신경형 가속기 성능 병목 모델링과 최적화: 플로어라인 접근법
📝 원문 정보
- Title: Modeling and Optimizing Performance Bottlenecks for Neuromorphic Accelerators
- ArXiv ID: 2511.21549
- 발행일: 2025-11-26
- 저자: Jason Yik, Walter Gallego Gomez, Andrew Cheng, Benedetto Leto, Alessandro Pierro, Noah Pacik-Nelson, Korneel Van den Berghe, Vittorio Fra, Andreea Danielescu, Gianvito Urgese, Vijay Janapa Reddi
📝 초록 (Abstract)
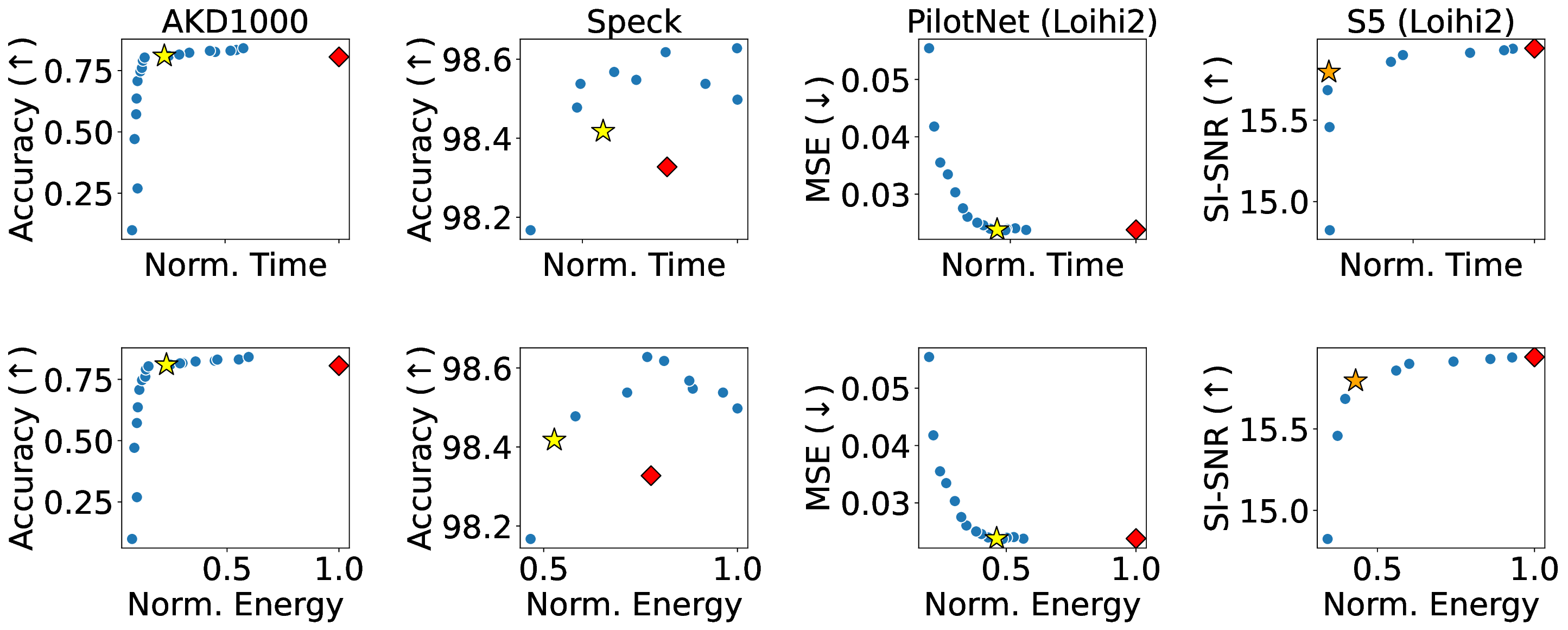
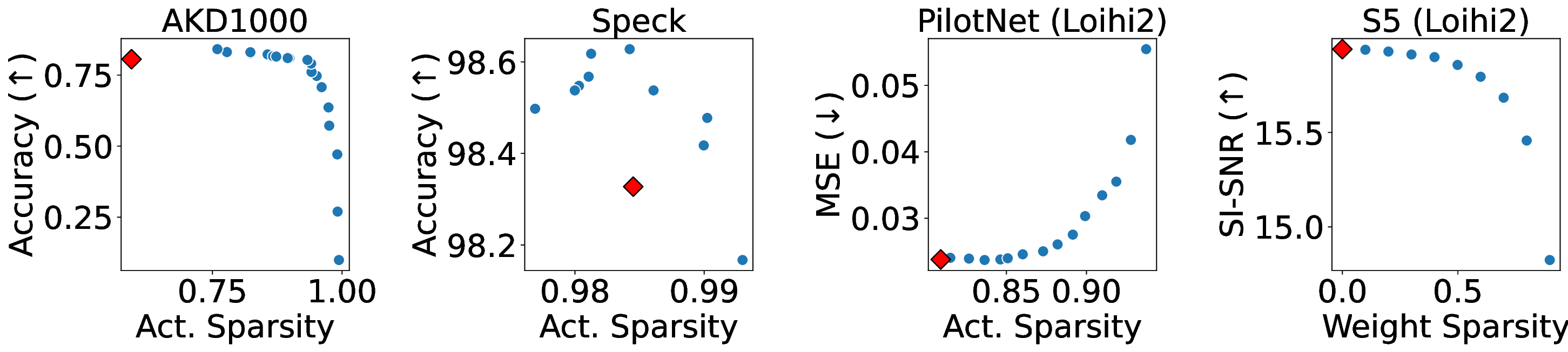
신경형 가속기는 이벤트 기반·공간 확장형 구조를 활용해 메모리와 연산을 공동 배치함으로써 비구조적 희소성을 자연스럽게 이용할 수 있어 머신러닝 추론에 유망한 플랫폼이다. 그러나 이러한 고유한 아키텍처 특성은 기존 가속기와는 전혀 다른 성능 동역학을 만든다. 기존의 신경형 가속기 워크로드 최적화 방법은 전체 네트워크 수준의 희소도와 연산 횟수에만 의존하지만, 이러한 지표가 실제 배포 성능을 얼마나 향상시키는지는 아직 밝혀지지 않았다. 