Adam과 RMSProp과 같은 적응형 옵티마이저는 복잡한 신경망, 특히 GAN 및 Transformer에서 안정적인 성능과 빠른 수렴 속도로 큰 주목을 받아왔다. 그러나 적응형 옵티마이저는 각 차원의 학습률을 개별적으로 조정함으로써 전체 손실 지형에 대한 정보를 무시하게 되고, 이는 파라미터 업데이트가 느려져 학습률 조정 전략이 무효화되며 결국 파라미터 수렴이 충분히 이루어지지 않는다는 한계를 가지고 있다. 본 논문에서는 모든 파라미터 차원을 연관시켜 새로운 업데이트 방향을 탐색하는 HVAdam이라는 새로운 옵티마이저를 제안한다. HVAdam은 파라미터 차원 간 상호작용을 고려함으로써 보다 정교한 업데이트 전략을 제공하고, 수렴 속도를 크게 향상시킨다. 광범위한 실험을 통해 이미지 분류, 이미지 생성, 자연어 처리 과제에서 기존 방법 대비 빠른 수렴, 높은 정확도, 그리고 더 안정적인 성능을 입증하였다. 특히 Wasserstein‑GAN(WGAN) 및 Gradient Penalty를 적용한 개선형 WGAN‑GP와 같은 GAN 모델에서 다른 최첨단 방법들에 비해 현저한 성능 향상을 보였다. 코드와 구현은 https://github.com/ChihayaAnn/HVAdam 에서 확인할 수 있다.
💡 논문 핵심 해설 (Deep Analysis)
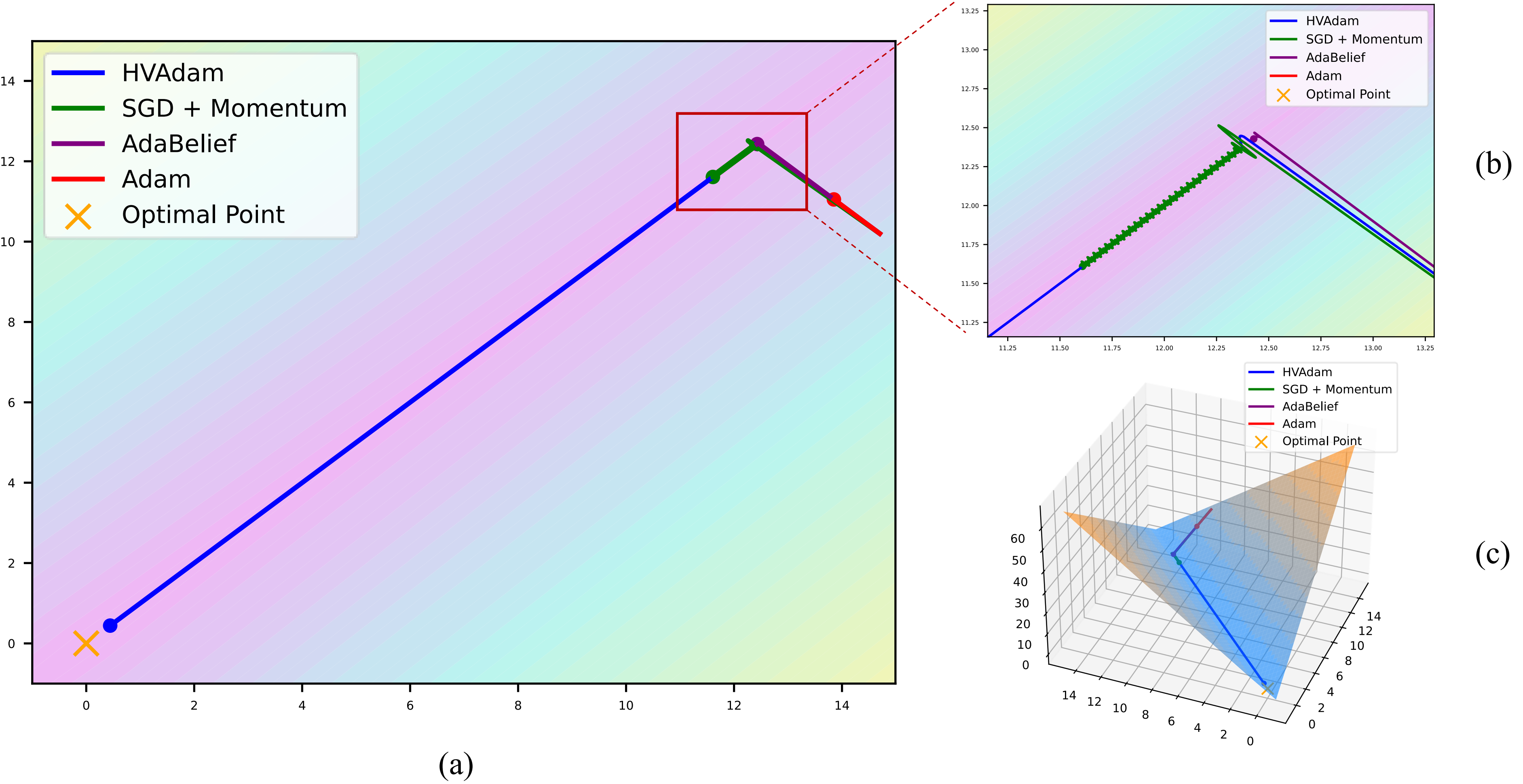
본 연구는 현재 딥러닝 커뮤니티에서 널리 사용되는 적응형 옵티마이저인 Adam·RMSProp이 갖는 근본적인 구조적 한계를 지적한다. 기존 적응형 방법은 1차원(각 파라미터)별로 순간적인 1차·2차 모멘트를 추정해 학습률을 조정한다. 이는 각 파라미터가 독립적으로 움직인다는 전제 하에 설계된 것이며, 실제 고차원 손실 표면에서는 파라미터 간 상관관계가 복잡하게 얽혀 있다. 이러한 상관관계를 무시하면, 예를 들어 손실이 좁은 골짜기 형태로 연속되는 경우 한 차원에서는 급격히 감소하지만 다른 차원에서는 완만히 변하는 상황에서, 개별 학습률 조정은 전체적인 이동 방향을 왜곡시켜 최적점에 도달하는 데 불필요한 반복을 초래한다.
