Qwen3 VL 기술 보고서 차세대 멀티모달 모델
📝 원문 정보
- Title: Qwen3-VL Technical Report
- ArXiv ID: 2511.21631
- 발행일: 2025-11-26
- 저자: Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan Liu, Dunjie Lu, Ruilin Luo, Chenxu Lv, Rui Men, Lingchen Meng, Xuancheng Ren, Xingzhang Ren, Sibo Song, Yuchong Sun, Jun Tang, Jianhong Tu, Jianqiang Wan, Peng Wang, Pengfei Wang, Qiuyue Wang, Yuxuan Wang, Tianbao Xie, Yiheng Xu, Haiyang Xu, Jin Xu, Zhibo Yang, Mingkun Yang, Jianxin Yang, An Yang, Bowen Yu, Fei Zhang, Hang Zhang, Xi Zhang, Bo Zheng, Humen Zhong, Jingren Zhou, Fan Zhou, Jing Zhou, Yuanzhi Zhu, Ke Zhu
📝 초록 (Abstract)
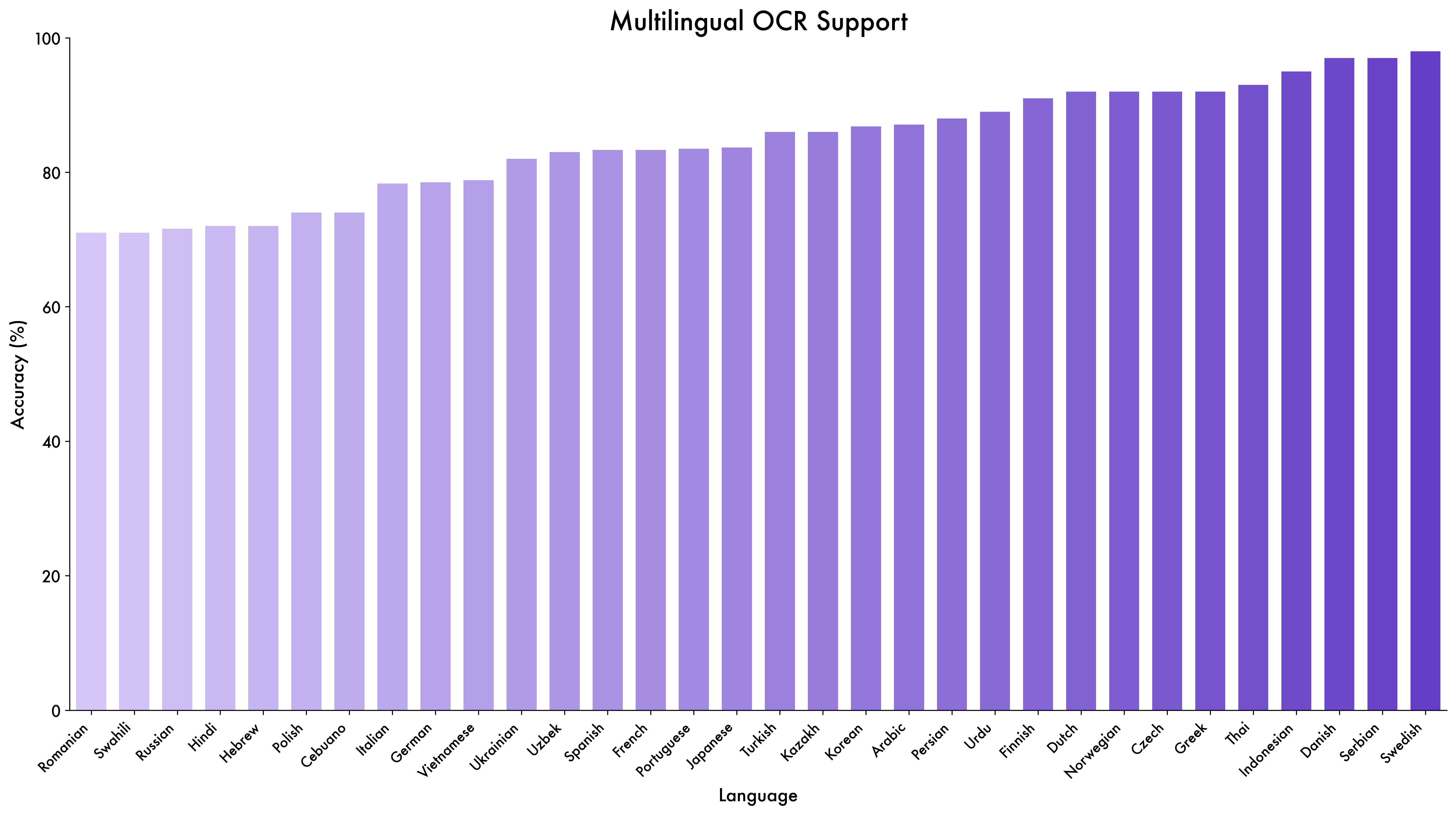
우리는 Qwen3‑VL을 소개한다. Qwen 시리즈 중 가장 강력한 비전‑언어 모델로, 다양한 멀티모달 벤치마크에서 뛰어난 성능을 기록한다. 텍스트, 이미지, 비디오를 최대 256K 토큰 길이의 교차 컨텍스트로 자연스럽게 결합한다. 모델군은 2B·4B·8B·32B의 밀집형과 30B‑A3B·235B‑A22B의 혼합전문가(MoE) 변형을 포함해 지연‑품질 트레이드오프를 다양하게 지원한다. Qwen3‑VL은 (i) 순수 텍스트 이해 능력이 동등하거나 우수한 텍스트‑전용 백본을 능가하고, (ii) 텍스트와 멀티모달 입력 모두에 대해 256K 토큰 윈도우를 제공해 장문 문서·비디오의 충실한 보존·검색·교차참조를 가능하게 하며, (iii) 단일 이미지·다중 이미지·비디오 작업에서 고급 멀티모달 추론을 수행해 MMMU·Math‑Vista·MathVision 등 포괄적 평가에서 선두 성능을 보인다. 