본 논문은 신경형 가속기에 대한 최초의 포괄적인 성능 한계와 병목 분석을 제시한다. 이를 통해 기존 지표의 한계를 드러내고, 워크로드 성능에 영향을 미치는 핵심 요소들을 규명한다. 우리는 이론적 분석 모델과 함께 Brainchip AKD1000, Synsense Speck, Intel Loihi 2 등 세 가지 실제 신경형 가속기에 대한 광범위한 실험을 수행하였다. 실험 결과, 메모리‑제한, 연산‑제한, 트래픽‑제한이라는 세 가지 뚜렷한 병목 상태를 정의하고, 각 워크로드 구성 특성이 어느 병목 상태에 해당하는지를 식별한다. 이러한 통찰을 종합해 ‘플로어라인 성능 모델’이라는 시각적 도구를 만들었으며, 이는 워크로드가 모델 상에서 차지하는 위치에 따라 성능 한계를 파악하고 최적화 방향을 제시한다. 마지막으로, 희소성 인식 학습과 플로어라인 기반 파티셔닝을 결합한 최적화 방법론을 제시한다. 이 방법은 동일 정확도 조건에서 기존 수동 튜닝 대비 최대 3.86배의 실행 시간 단축과 3.38배의 에너지 감소를 달성한다. 본 연구는 신경형 가속기의 시스템 수준 최적화 기반을 마련하고, 건축적 인사이트와 체계적인 최적화 프레임워크를 제공함으로써 해당 아키텍처에 대한 원칙적인 성능 엔지니어링을 가능하게 한다.💡 논문 핵심 해설 (Deep Analysis)
