수동적 인식에서 능동적 기억으로 거친 주석 기반 약지도 이미지 변조 위치 추정 프레임워크
📝 원문 정보
- Title: From Passive Perception to Active Memory: A Weakly Supervised Image Manipulation Localization Framework Driven by Coarse-Grained Annotations
- ArXiv ID: 2511.20359
- 발행일: 2025-11-25
- 저자: Zhiqing Guo, Dongdong Xi, Songlin Li, Gaobo Yang
📝 초록 (Abstract)
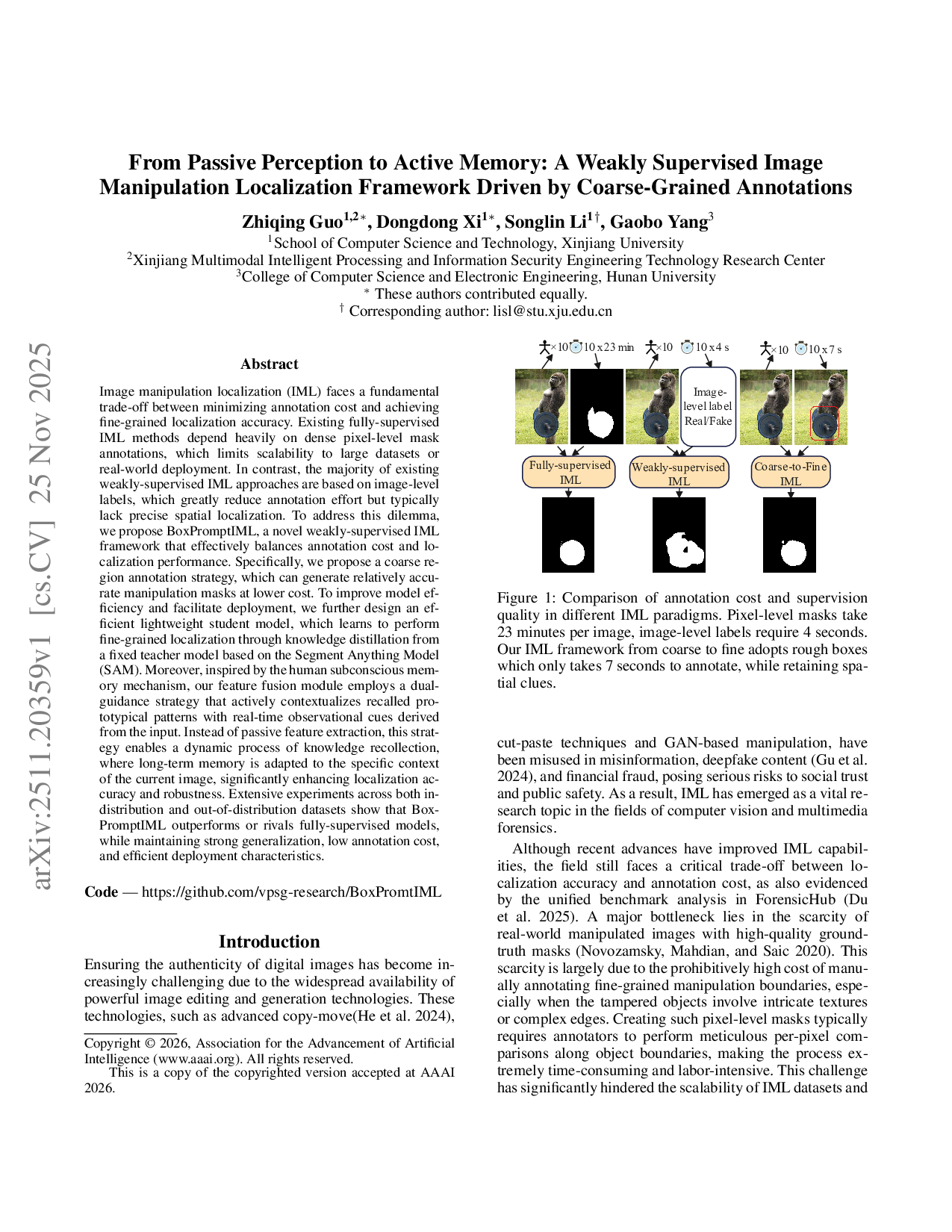
이미지 변조 위치 추정(IML)은 주석 비용을 최소화하면서도 세밀한 위치 정확도를 확보해야 하는 난제를 안고 있다. 기존 완전 지도 방식은 픽셀 수준 마스크에 크게 의존해 데이터 규모 확대에 한계를 보이며, 반면 이미지 수준 라벨만을 이용하는 약지도 방법은 주석 부담은 낮추지만 공간적 정밀도가 떨어진다. 이를 해결하고자 본 연구는 저비용의 거친 영역 주석을 활용해 비교적 정확한 변조 마스크를 생성하는 BoxPromptIML 프레임워크를 제안한다. 