LLaMCAT 대규모 언어 모델 추론을 위한 캐시 중재와 스로틀링 최적화
📝 원문 정보
- Title: LLaMCAT: Optimizing Large Language Model Inference with Cache Arbitration and Throttling
- ArXiv ID: 2512.00083
- 발행일: 2025-11-26
- 저자: Zhongchun Zhou, Chengtao Lai, Wei Zhang
📝 초록 (Abstract)
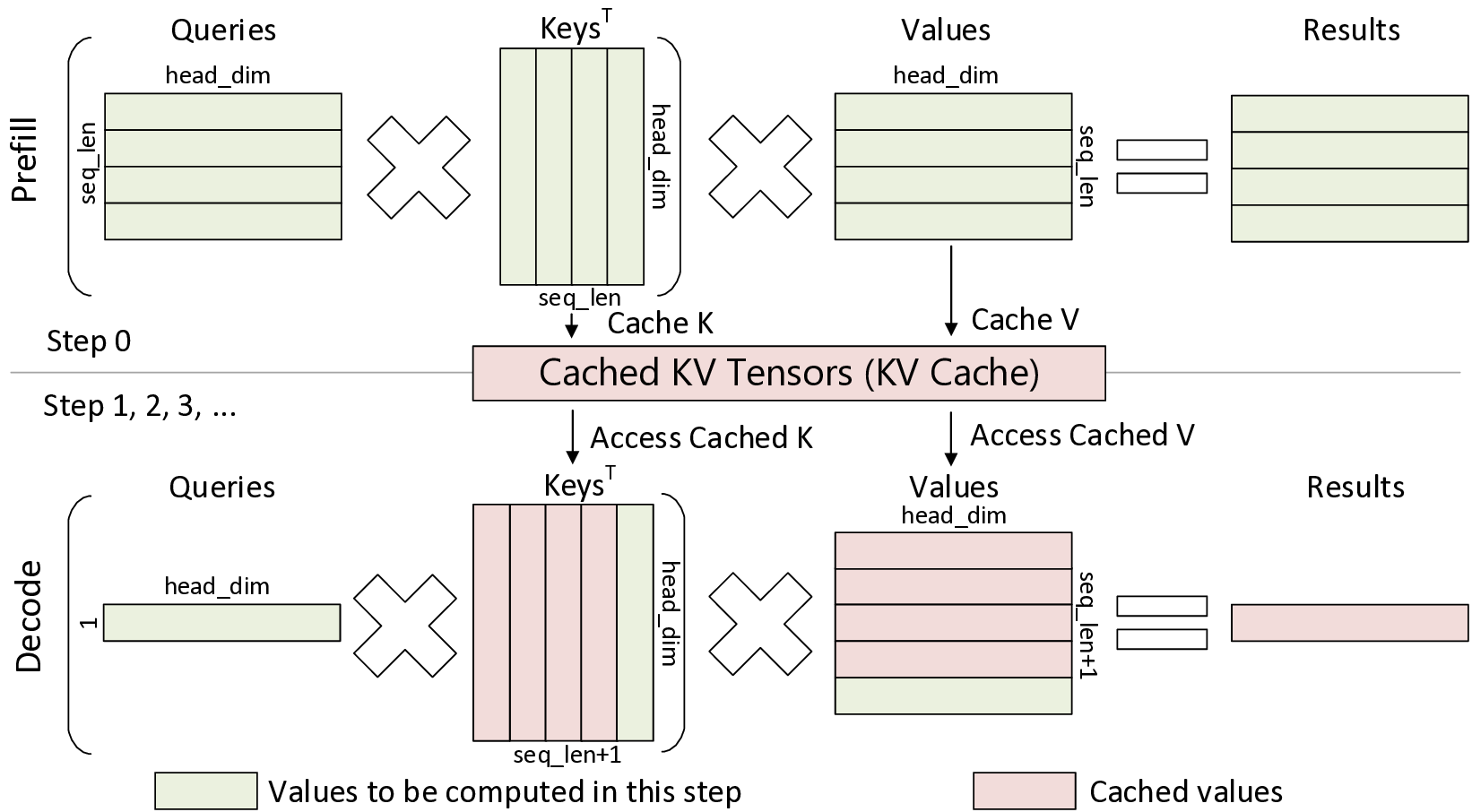
대규모 언어 모델(LLM)은 다양한 응용 분야에서 전례 없는 성공을 거두었지만, 그 막대한 메모리 요구량은 특히 추론 단계에서 현재 메모리 시스템 설계에 큰 어려움을 안겨준다. 본 연구는 NVIDIA GPU와 같은 GPU 및 AI 가속기를 포함한 최종 레벨 캐시(LLC) 기반 아키텍처를 대상으로 한다. 