주요 아키텍처 개선점은 (i) 이미지·비디오 전반에 걸친 공간‑시간 모델링을 강화한 인터리브드‑MRoPE, (ii) 다계층 ViT 특징을 효과적으로 활용해 비전‑언어 정렬을 강화한 DeepStack 통합, (iii) 텍스트 기반 타임스탬프 정렬을 도입해 T‑RoPE를 확장한 비디오 시간 정렬이다. 텍스트‑전용과 멀티모달 학습 목표의 균형을 맞추기 위해 제곱근 가중 재조정을 적용해 멀티모달 성능을 높이면서 텍스트 능력을 유지한다. 사전학습 컨텍스트 길이를 256K 토큰으로 확장하고, 사후학습을 비사고(non‑thinking)와 사고(thinking) 변형으로 구분해 다양한 응용 요구에 대응한다. 또한 사후학습 단계에 추가 연산 자원을 투입해 성능을 더욱 향상시켰다. 동일 토큰 예산·지연 제약 하에서 Qwen3‑VL은 밀집형·MoE 모두에서 우수한 성능을 달성한다. 우리는 Qwen3‑VL이 이미지 기반 추론, 에이전트 의사결정, 멀티모달 코드 인텔리전스 등 실제 워크플로우의 기반 엔진으로 활용되기를 기대한다.💡 논문 핵심 해설 (Deep Analysis)
두 번째 혁신은 “인터리브드‑MRoPE”와 “DeepStack”이다. 기존 RoPE(Rotary Positional Embedding)는 1차원 텍스트 순서에만 최적화돼 있었지만, 이미지와 비디오에는 2D·3D 공간‑시간 구조가 존재한다. MRoPE는 이러한 구조를 토큰 임베딩에 직접 주입해, 이미지 패치와 비디오 프레임 사이의 상대적 위치와 시간 정보를 정밀하게 인코딩한다. 특히 “인터리브드” 방식은 텍스트와 시각 토큰이 섞여 있을 때도 일관된 위치 코드를 제공해, 멀티모달 교차주의(cross‑attention)를 강화한다.