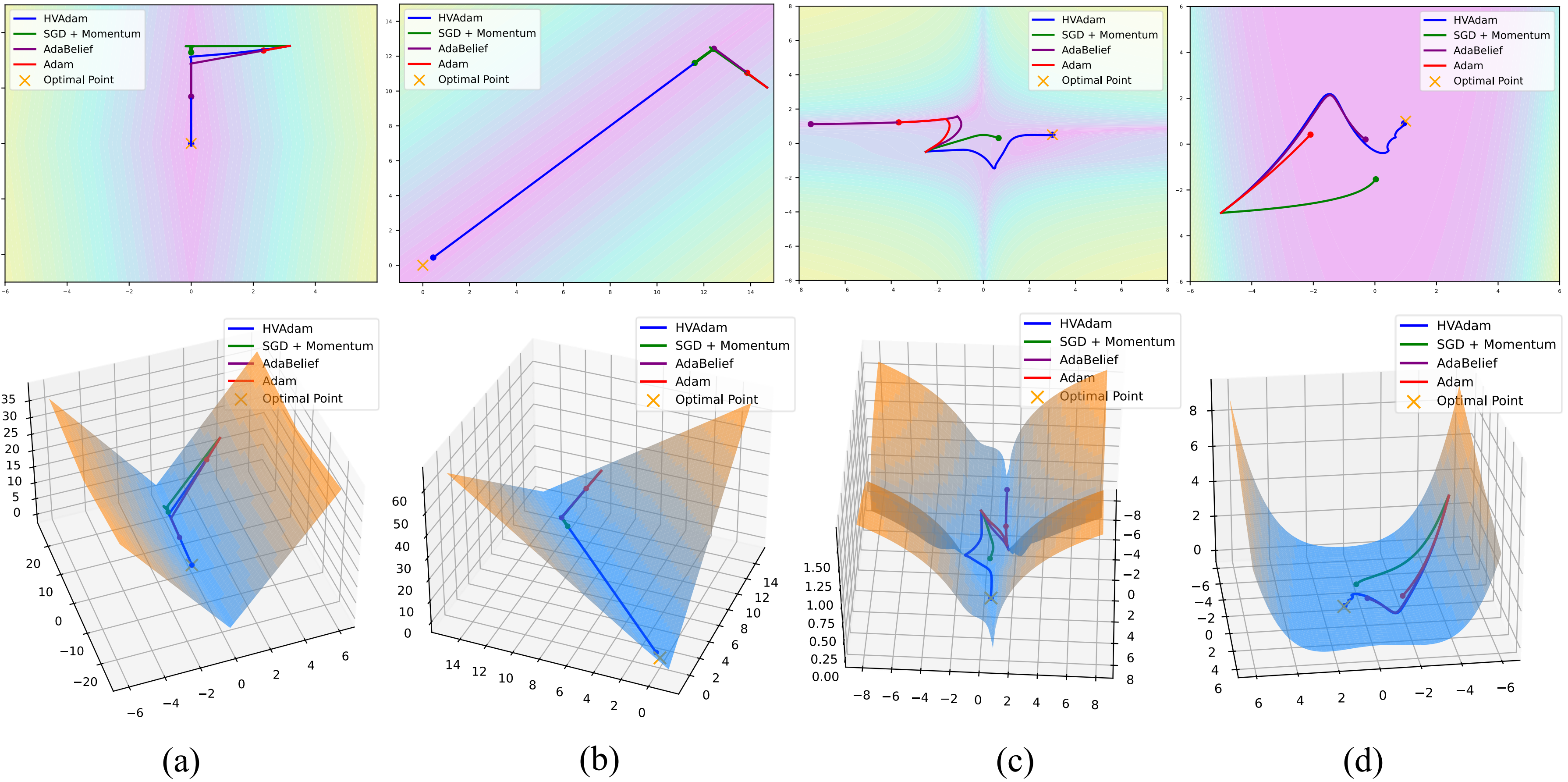
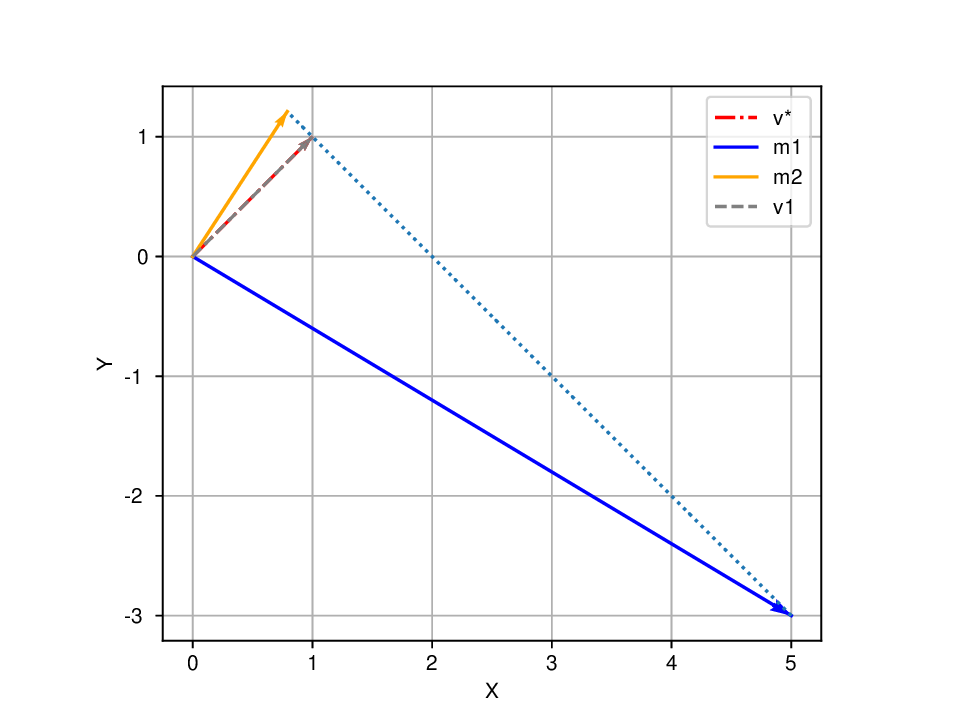
HVAdam은 이러한 문제를 해결하기 위해 “전체 차원 연관성(High‑Dimensional Variance)”을 명시적으로 모델링한다. 구체적으로, 각 파라미터의 1차·2차 모멘트뿐 아니라 차원 간 공분산 행렬을 추정하고, 이를 기반으로 다변량 정규분포 형태의 업데이트 방향을 샘플링한다. 이 과정에서 차원 간 상호작용을 반영한 공분산 행렬의 역행렬을 이용해 스케일링을 수행함으로써, 손실 표면의 주요 축에 맞춰 효율적인 이동을 가능하게 한다. 결과적으로 파라미터가 손실 골짜기의 긴 축을 따라 빠르게 전진하고, 얕은 축에서는 과도한 진동을 억제한다.