우리는 LLaMCAT이라는 새로운 접근법을 제안한다. LLaMCAT은 Miss Status Holding Register(MSHR)와 로드 밸런스를 고려한 캐시 중재와 스레드 스로틀링을 결합하여 KV 캐시 접근 시 발생하는 높은 대역폭 요구와 캐시 스톨을 최소화한다. 또한 메모리 트레이스를 활용한 분석 모델과 사이클 수준 시뮬레이터를 통합한 하이브리드 시뮬레이션 프레임워크를 제시하여 설계 상세도와 효율성 사이의 균형을 맞춘다. 실험 결과, 시스템이 주로 미스 처리 처리량에 의해 병목이 발생하는 경우 LLaMCAT은 평균 1.26배의 속도 향상을 달성했으며, 기존 방법들은 최적화가 부족해 성능이 감소하였다. 캐시 용량이 제한된 상황에서도 우리 정책은 최적화되지 않은 버전 대비 1.58배, 최고 성능을 보인 기존 기법(dyncta) 대비 1.26배의 향상을 보였다. 전반적으로 LLaMCAT은 LLM 디코딩 단계에서 발생하는 MSHR 경쟁을 최초로 목표로 삼아, 향후 하드웨어 플랫폼에서 LLM 추론 가속을 위한 실용적인 솔루션을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
