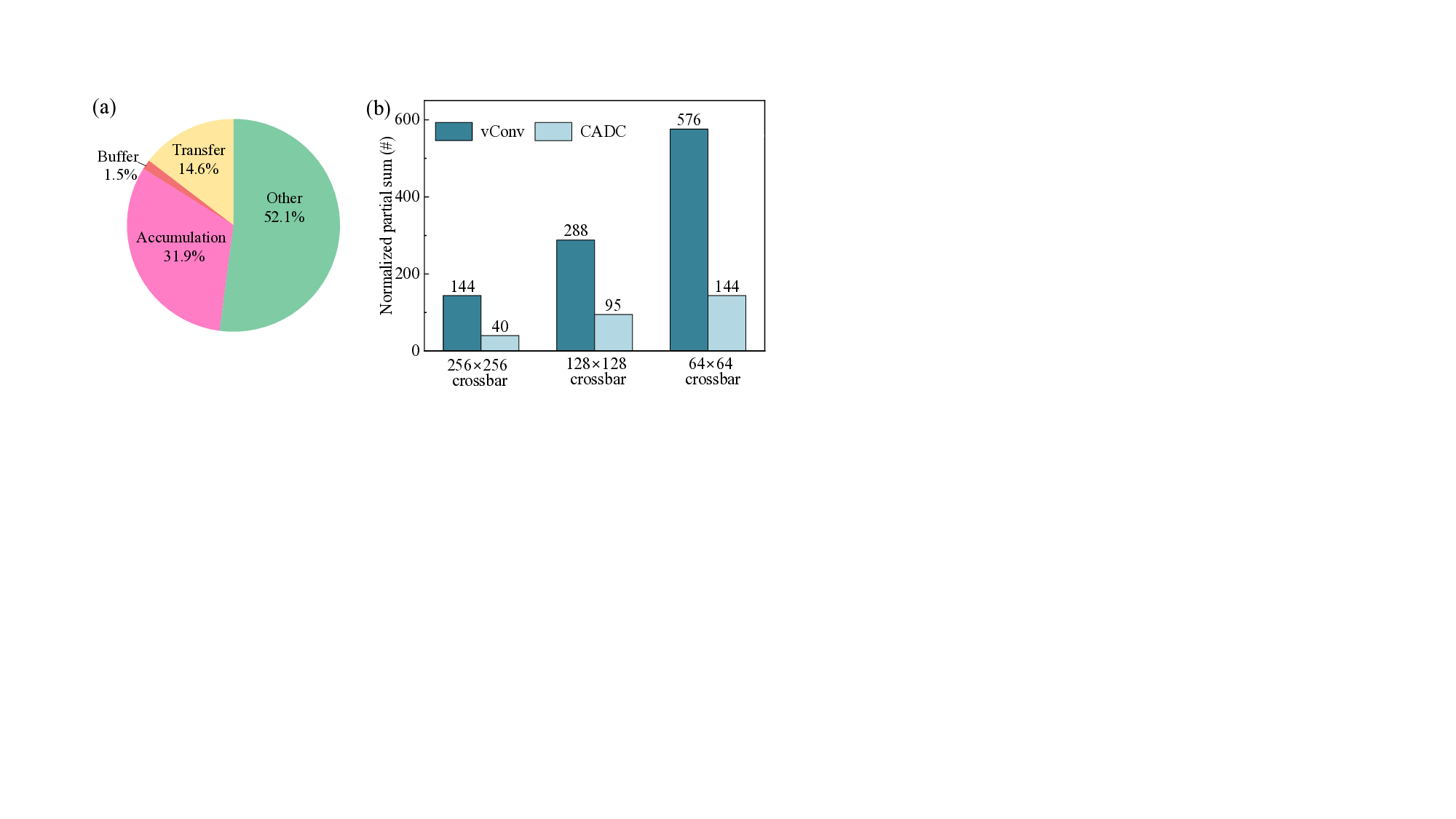교차바 기반 수상돌기 컨볼루션으로 부분합 희소성 극대화
📝 원문 정보
- Title: CADC: Crossbar-Aware Dendritic Convolution for Efficient In-memory Computing
- ArXiv ID: 2511.22166
- 발행일: 2025-11-27
- 저자: Shuai Dong, Junyi Yang, Ye Ke, Hongyang Shang, Arindam Basu
📝 초록 (Abstract)
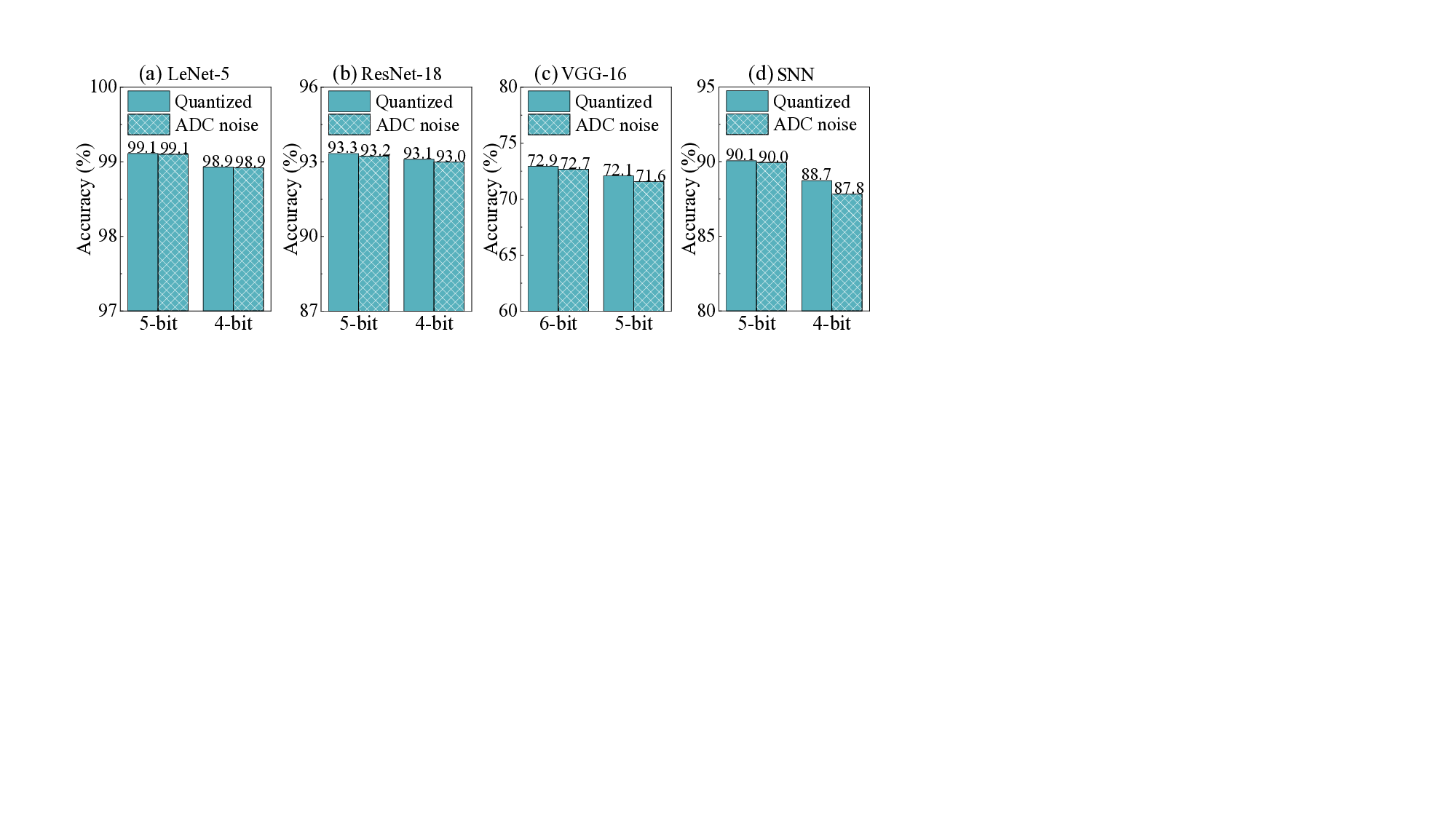