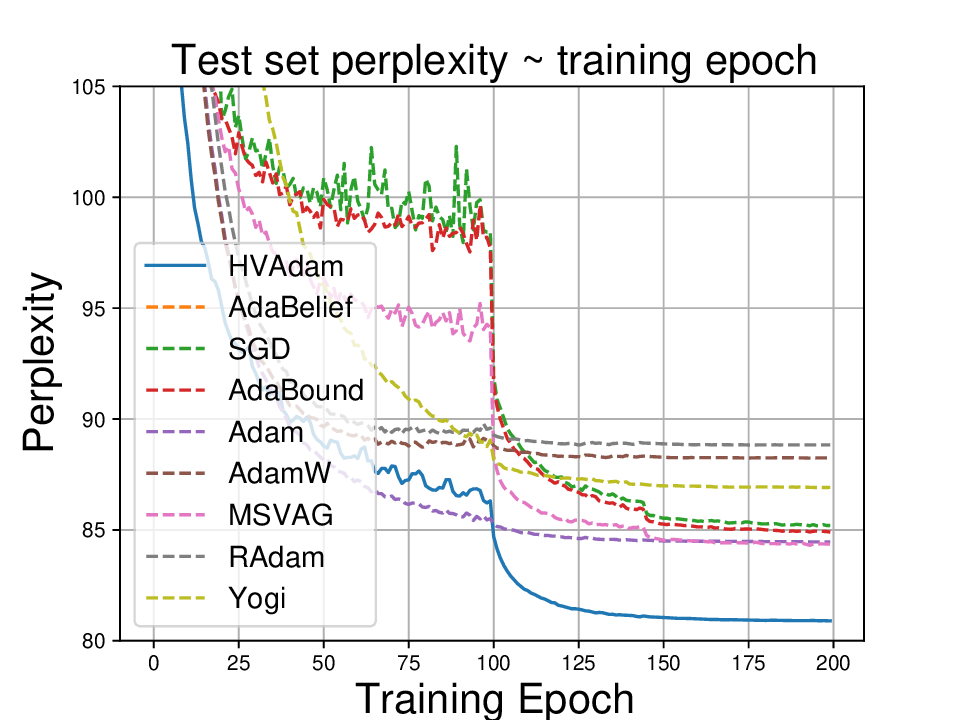
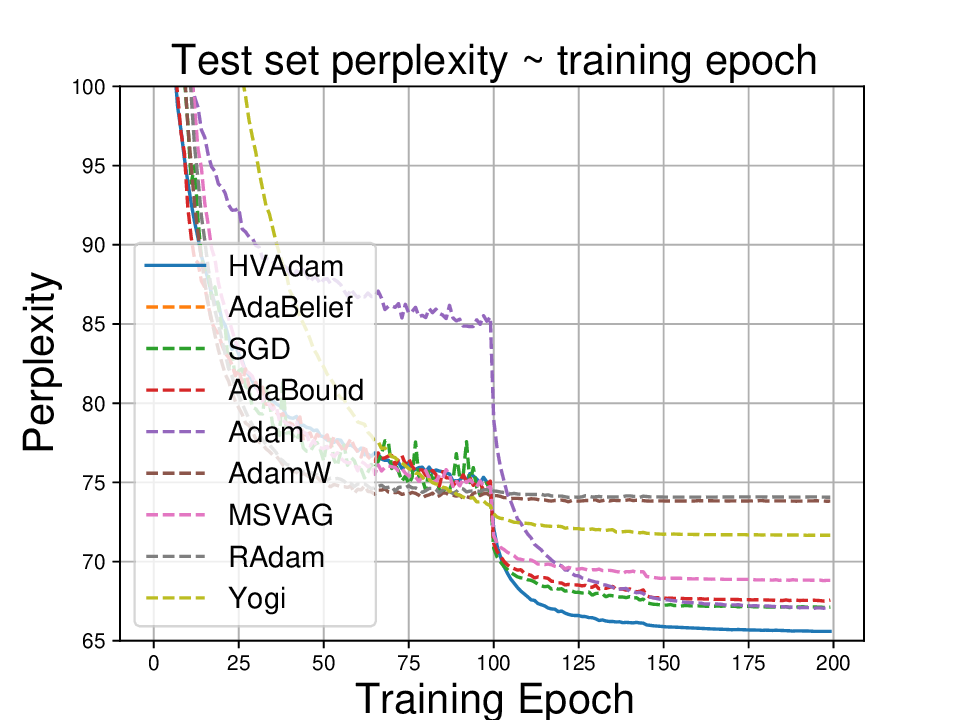
