추천 대화 시스템 이론적 마음 이론 평가 벤치마크 RECTOM
📝 원문 정보
- Title: RecToM: A Benchmark for Evaluating Machine Theory of Mind in LLM-based Conversational Recommender Systems
- ArXiv ID: 2511.22275
- 발행일: 2025-11-27
- 저자: Mengfan Li, Xuanhua Shi, Yang Deng
📝 초록 (Abstract)
대형 언어 모델(LLM)은 명령 이해, 추론, 인간과의 상호작용에서 뛰어난 능력을 보여주며 대화형 추천 시스템(CRS)을 혁신하고 있다. 효과적인 추천 대화의 핵심은 사용자의 욕구·의도·신념 등 정신 상태를 추론하고 이유화하는 능력, 즉 이론적 마음 이론(Theory of Mind, ToM)이다. 최근 LLM의 ToM 평가에 대한 관심이 높아지고 있으나, 기존 벤치마크는 주로 물리적 지각에 초점을 맞춘 Sally‑Anne식 인공 서사에 의존해 현실 대화에서의 복잡한 정신 상태 추론을 충분히 반영하지 못한다. 또한 인간 ToM의 중요한 요소인 행동 예측—추론된 정신 상태를 바탕으로 전략적 의사결정을 내리고 향후 대화 행동을 선택하는 능력—을 간과한다. 인간과 유사한 사회적 추론에 맞춰 LLM 기반 ToM 평가를 정교화하기 위해, 우리는 추천 대화에서 ToM 능력을 평가하는 새로운 벤치마크 RECTOM을 제안한다. RECTOM은 인지 추론(Cognitive Inference)과 행동 예측(Behavioral Prediction)이라는 두 보완적 차원을 중심으로 설계되었다. 전자는 대화에서 전달된 정보를 기반으로 숨겨진 정신 상태를 파악하는 능력을, 후자는 파악된 정신 상태를 활용해 다음에 취해야 할 대화 전략을 예측·선택·평가하는 능력을 평가한다. 이 두 차원을 결합함으로써 CRS에서의 ToM 추론을 포괄적으로 측정할 수 있다. 최신 LLM들을 대상으로 한 광범위한 실험 결과, RECTOM은 모델들에게 상당한 난이도를 제시함을 확인했다. 