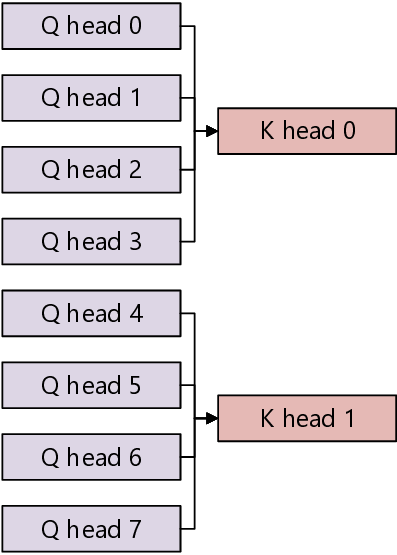
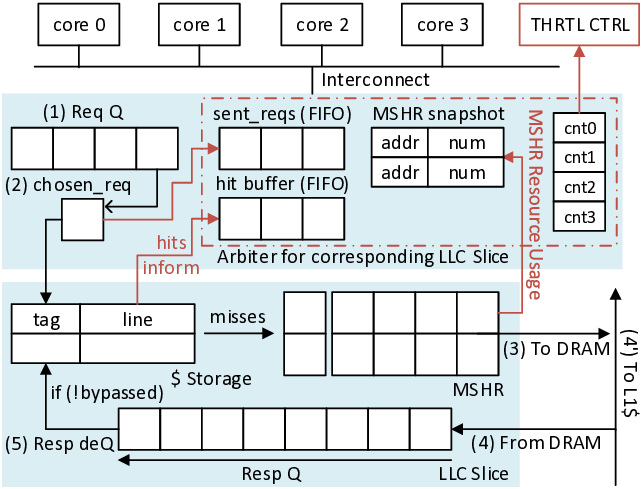
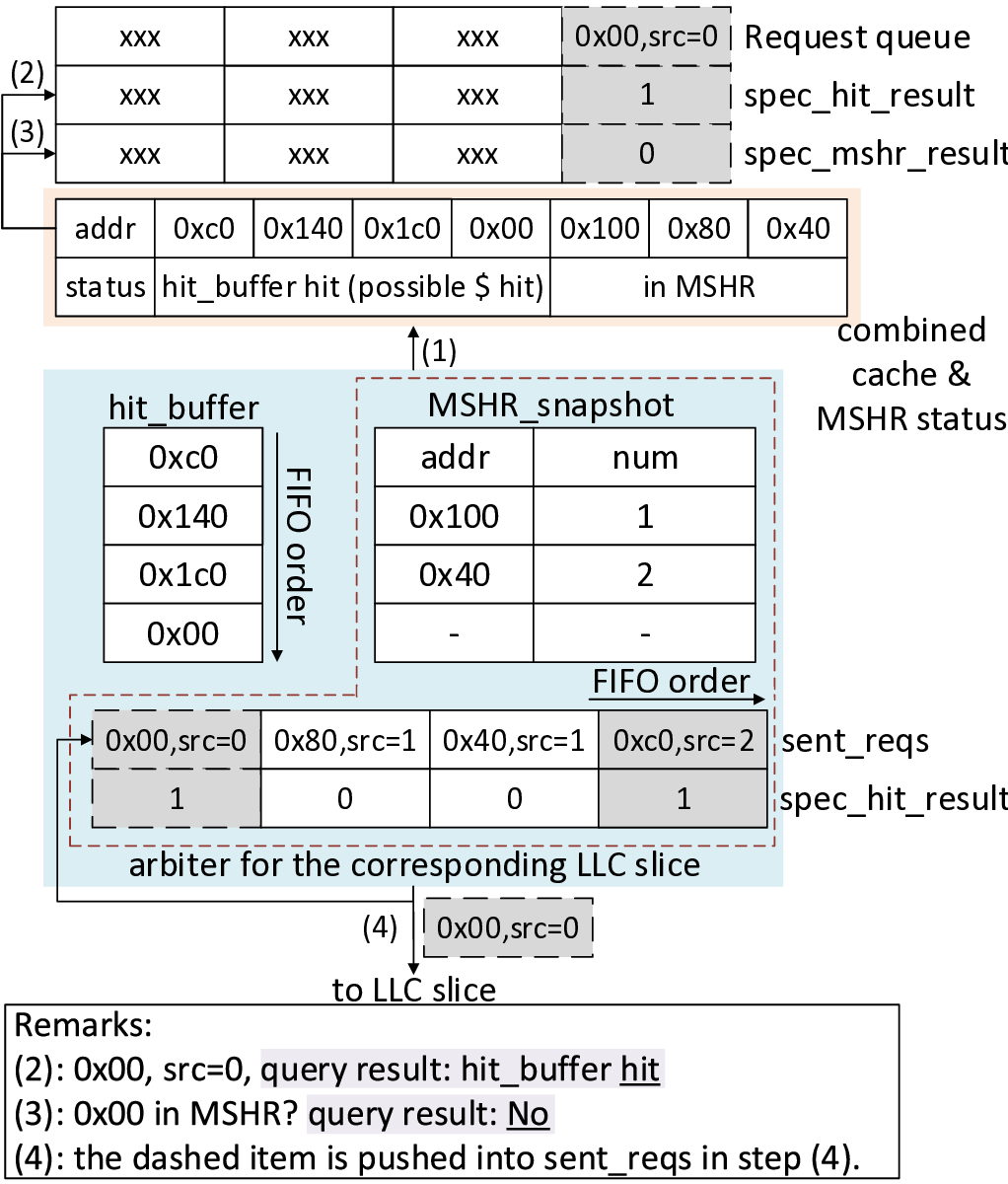
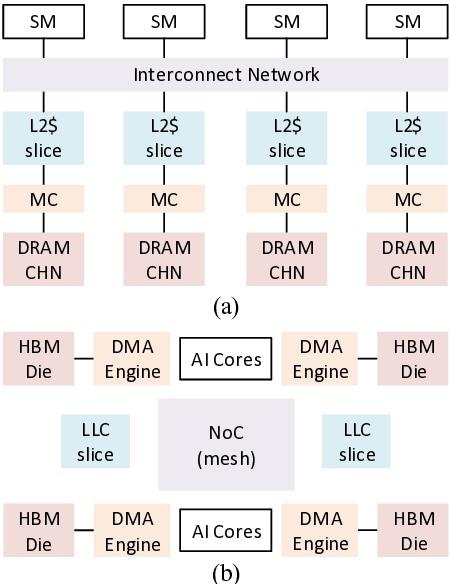
첫 번째 핵심 기여는 “MSHR‑and load balance‑aware cache arbitration”이라는 새로운 캐시 중재 메커니즘이다. MSHR은 메모리 미스가 발생했을 때 해당 요청을 추적·관리하는 레지스터 집합으로, 동시에 여러 미스가 발생하면 MSHR 자원이 포화돼 파이프라인이 정지하는 현상이 나타난다. LLaMCAT은 각 스레드가 발생시키는 미스의 특성을 분석하고, 로드 밸런스를 고려해 MSHR 할당 우선순위를 동적으로 조정한다. 이를 통해 특정 스레드가 과도하게 MSHR을 독점하는 상황을 방지하고, 전체 시스템의 미스 처리량을 최적화한다.