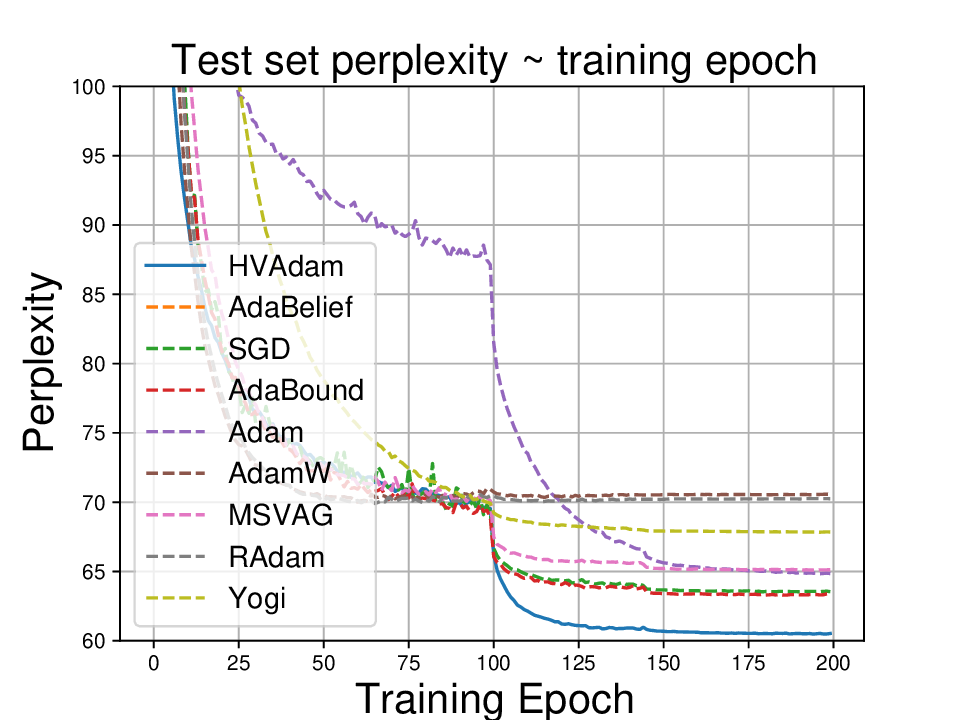
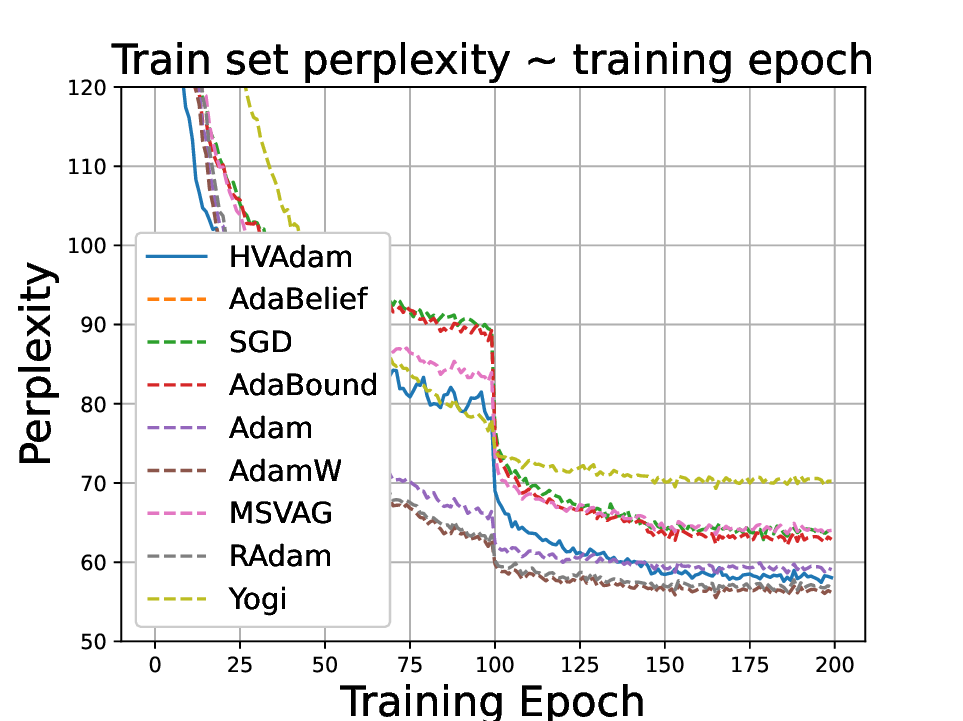
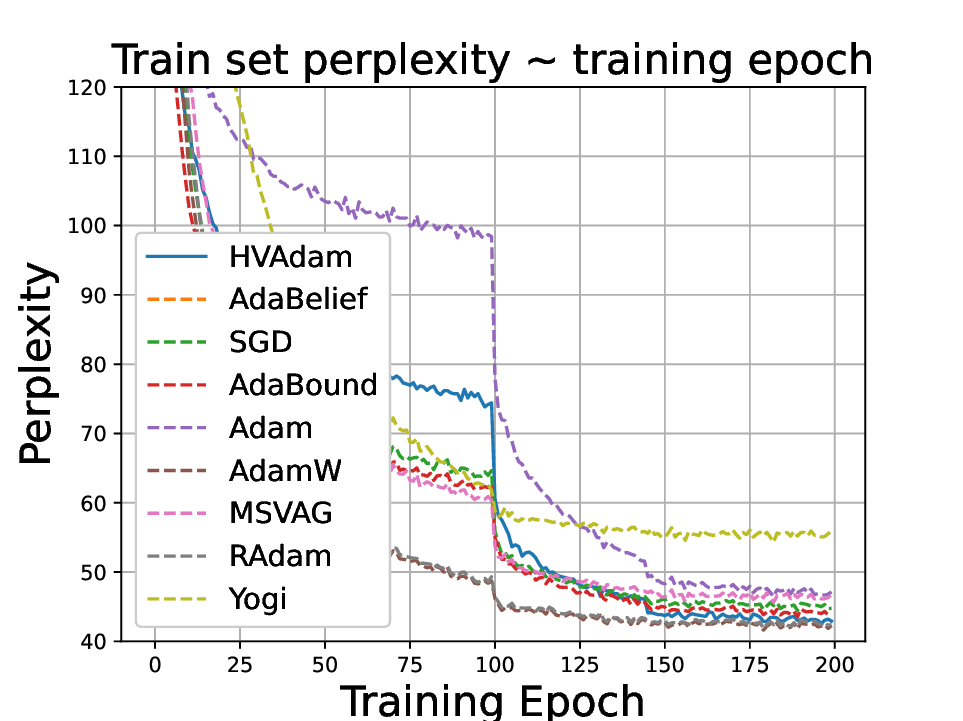
