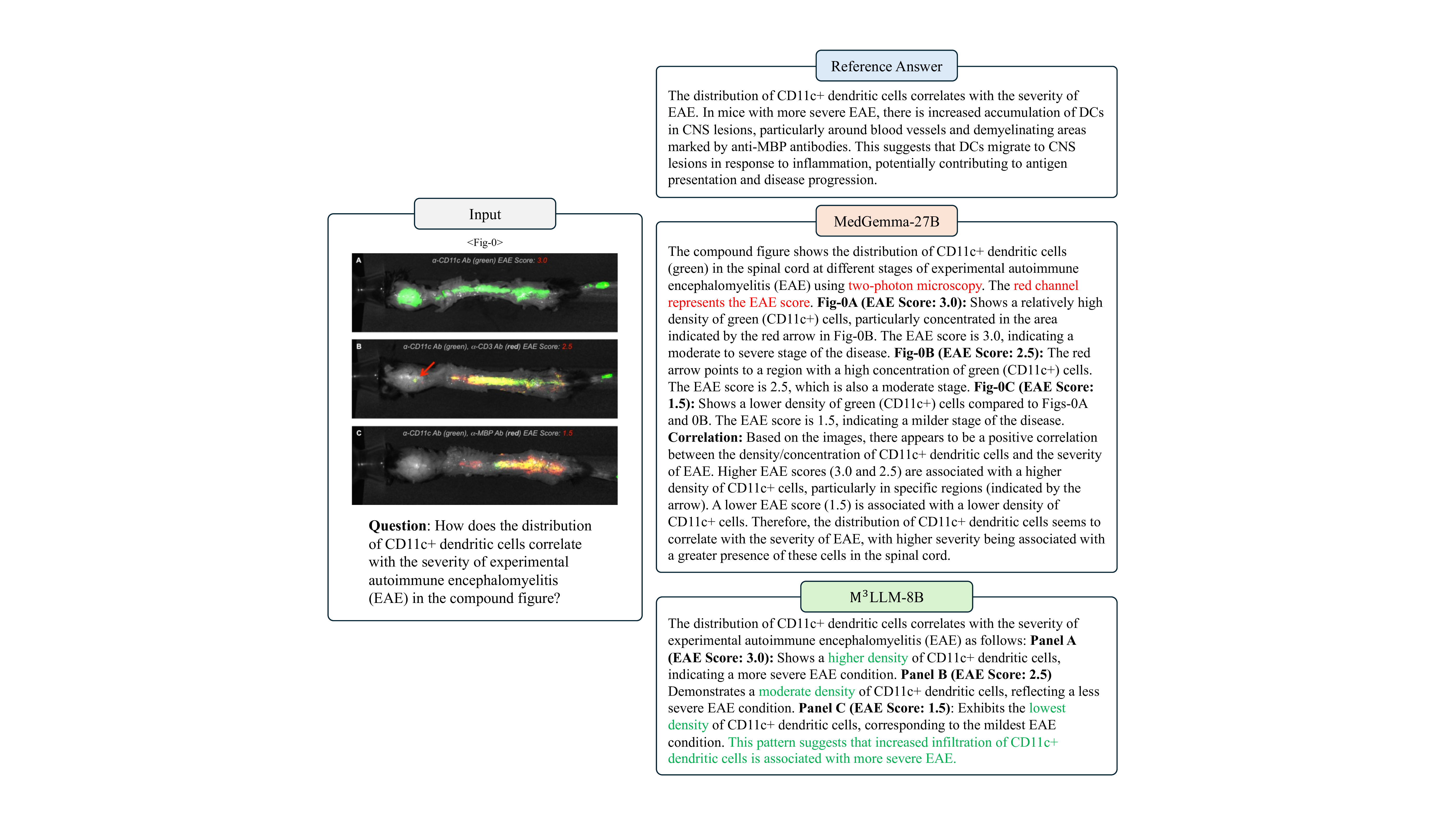
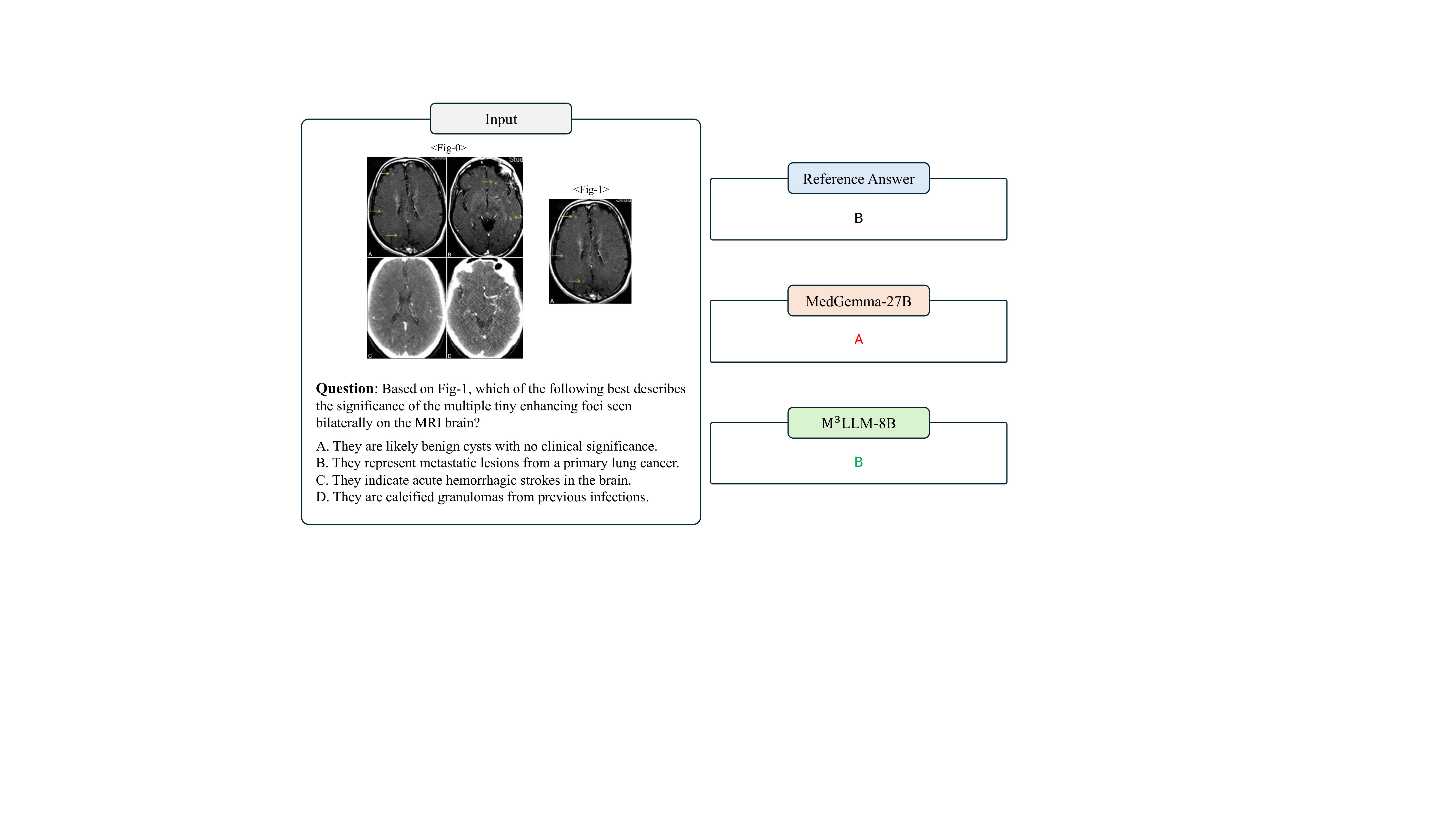
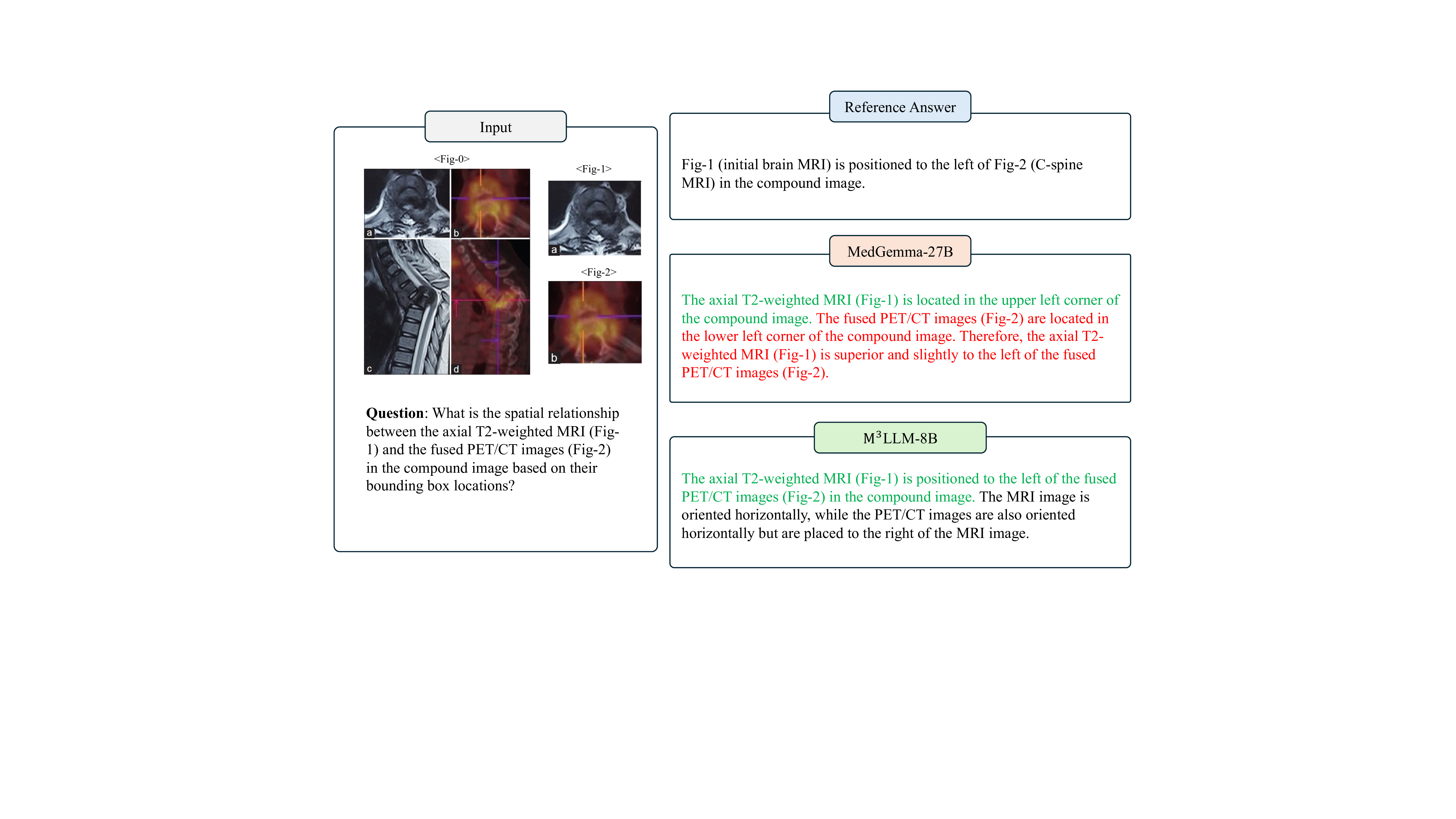
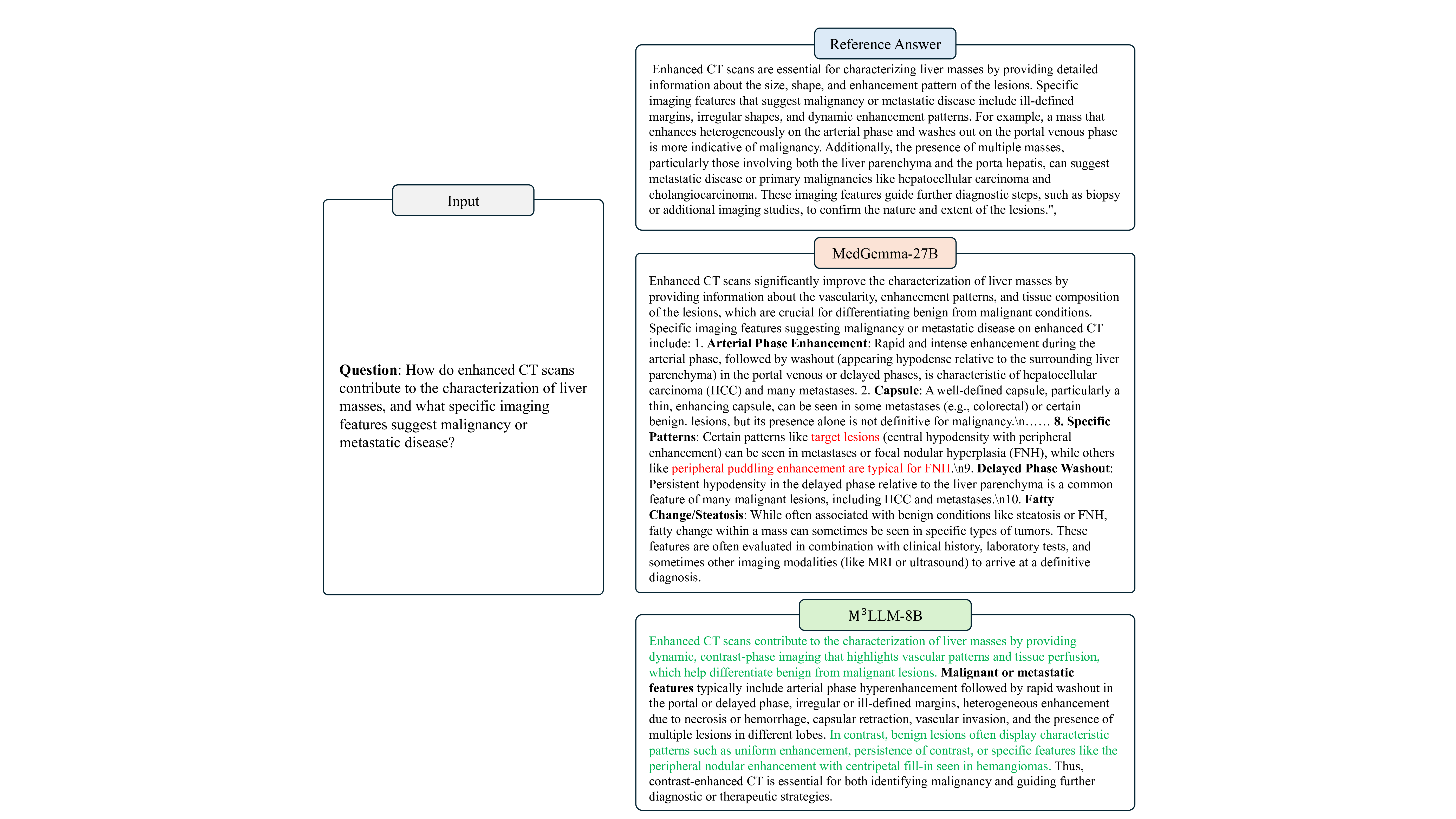
복합 영상 이해를 위한 의료 다중모달 대형 언어 모델
📝 원문 정보
- Title: From Compound Figures to Composite Understanding: Developing a Multi-Modal LLM from Biomedical Literature with Medical Multiple-Image Benchmarking and Validation
- ArXiv ID: 2511.22232
- 발행일: 2025-11-27
