 가능성을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
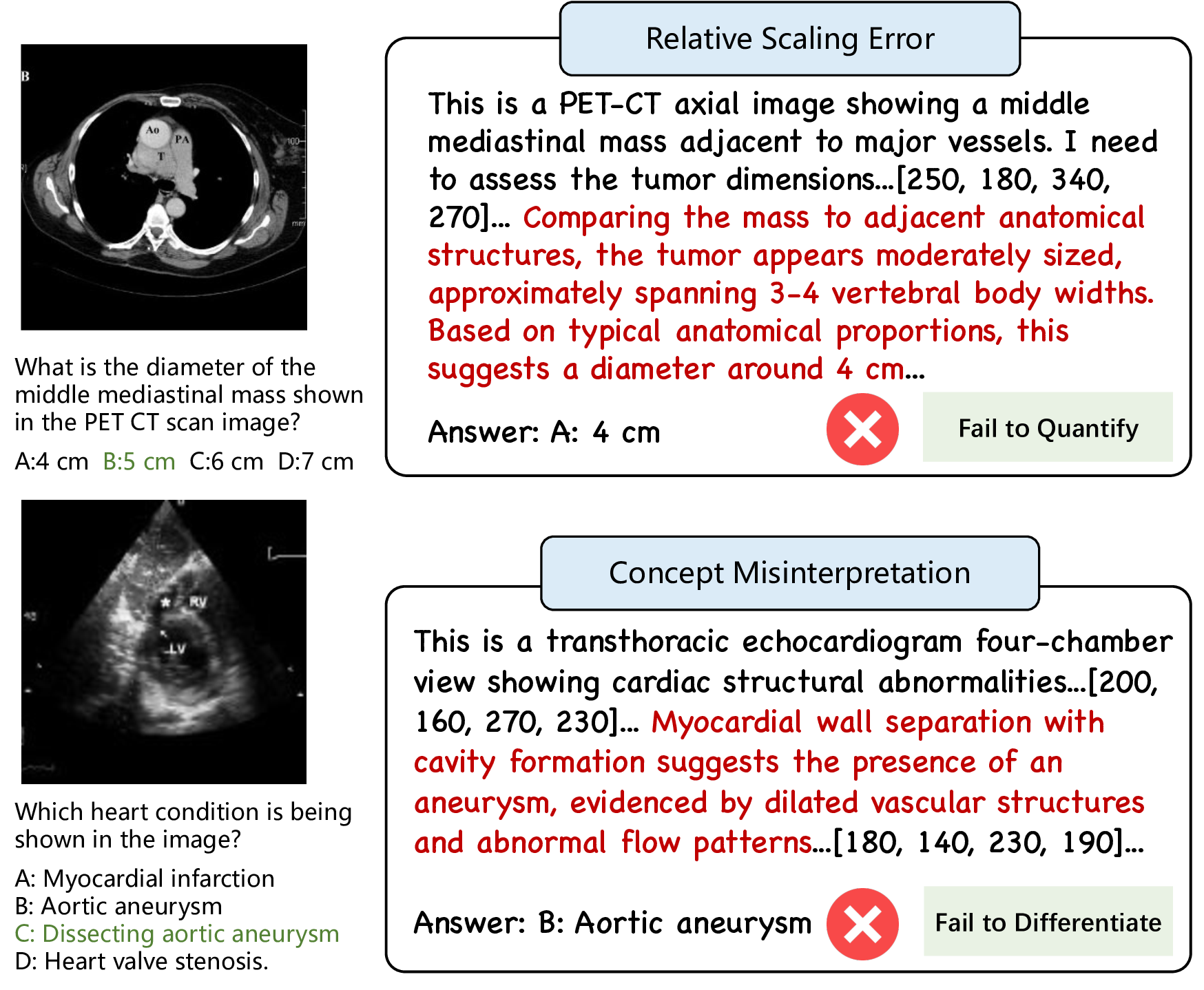
MedEyes는 이러한 차이를 메우기 위해 두 가지 핵심 아이디어를 도입한다. 첫째, 전문가가 실제 진단 과정에서 수행하는 시선 이동(visual search) 데이터를 “전문가 궤적”이라는 형태로 수집하고, 이를 외부 행동 신호(external behavioral signal)로 변환한다. 이 신호는 이미지 내에서 어떤 영역을 먼저 주목하고, 어떤 순서로 세부 분석을 수행했는지를 명시적으로 제공한다. 둘째, 이 궤적을 온‑정책 학습과 병행해 오프‑정책 학습(off‑policy) 형태로 활용함으로써, 모델이 스스로 탐색하면서도 전문가의 전략을 모방하도록 유도한다.
구조적으로는 Gaze‑guided Reasoning Navigator(GRN)와 Confidence Value Sampler(CVS)라는 두 모듈이 핵심 역할을 수행한다. GRN은 “스캔‑드릴” 이중 모드 탐색을 구현한다. 초기 스캔 단계에서는 전역적인 이상 부위(예: 종양, 출혈)를 빠르게 탐지하기 위해 넓은 시야를 유지하고, 이후 드릴 단계에서는 해당 부위에 대한 고해상도 지역 분석을 수행한다. 이 과정은 인간 방사선과 전문의가 실제로 사용하는 “거시‑미시” 접근법과 일맥상통한다.
