가상 주소 RDMA에서 메모리 페이지 폴트 처리 방안
📝 원문 정보
- Title: Handling of Memory Page Faults during Virtual-Address RDMA
- ArXiv ID: 2511.21018
- 발행일: 2025-11-26
- 저자: Antonis Psistakis
📝 초록 (Abstract)
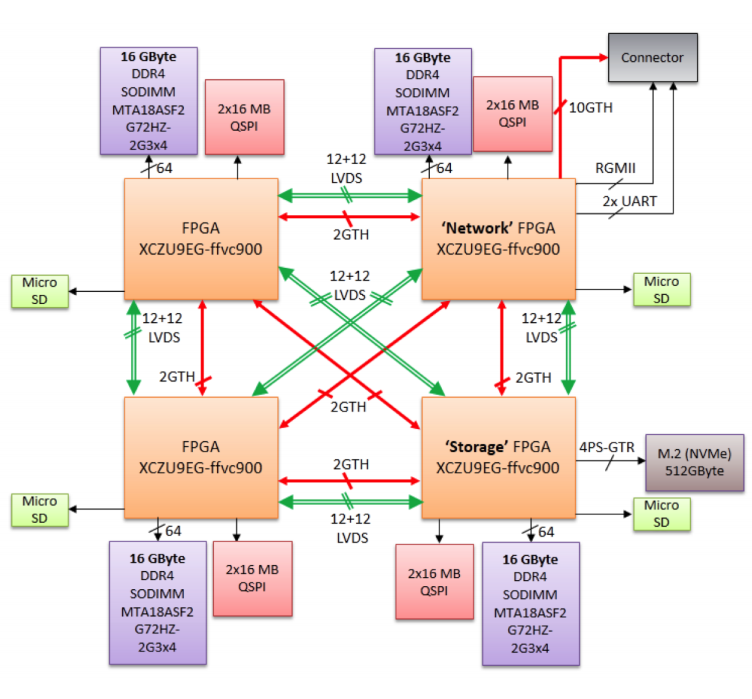
현대 고속 인터커넥트 네트워크에서는 시스템 콜을 최소화하고 커널‑유저 간 복사를 없애는 것이 성능과 에너지 효율을 높이는 핵심 과제이다. 사용자 수준 제로‑카피 RDMA 기술은 이러한 요구를 충족시키지만, 기존 RDMA 엔진은 페이지 폴트를 허용하지 않아 주소 공간 고정(pin)이나 다중 페이지 매핑과 같은 우회 방식을 사용한다. 그러나 고정은 프로그래밍 복잡성을 증가시키고, 고정 가능한 메모리 양에 제한을 두며, 투명 대용량 페이지(THP)와 같은 커널 최적화에 의해 여전히 폴트가 발생할 수 있다. 