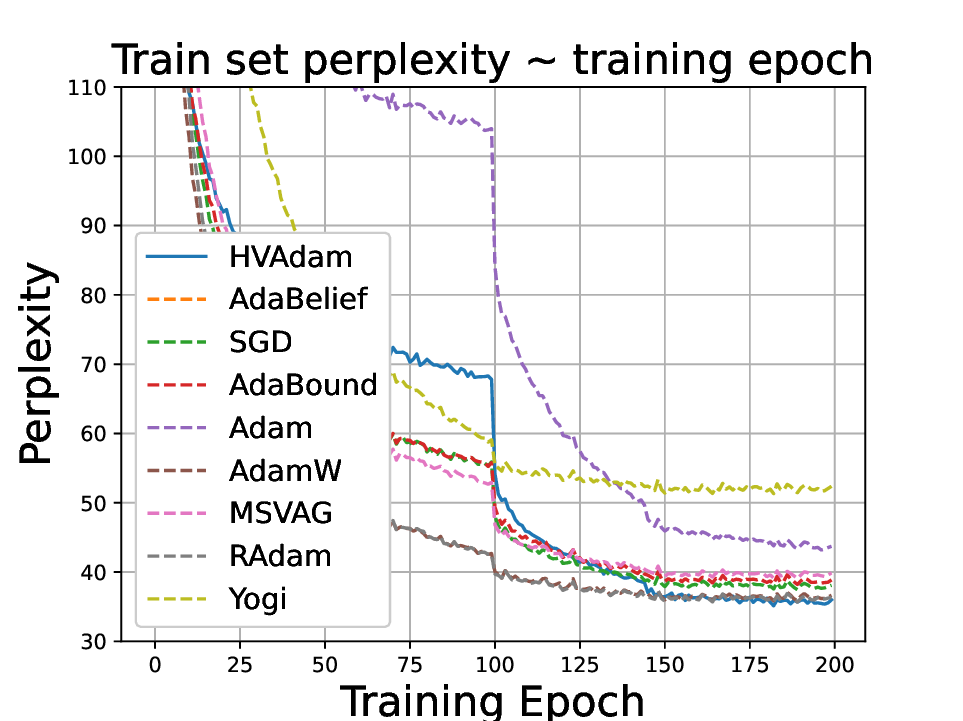
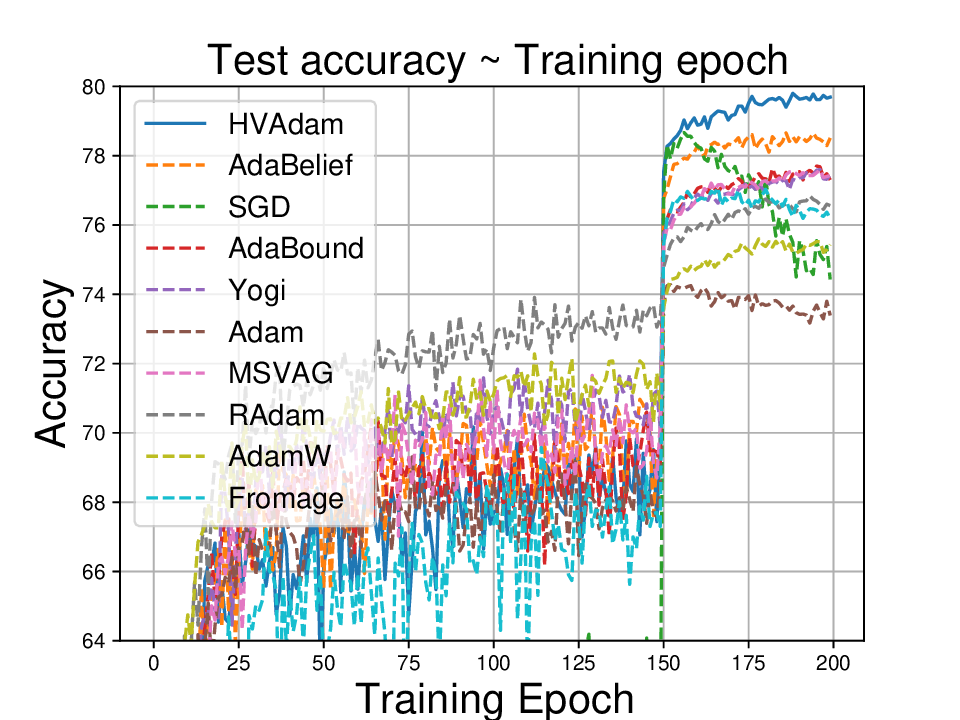
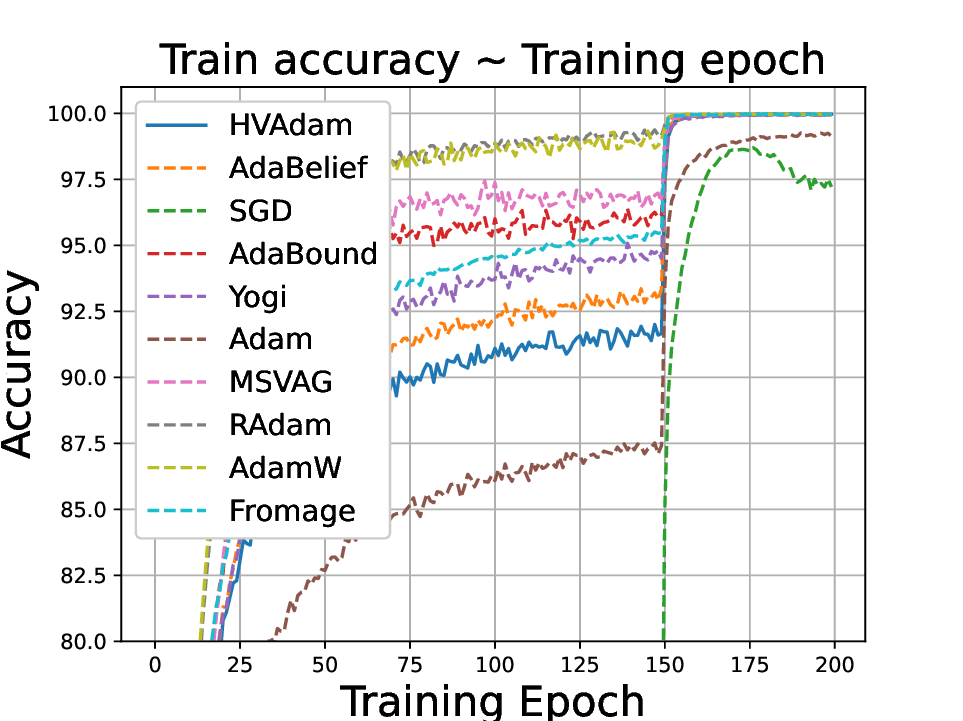