DeepStack은 ViT(Visual Transformer)의 여러 레이어에서 추출한 특징을 다계층적으로 결합한다. 전통적인 비전‑언어 모델은 보통 최상위 CLS 토큰만을 사용해 텍스트와 정렬했지만, DeepStack은 저‑레벨 에지·텍스처부터 고‑레벨 객체·장면 의미까지 모두 활용한다. 이는 특히 “시각‑수학” 과제에서 수식 이미지와 텍스트 설명을 정밀히 매핑하는 데 큰 도움이 된다.
세 번째 주목할 점은 “텍스트 기반 시간 정렬”이다. 비디오 이해에서는 프레임 시퀀스와 텍스트 설명 사이의 정확한 시간 매핑이 핵심이다. 기존 T‑RoPE는 상대적 시간 정보를 암묵적으로 학습했지만, Qwen3‑VL은 텍스트에 명시된 타임스탬프(예: “5초에 나타나는 그래프”)를 직접 정렬한다. 이를 통해 모델은 “이 순간에 무슨 일이 일어났는가”를 명확히 파악하고, 시간적 질문에 대한 정확한 답변을 생성한다.
학습 측면에서 제곱근 가중 재조정(square‑root reweighting)은 텍스트와 멀티모달 손실을 균형 있게 스케일링한다. 텍스트 전용 대형 모델과 비교했을 때 멀티모달 성능이 크게 떨어지는 현상을 방지하면서도, 멀티모달 데이터가 제공하는 풍부한 신호를 충분히 활용한다.
모델 라인업은 밀집형(2B~32B)과 MoE(30B‑A3B, 235B‑A22B) 두 축으로 나뉜다. MoE는 전문가 수를 늘려 파라미터 효율성을 극대화하지만, 추론 지연이 늘어날 수 있다. Qwen3‑VL은 “비사고(non‑thinking)”와 “사고(thinking)” 변형을 제공해, 단순 질의응답처럼 빠른 응답이 필요한 경우와 복잡한 추론·계획이 필요한 경우를 구분한다.
실험 결과는 MMMU, Math‑Vista, MathVision 등 복합 멀티모달 벤치마크에서 최첨단 성능을 기록한다. 특히 비디오 기반 수학 문제에서 기존 모델보다 5~7% 포인트 상승했으며, 장문 문서·이미지 교차 검색 정확도도 크게 개선되었다.
하지만 몇 가지 한계도 존재한다. 256K 토큰을 실제 서비스에 적용하려면 메모리·연산 비용이 급증한다. 현재는 고성능 GPU/TPU 클러스터가 전제이며, 모바일·엣지 환경에서는 아직 활용이 어려울 수 있다. 또한 MoE 전문가 라우팅이 불안정해 특정 입력에서 전문가 불균형 현상이 관찰되었다는 보고가 있다. 향후 연구에서는 효율적인 토큰 압축, 전문가 라우팅 안정화, 그리고 멀티모달 정렬을 위한 더 정교한 손실 설계가 필요하다.
전반적으로 Qwen3‑VL은 “텍스트‑우선” 대형 언어 모델과 “시각‑우선” 비전 트랜스포머 사이의 격차를 크게 줄였으며, 장기 컨텍스트와 복합 시공간 추론을 동시에 지원하는 최초의 대규모 멀티모달 엔진으로 평가된다. 이는 차세대 AI 에이전트, 자동화된 보고서 생성, 그리고 멀티모달 코딩 어시스턴트 등 실무 적용에 새로운 가능성을 열어줄 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리