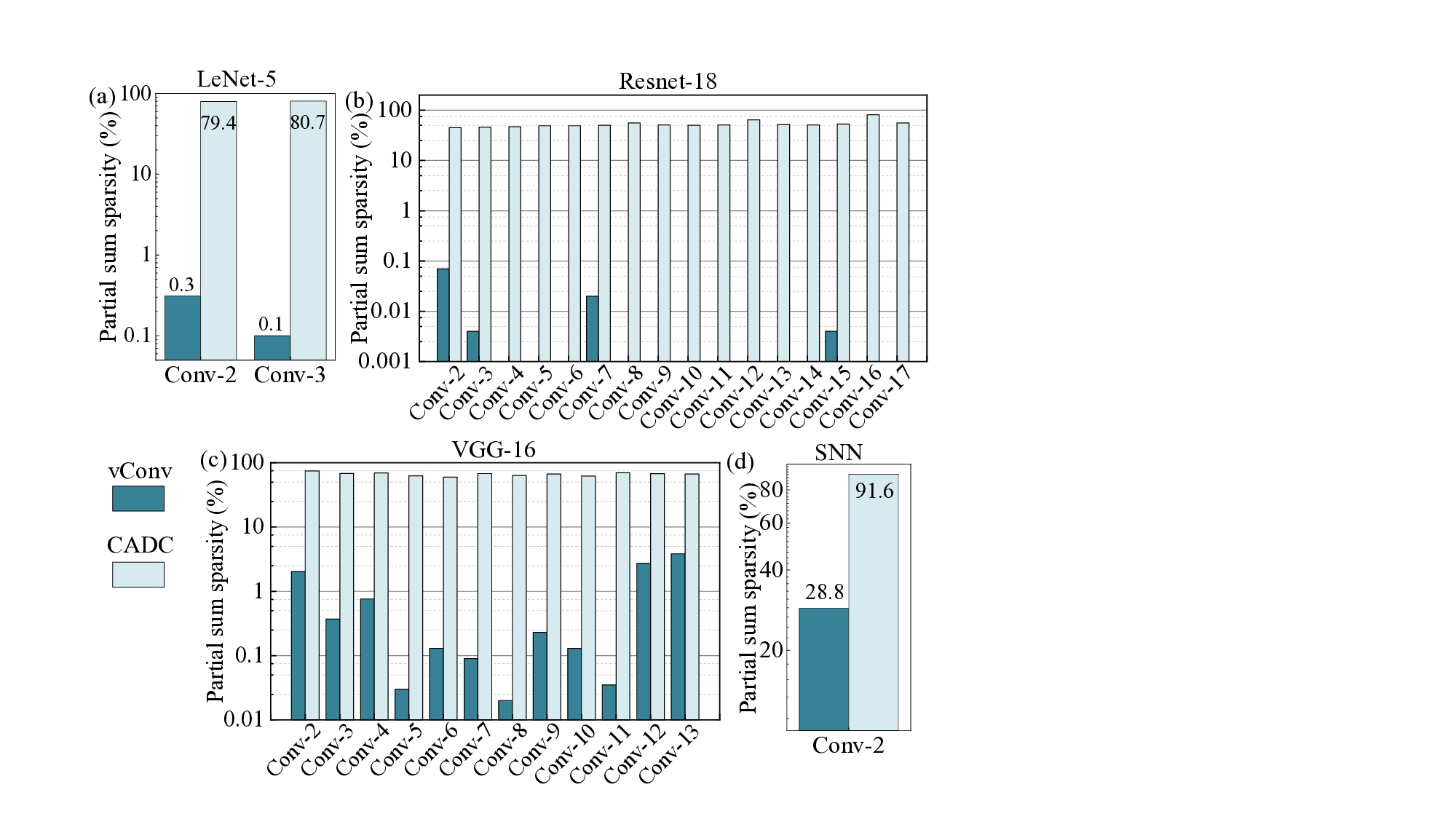
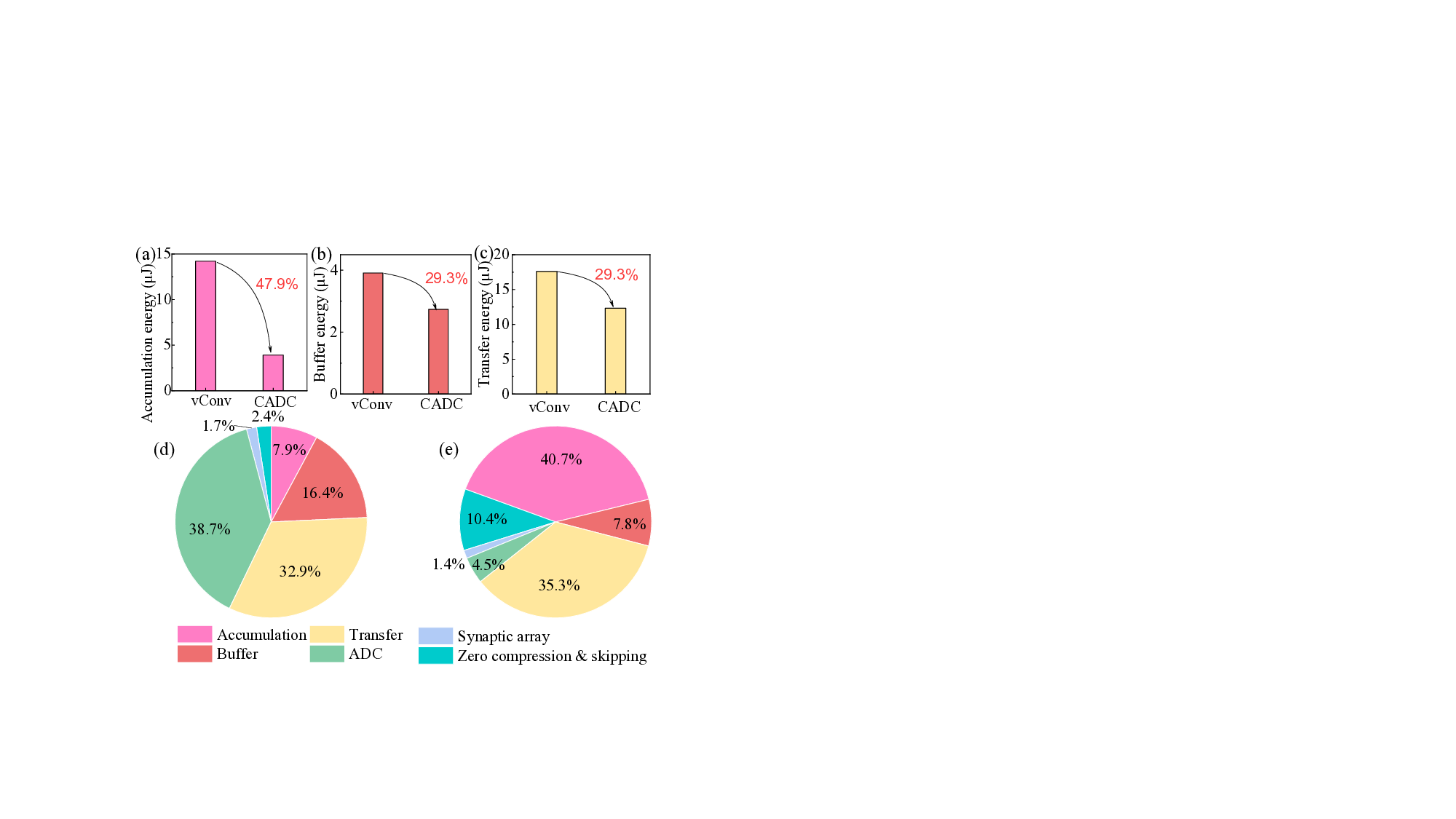
컨볼루션 신경망(CNN)은 연산량이 많아 교차바 기반 인메모리 컴퓨팅(IMC) 구조로 가속화되는 경우가 많다. 그러나 큰 컨볼루션 층은 여러 교차바에 분할돼 다수의 부분합(psum)이 생성되며, 이는 추가 버퍼, 전송 및 누적을 필요로 하여 시스템 수준의 오버헤드를 크게 만든다. 신경과학의 수상돌기 컴퓨팅 원리를 차용해, 우리는 교차바 인식 연산에 비선형 수상돌기 함수(음수 값을 0으로 만드는)를 직접 삽입하는 새로운 방법인 교차바‑인식 수상돌기 컨볼루션(CADC)을 제안한다. 