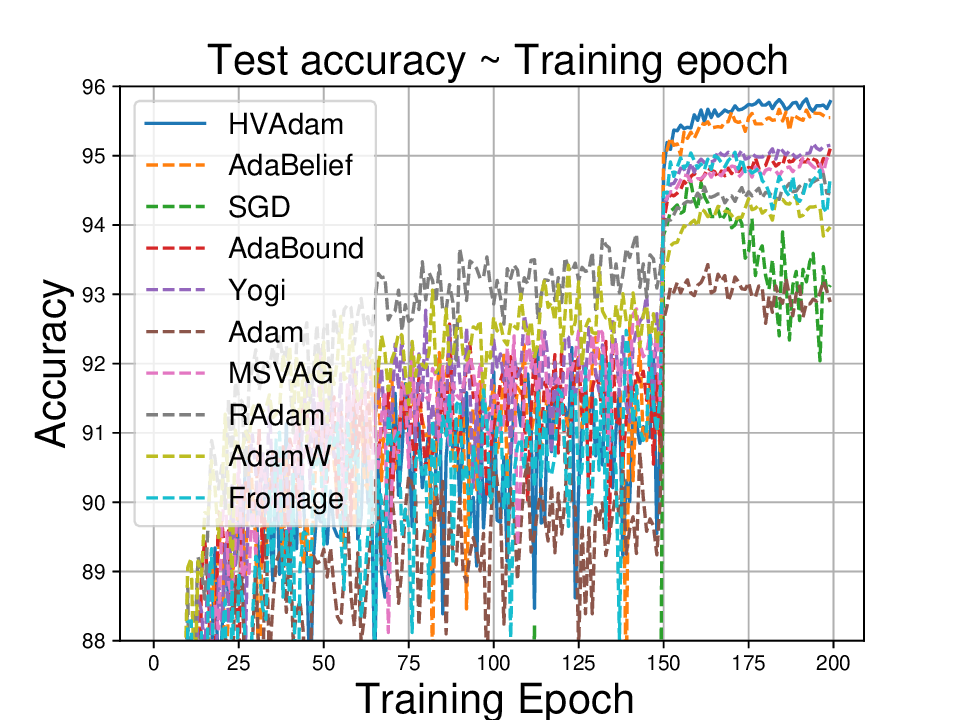
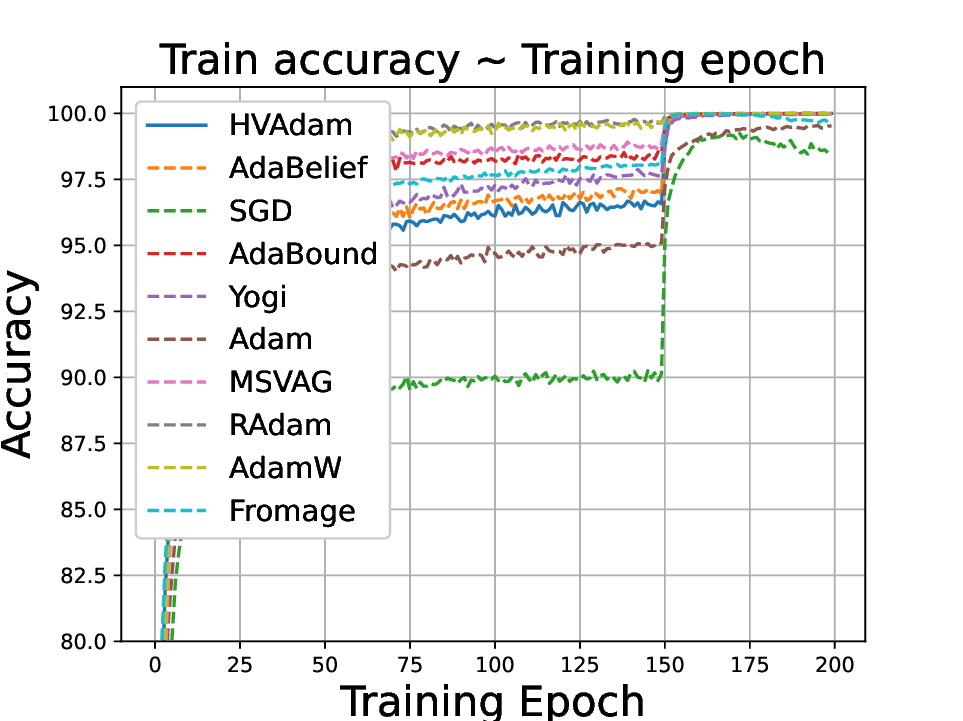