모델들은 정신 상태를 어느 정도 인식하는 데는 성공하지만, 동적인 추천 대화 흐름 속에서 의도를 지속적으로 추적하고, 추론된 정신 상태와 일치하는 전략적 대화 행동을 일관되게 유지하는 데는 한계를 보였다.💡 논문 핵심 해설 (Deep Analysis)

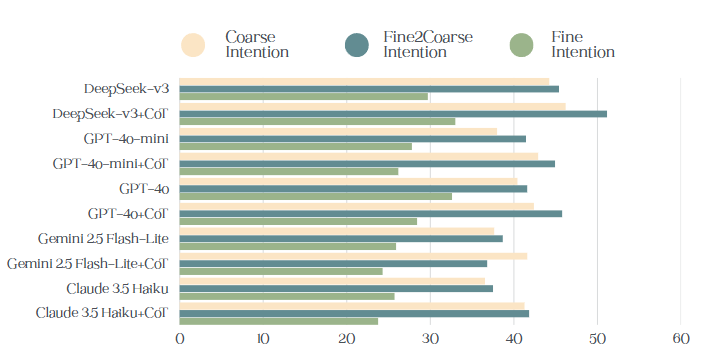
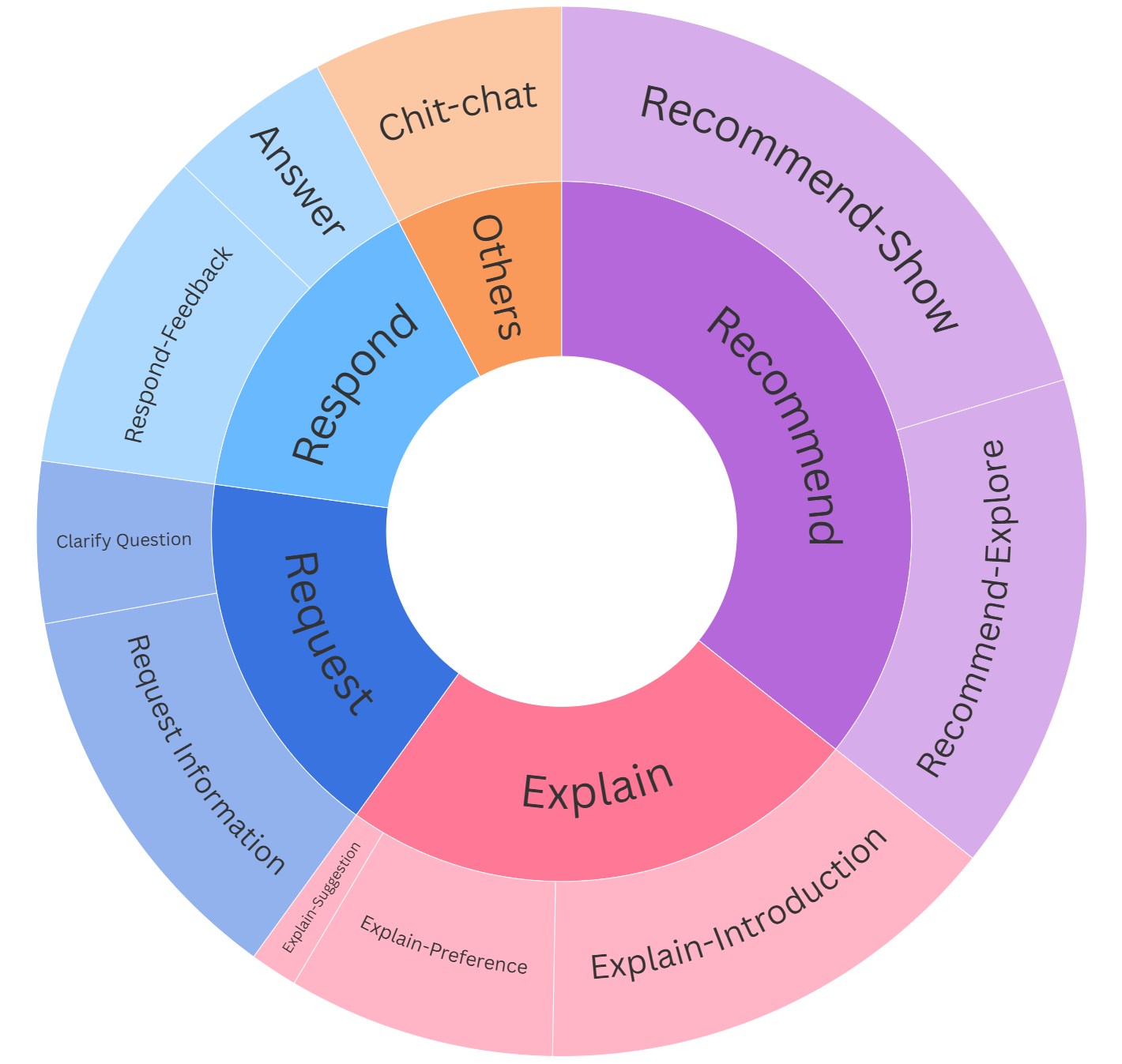
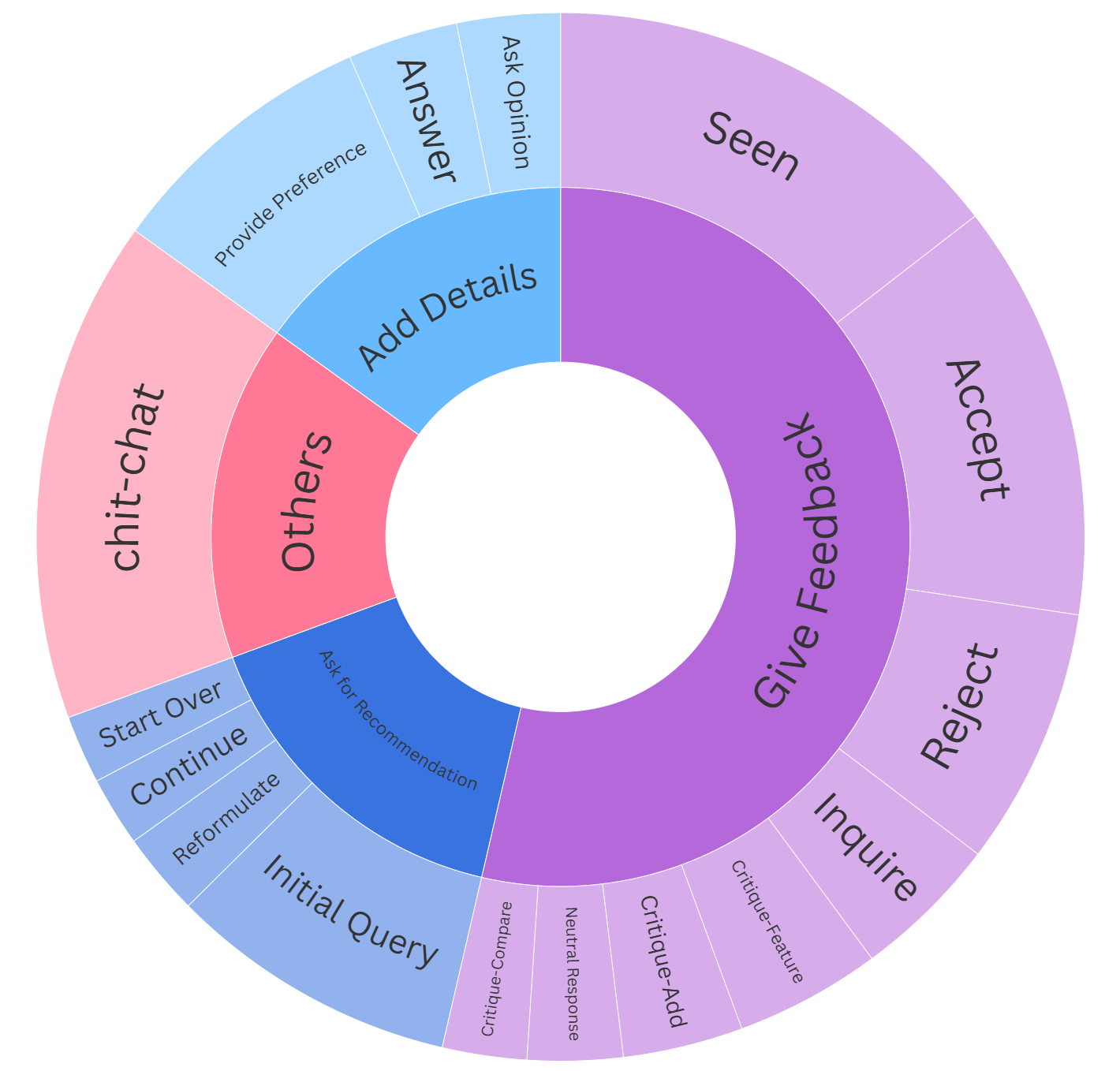
RECTOM 벤치마크는 실제 추천 시나리오를 기반으로 한 다중 턴 대화 데이터를 구축하고, 각 턴마다 (1) 사용자의 숨은 욕구·의도·신념을 라벨링하고, (2) 그 라벨을 토대로 최적의 시스템 응답(예: 아이템 제안, 질문, 확인) 을 선택하도록 요구한다. 평가 지표는 단순 정확도 외에도 ‘전략 일관성(Strategic Consistency)’과 ‘의도 추적 지속성(Intent Tracking Persistence)’을 포함해 모델이 대화 전반에 걸쳐 정신 상태를 어떻게 유지·갱신하는지를 정량화한다.