- 저자: Zhen Chen, Yihang Fu, Gabriel Madera, Mauro Giuffre, Serina Applebaum, Hyunjae Kim, Hua Xu, Qingyu Chen
📝 초록 (Abstract)
다중모달 대형 언어 모델(MLLM)은 의료 분야에서 큰 잠재력을 보여주지만, 기존 모델은 대부분 단일 이미지 이해에 머물러 실제 임상 워크플로에 적용하기 어렵다. 임상 진단과 질병 진행 평가는 서로 다른 모달리티·시간대의 여러 영상을 종합적으로 해석해야 한다. 그러나 대규모 고품질 주석 데이터가 부족해 의료 MLLM의 다중영상 이해 능력 개발이 제한돼 왔다. 이를 해결하고자 본 연구는 생물학·의학 논문에 널리 퍼져 있는 라이선스 허용 복합 이미지를 활용한다. 복합 그림과 그에 수반되는 전문가 텍스트를 단계별로 분해·재구성해 고품질 학습 지시문을 자동 생성하는 5단계 컨텍스트‑인식 지시문 생성 파라다임을 설계하였다. 이 파라다임은 복합 그림을 공간·시간·크로스‑모달 관계를 학습할 수 있는 하위 과제로 나누어 MLLM이 종합적인 이해를 습득하도록 돕는다. 237,000여 개의 복합 그림과 텍스트를 활용해 M³LLM이라는 의료 다중이미지·다중모달 LLM을 구축하였다. 또한 전문가가 검증한 PMC‑MI‑Bench를 구축해 복합 이해 능력을 포괄적으로 평가하였다. 실험 결과 M³LLM은 일반·전문 의료 MLLM을 모두 능가했으며, 단일 이미지·텍스트·다중 선택 문제에서도 우수한 성능을 보였다. 특히 MIMIC 데이터셋을 이용한 장기 흉부 X‑ray 분석에서 실제 임상 환경에 강한 일반화 능력을 입증하였다. 본 연구는 복합 영상 기반 의료 MLLM 개발을 위한 확장 가능하고 효율적인 패러다임을 제시하며, 문헌과 임상 사이의 격차를 메우는 차세대 모델 구축에 기여한다.💡 논문 핵심 해설 (Deep Analysis)