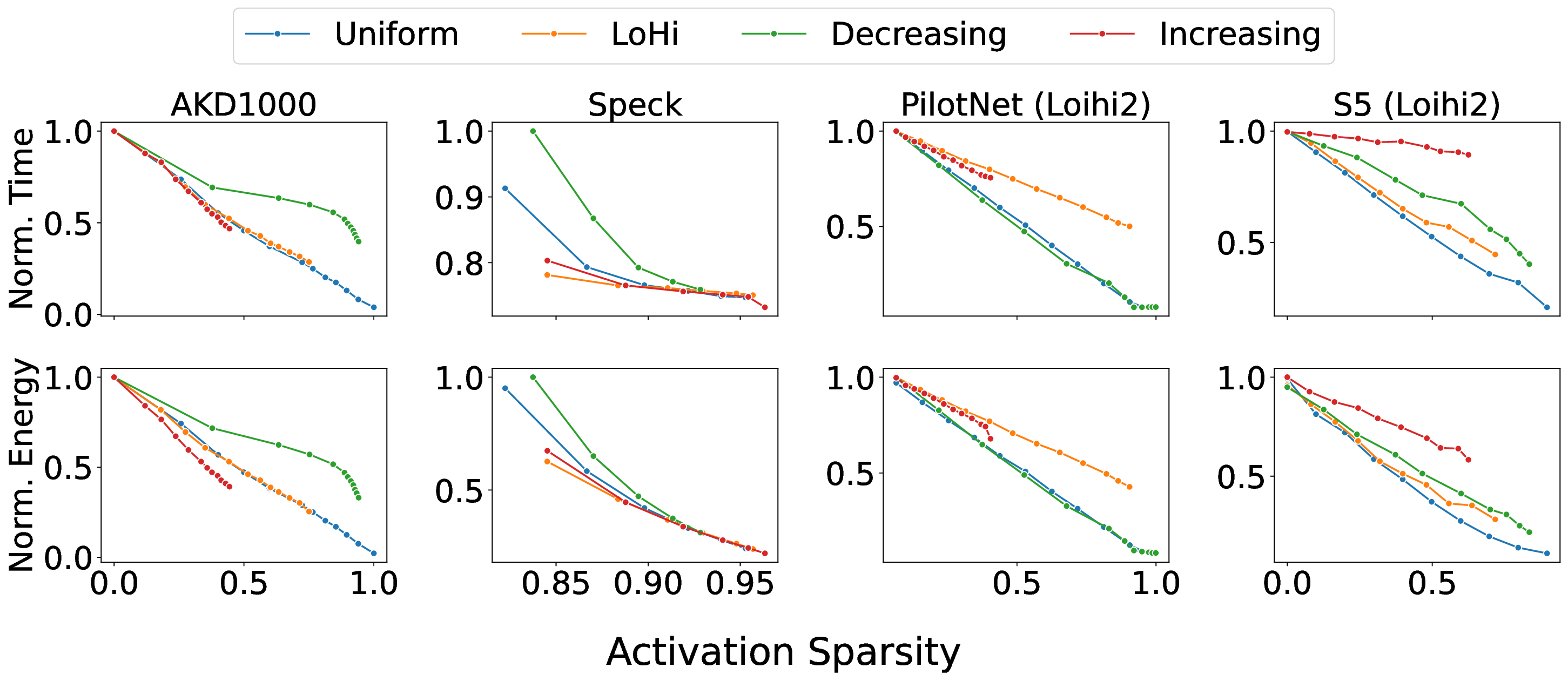
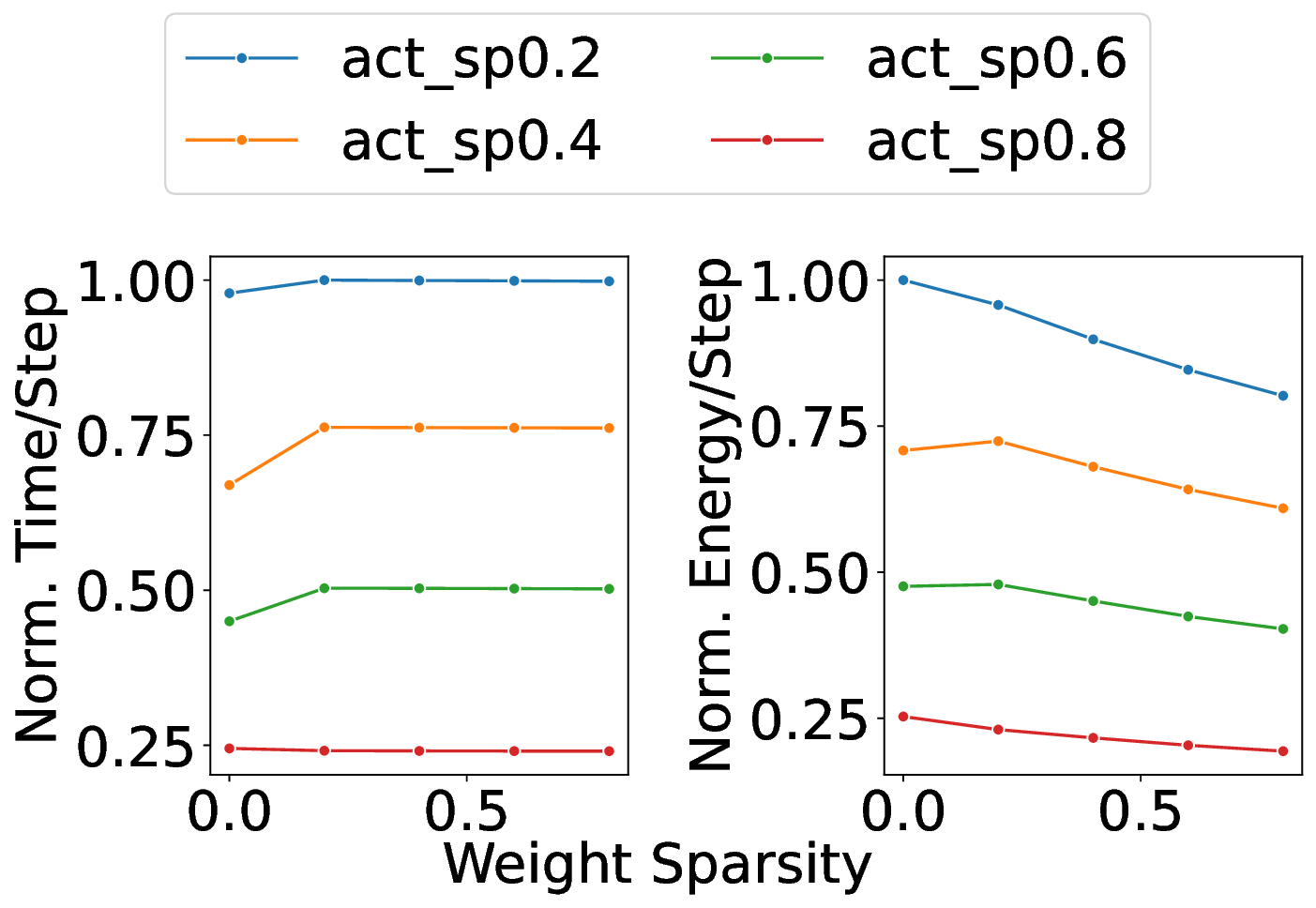
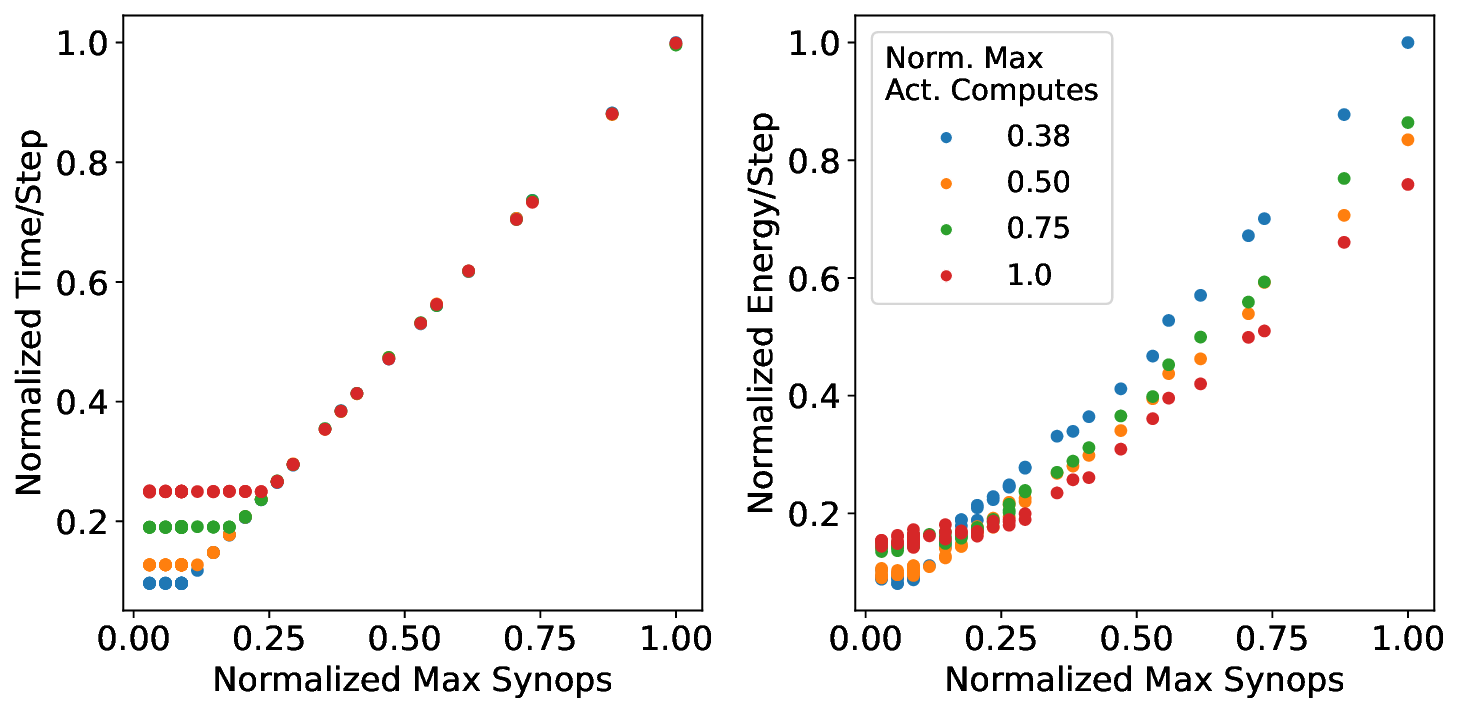
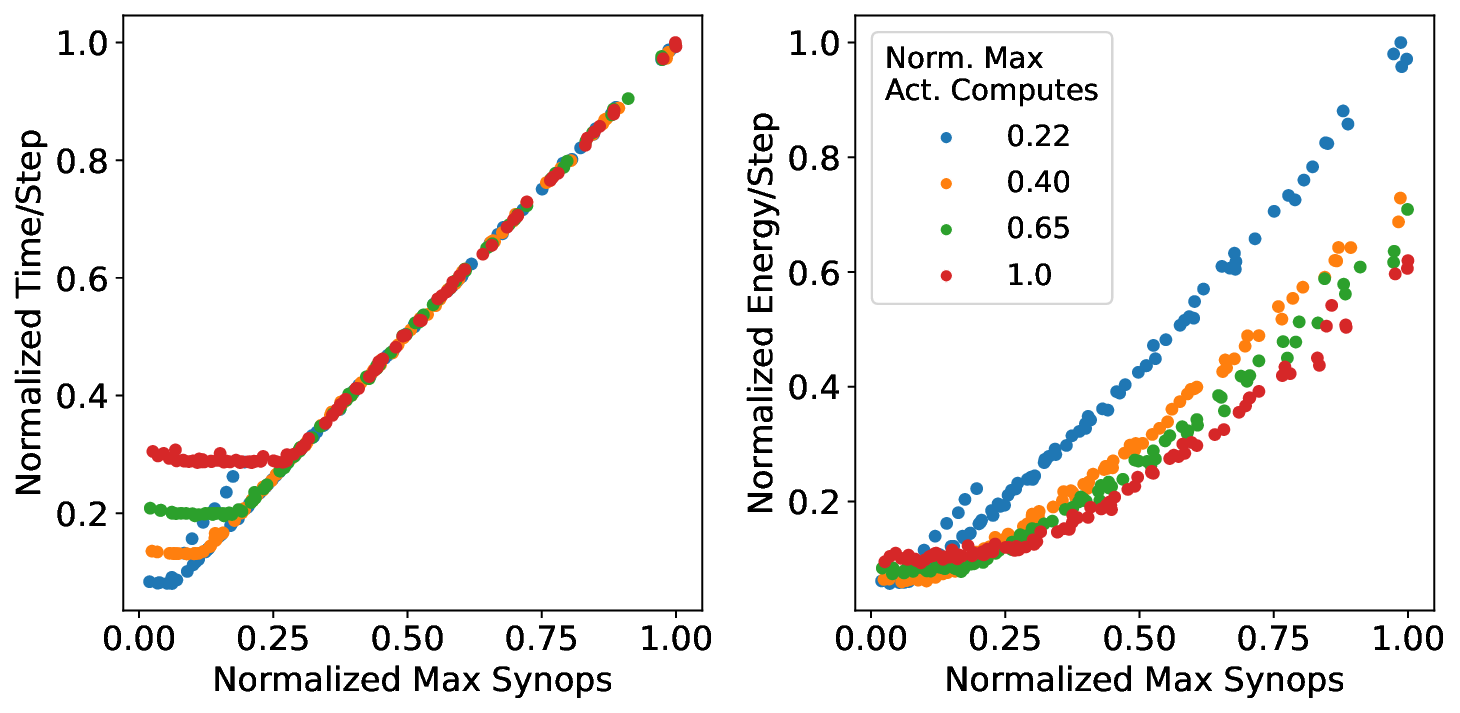
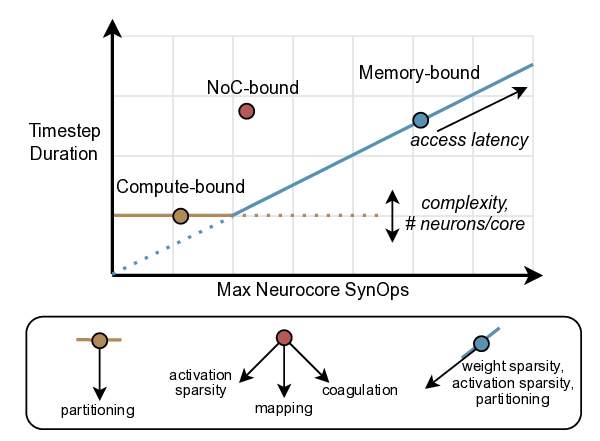
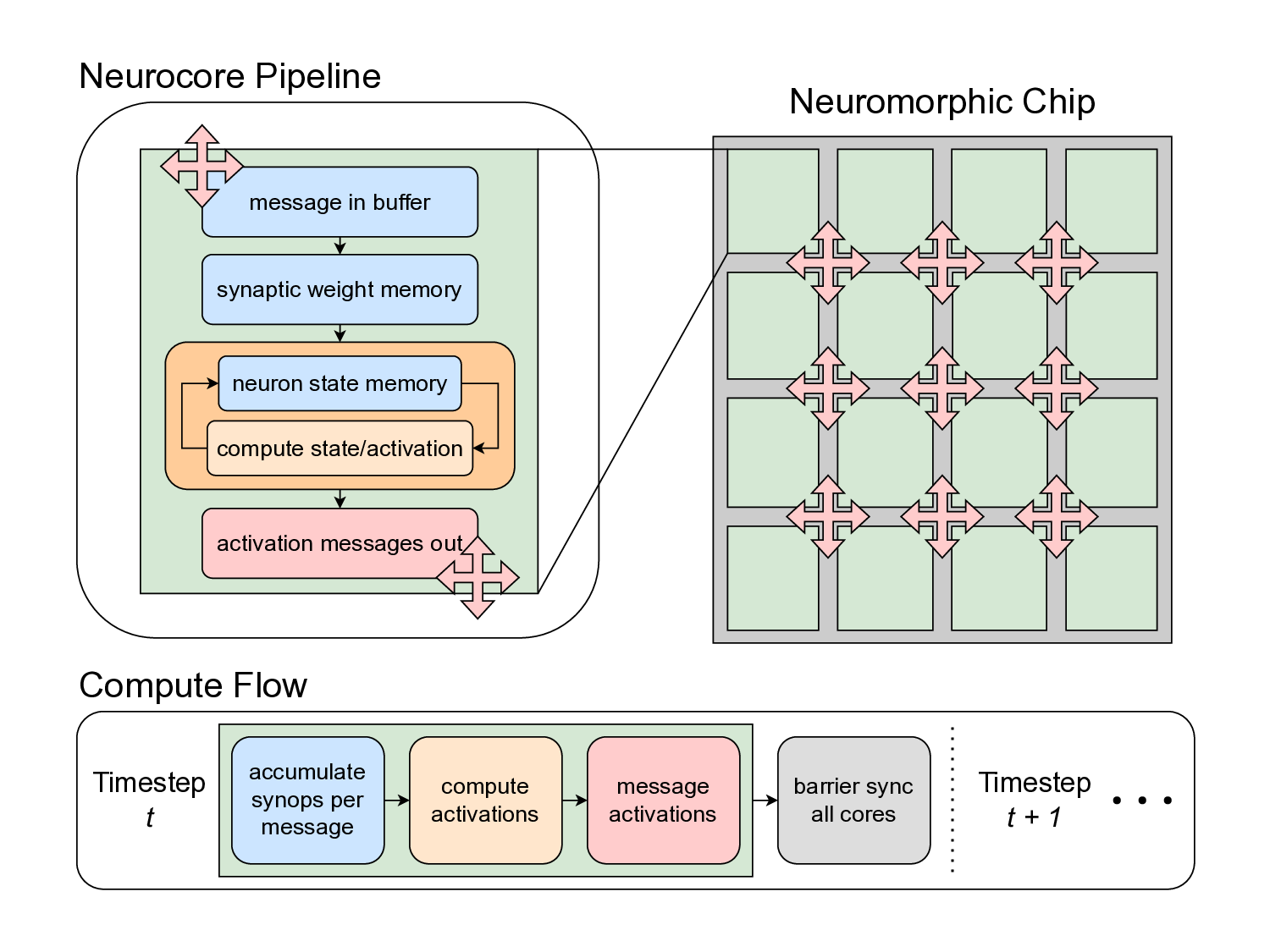
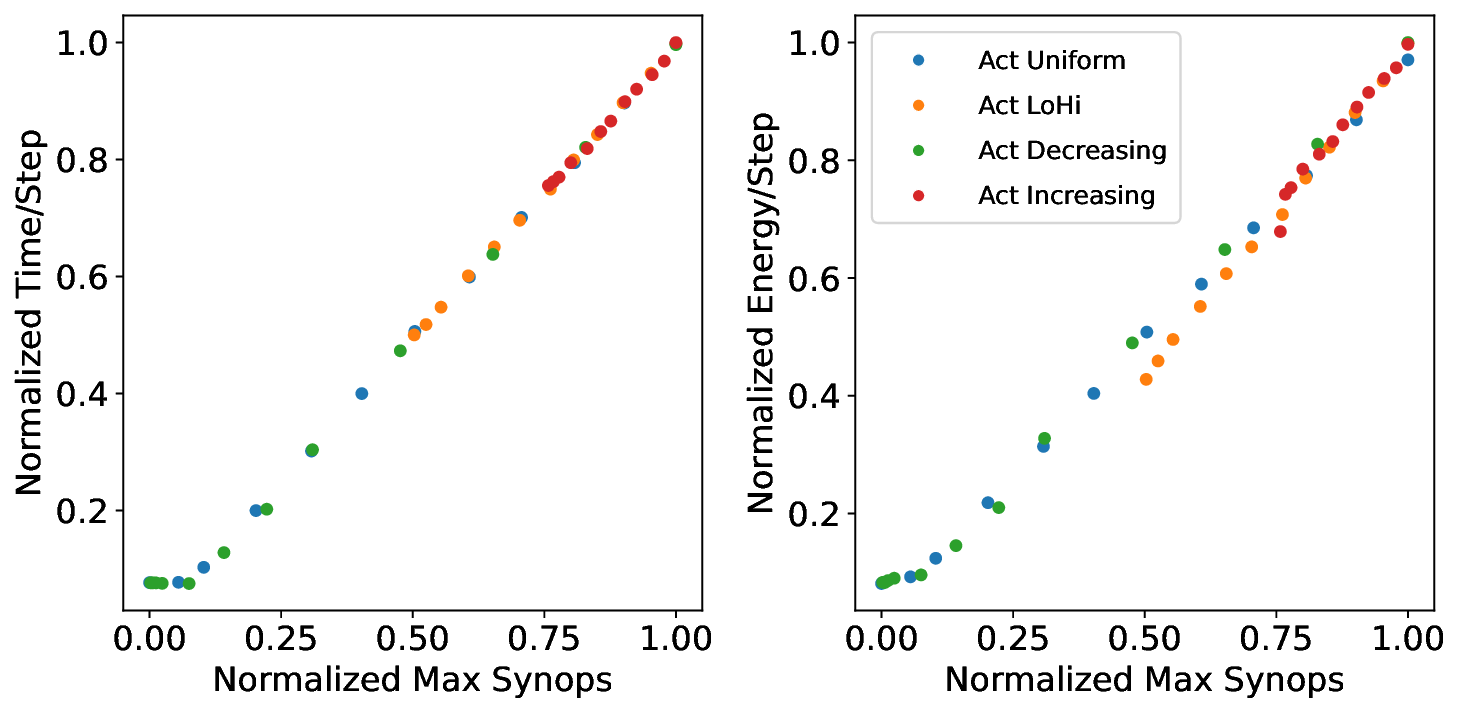
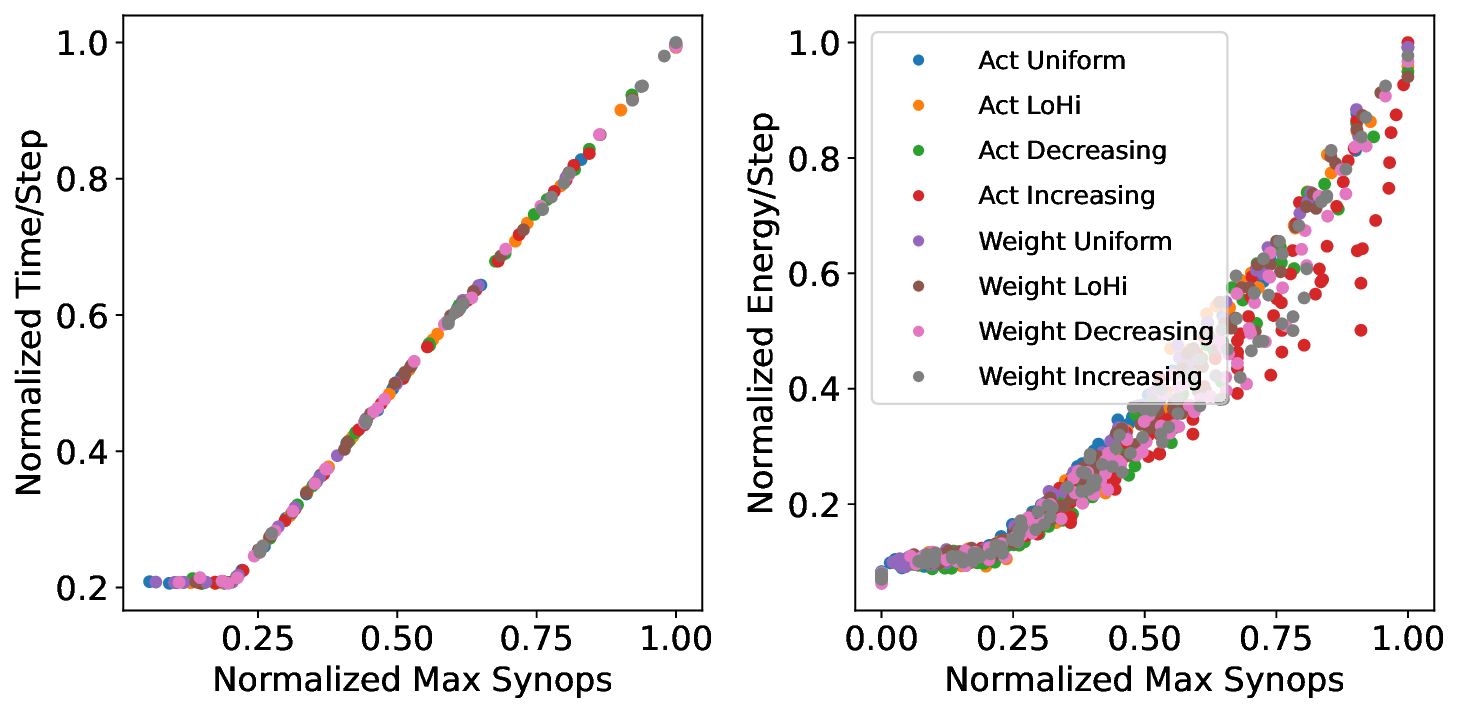