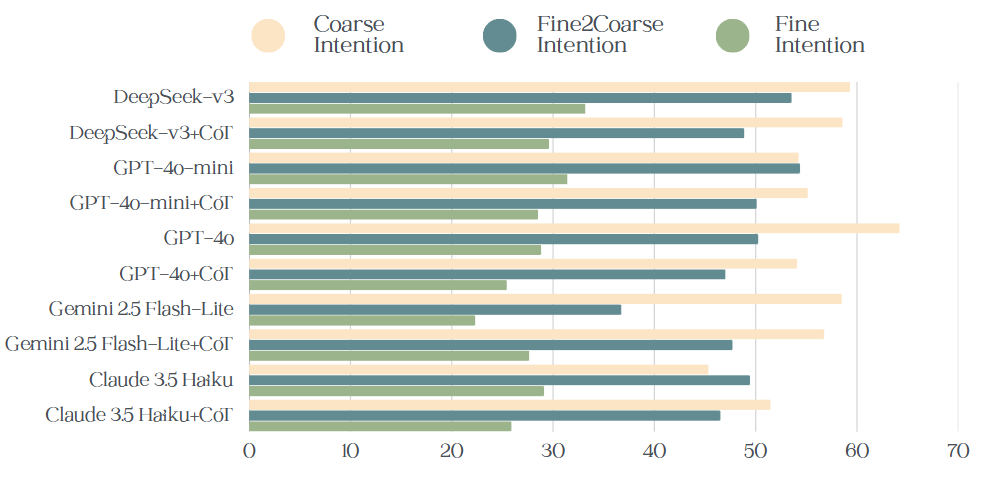
실험에서는 GPT‑4, Claude, LLaMA‑2 등 최신 상용·오픈소스 LLM들을 사전학습된 상태와, ToM‑특화 프롬프트 엔지니어링을 적용한 두 조건에서 테스트했다. 결과는 전반적으로 모델들이 ‘인지 추론’ 단계에서는 70 % 이상 정확도를 보였지만, ‘행동 예측’ 단계에서는 40 % 이하의 성능에 머물렀음을 보여준다. 특히, 사용자의 의도가 대화 중에 변할 때 모델은 이전 의도를 고정된 것으로 오인하거나, 적절한 전환 질문을 놓치는 경향이 있었다. 이는 현재 LLM이 장기적인 대화 메모리와 동적 의도 업데이트 메커니즘이 부족함을 시사한다.
한계점으로는 (1) 데이터 구축 과정에서 인간 라벨러의 주관성이 개입될 수 있다는 점, (2) 현재 평가가 텍스트 기반 응답에 국한돼 실제 멀티모달 추천 상황(이미지·음성)에는 확장되지 않았다는 점을 들 수 있다. 향후 연구는 (가) 라벨링 프로세스에 메타-주석을 도입해 라벨 신뢰도를 높이고, (나) 대화 기억 네트워크와 의도 추적 모듈을 별도 학습시켜 LLM에 통합하는 방안을 모색해야 한다. 또한, RECTOM을 다른 도메인(예: 의료 상담, 교육 튜터링)으로 확장함으로써 ToM 기반 대화 전략이 다양한 분야에 미치는 영향을 검증할 필요가 있다.
요약하면, 본 논문은 ‘정신 상태 추론’과 ‘그에 기반한 행동 선택’이라는 두 축을 통해 LLM의 ToM 능력을 종합적으로 평가하는 최초의 벤치마크를 제시하고, 현존 모델들의 전략적 한계를 실증함으로써 차세대 대화형 추천 시스템 연구에 중요한 방향성을 제공한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리