실험 결과 CADC는 LeNet‑5(MNIST)에서 psum을 80 %, ResNet‑18(CIFAR‑10)에서 54 %, VGG‑16(CIFAR‑100)에서 66 %, DVS Gesture 데이터셋의 스파이킹 신경망(SNN)에서는 최대 88 %까지 크게 감소시켰다. CADC가 유도한 희소성은 (1) 제로 압축 및 제로 스키핑을 가능하게 하여 버퍼·전송 오버헤드를 29.3 % 감소시키고 누적 오버헤드를 47.9 % 감소시키며, (2) ADC 양자화 잡음 누적을 최소화해 정확도 저하를 LeNet‑5 0.01 %, ResNet‑18 0.1 %, VGG‑16 0.5 %, SNN 0.9 % 수준으로 제한한다. 기존 컨볼루션(vConv)과 비교했을 때 CADC는 교차바 크기 64×64~256×256에서 LeNet‑5는 +0.11~+0.19 %, ResNet‑18은 –0.04~–0.27 %, VGG‑16은 +0.99~+1.60 %, SNN은 –0.57~+1.32 %의 정확도 변화를 보인다. 최종적으로 SRAM 기반 IMC 구현에서 CADC는 ResNet‑18(4/2/4 bit) 기준 2.15 TOPS·40.8 TOPS/W를 달성했으며, 기존 IMC 가속기에 비해 속도는 11~18배, 에너지 효율은 1.9~22.9배 향상되었다.💡 논문 핵심 해설 (Deep Analysis)
