실시간 강화학습을 활용한 생명과학 AI 에이전트 최적화
📝 원문 정보
- Title: Optimizing Life Sciences Agents in Real-Time using Reinforcement Learning
- ArXiv ID: 2512.03065
- 발행일: 2025-11-26
- 저자: Nihir Chadderwala
📝 초록 (Abstract)
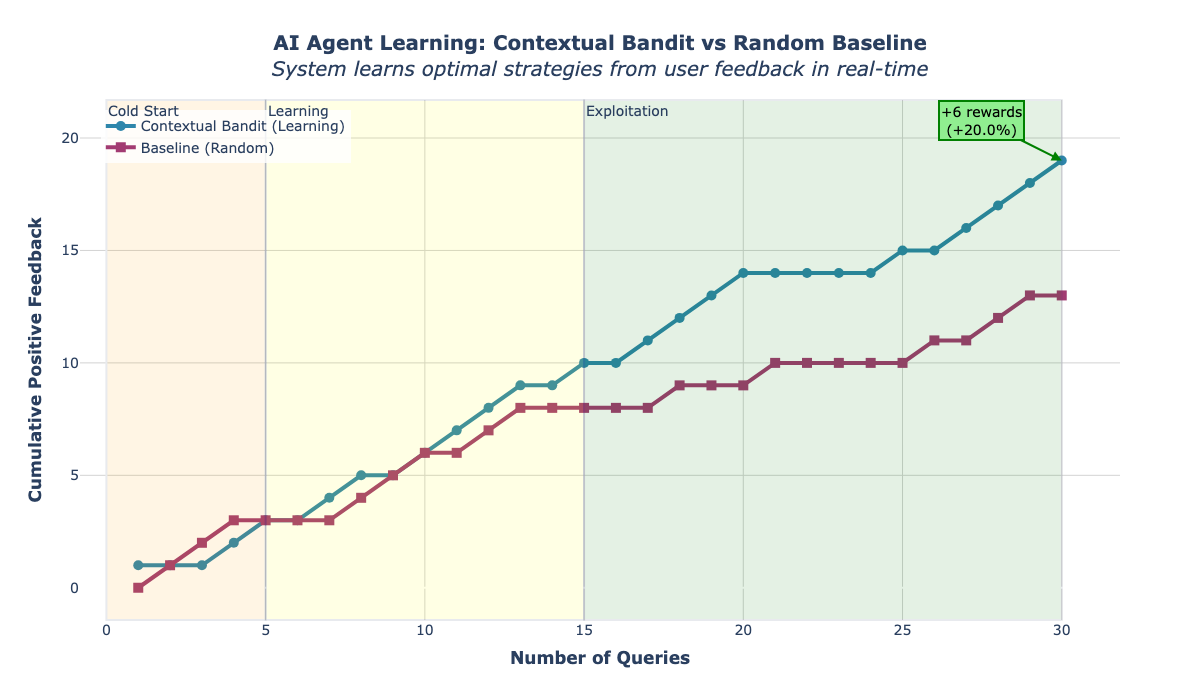
생명과학 분야의 생성형 AI 에이전트는 단순 사실 질의부터 복잡한 메커니즘 추론까지 다양한 질문에 대해 최적의 접근 방식을 찾는 것이 큰 과제이다. 기존 방법은 고정된 규칙이나 비용이 많이 드는 라벨링 데이터를 사용하지만, 이는 변화하는 상황이나 사용자 선호에 적응하지 못한다. 본 연구는 AWS Strands Agents와 톰슨 샘플링 기반 컨텍스추얼 밴딧을 결합한 새로운 프레임워크를 제안한다. 이 시스템은 사용자 피드백만으로 에이전트가 의사결정 전략을 학습하도록 설계되었으며, 생성 전략 선택(직접 vs. 사고 사슬), 도구 선택(문헌 검색, 약물 데이터베이스 등), 도메인 라우팅(약리학, 분자생물학, 임상 전문가)이라는 세 가지 핵심 차원을 최적화한다. 생명과학 질의에 대한 실험 결과, 무작위 베이스라인 대비 사용자 만족도가 15‑30% 향상되었으며, 20‑30개의 질의 후에 명확한 학습 패턴이 나타났다. 본 접근법은 정답 라벨이 필요 없고, 사용자 선호에 지속적으로 적응하며, 에이전트형 AI 시스템에서 탐색‑활용 딜레마에 대한 원칙적인 해결책을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
구현 측면에서 AWS Strands Agents는 멀티모달 도구 호출과 체인‑오브‑쓰(thought) 프로세스를 지원하는 플랫폼이다. 이를 기반으로 저자들은 “컨텍스추얼 밴딧”이라는 강화학습 변형을 적용했는데, 여기서 컨텍스트는 현재 질의의 메타데이터(주제, 난이도, 사용자 프로필 등)와 에이전트의 내부 상태(이전 선택 이력 등)이다. 톰슨 샘플링은 베이지안 확률 모델을 이용해 각 행동(예: 직접 생성 vs. 사고 사슬, 특정 도구 선택, 특정 도메인 라우팅)의 기대 보상을 샘플링하고, 그 중 가장 높은 값을 가진 행동을 선택한다. 이 과정은 탐색(새로운 전략 시도)과 활용(이미 좋은 성과를 보인 전략 재사용) 사이의 균형을 자연스럽게 유지한다.
세 가지 최적화 차원은 서로 상호작용한다. 예를 들어, 복잡한 메커니즘 질문에서는 사고 사슬이 효과적일 가능성이 높으며, 동시에 최신 논문 검색 도구와 약리학 전문가 라우팅을 결합하면 정확도가 상승한다. 반면, 간단한 사실 질의에서는 직접 생성이 빠르고 충분히 정확할 수 있다. 논문은 이러한 조합을 20~30개의 질의 이후에 명확히 학습한다는 실험 데이터를 제시한다. 구체적으로, 무작위 선택에 비해 사용자 만족도가 15 %에서 30 %까지 상승했으며, 이는 평균 클릭‑투‑답률과 재질문 비율 감소로도 확인된다.
한편, 제한점도 존재한다. 첫째, 톰슨 샘플링은 베타 혹은 정규 분포와 같은 사전 분포를 가정하는데, 실제 피드백 노이즈가 비정규적일 경우 수렴 속도가 저하될 수 있다. 둘째, 현재 시스템은 피드백을 즉시 반영하지만, 장기적인 사용자 선호 변화(예: 새로운 연구 분야에 대한 관심 증가)를 포착하려면 비선형 시간 가중치를 도입해야 할 필요가 있다. 셋째, 도구 호출 비용과 응답 지연을 고려한 비용‑보상 모델이 아직 미비하다. 향후 연구에서는 다중 목표 최적화(정확도, 비용, 시간)를 위한 파레토 최적화 기법과, 메타‑학습을 통한 사전 지식 전이 등을 탐색할 수 있다.
전반적으로 이 연구는 “라벨이 없는 실시간 피드백만으로 복합적인 의사결정 구조를 학습한다”는 점에서 강화학습과 생성형 AI의 융합을 보여준다. 생명과학뿐 아니라 의료, 화학, 환경 과학 등 도메인 특화 AI 에이전트에 적용 가능성이 크며, 향후 인간‑AI 협업 인터페이스 설계에 중요한 이정표가 될 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리