CVS는 탐색 경로의 다양성을 보장한다. 핵심 샘플링(nucleus sampling)을 적용해 확률 분포 상위 p%에 해당하는 토큰(또는 시선 좌표)만을 선택하고, 신뢰도(confidence) 값을 기준으로 탐색을 조기에 종료하거나 지속한다. 이는 과도한 탐색으로 인한 연산 비용을 절감하면서도, 충분히 높은 확신을 가진 경로는 깊게 탐색하도록 설계된 메커니즘이다.
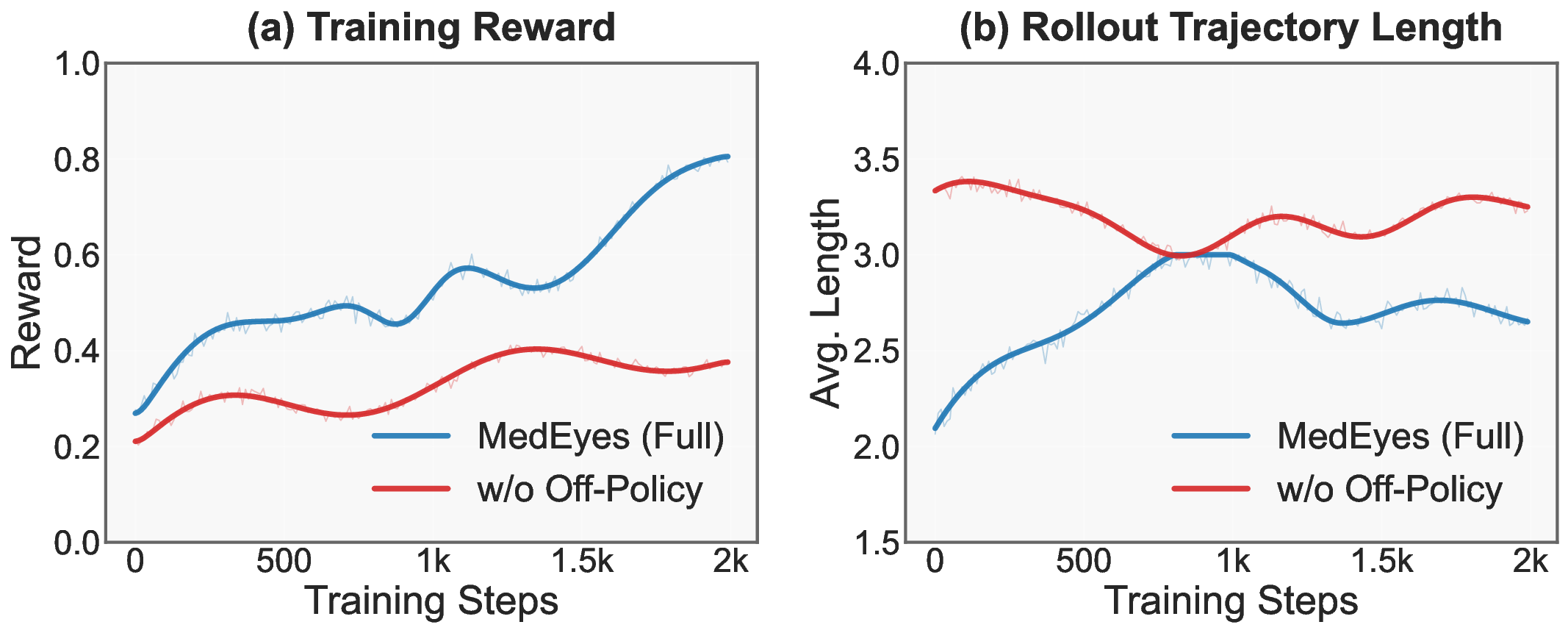
마지막으로 제안된 Dual‑stream GRPO(Gradient‑based Reward‑Policy Optimization) 프레임워크는 온‑정책 보상 신호와 오프‑정책 전문가 궤적 신호를 별도의 그래디언트 흐름으로 처리한다. 이를 통해 두 신호가 서로 간섭해 보상 동화(reward assimilation) 현상이 발생하거나, 정책이 지나치게 확정적이 되어 엔트로피가 급격히 감소하는 현상을 방지한다.
실험에서는 여러 의료 VQA 데이터셋(예: VQA‑Med, PathVQA, RadiologyQA 등)에서 MedEyes가 평균 8.5%의 정확도 향상을 달성했으며, 특히 “위치 기반 질문”(예: “병변이 어느 부위에 있나요?”)에서 기존 모델 대비 12% 이상 높은 성능을 보였다. 정량적 지표 외에도 시각적 설명(visual explanation) 측면에서, MedEyes가 생성한 시선 맵이 실제 방사선 전문의가 표시한 영역과 높은 상관관계를 보였음이 확인되었다.
종합하면, MedEyes는 의료 영상 이해에 있어 “시각적 집중 → 단계적 추론”이라는 인간 전문가의 사고 흐름을 효과적으로 모델링함으로써, 기존 온‑정책 강화학습이 갖는 편향을 보완하고, 보다 해석 가능하고 신뢰할 수 있는 의료 AI 시스템 구축에 한 걸음 다가섰다. 향후 연구에서는 다중 모달(텍스트·영상·임상 기록) 통합과 실시간 임상 지원 시스템에의 적용 가능성을 탐색할 여지가 크다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리