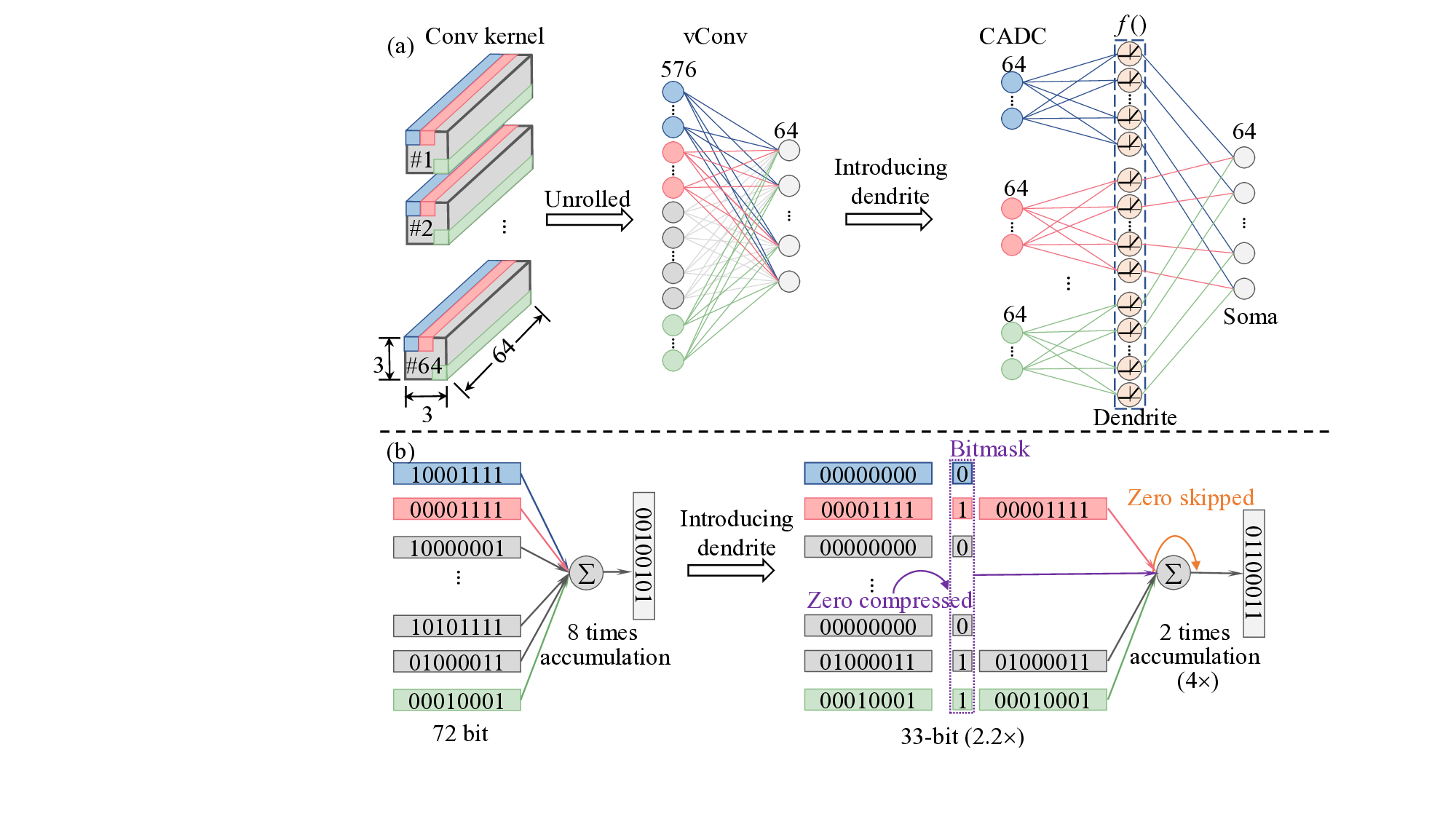
이 논문은 뇌의 수상돌기(dendrite)에서 관찰되는 ‘음수 억제’ 메커니즘을 영감으로 삼아, 교차바 내부에 비선형 함수를 삽입한다. 구체적으로, 교차바 연산 결과가 음수일 경우 이를 0으로 강제하는 함수(즉, ReLU와 유사한 제로화)를 하드웨어 수준에서 구현한다. 이렇게 하면 각 교차바가 출력하는 psum 중 음수 성분이 사전에 제거돼, 실제로 전달·누적해야 할 값이 크게 줄어든다. 결과적으로 (a) psum의 전체 개수가 감소해 버퍼 요구량이 감소하고, (b) 전송되는 데이터 중 0값을 압축·스키핑할 수 있어 메모리·버스 