본 논문은 ExaNeSt 프로젝트의 DMA 엔진에 페이지 폴트 처리 메커니즘을 구현한다. ARM SMMU의 폴트 핸들러가 결함을 탐지하고, 하드웨어‑소프트웨어 연동으로 폴트를 해결한 뒤 필요 시 재전송을 요청한다. 이를 위해 SMMU 리눅스 드라이버 수정, 새로운 사용자 라이브러리, DMA 엔진 회로 변경, 스케줄러 조정이 수행되었다. 실험은 Zynq UltraScale+ MPSoC 기반 Quad‑FPGA Daughter Board에서 진행했으며, 고정 및 사전 폴트(pre‑fault) 방식과 비교해 메모리 활용도와 성능 면에서 장점을 입증하였다.💡 논문 핵심 해설 (Deep Analysis)
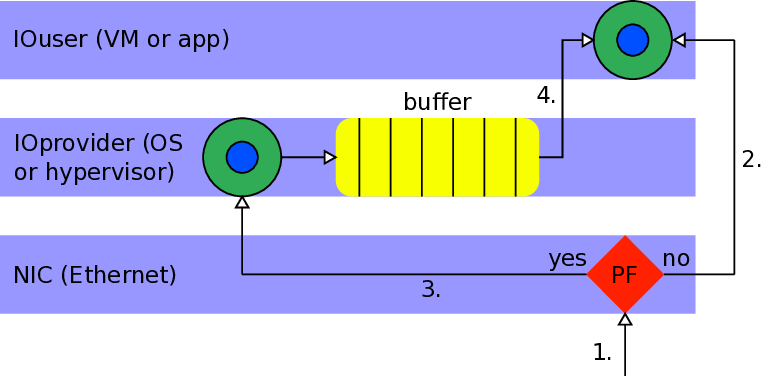
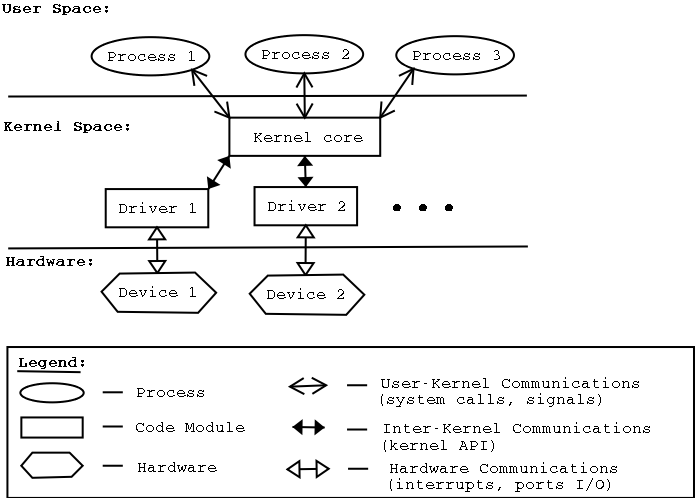
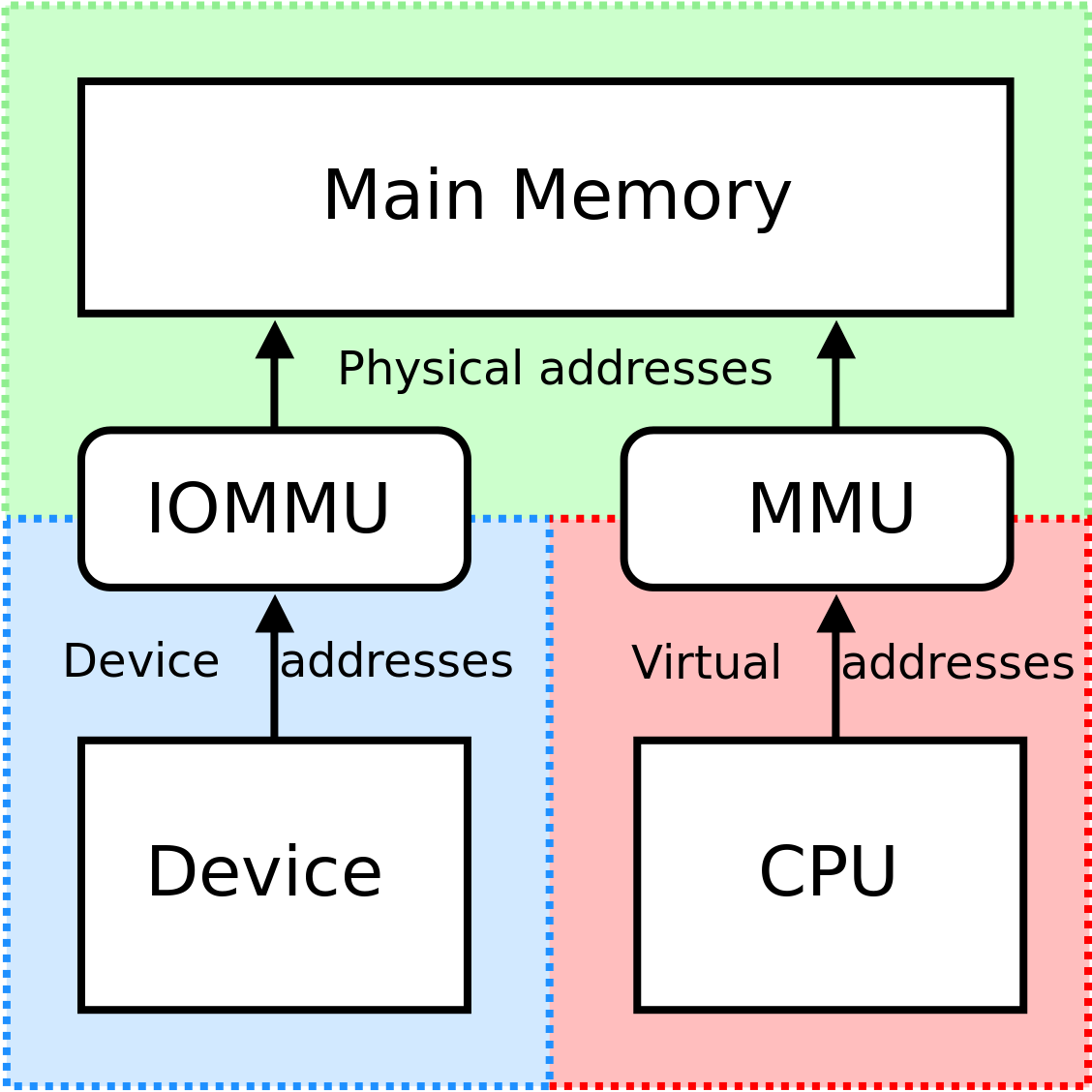
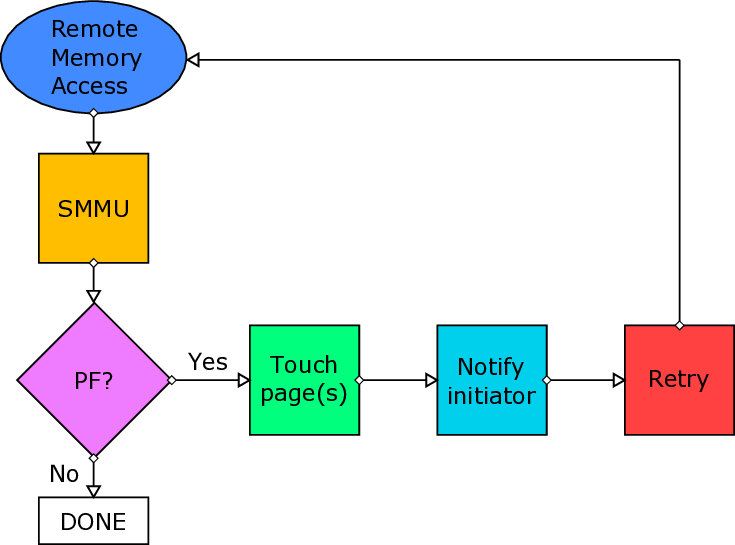