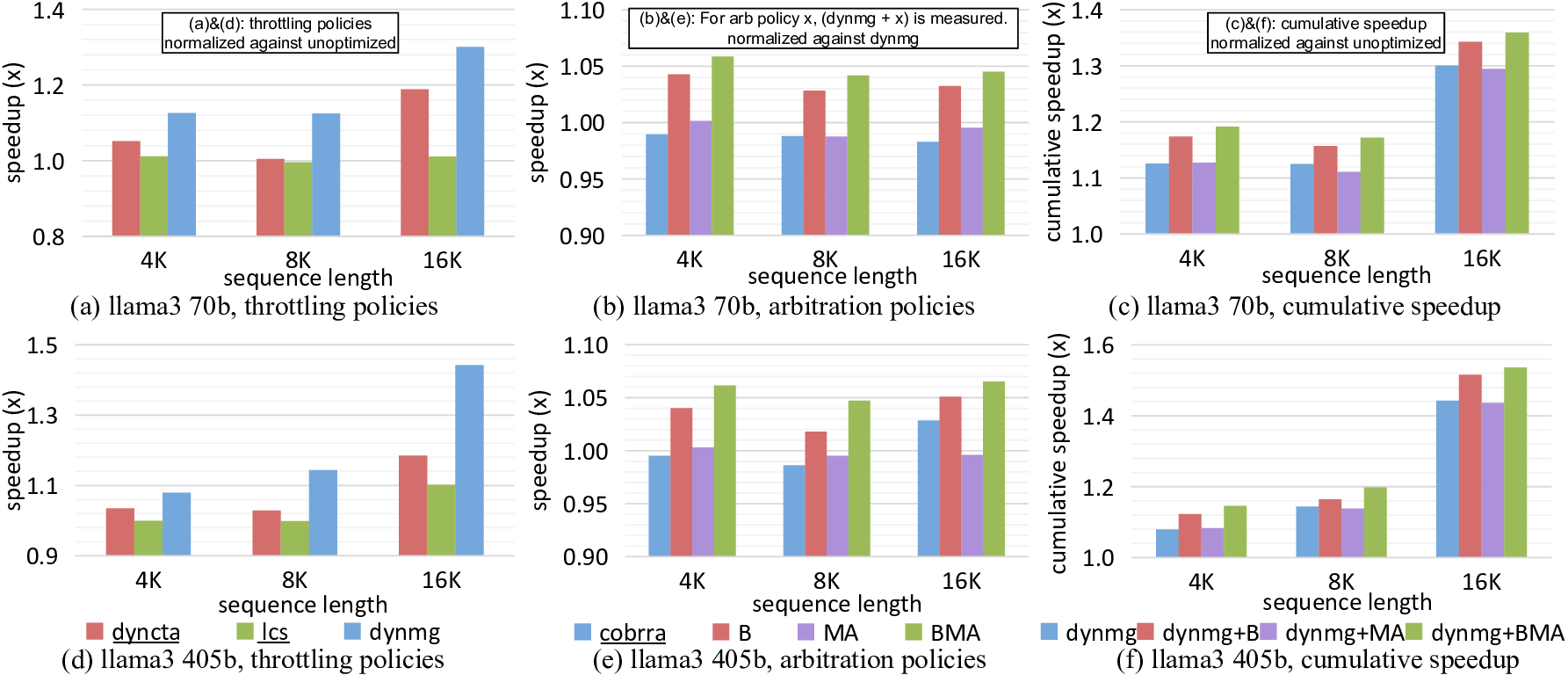
두 번째 기여는 “thread throttling”이다. 디코딩 시에는 토큰당 연산량이 작아 스레드 수를 과도하게 늘리면 오히려 메모리 대역폭 경쟁이 심화된다. LLaMCAT은 실시간으로 캐시 미스율과 메모리 대역폭 사용량을 모니터링하고, 일정 임계치를 초과하면 일부 스레드의 실행을 일시 중단(throttle)한다. 이렇게 하면 메모리 서브시스템에 가해지는 압력을 완화하면서도 전체 처리량을 유지할 수 있다.
세 번째로 제시된 하이브리드 시뮬레이션 프레임워크는 설계 탐색 단계에서 큰 의미를 가진다. 전통적인 사이클‑정밀 시뮬레이터는 정확도가 높지만 실행 시간이 비현실적으로 길고, 순수 분석 모델은 빠르지만 세부적인 마이크로아키텍처 효과를 놓친다. 저자들은 메모리 트레이스를 기반으로 분석 모델을 먼저 적용해 거친 설계 공간을 축소한 뒤, 후보 설계에 대해 사이클‑정밀 시뮬레이션을 수행한다. 이 접근법은 설계 탐색 비용을 크게 낮추면서도 신뢰할 수 있는 성능 예측을 가능하게 한다.