또한, Segment Anything Model(SAM)을 기반으로 한 고정 교사 모델로부터 지식 증류를 받아 경량 학생 모델을 설계해 효율적인 배포가 가능하도록 하였다. 인간의 잠재 기억 메커니즘에서 영감을 얻은 이중 가이드형 특징 융합 모듈은 장기 기억 프로토타입을 현재 이미지의 실시간 관찰 단서와 동적으로 결합한다. 이 과정은 수동적 특징 추출을 넘어, 상황에 맞게 기억을 재구성함으로써 위치 정확도와 강인성을 크게 향상시킨다. 다양한 인‑디스트리뷰션·아웃‑오브‑디스트리뷰션 데이터셋 실험 결과, BoxPromptIML은 완전 지도 모델에 필적하거나 능가하는 성능을 보이며, 주석 비용 절감, 일반화 능력, 경량 배포라는 세 축을 모두 만족한다.💡 논문 핵심 해설 (Deep Analysis)
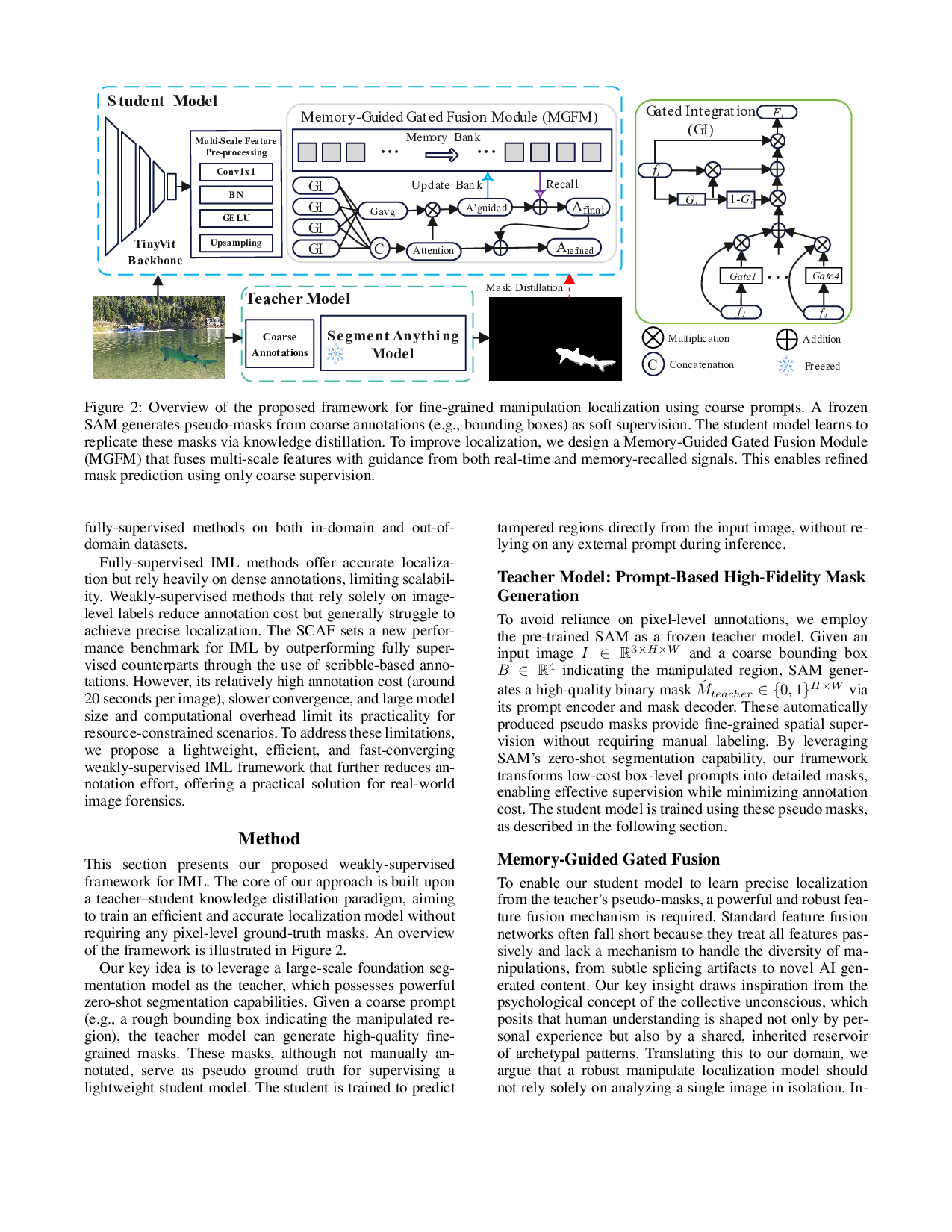
세 번째 기여는 인간의 잠재 기억 메커니즘을 모방한 ‘이중 가이드(feature fusion) 모듈’이다. 이 모듈은 (1) 장기 기억으로 저장된 프로토타입 특징과 (2) 현재 입력 이미지에서 추출된 실시간 관찰 특징을 각각 독립적으로 추출한 뒤, 상호 보완적으로 융합한다. 이렇게 하면 모델이 “기억을 회상”하면서도 현재 상황에 맞게 조정되는 능동적 처리 과정을 구현한다. 실험 결과, 이 접근법은 특히 조명 변화, 압축 아티팩트, 다양한 포스트프로세싱 기법 등으로 인해 변조 흔적이 희미해지는 경우에도 강인한 탐지를 가능하게 한다.