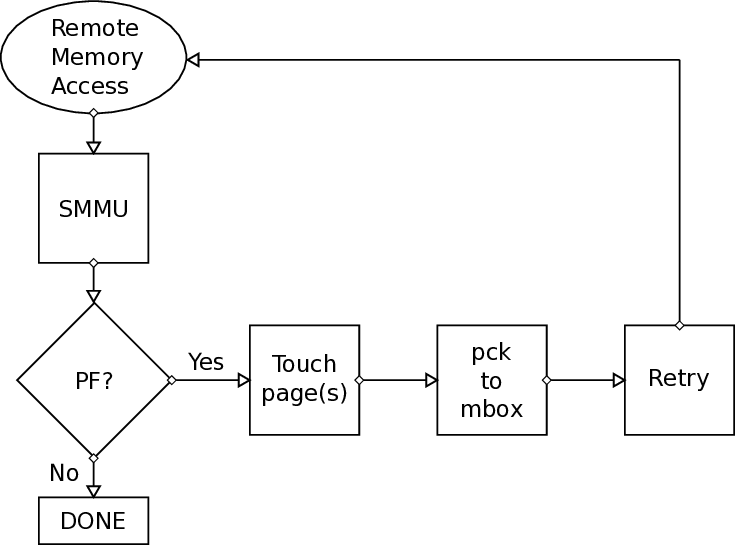
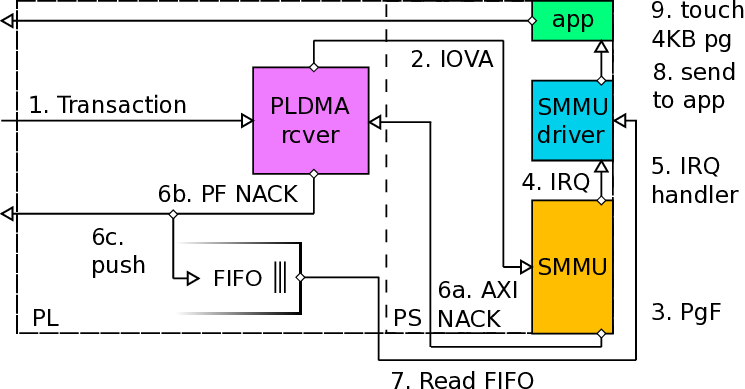
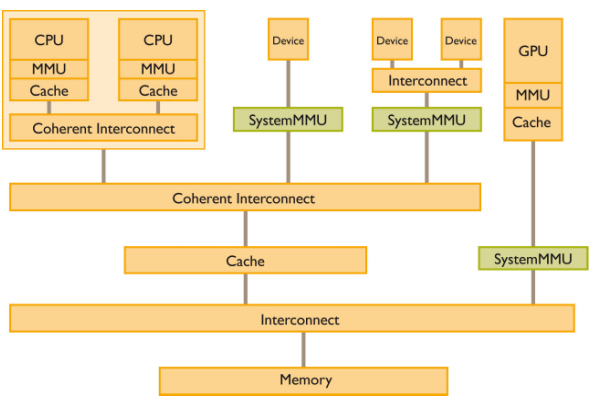
본 논문이 제시한 해결책은 ARM SMMU의 페이지 폴트 인터럽트를 활용한다는 점에서 혁신적이다. SMMU는 가상 주소와 물리 주소 사이의 매핑을 담당하는 IOMMU 역할을 수행하는데, 페이지가 매핑되지 않았을 때 자동으로 폴트 인터럽트를 발생시킨다. 저자들은 이 인터럽트를 가로채어 사용자 수준 라이브러리와 커널 드라이버가 협업하도록 설계하였다. 구체적으로, 폴트가 감지되면 드라이버는 해당 가상 페이지를 물리 페이지와 연결하고, DMA 엔진의 전송 큐를 일시 정지한다. 이후 재전송 요청을 통해 손실된 패킷을 다시 전송함으로써 데이터 일관성을 유지한다. 이 과정에서 DMA 엔진 자체에 페이지 매핑을 동적으로 업데이트할 수 있는 하드웨어 로직을 추가했으며, 스케줄러는 전송 재시도를 효율적으로 관리하도록 개조되었다.