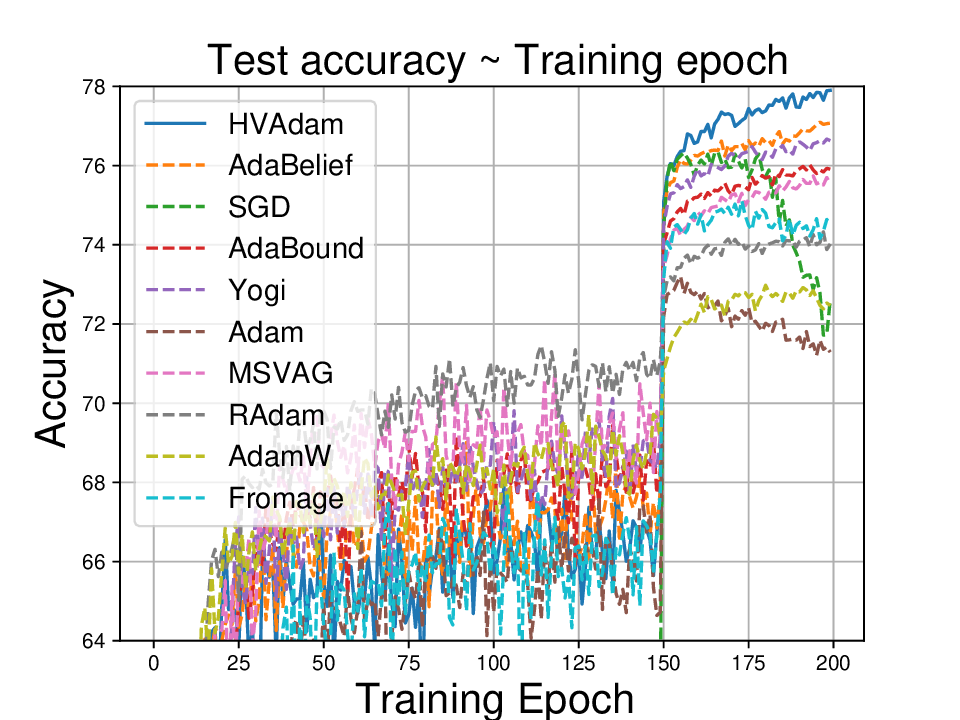
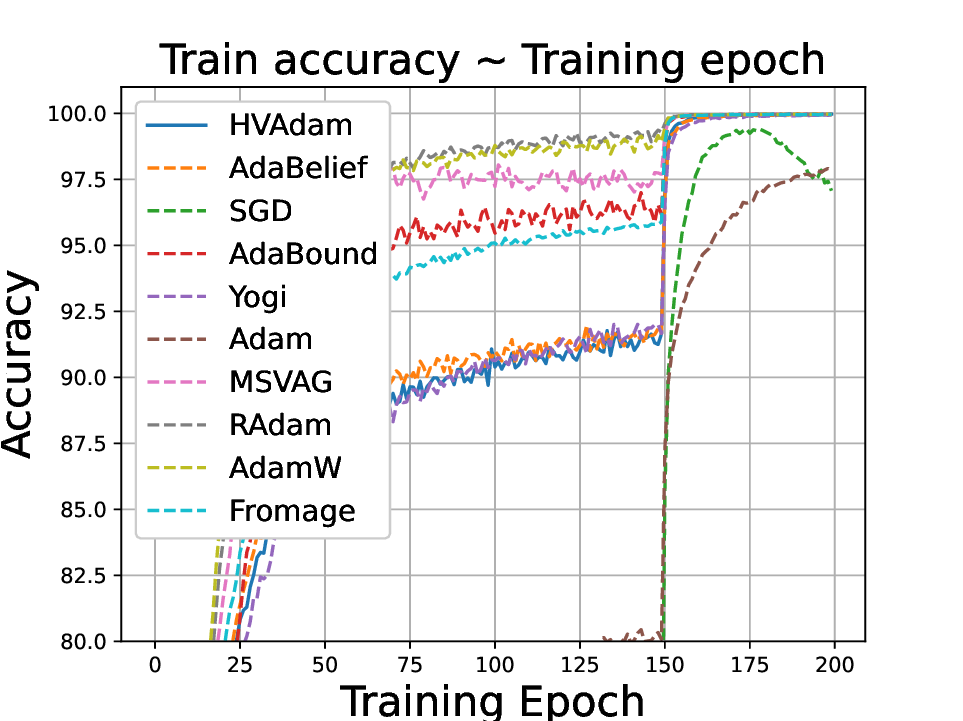