대역폭이 절감되며, (c) 누적 과정에서 양자화 잡음이 적은 0값이 많이 포함돼 평균 잡음이 낮아진다. 이러한 장점은 특히 저비트(4/2/4 bit) 양자화와 스파이킹 신경망(SNN)처럼 잡음에 민감한 모델에서 두드러진다.
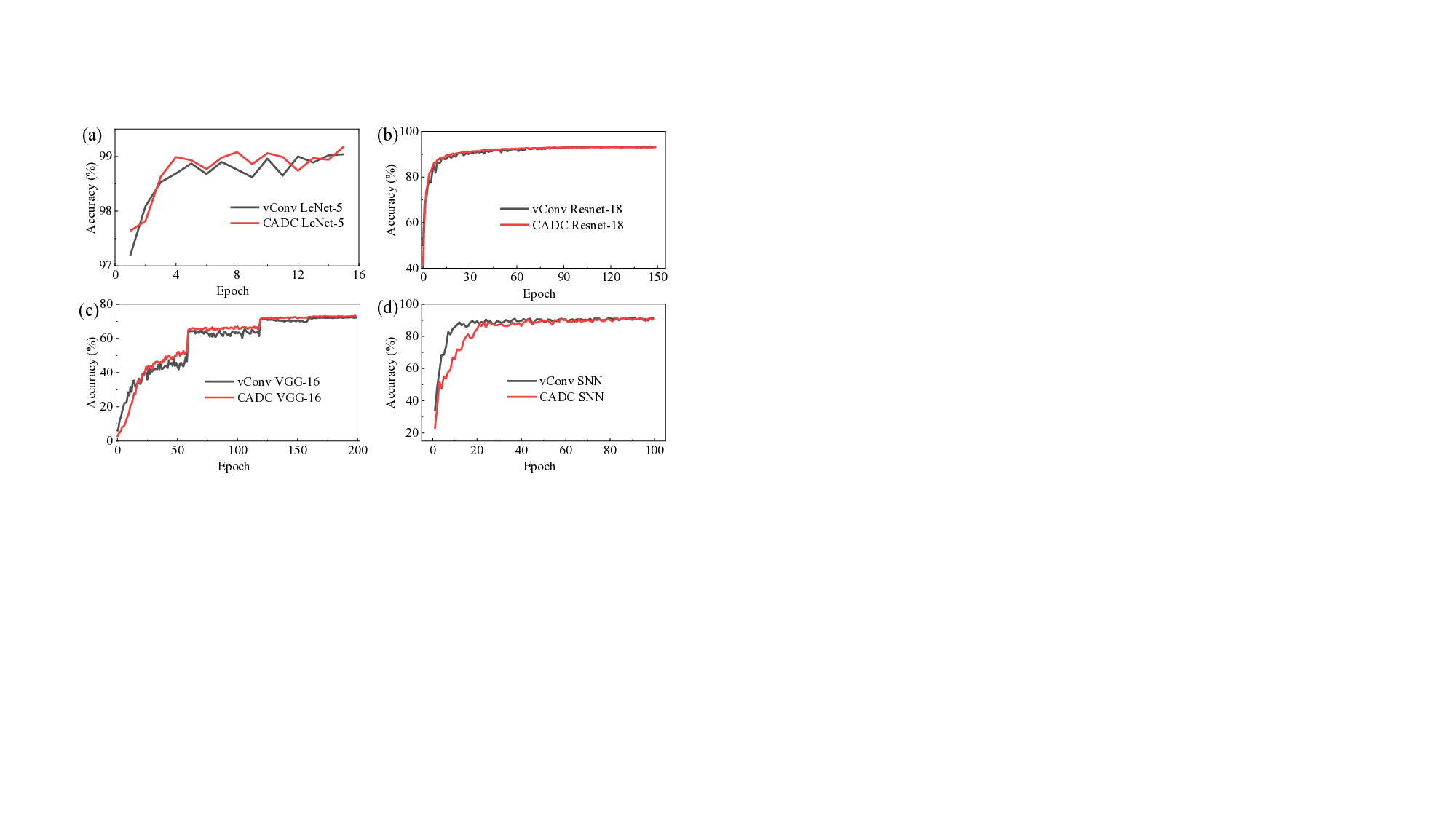
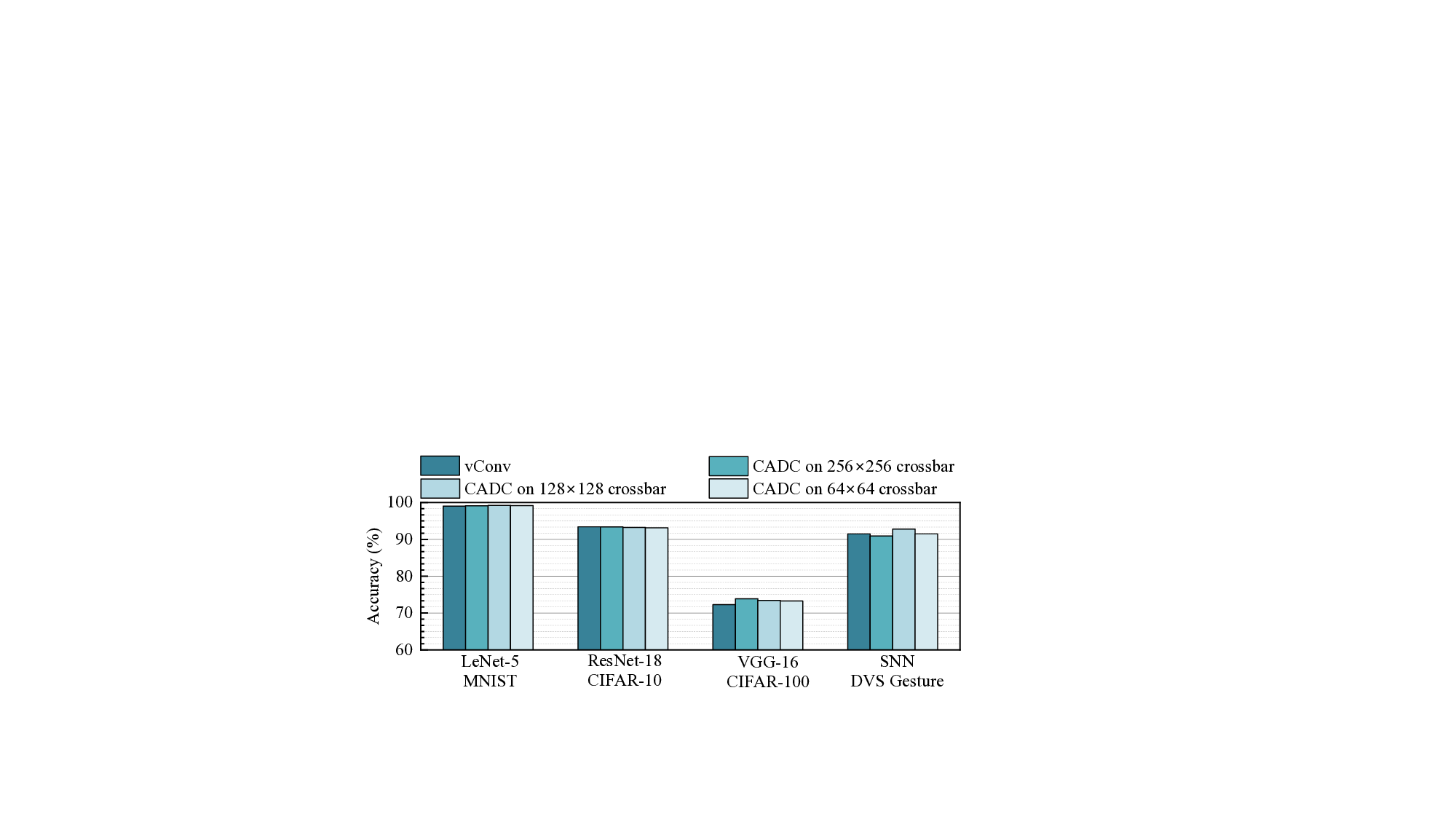
실험에서는 대표적인 네트워크인 LeNet‑5, ResNet‑18, VGG‑16 및 DVS Gesture용 SNN에 CADC를 적용했다. LeNet‑5에서는 psum이 80 % 감소했으며, 정확도 저하가 0.01 %에 불과했다. ResNet‑18은 