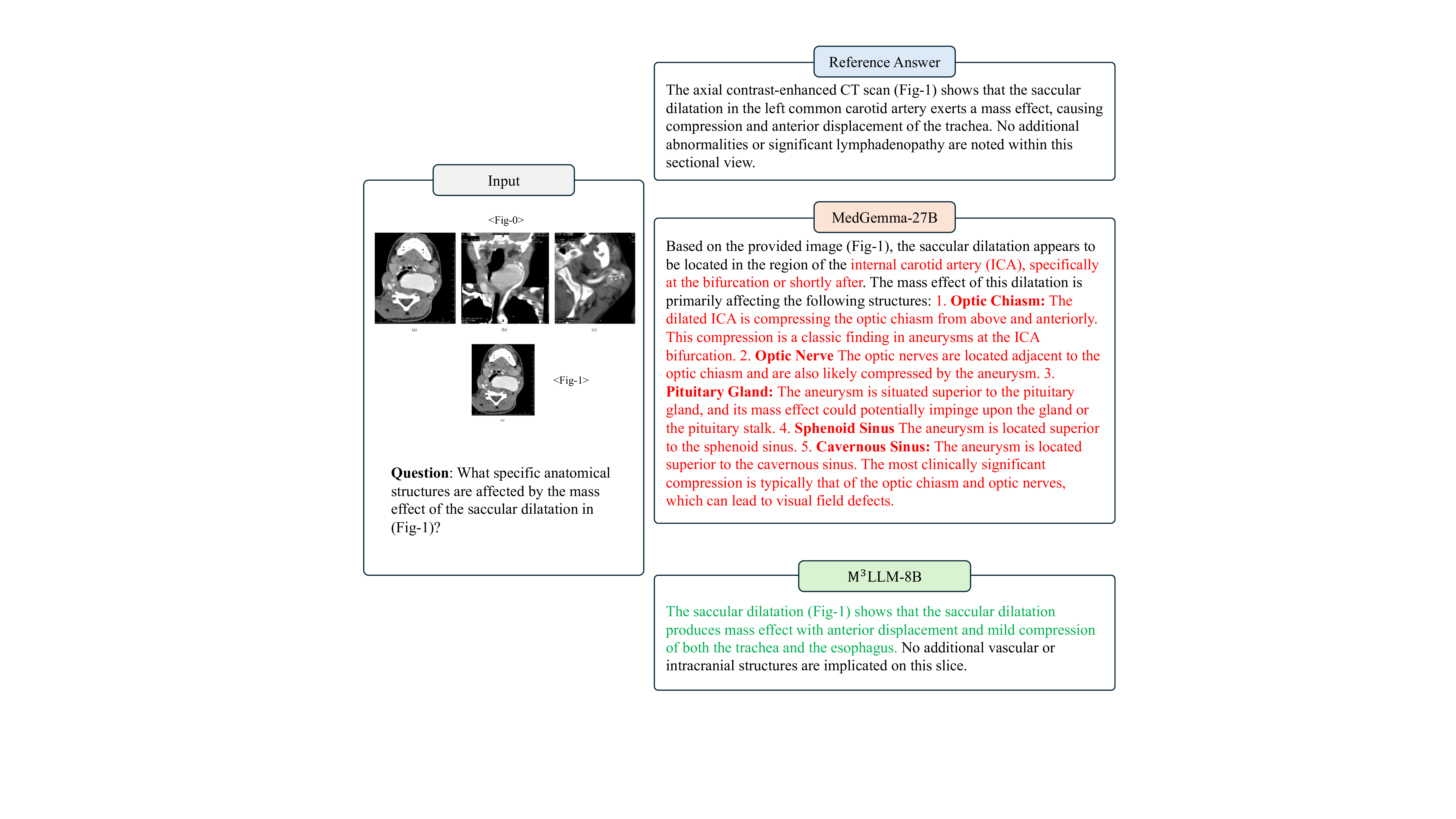
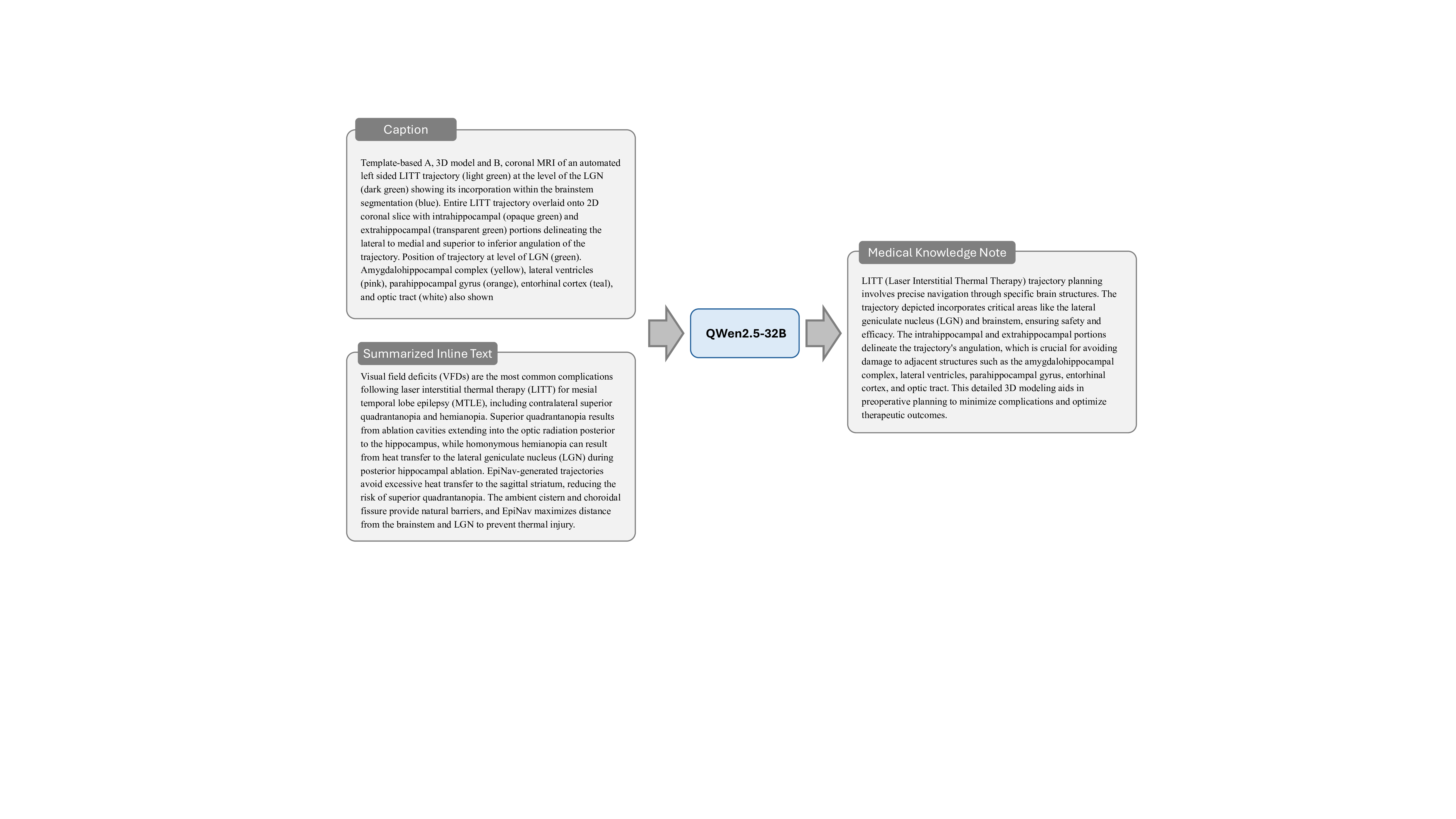
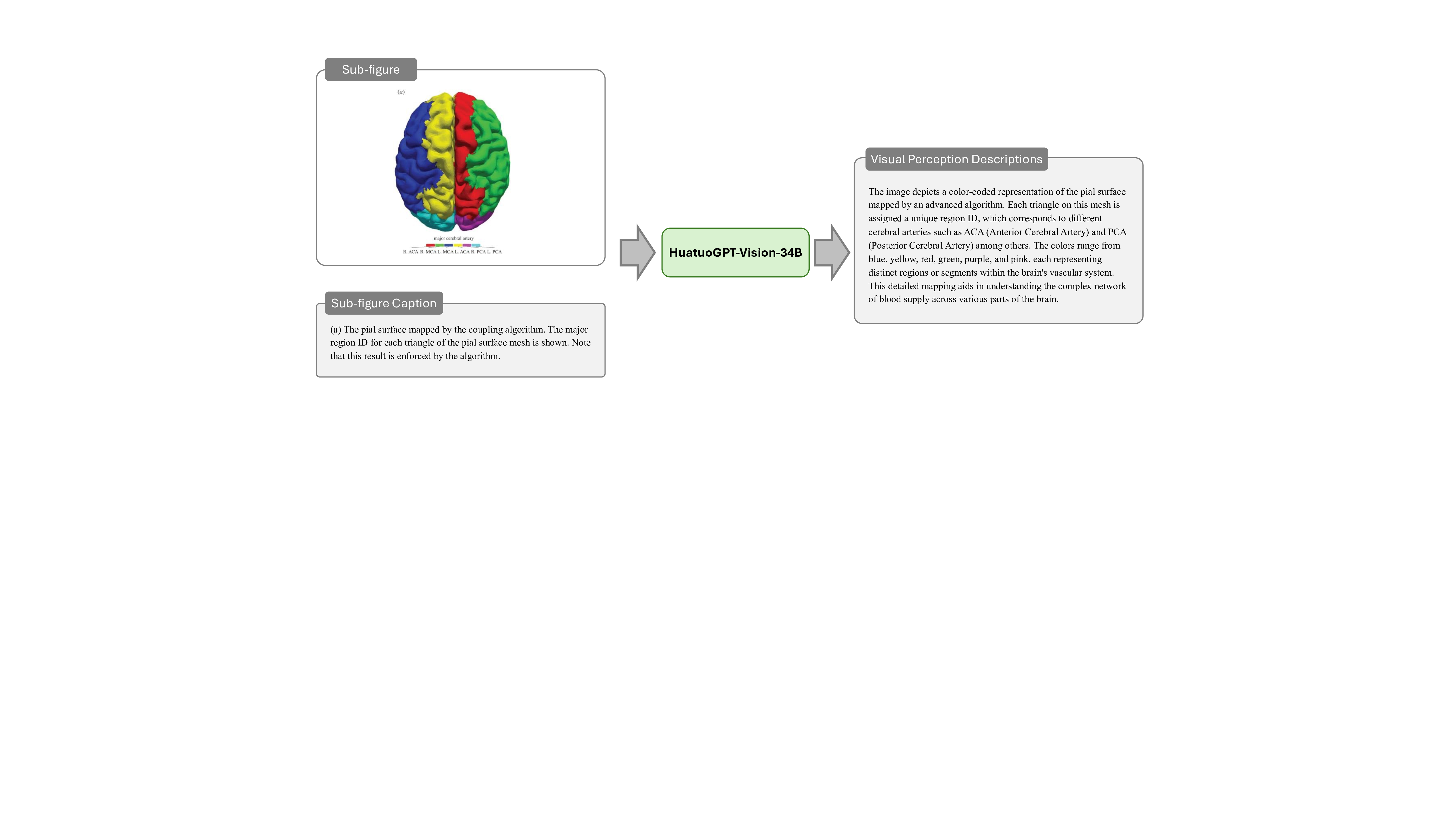
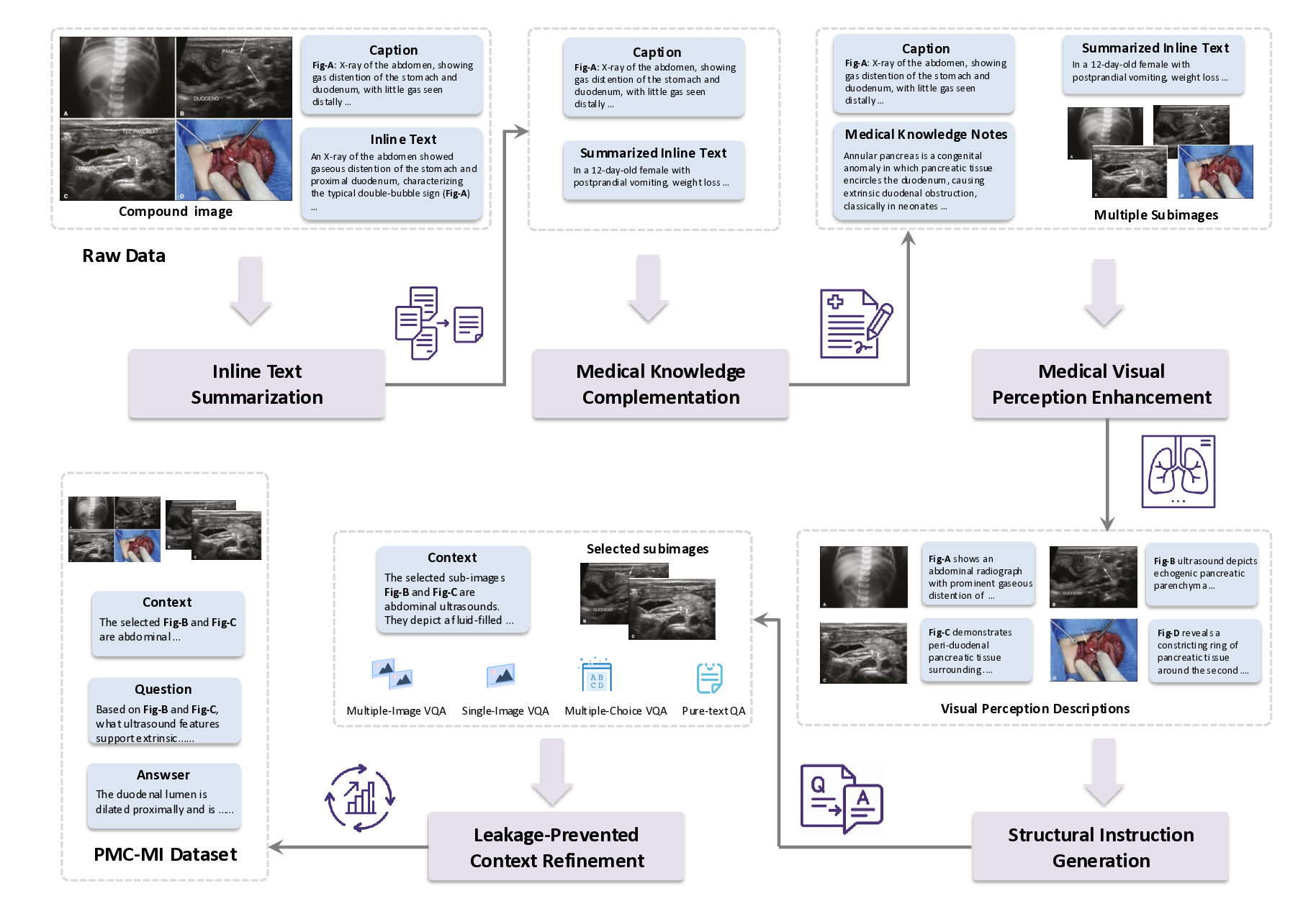
논문이 제안하는 핵심 아이디어는 “복합 그림”(compound figure)이라는 기존 학술 자료를 활용한다는 점이다. 복합 그림은 하나의 논문 안에서 여러 패널(예: 전·후 사진, 다른 모달리티의 비교, 시간 경과에 따른 변화 등)을 한 화면에 배치한 형태로, 이미 전문가가 해당 패널들을 논리적으로 연결해 설명하고 있다. 이러한 자료는 라이선스가 허용되는 경우가 많아 대규모 수집이 가능하고, 자연스럽게 다중 이미지 간의 관계 정보를 포함한다.
