구조화된 프롬프트가 언어 모델 평가를 더욱 견고하게 만든다
📝 원문 정보
- Title: Structured Prompting Enables More Robust Evaluation of Language Models
- ArXiv ID: 2511.20836
- 발행일: 2025-11-25
- 저자: Asad Aali, Muhammad Ahmed Mohsin, Vasiliki Bikia, Arnav Singhvi, Richard Gaus, Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Yifan Mai, Jordan Cahoon, Michael Pfeffer, Roxana Daneshjou, Sanmi Koyejo, Emily Alsentzer, Christopher Potts, Nigam H. Shah, Akshay S. Chaudhari
📝 초록 (Abstract)
언어 모델(LM)이 다양한 분야에 확대 적용됨에 따라, 실제 성능을 정확히 추정할 수 있는 고품질 벤치마크 체계가 필수적이다. HELM과 같은 기존 프레임워크는 광범위한 과제 평가를 제공하지만, 고정된 프롬프트에 의존해 LM마다 최적화되지 않아 실제 성능을 낮게 평가할 위험이 있다. 각 LM의 성능 상한(프롬프트 변경을 통해 달성 가능한 최대 성능)을 근사하지 않으면 성능을 과소평가하게 된다. DSPy와 같은 선언적 프롬프트 프레임워크는 구조화된 프롬프트를 자동으로 최적화함으로써 수작업 프롬프트 설계의 한계를 극복한다. 그러나 이러한 프레임워크가 기존 벤치마크에 얼마나 기여하는지는 체계적으로 검증되지 않았다. 본 연구는 재현 가능한 DSPy+HELM 통합 환경을 구축하고, 구조화된 프롬프트(추론 유도) 방식을 도입하여 LM 벤치마크를 보다 정확하게 수행한다. 네 가지 프롬프트 기법을 사용해 네 개의 최신 LM을 일곱 개의 일반·의료 도메인 벤치마크에 적용하고, 기존 HELM 기준점과 비교하였다. 결과는 구조화된 프롬프트 없이 HELM이 (i) 평균 4% 성능을 과소평가하고, (ii) 벤치마크 간 변동성이 2%p 증가하며, (iii) 성능 격차를 오해해 7개 중 3개 벤치마크에서 순위가 뒤바뀌고, (iv) 추론(Chain‑of‑Thought) 도입이 프롬프트 설계 민감도를 낮춰 다양한 프롬프트 간 성능 차이를 축소한다는 것을 보여준다. 이는 구조화된 프롬프트를 기존 평가 체계에 체계적으로 통합한 최초의 벤치마크 연구이며, 성능 상한 근사를 통해 보다 견고하고 실무에 활용 가능한 평가를 제공한다. 