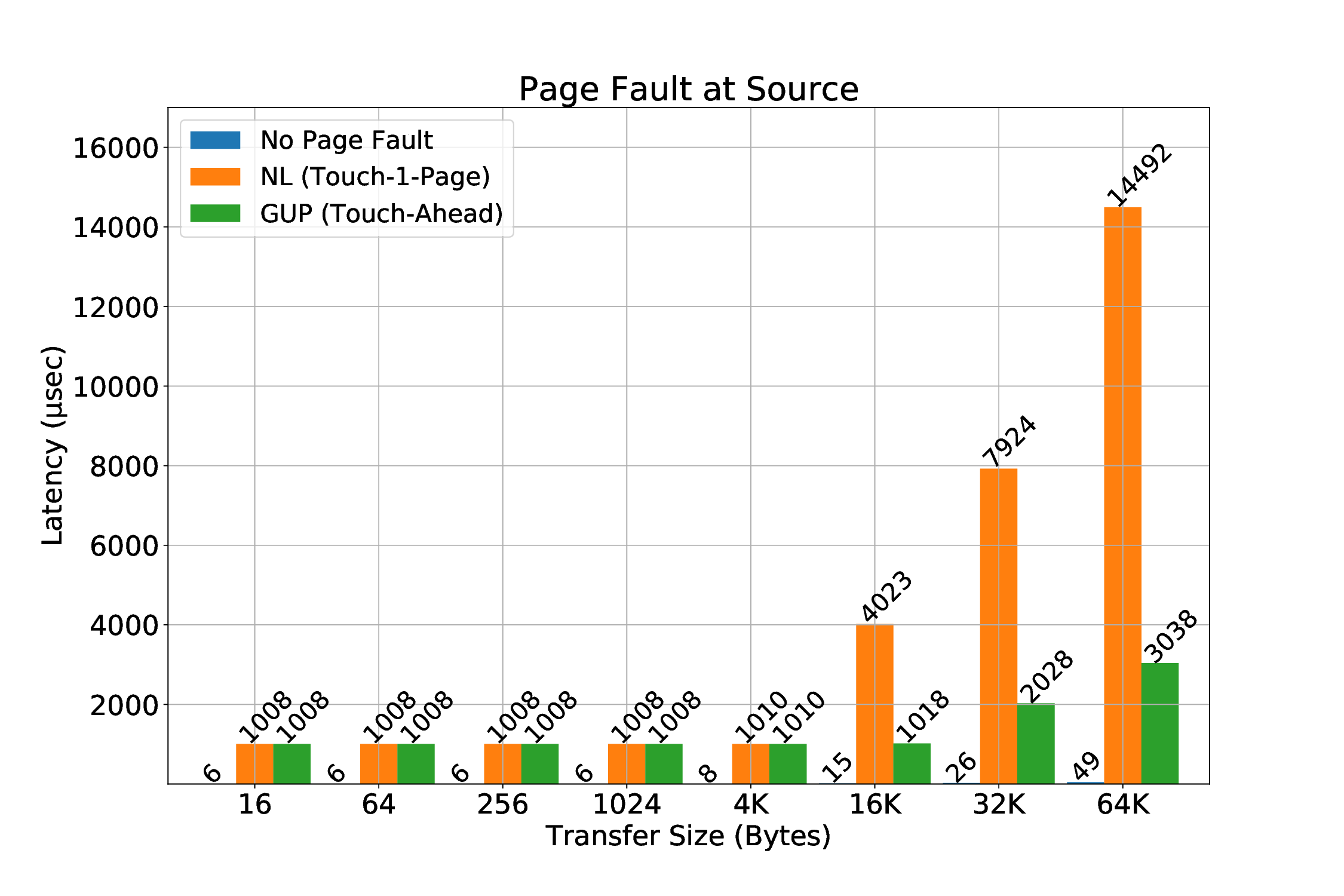
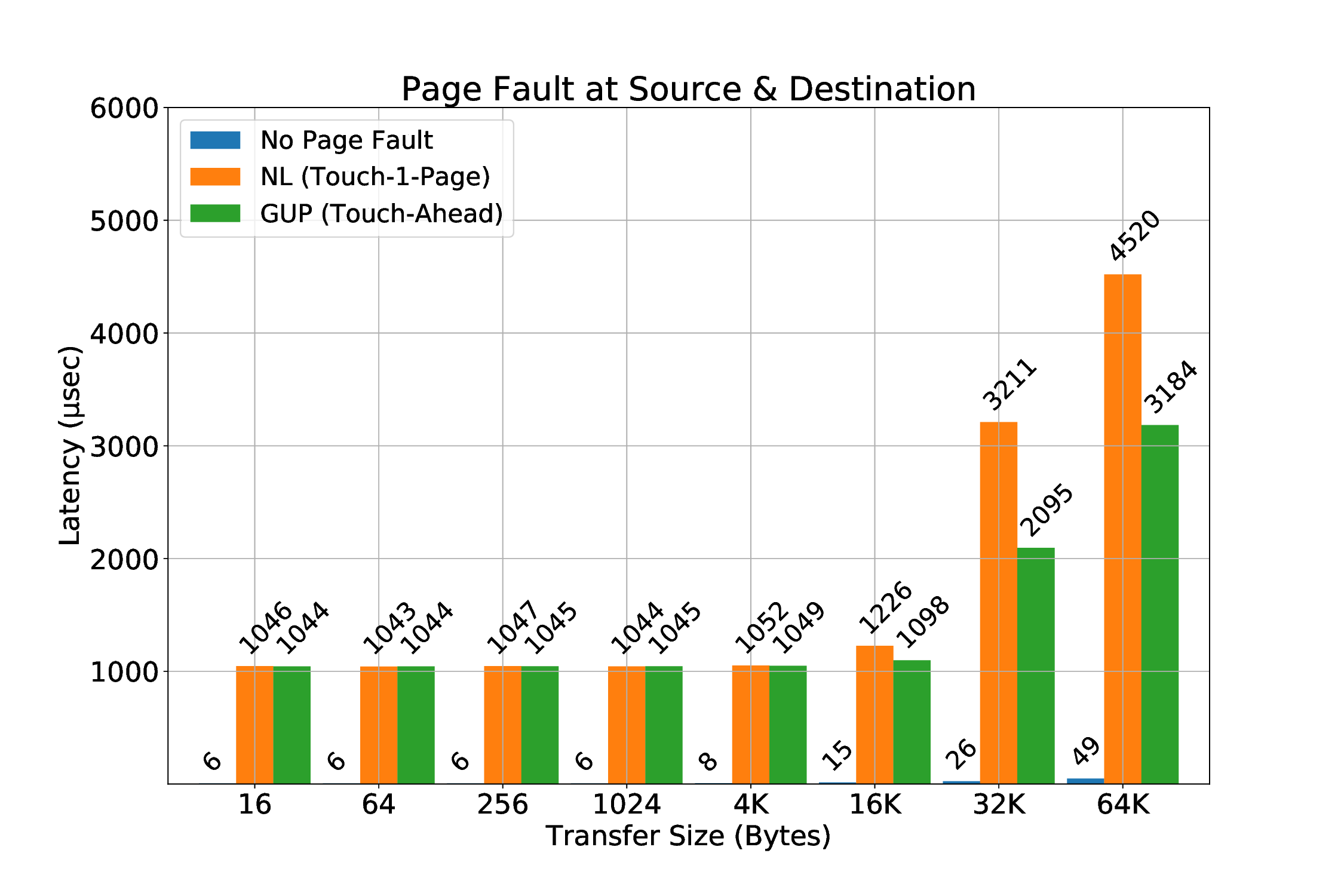
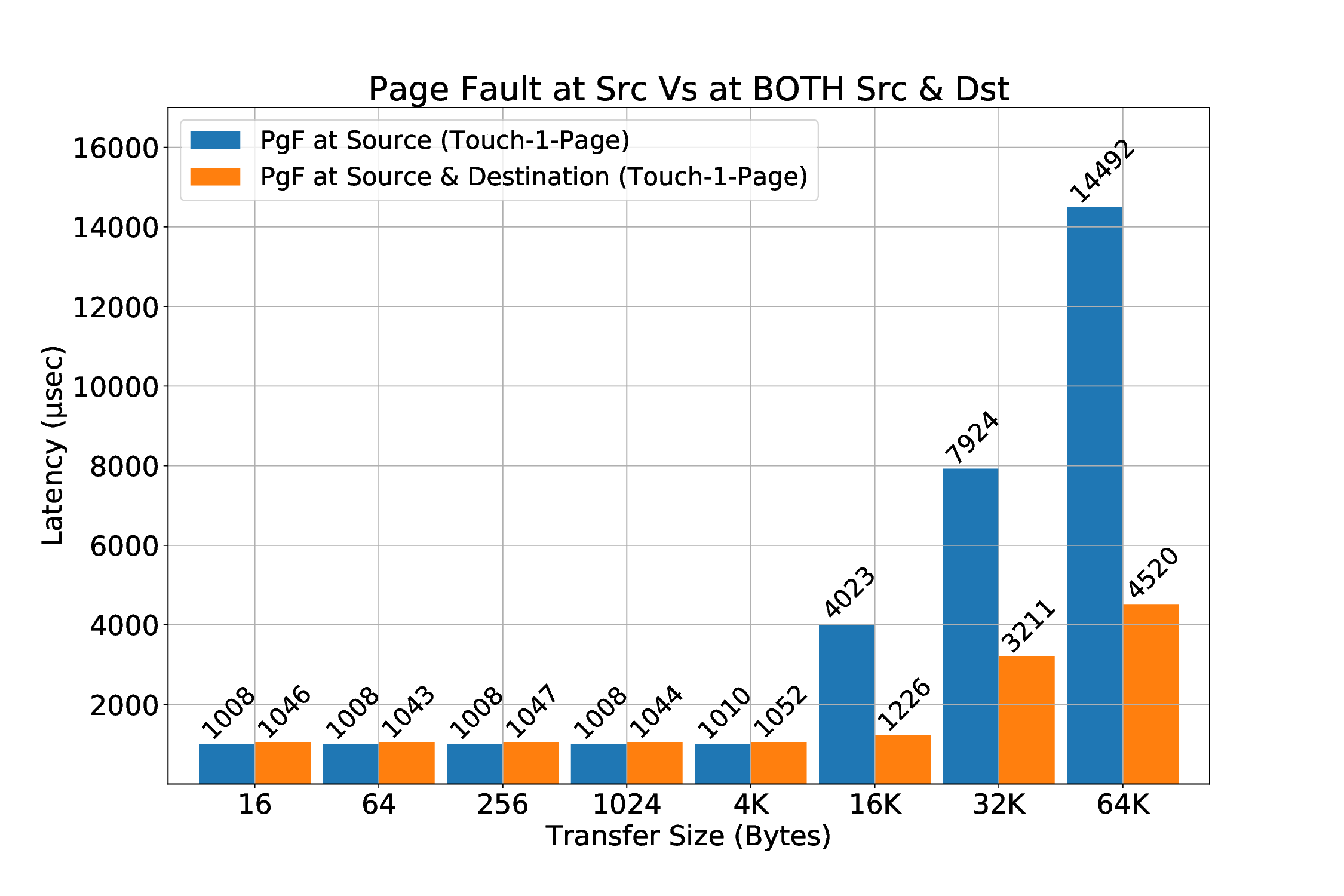