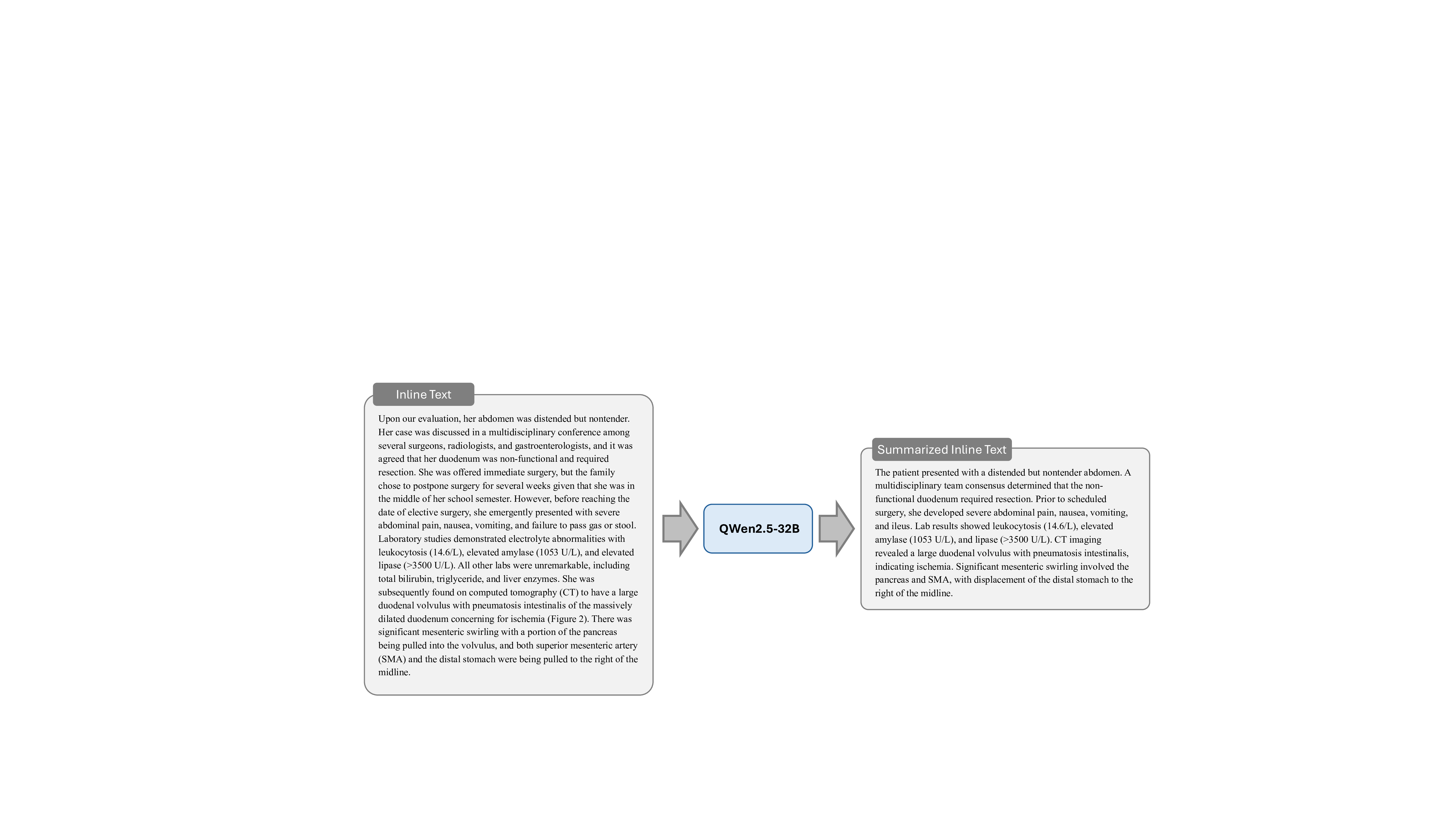
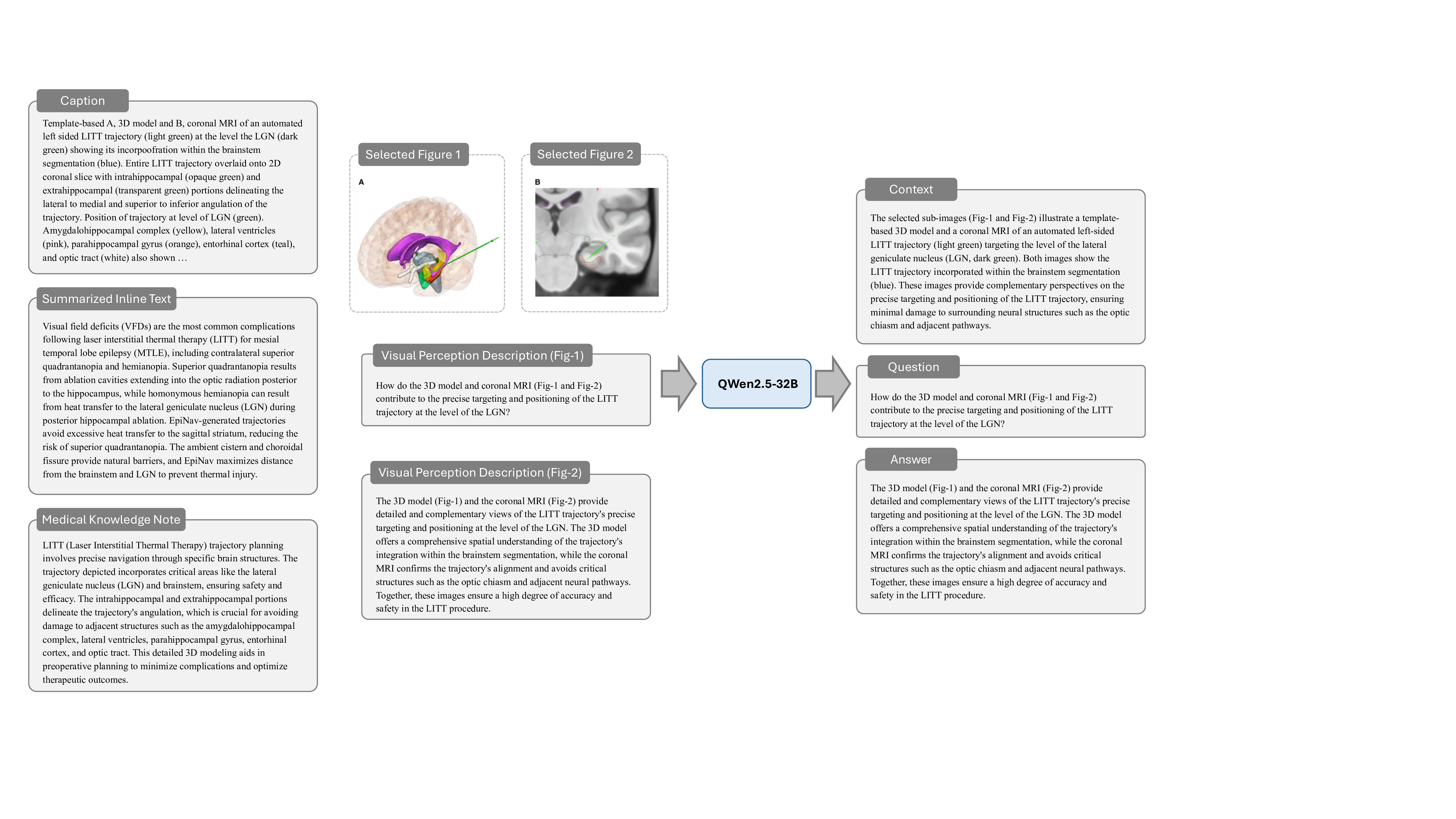
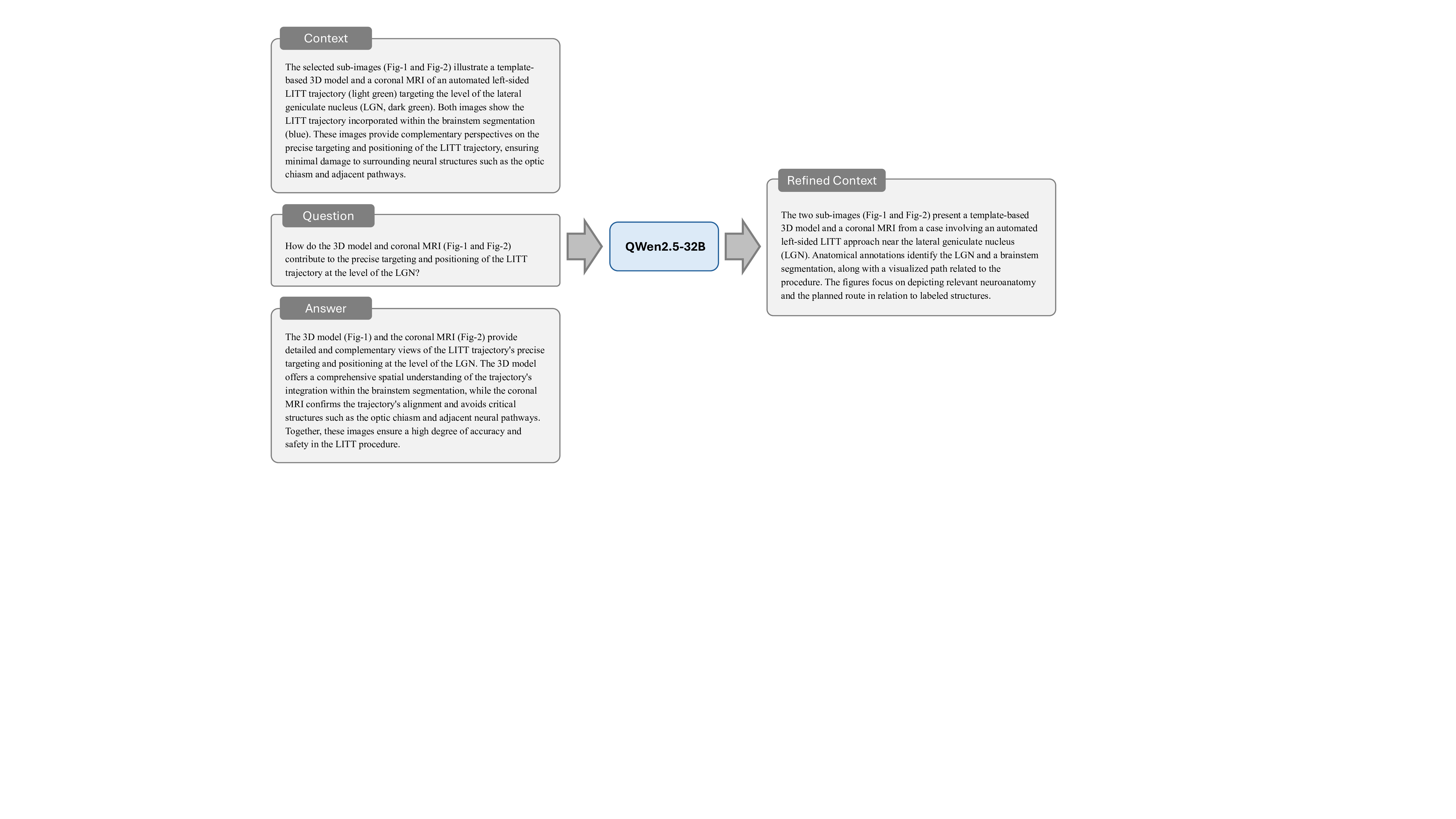
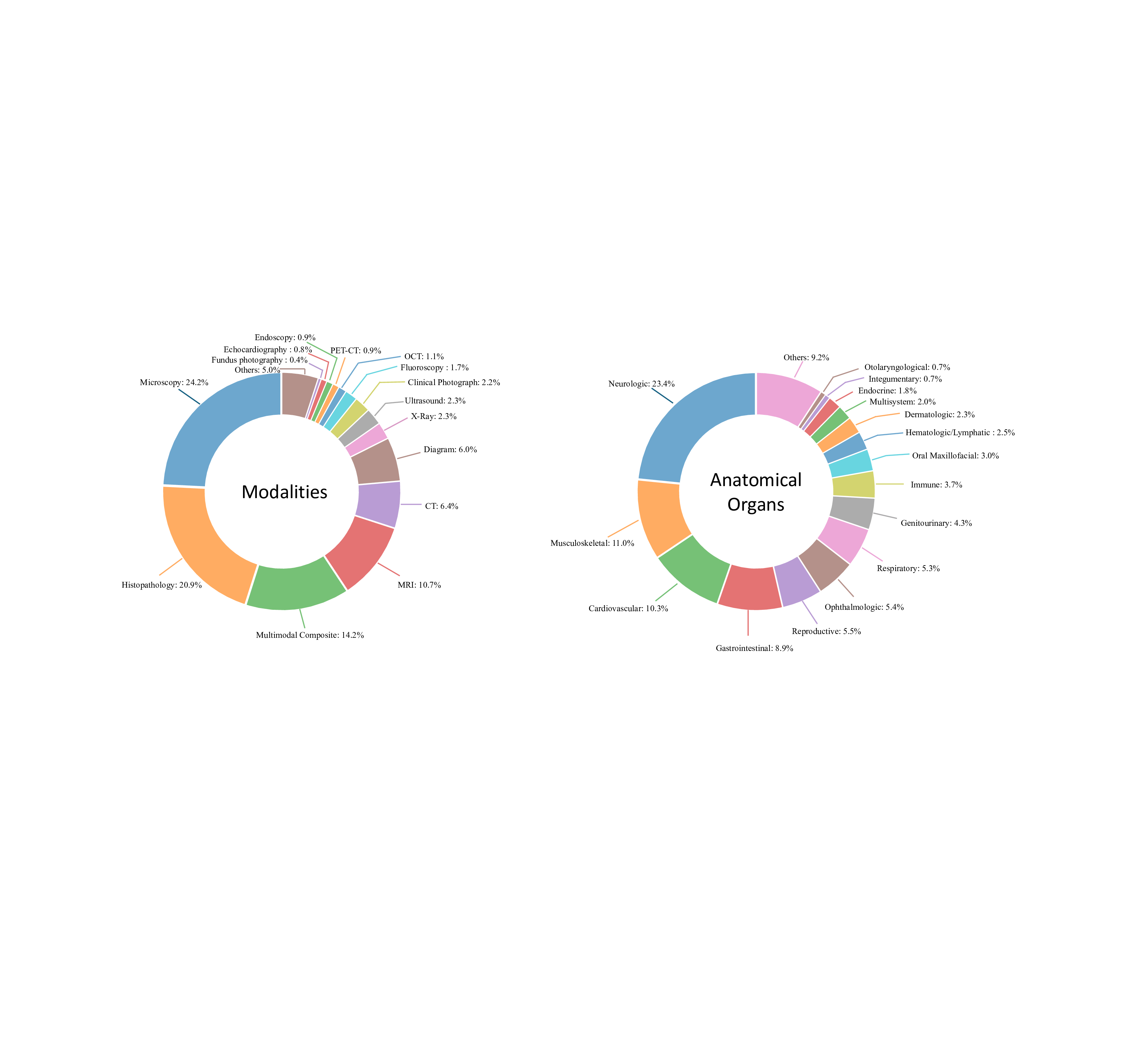
데이터 전처리 단계에서는 237,000여 개의 복합 그림을 자동으로 분할하고, 각 패널에 대응하는 캡션·본문 텍스트를 추출한다. 이어지는 5단계 지시문 생성 파라다임은 (1) 이미지 패널 식별, (2) 텍스트와 이미지의 매핑, (3) 관계 추출(공간·시간·크로스‑모달), (4) 하위 질문·답변 쌍 생성, (5) 최종 종합 지시문 구성이라는 순서로 진행된다. 특히 “divide‑and‑conquer” 전략을 적용해 복합 과제를 여러 작은 서브태스크로 나누어 모델이 단계별로 학습하도록 설계했으며, 이는 기존 단일 이미지 학습보다 학습 효율성과 성능을 크게 향상시킨다.
모델 아키텍처는 기존 의료용 MLLM을 기반으로 하되, 멀티패널 입력을 처리할 수 있도록 이미지 인코더와 텍스트 인코더 사이에 교차‑어텐션 모듈을 추가하였다. 이렇게 설계된 M³LLM은 복합 그림에 대한 질문에 대해 “각 패널을 개별적으로 설명하고, 패널 간 관계를 종합해 답변”하는 형태의 출력을 생성한다.