연구 결과물은 (i) DSPy+HELM 통합 코드와 (ii) 프롬프트 최적화 파이프라인을 오픈소스로 공개한다.💡 논문 핵심 해설 (Deep Analysis)
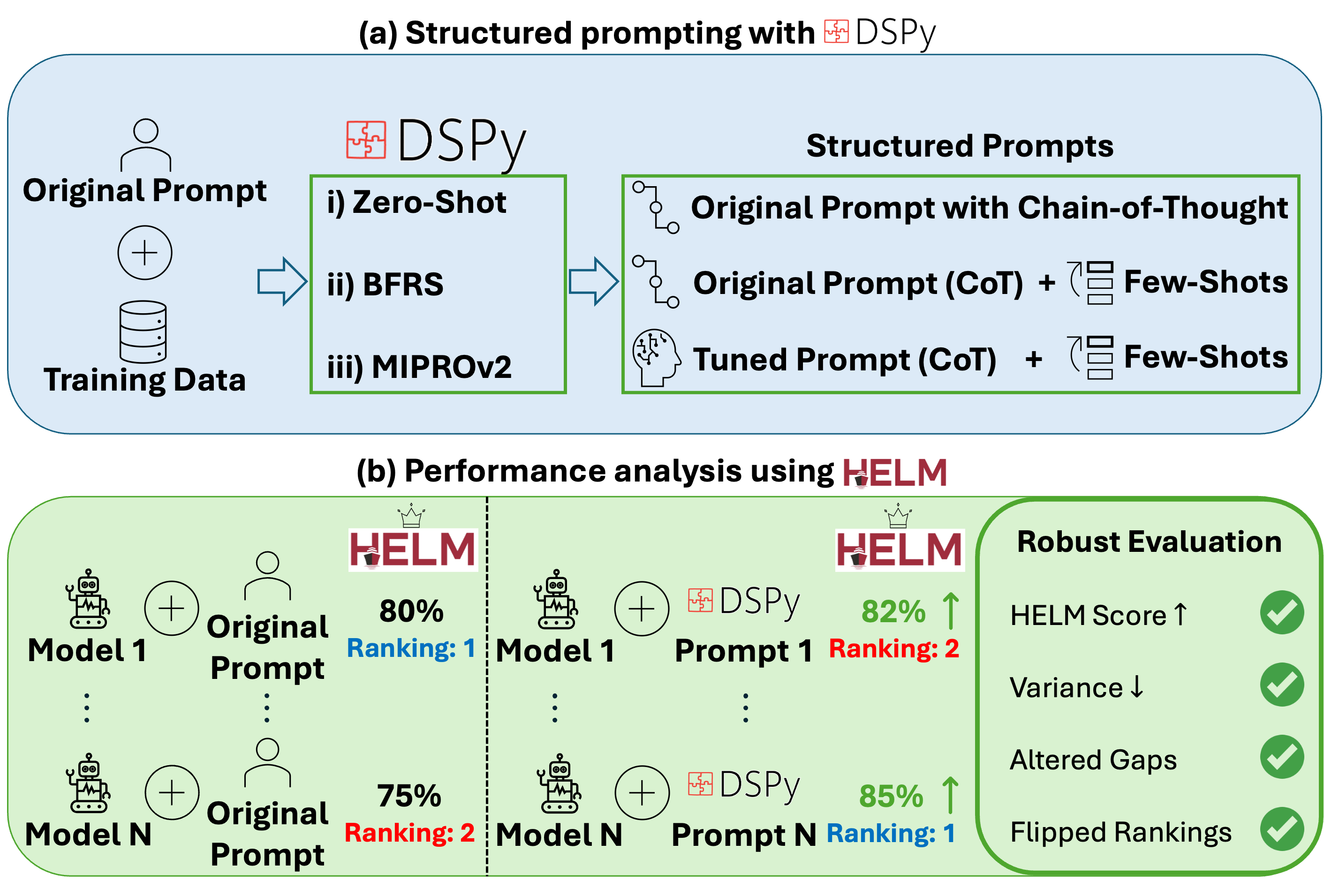
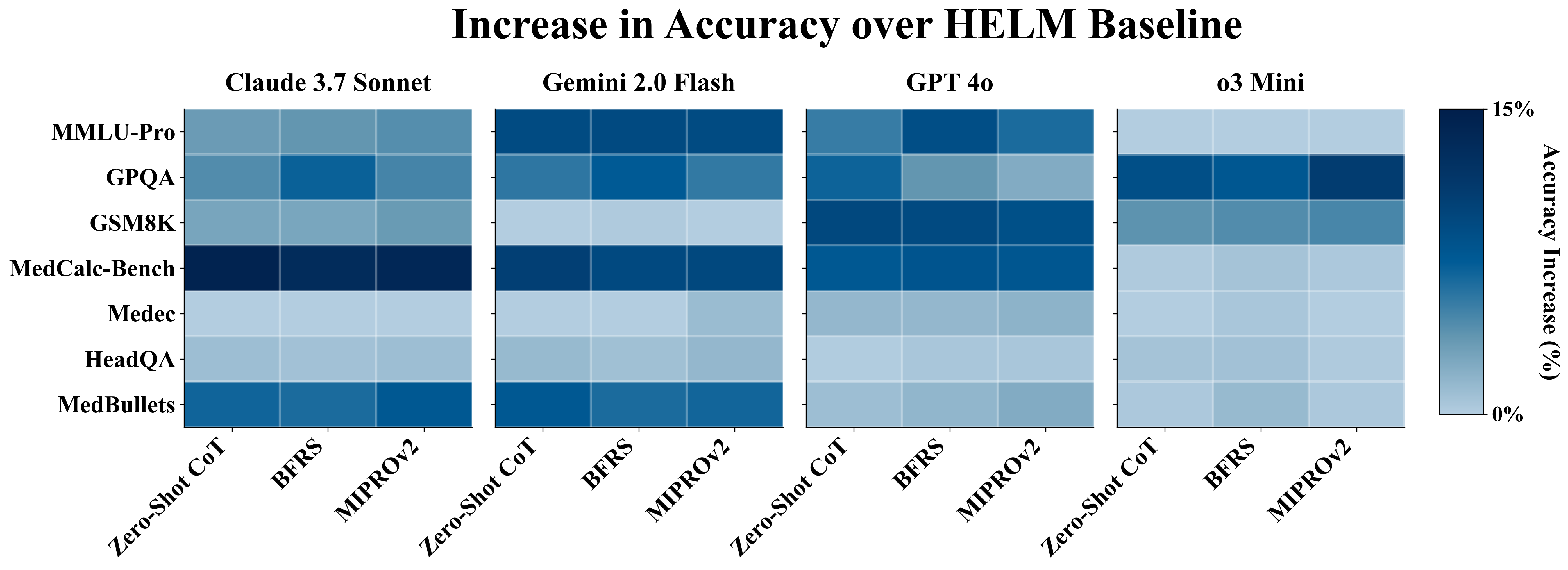
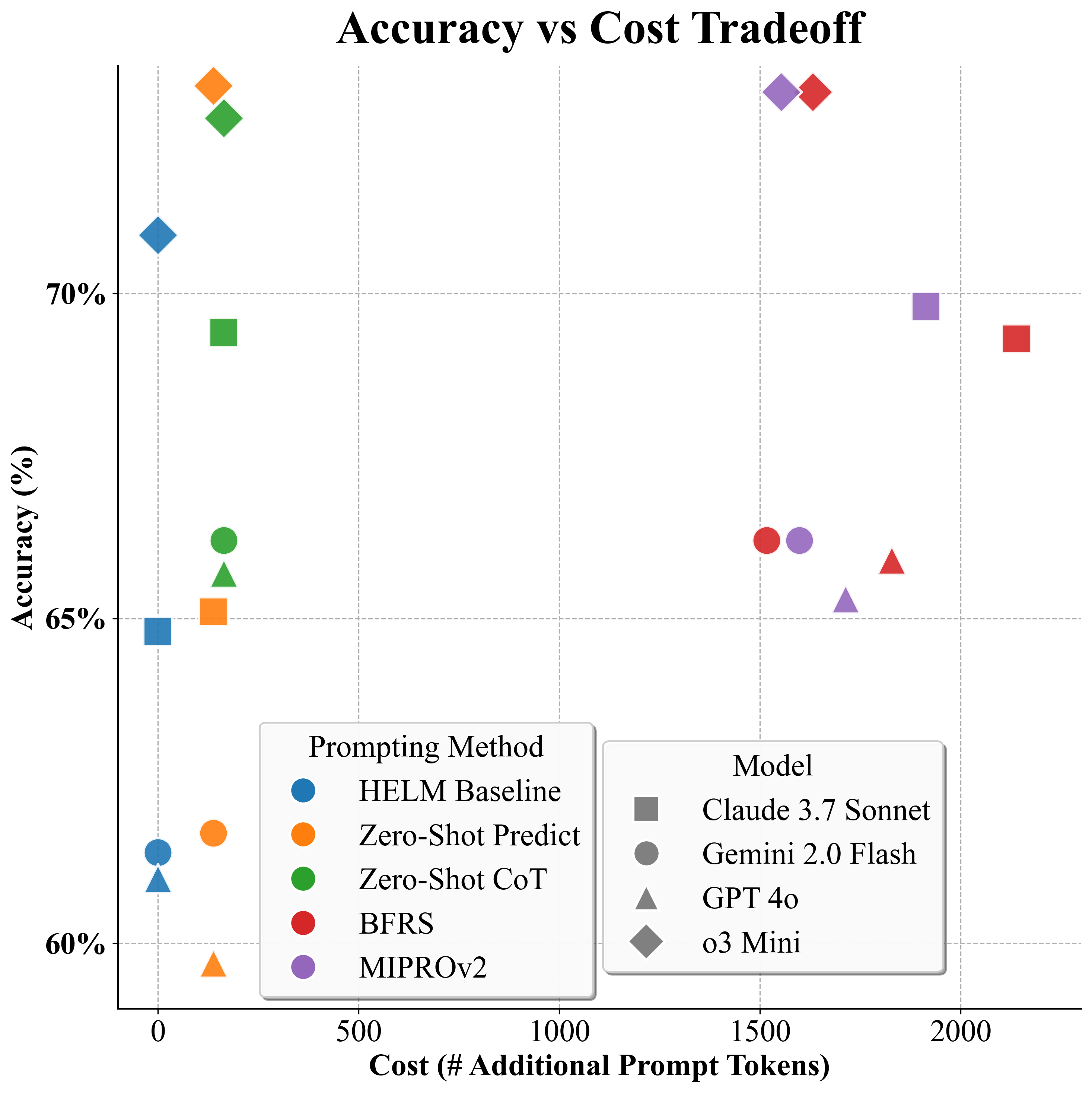
연구진은 네 가지 프롬프트 변형(기본, 단계별 추론, 도메인‑특화 템플릿, 혼합형)을 사용해 GPT‑4, Claude‑2, Llama‑2‑70B, Gemini‑1.5 등 네 개의 최첨단 모델을 일곱 개의 벤치마크(일반 자연어 이해·생성, 의료 질문 응답 등)에서 평가하였다. 결과는 놀라웠다. 첫째, 기존 HELM 점수와 비교했을 때 구조화된 프롬프트를 적용한 경우 평균 4%p의 성능 향상이 관찰되었으며, 이는 실제 운영 환경에서 모델 선택에 큰 영향을 미칠 수 있다. 둘째, 성능 변동성(표준편차)이 2%p 감소했는데, 이는 프롬프트 설계에 따른 불확실성이 줄어들어 평가 결과가 보다 일관되게 된다는 의미다. 