망막 질환 분류를 위한 소형 비전 모델의 효율성 검증
📝 원문 정보
- Title: When Do Domain-Specific Foundation Models Justify Their Cost? A Systematic Evaluation Across Retinal Imaging Tasks
- ArXiv ID: 2511.22001
- 발행일: 2025-11-27
- 저자: David Isztl, Tahm Spitznagel, Gabor Mark Somfai, Rui Santos
📝 초록 (Abstract)
대규모 비전 기반 파운데이션 모델이 망막 질환 분류에 널리 사용되고 있으나, 파라미터 규모에 대한 체계적 근거는 부족하다. 본 연구는 두 가지 핵심 질문에 답한다. 첫째, 대규모 도메인‑특화 파운데이션 모델이 반드시 필요한가, 아니면 소형 범용 아키텍처만으로 충분한가? 둘째, 망막 전용 사전학습이 그 계산 비용을 정당화하는가? 이를 위해 OCT와 색채 안저 사진(CFP) 두 모달리티에 걸친 네 가지 분류 과제(8‑클래스 OCT, 3‑클래스 당뇨망막부종, 5‑클래스 당뇨망막증, 3‑클래스 녹내장)를 대상으로 12‑13개의 모델 구성을 동일 학습 조건에서 벤치마크했다. 평가 대상은 Vision Transformer(22.8M‑86.6M), Swin Transformer(27.6M‑28.3M), ConvNeXt(28.6M), 그리고 도메인‑특화 RETFound(303M)이다. 결과는 기존 가정을 뒤흔든다. 첫째, 사전학습은 모든 과제에서 5.18‑18.41%의 정확도 향상을 제공하며 과제 난이도가 높을수록 효과가 커진다. 둘째, 27‑29M 규모의 소형 모델이 파레토 최적선에 위치하며, SwinV2‑tiny가 세 데이터셋에서 최고 성능을 기록한다. 셋째, RETFound는 DR 등급 구분(정확도 71.15%)과 같이 매우 미세한 구분이 요구되는 경우에만 그 비용을 정당화하고, 나머지 과제에서는 ImageNet 사전학습만으로도 충분히 높은 정확도(DME 99.24%, OCT 97.96%)를 달성한다. CFP 과제는 OCT에 비해 사전학습 효과가 더 크게 나타났다(9.13‑18.41%). 종합적으로, 대부분의 망막 분류 과제에서는 소형 범용 모델이 최적에 가깝게 성능을 발휘하며, 특수 파운데이션 모델은 극심한 클래스 불균형과 같은 고난이도 상황에서만 필요함을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
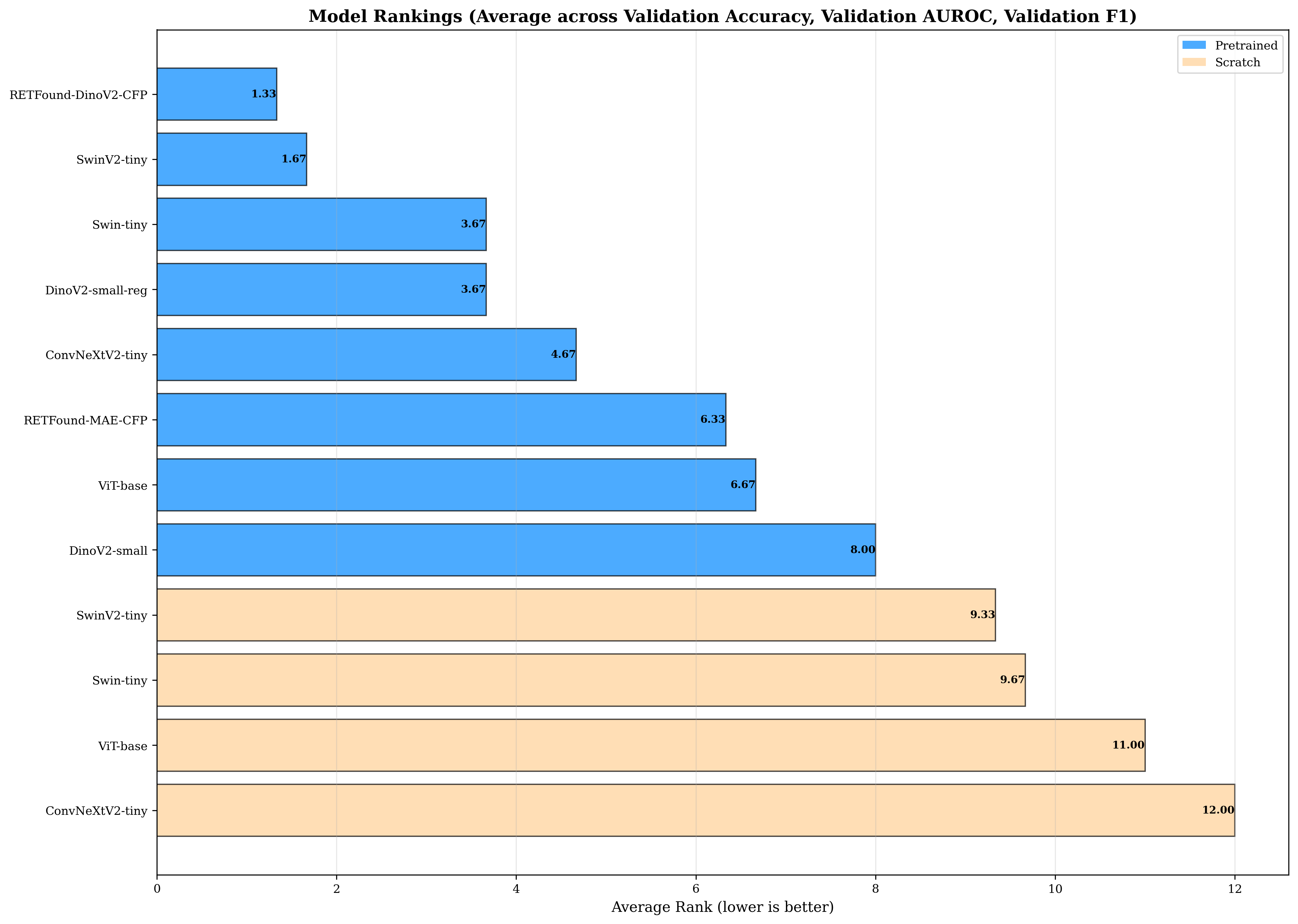