54 % 감소, VGG‑16은 66 % 감소, SNN은 최대 88 % 감소를 보였으며, 각각 0.1 %0.9 % 수준의 정확도 손실만을 기록했다. 흥미롭게도, 일부 경우에는 비선형 제로화가 활성화된 뉴런의 분포를 재조정해 일반화 성능이 약간 향상되기도 했다(예: VGG‑16에서 +0.99+1.60 %). 교차바 크기를 64×64에서 256×256까지 변동시켜도 정확도 변화는 ±0.3 % 이내에 머물렀다.
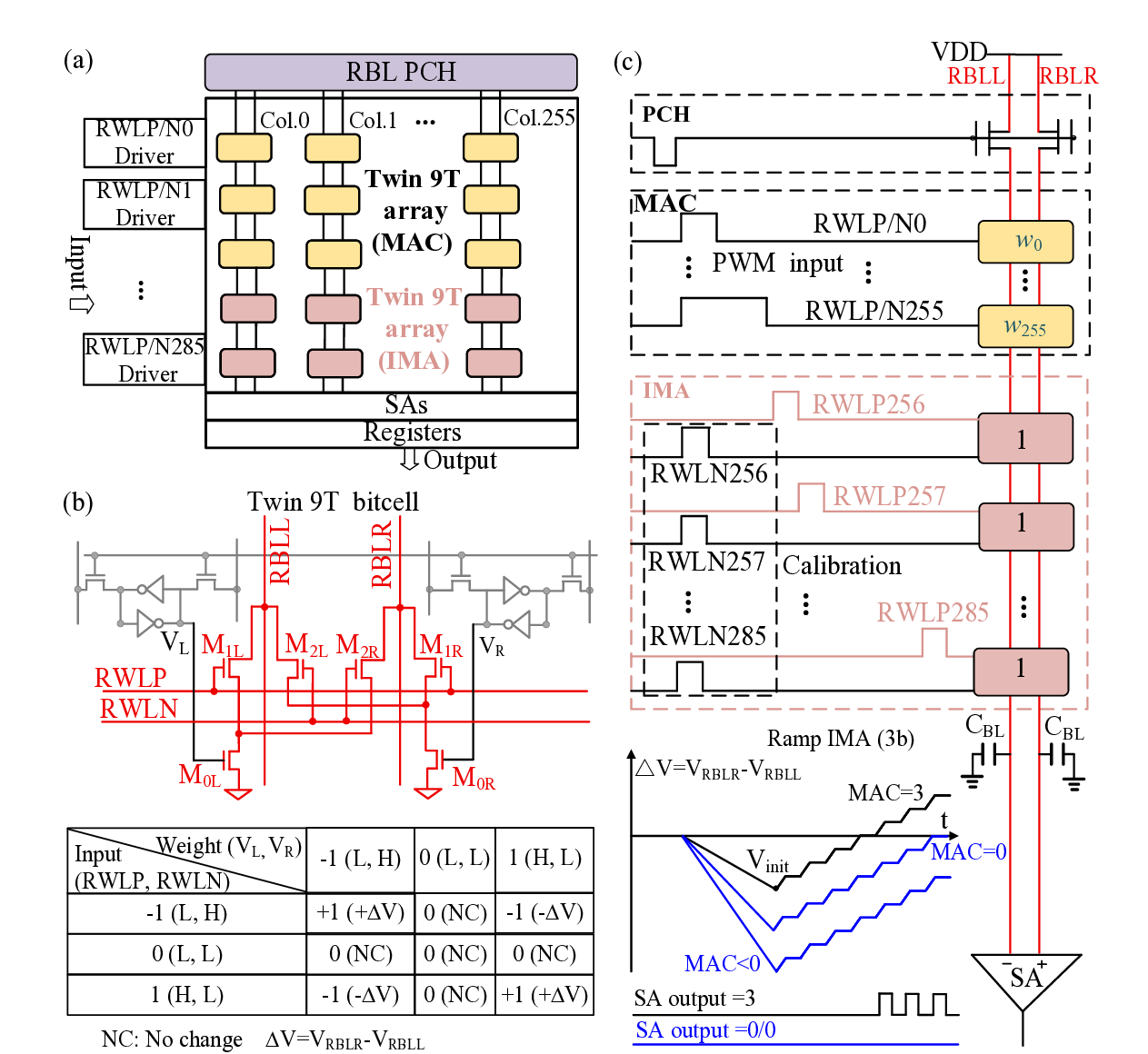
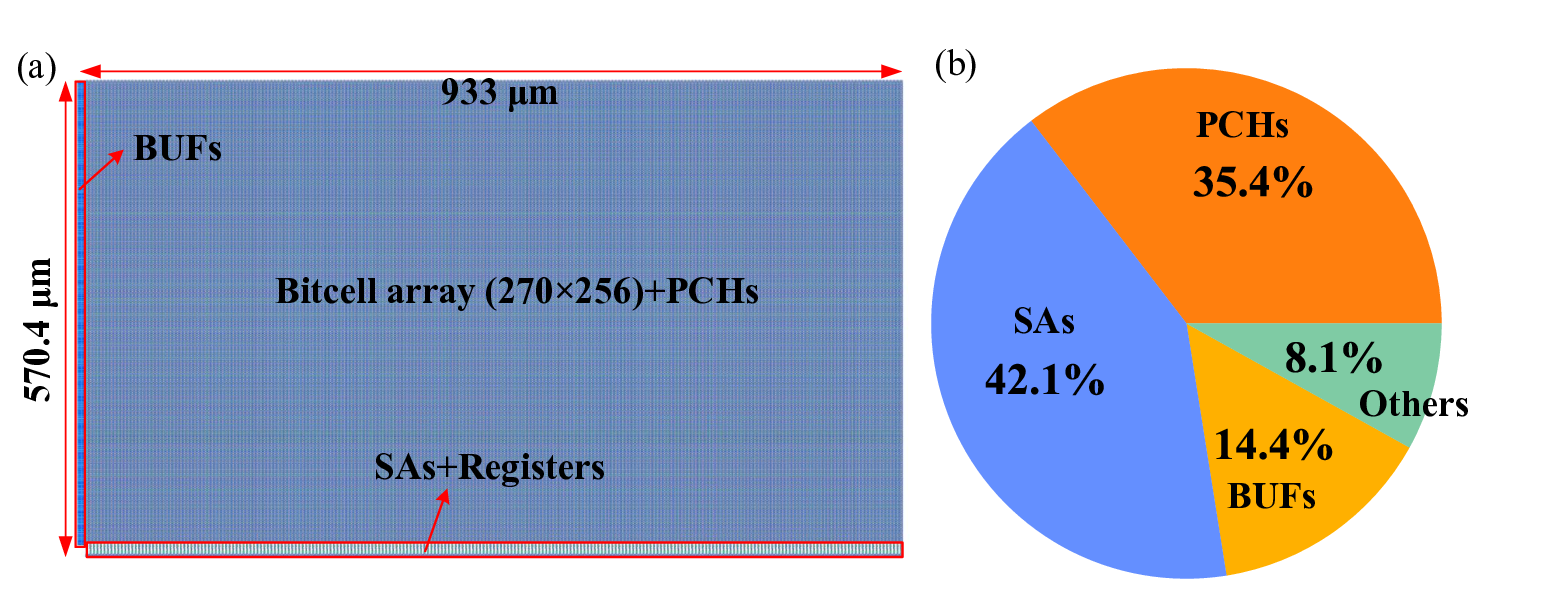
마지막으로 SRAM 기반 IMC 프로토타입에 CADC를 구현해 ResNet‑18(4/2/4 bit)에서 2.15 TOPS·40.8 TOPS/W를 달성했으며, 이는 기존 IMC 가속기 대비 1118배 빠른 처리 속도와 1.922.9배 높은 에너지 효율을 의미한다. 이는 교차바 설계 단계에서 비선형 함수를 삽입하는 것이 시스템 전체 성능을 크게 끌어올릴 수 있음을 입증한다. 앞으로는 다양한 비선형 함수와 동적 임계값 조절을 통해 더욱 높은 희소성을 유도하고, 비정형 메모리·광학 교차바 등 다른 물리적 구현에도 적용 가능성을 탐색할 여지가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리