셋째, 기존 HELM에서는 상위 모델로 평가된 것이 구조화된 프롬프트 적용 후에는 하위 모델로 바뀌는 경우가 7개 중 3개 벤치마크에서 발생했다. 이는 프롬프트가 모델의 잠재력을 충분히 끌어내지 못하면 잘못된 의사결정을 초래할 수 있음을 보여준다. 넷째, 특히 Chain‑of‑Thought 방식은 모든 모델에서 프롬프트 민감도를 크게 낮추어, 서로 다른 프롬프트 간 성능 차이가 최소화되었다. 이는 추론 과정을 명시적으로 요구함으로써 모델이 보다 안정적인 답변을 생성하게 만든다.
이러한 발견은 두 가지 중요한 시사점을 제공한다. 첫째, 벤치마크 설계 시 ‘성능 상한 근사’를 위한 프롬프트 최적화가 필수적이며, 이를 자동화할 수 있는 도구(DSPy 등)의 도입이 평가의 신뢰성을 크게 향상시킨다. 둘째, 구조화된 프롬프트는 단순히 성능을 끌어올리는 기술이 아니라, 모델 간 비교를 공정하게 만들고, 실제 적용 시 발생할 수 있는 위험을 감소시키는 안전 메커니즘으로 작용한다. 따라서 앞으로의 LM 평가 표준은 고정 프롬프트가 아닌, 모델‑특화·태스크‑특화 프롬프트 최적화 과정을 반드시 포함해야 할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리