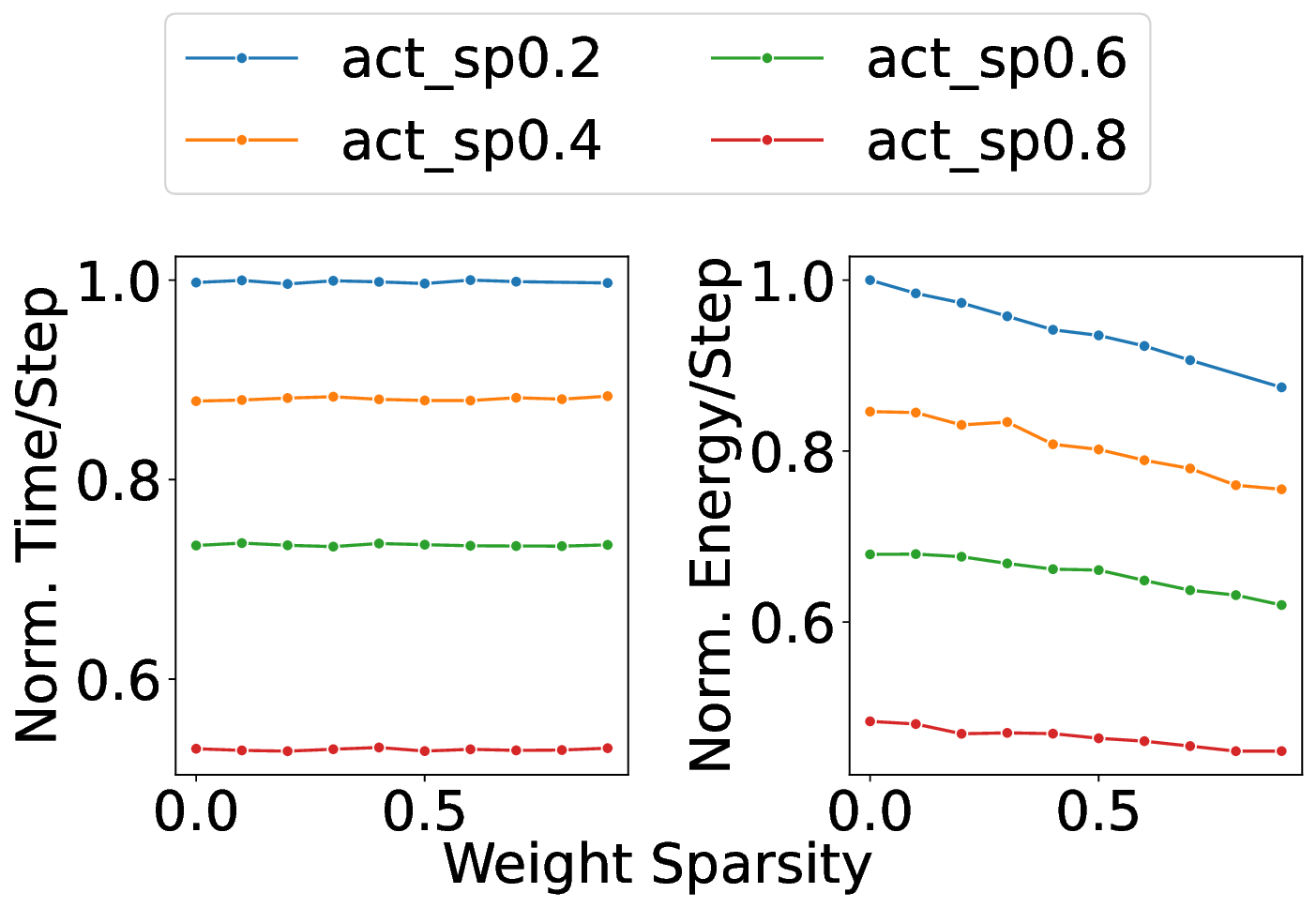
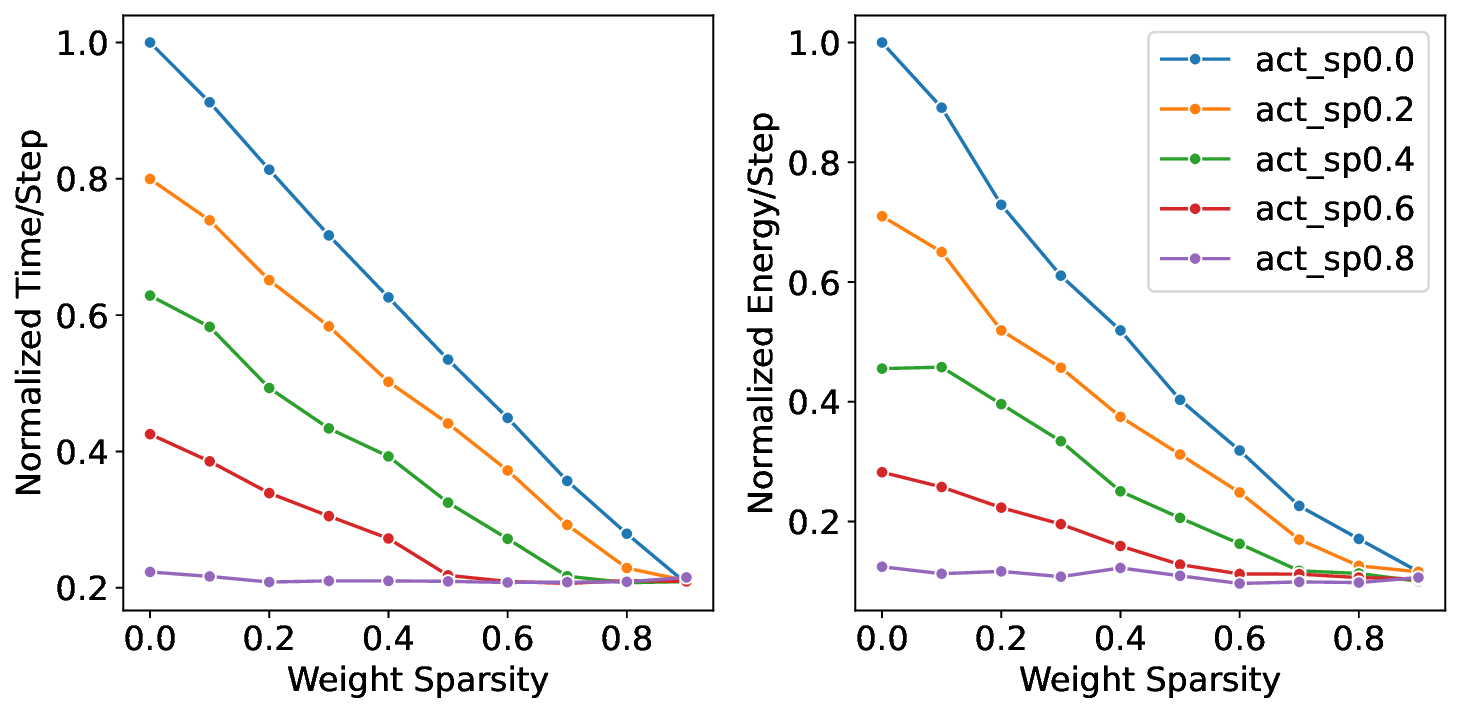
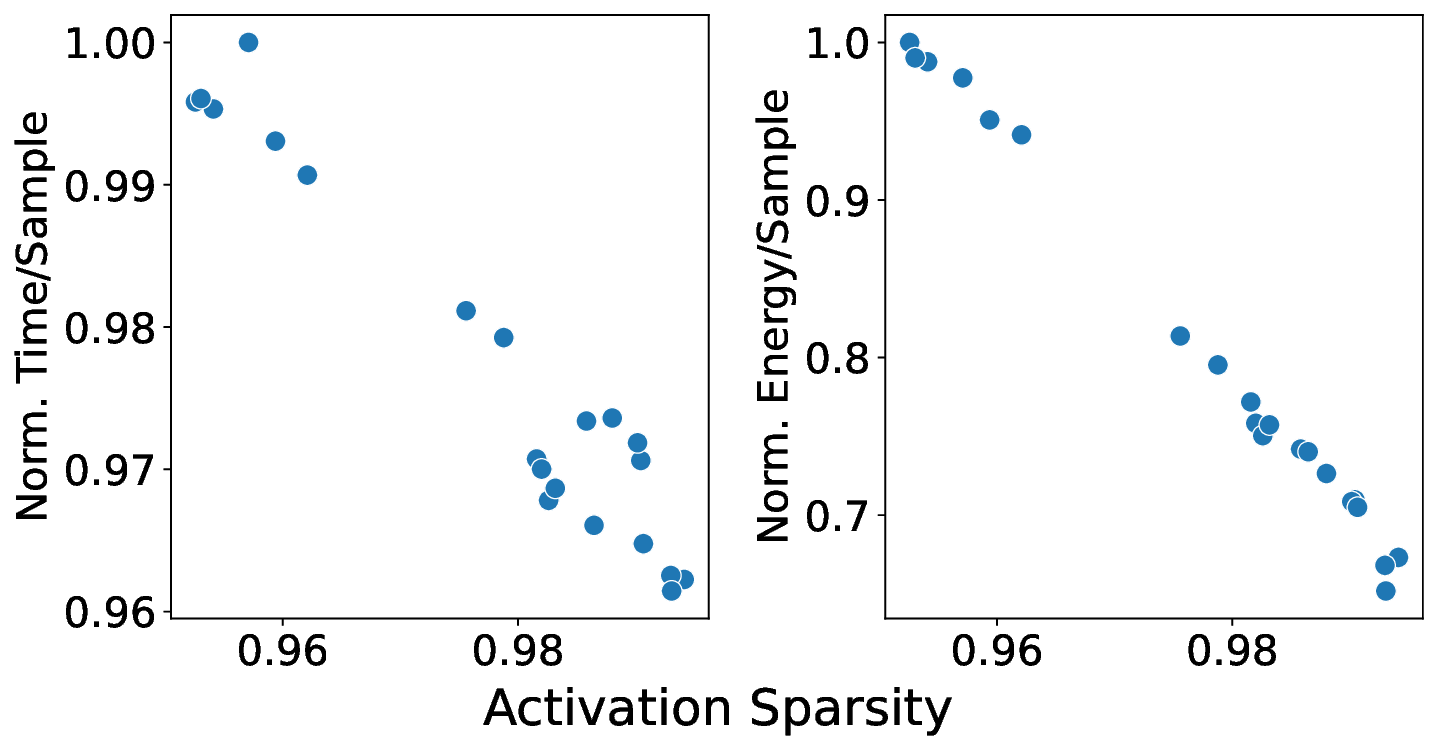
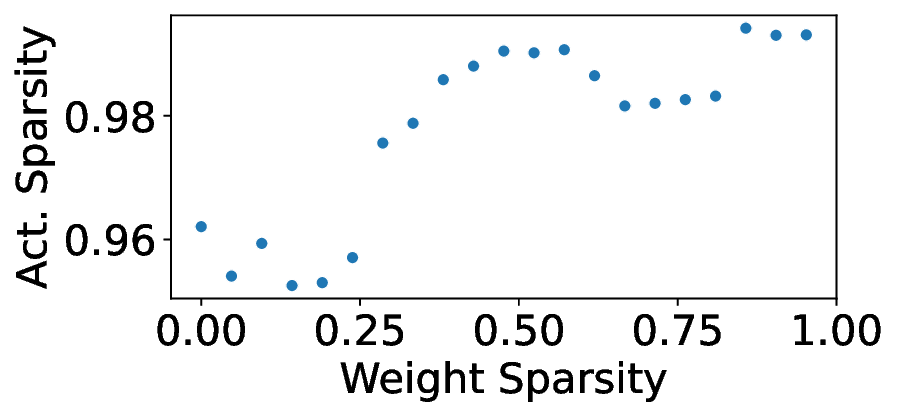
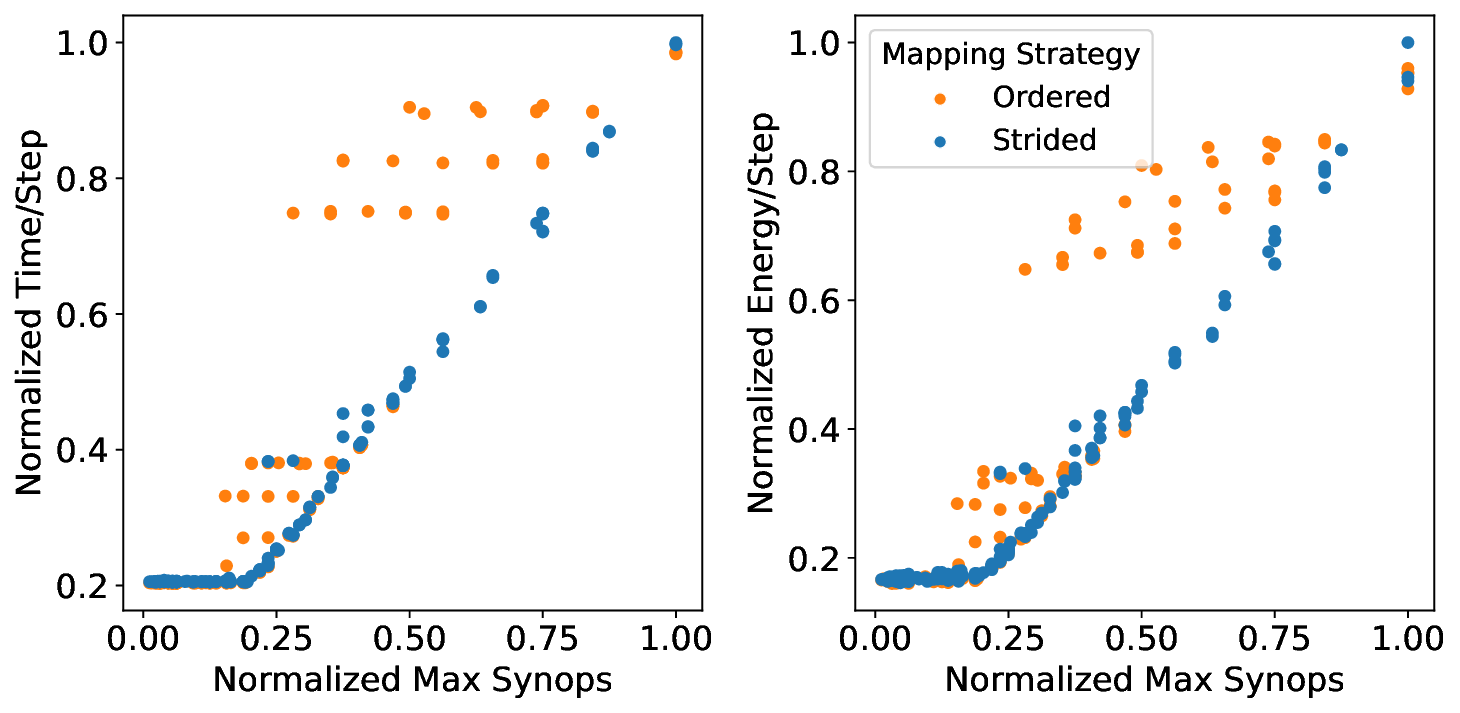
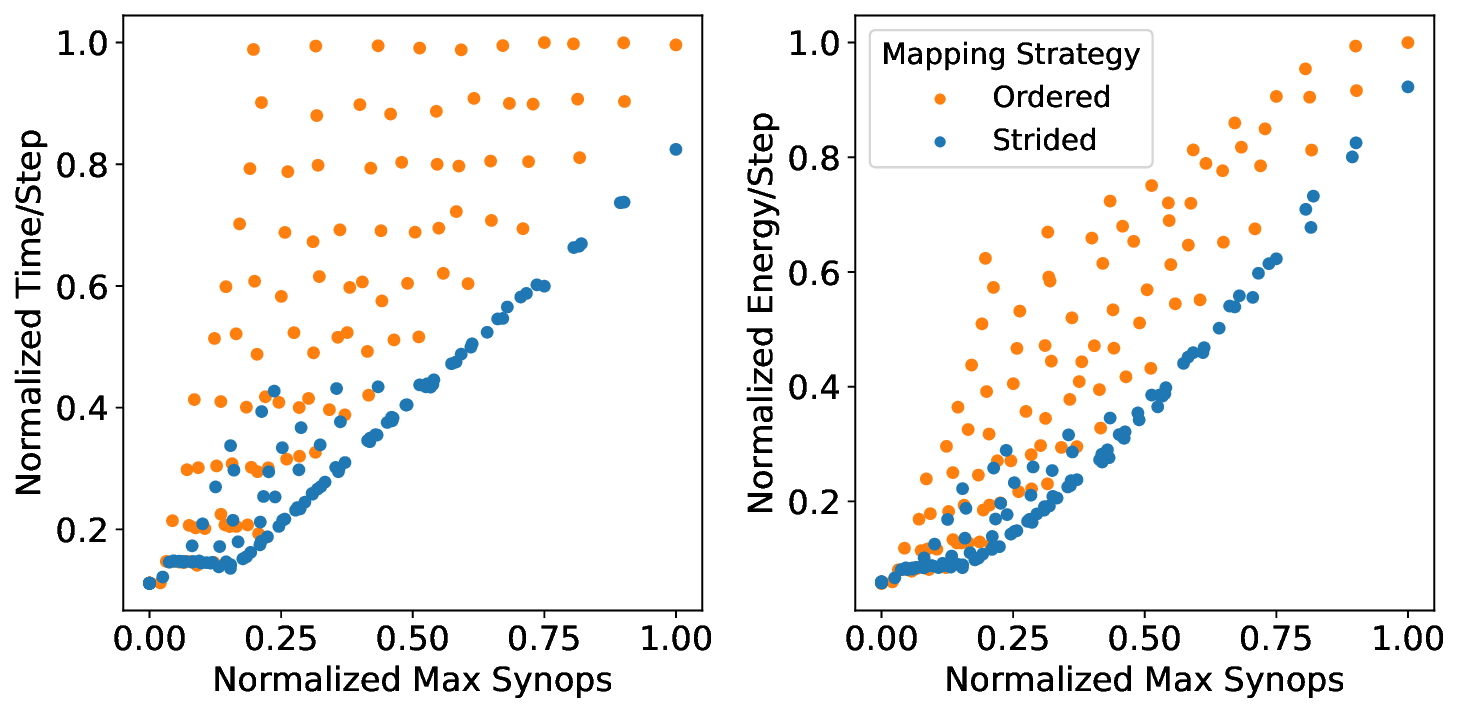
플로어라인 성능 모델은 이러한 병목을 시각적으로 한눈에 파악할 수 있게 해준다. 모델은 X축에 ‘연산 집약도’, Y축에 ‘메모리·통신 요구량’을 배치하고, 각 영역을 색으로 구분해 어느 구역에 워크로드가 위치하는지를 직관적으로 나타낸다. 