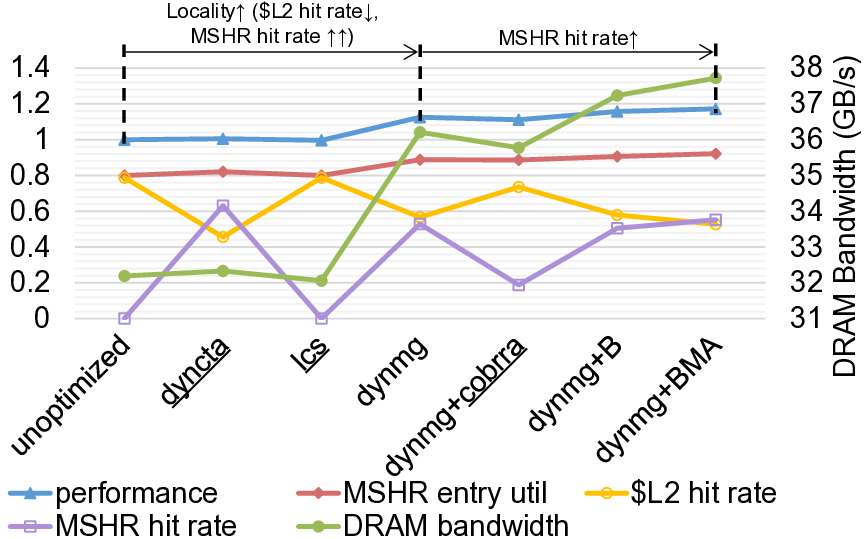
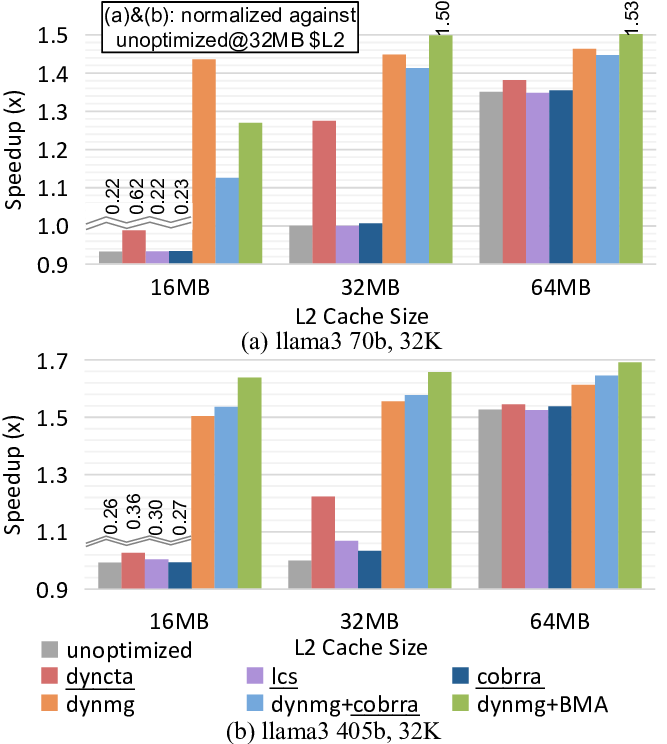
실험 결과는 제안된 정책이 실제 하드웨어 제한 상황에서 얼마나 효과적인지를 잘 보여준다. 특히 “miss handling throughput”이 병목인 경우 평균 1.26배의 속도 향상을 기록했으며, 캐시 용량이 제한된 환경에서는 1.58배까지 성능이 개선되었다. 기존의 동적 캐시 할당 기법(dyncta)과 비교했을 때도 1.26배의 추가 이득을 얻었다는 점은, MSHR 경쟁을 직접 겨냥한 것이 실질적인 성능 향상으로 이어짐을 증명한다.
이 논문의 의의는 두 가지로 요약할 수 있다. 첫째, LLM 디코딩 단계에서 발생하는 특수한 메모리 접근 패턴—특히 KV 캐시와 MSHR 경쟁—을 명시적으로 모델링하고 최적화함으로써, 기존 연구가 간과했던 병목을 해소했다는 점이다. 둘째, 하드웨어 설계자와 시스템 연구자가 실제 제품에 적용 가능한 실용적인 솔루션을 제공한다는 점이다. 앞으로 GPU와 AI 가속기의 캐시 구조가 더욱 복잡해지고, LLM 규모가 계속 확대됨에 따라 LLaMCAT과 같은 MSHR‑aware 정책은 차세대 인공지능 시스템의 핵심 구성 요소가 될 가능성이 크다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리