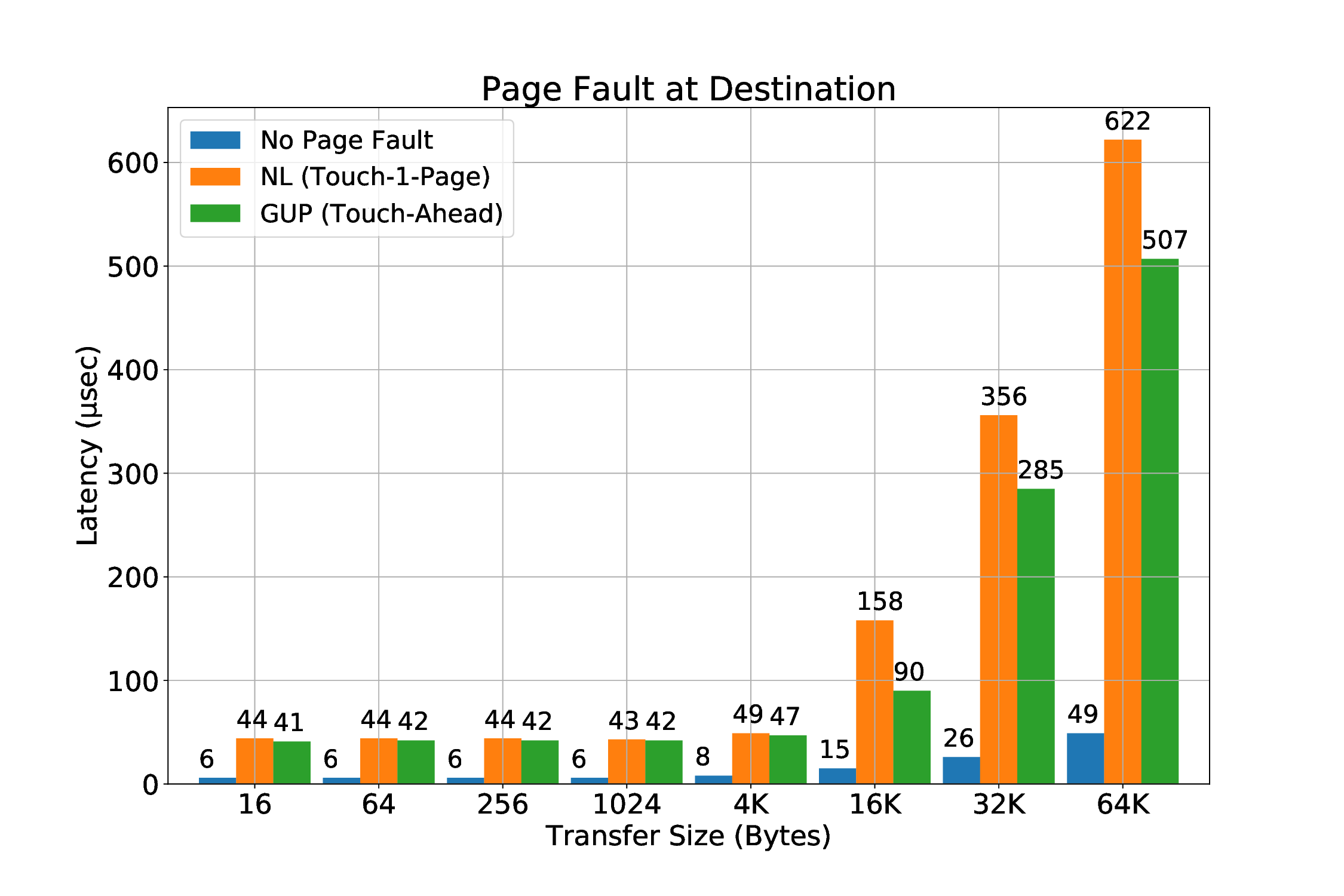
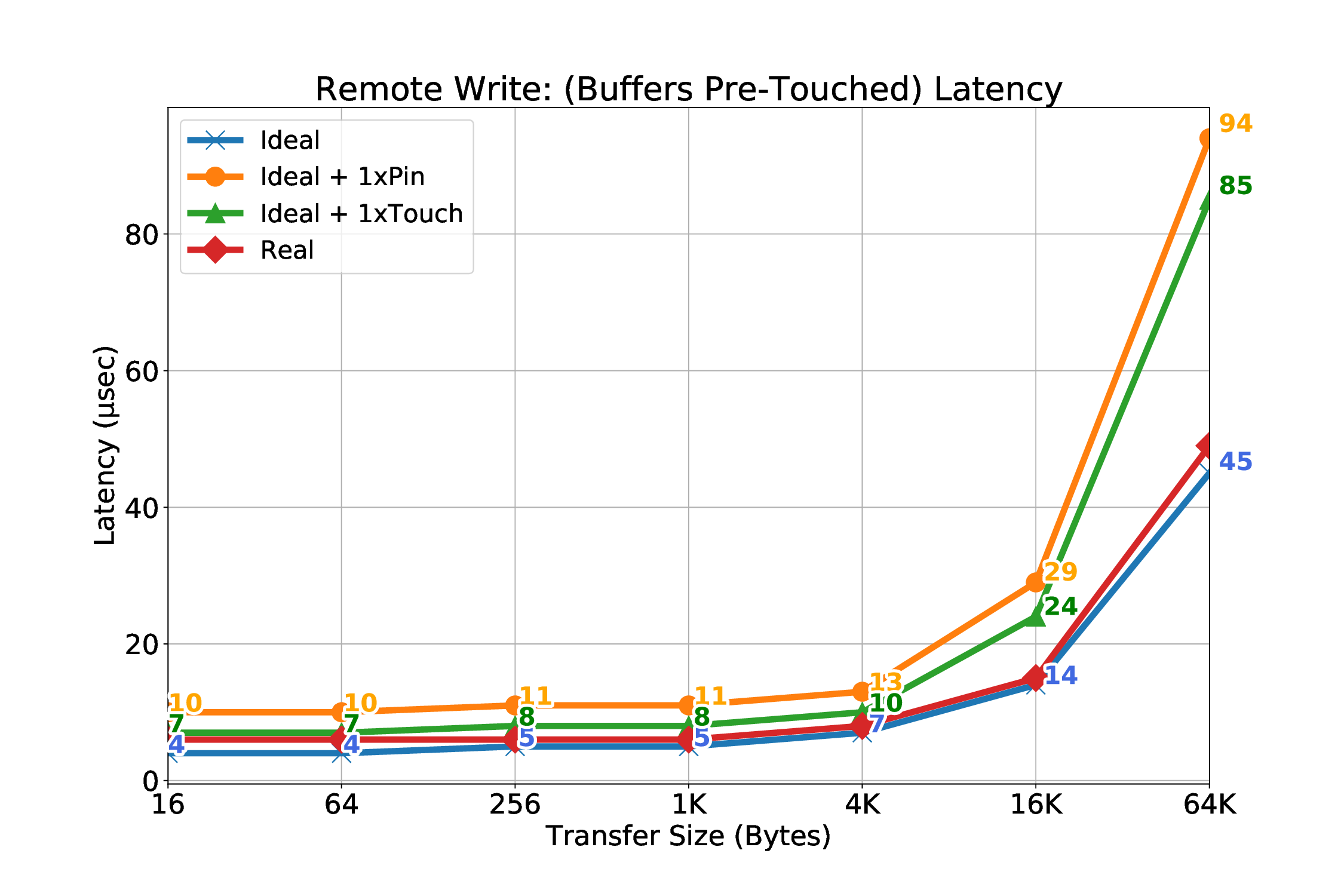
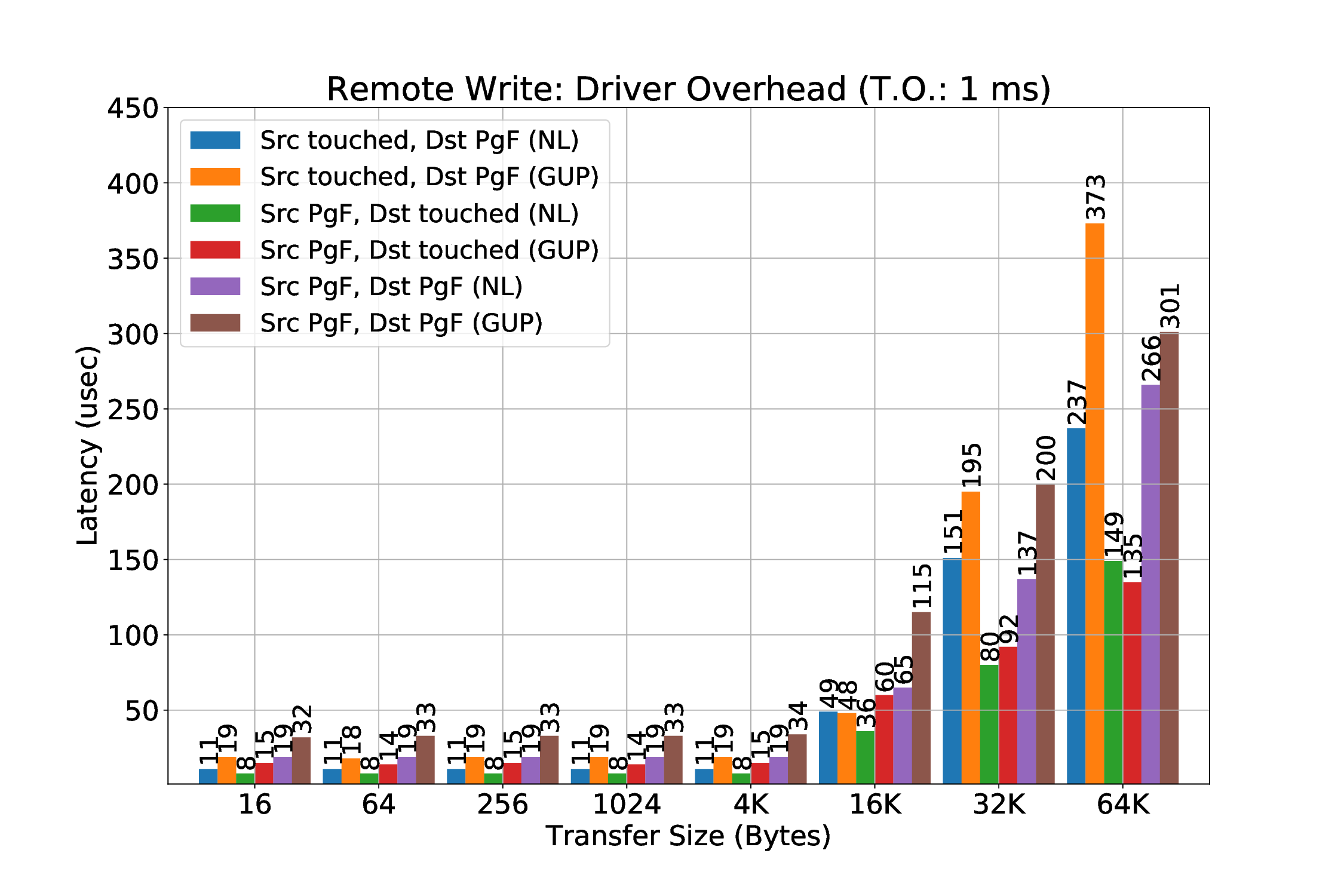
실험 결과는 두드러진 장점을 보여준다. 첫째, 페이지 고정에 의한 메모리 사용량 제한이 사라져, 애플리케이션은 자유롭게 메모리를 할당하고 해제할 수 있다. 둘째, THP와 같은 커널 최적화가 활성화된 상태에서도 안정적인 RDMA 전송이 가능해졌다. 셋째, 사전 폴트 방식에 비해 초기 지연이 현저히 감소했으며, 전체 전송량 대비 오버헤드가 최소화되었다. 이러한 결과는 대규모 데이터 센터와 HPC 환경에서 메모리 집약적인 워크로드를 수행할 때, 전통적인 고정 기반 RDMA보다 에너지 효율과 성능 면에서 우수함을 의미한다. 앞으로는 다중 노드 간의 동시 전송, 다양한 ISA(예: RISC‑V)와의 호환성, 그리고 페이지 폴트 처리 로직을 가속화하는 전용 하드웨어 모듈 설계 등으로 연구 범위를 확장할 여지가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리