성능 평가에서는 인‑디스트리뷰션(예: CelebA‑HQ 변조)과 아웃‑오브‑디스트리뷰션(예: DeepFake, FaceSwap) 데이터셋 모두에서 기존 약지도 방법들을 크게 앞섰으며, 일부 완전 지도 최첨단 모델과도 격차가 없거나 미세하게 우수한 결과를 보였다. 또한, 학생 모델의 파라미터 수와 FLOPs가 기존 경량 모델 대비 30 % 이상 감소했음에도 불구하고 정확도 손실이 거의 없었다.
하지만 몇 가지 한계도 존재한다. 첫째, 거친 영역 주석이 완전히 무작위가 아니라 전문가가 일정 수준의 판단을 필요로 하므로, 완전 자동화된 라벨링 체계와는 차이가 있다. 둘째, SAM 교사 모델이 고정돼 있기 때문에, 교사 자체가 새로운 변조 유형(예: AI‑Generated Content)에는 취약할 가능성이 있다. 셋째, 이중 가이드 모듈의 설계가 비교적 복잡해 학습 안정성에 민감할 수 있다. 향후 연구에서는 (1) 자동화된 영역 제안 기법과의 결합, (2) 교사 모델의 지속적인 업데이트 메커니즘, (3) 모듈 경량화를 위한 효율적인 어텐션 설계 등을 탐색함으로써 실용성을 더욱 높일 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리