이를 통해 설계자는 단순히 희소도를 높이는 것이 아니라, 목표 워크로드가 어느 병목에 머물고 있는지를 판단하고, 해당 병목을 해소하기 위한 구체적인 전략—예를 들어 시냅스 압축, 뉴런 파티셔닝, 혹은 통신 스케줄링—을 선택할 수 있다.
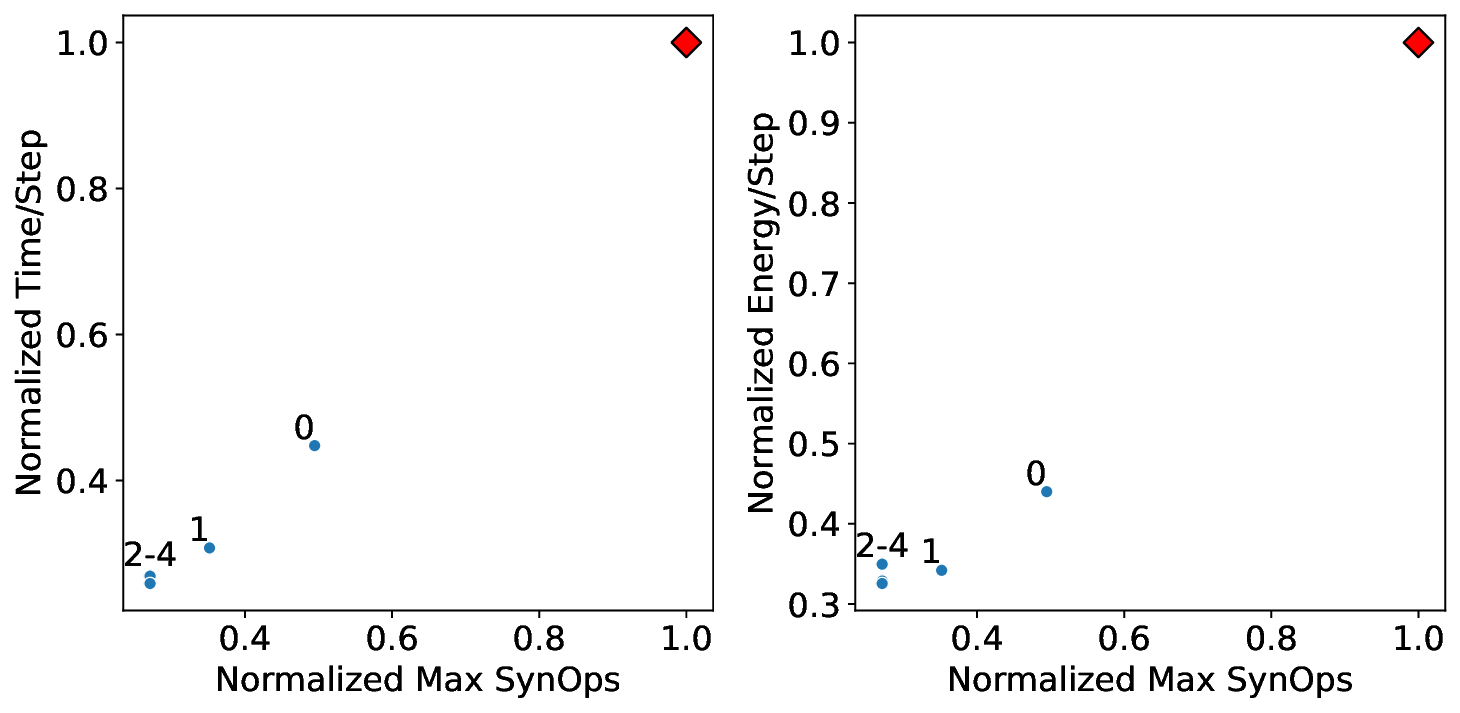
또한 논문은 희소성 인식 학습(sparsity‑aware training)과 플로어라인 기반 파티셔닝을 결합한 최적화 파이프라인을 제시한다. 학습 단계에서 불필요한 스파이크를 사전에 억제하고, 실행 단계에서는 메모리·연산·통신 자원을 균형 있게 배분함으로써 3.86배의 실행 시간 단축과 3.38배의 에너지 절감을 달성했다. 이는 단순히 하드웨어 매개변수를 조정하는 수준을 넘어, 알고리즘‑하드웨어 공동 설계(co‑design)의 가능성을 입증한다. 다만, 현재 연구는 세 가지 상용 칩에 국한되어 있어, 차세대 대규모 신경형 시스템이나 비정형 토폴로지에 대한 일반화 가능성은 추가 검증이 필요하다. 향후 연구에서는 다양한 네트워크 구조, 멀티칩 인터커넥트, 그리고 실시간 학습 시나리오까지 확장함으로써 플로어라인 모델의 적용 범위를 넓히는 것이 과제로 남는다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리