모델 구성은 Vision Transformer(ViT), Swin Transformer, ConvNeXt 등 최신 범용 아키텍처를 22.8M에서 86.6M 파라미터 범위로 다양하게 포함하고, 도메인‑특화 RETFound(303M)라는 초대형 모델까지 포함함으로써 ‘크기‑성능 트레이드오프’를 명확히 드러낸다. 특히, 동일한 학습 프로토콜(데이터 전처리, 학습률 스케줄, 에포크 수 등)을 적용해 비교했기 때문에, 파라미터 수 자체가 아닌 아키텍처와 사전학습 전략이 성능에 미치는 영향을 순수하게 평가할 수 있다.
실험 결과는 세 가지 주요 인사이트를 제공한다. 첫째, 사전학습이 전반적으로 5.18%에서 18.41%까지 정확도 향상을 가져오며, 이는 특히 클래스가 많고 구분이 어려운 DR 과제에서 크게 나타난다. 이는 대규모 일반 이미지(ImageNet) 사전학습이 의료 영상에서도 강력한 전이 학습 기반이 될 수 있음을 재확인한다. 둘째, 파라미터가 27‑29M 수준인 SwinV2‑tiny와 ConvNeXt와 같은 소형 모델이 대부분의 과제에서 파레토 최적점을 형성한다는 점은, 실제 임상 현장에서 제한된 연산 자원과 실시간 추론이 요구될 때 큰 의미를 가진다. 특히, SwinV2‑tiny가 세 데이터셋에서 최고 성능을 기록한 것은, 윈도우 기반 자기‑주의 메커니즘이 안과 영상의 국소적 패턴을 효과적으로 포착한다는 점을 시사한다.
셋째, RETFound와 같은 초대형 도메인‑특화 모델은 DR 등급 구분처럼 미세한 차이를 구분해야 하고 클래스 불균형이 심한 경우에만 성능 우위를 보인다. 그러나 그 비용(메모리, 학습 시간, 에너지 소비)은 일반적인 과제에서는 정당화되지 않는다. 이는 연구자와 의료 기관이 모델 선택 시 ‘과제 난이도와 자원 제약’을 명확히 고려해야 함을 강조한다.
또한, CFP 과제에서 사전학습 효과가 OCT보다 크게 나타난 점은, 색채 정보와 전반적인 시야가 풍부한 CFP가 사전학습된 특징 표현과 더 높은 상관관계를 가짐을 의미한다. 이는 향후 색채 기반 안저 사진에 특화된 사전학습 데이터셋 구축의 필요성을 제기한다.
전체적으로, 본 연구는 ‘큰 모델이 무조건 좋다’는 편견을 과학적으로 반박하고, 파라미터 효율성, 사전학습 전략, 과제 특성 간의 복합적인 관계를 정량적으로 제시한다. 이러한 결과는 안과 AI 연구뿐 아니라, 의료 영상 전반에 걸쳐 모델 선택과 자원 배분에 실질적인 가이드라인을 제공한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리