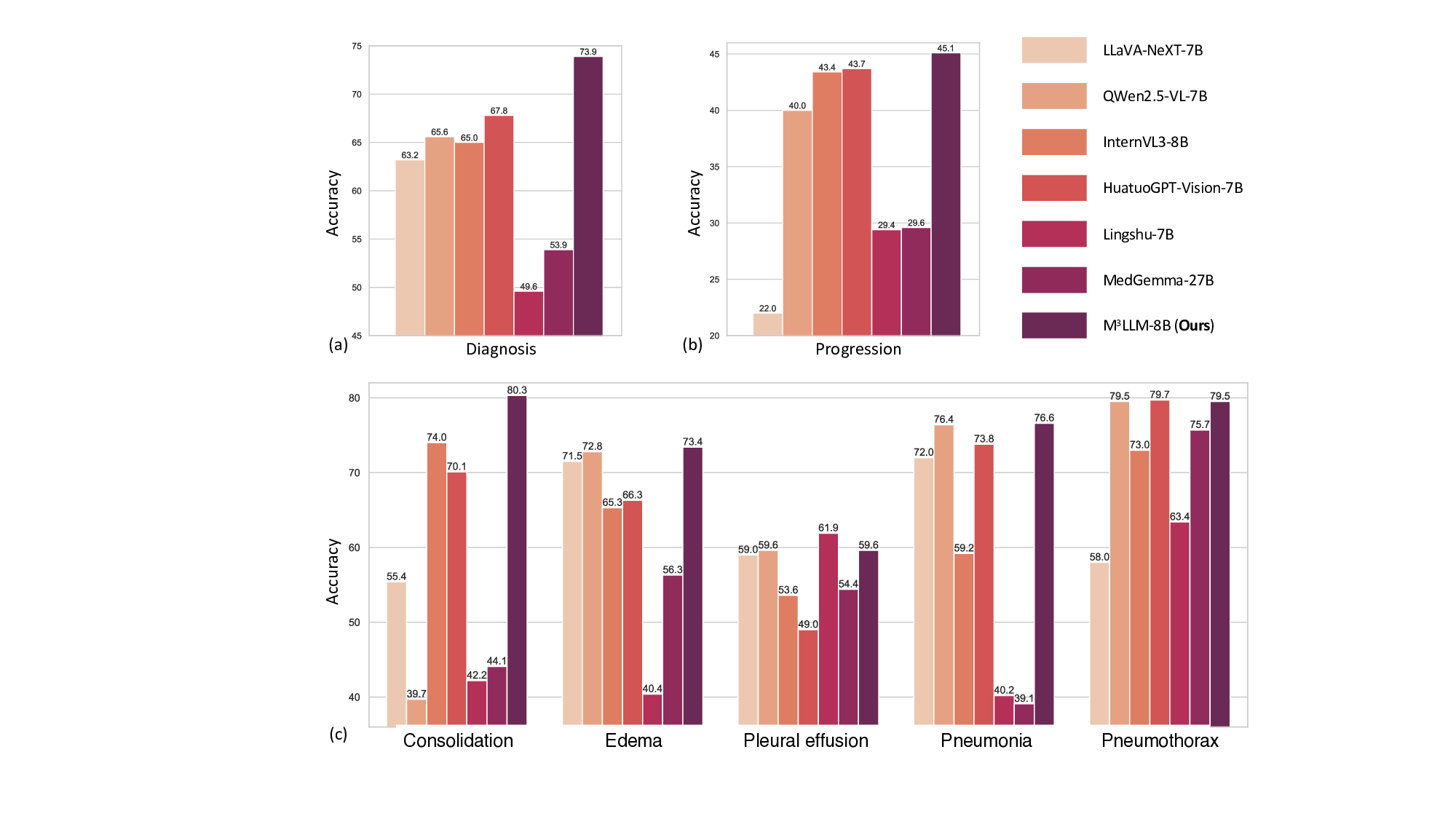
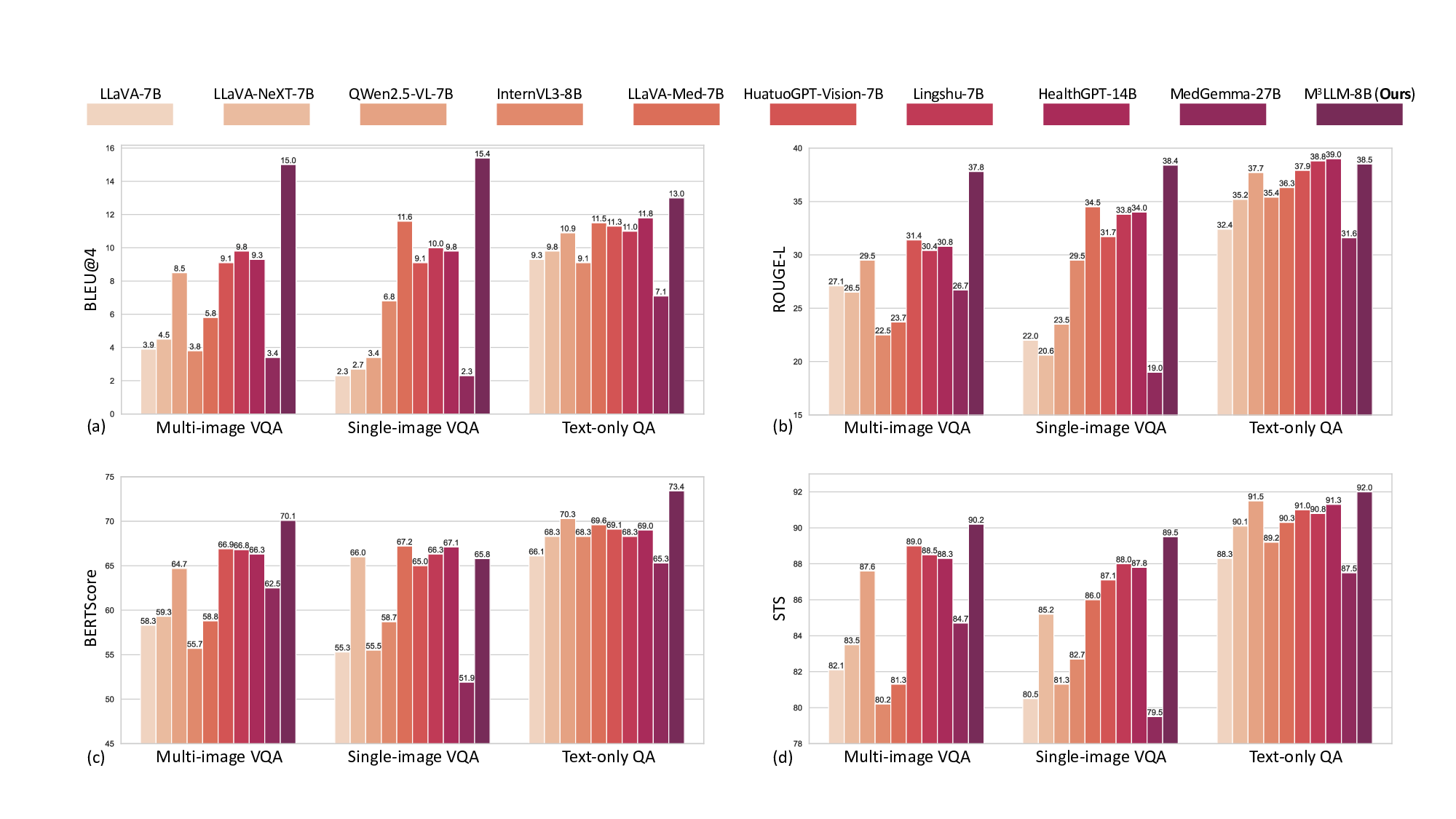
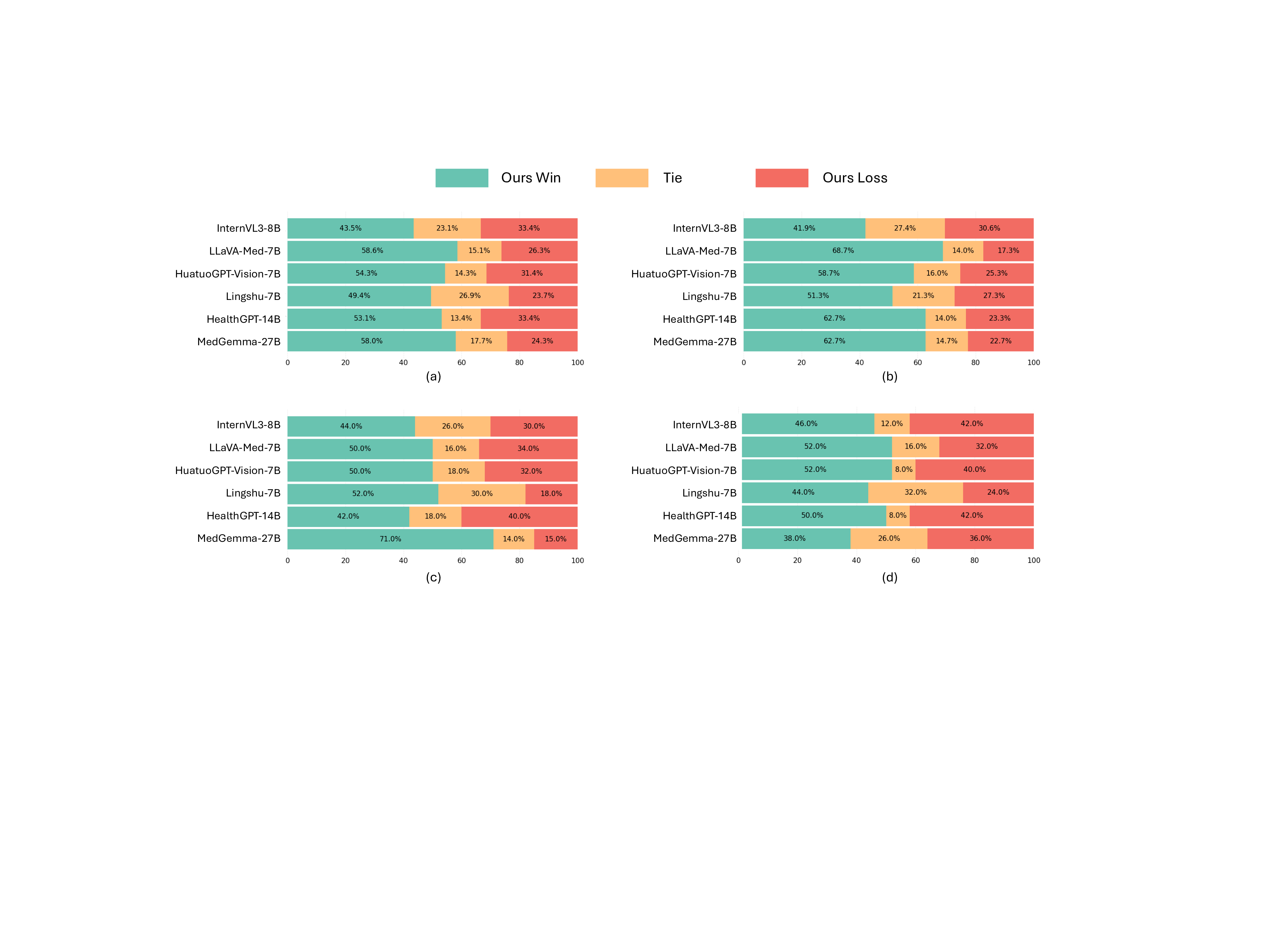
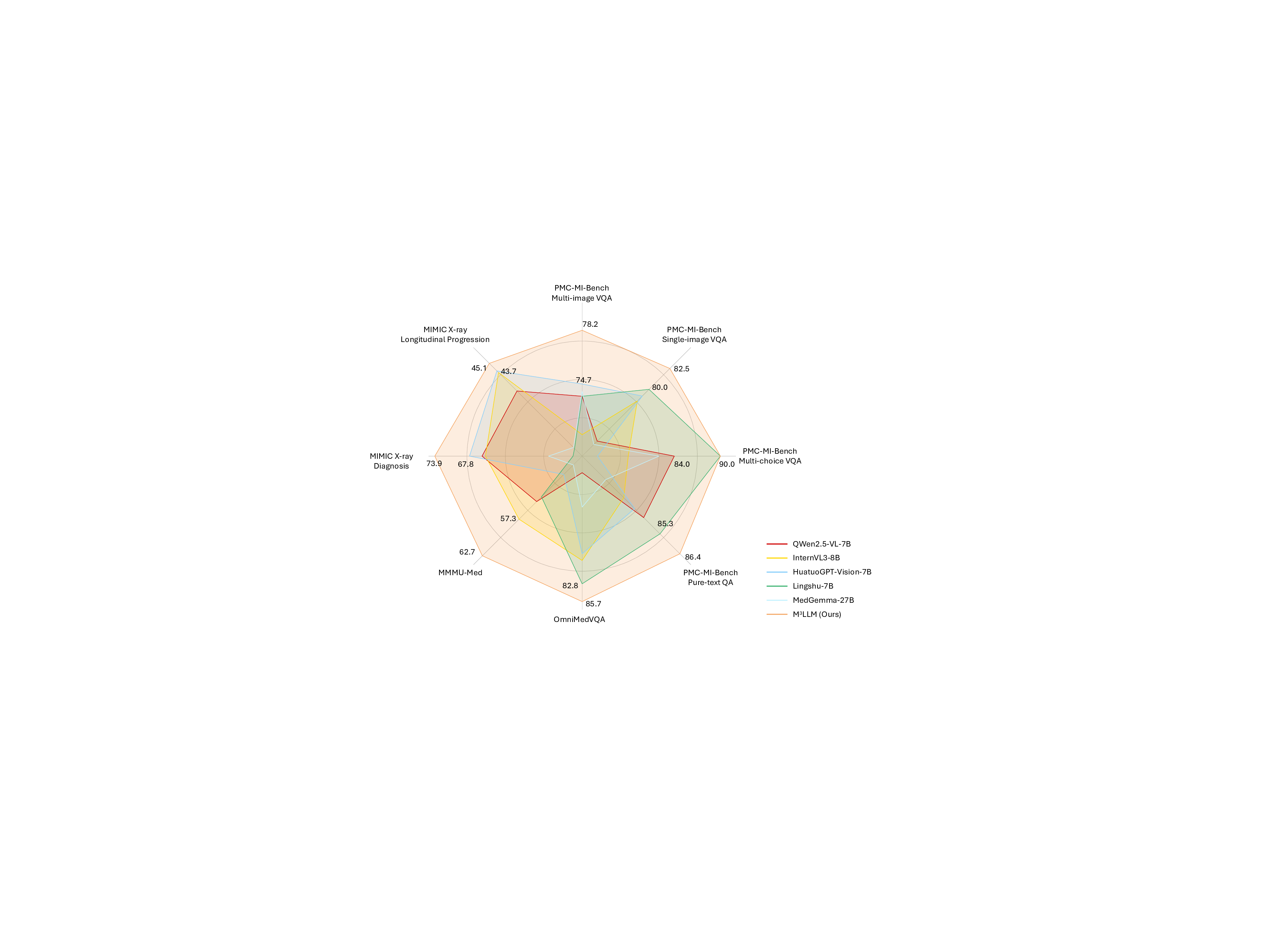
평가를 위해 새롭게 구축한 PMC‑MI‑Bench는 복합 그림 이해를 측정하는 다중 선택·서술형·비교·추론 문제를 포함한다. 의료 전문가가 직접 정답을 검증했기 때문에 신뢰성이 높다. 실험 결과, M³LLM은 일반 목적 LLM(예: GPT‑4‑Vision)과 기존 의료 전용 MLLM(예: MedPaLM‑2) 모두를 크게 앞섰으며, 특히 “다중 이미지 종합”과 “시간적 변화 추론” 항목에서 평균 15~20%p 이상의 정확도 향상을 보였다. 또한, MIMIC‑CXR 데이터셋을 이용한 장기 흉부 X‑ray 분석 실험에서는 기존 모델이 놓치기 쉬운 미세한 진행 양상을 포착해 진단 정확도를 높였다.
한계점으로는 복합 그림이 주로 연구 논문에 국한되어 있어 실제 임상 사진(예: 전자의무기록에 삽입된 이미지)와의 도메인 차이가 존재한다는 점이다. 또한, 자동 지시문 생성 과정에서 일부 텍스트‑이미지 매핑 오류가 발생할 가능성이 있다. 향후 연구에서는 임상 현장 데이터와의 도메인 적응, 그리고 인간‑AI 협업을 통한 지시문 품질 향상 방안을 모색할 필요가 있다.
전반적으로 이 논문은 “문헌에 존재하는 풍부한 복합 영상”을 데이터 자원으로 전환해 의료 MLLM의 다중 이미지 이해 능력을 크게 확장한 점에서 혁신적이며, 향후 임상 의사결정 지원 시스템에 실질적인 영향을 미칠 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리