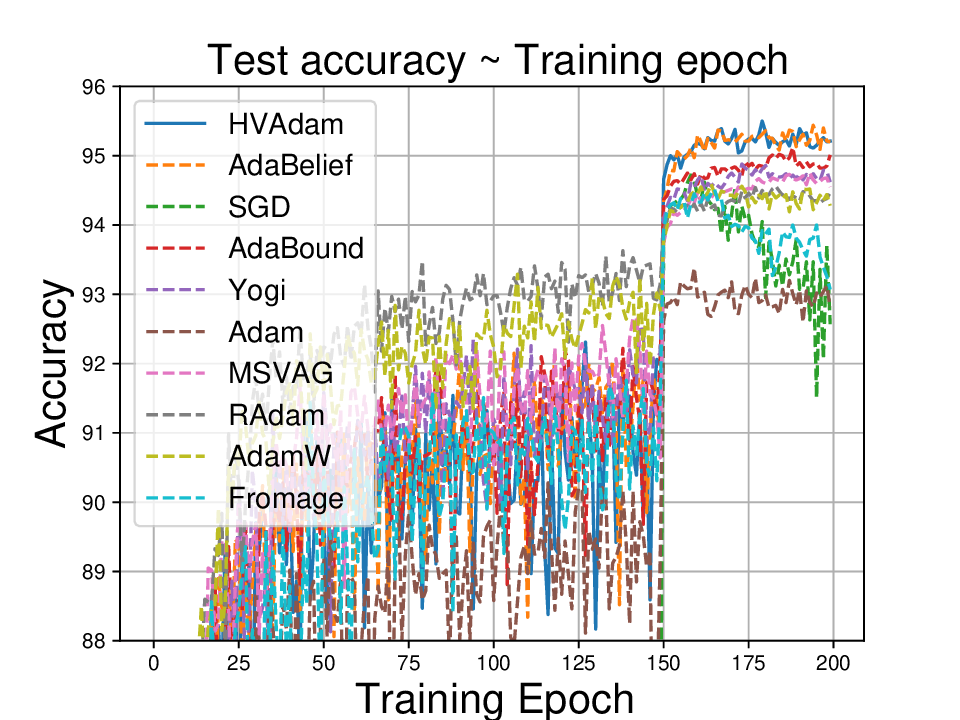
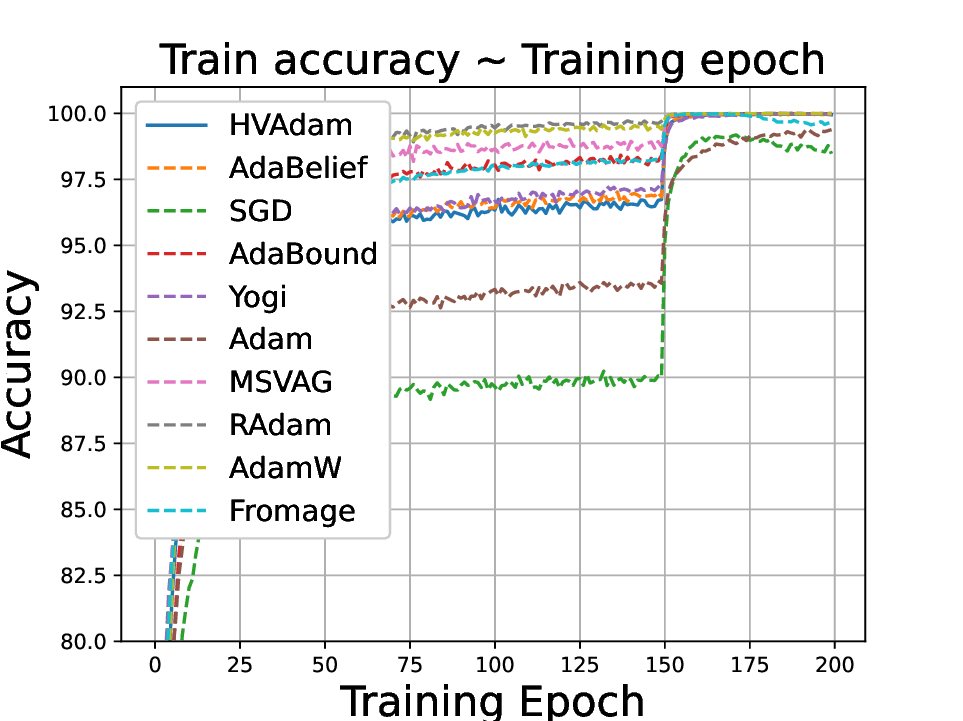
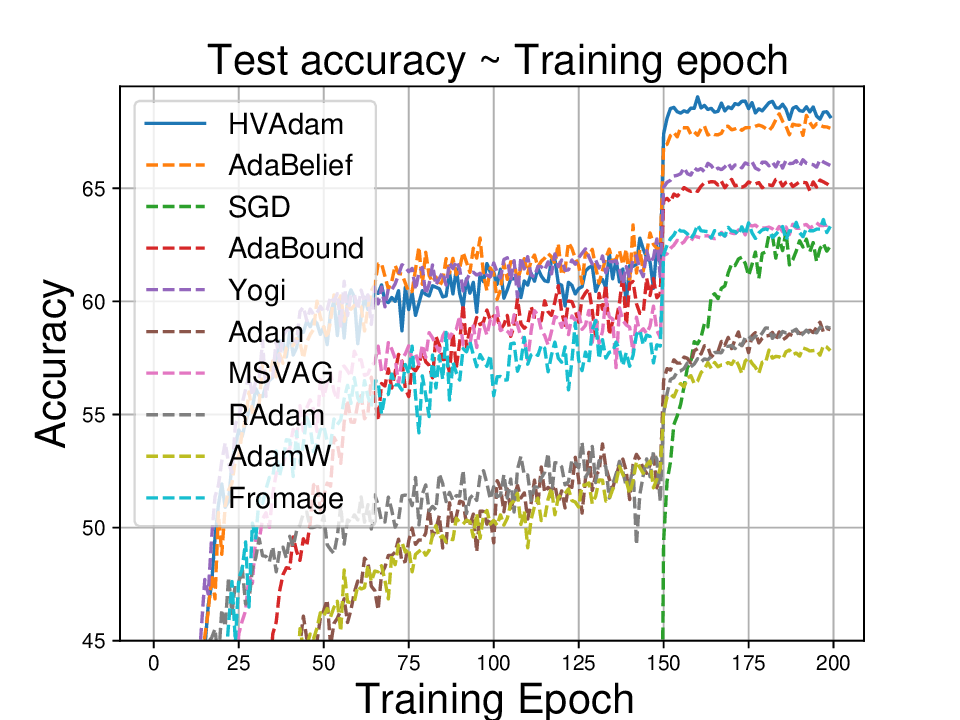
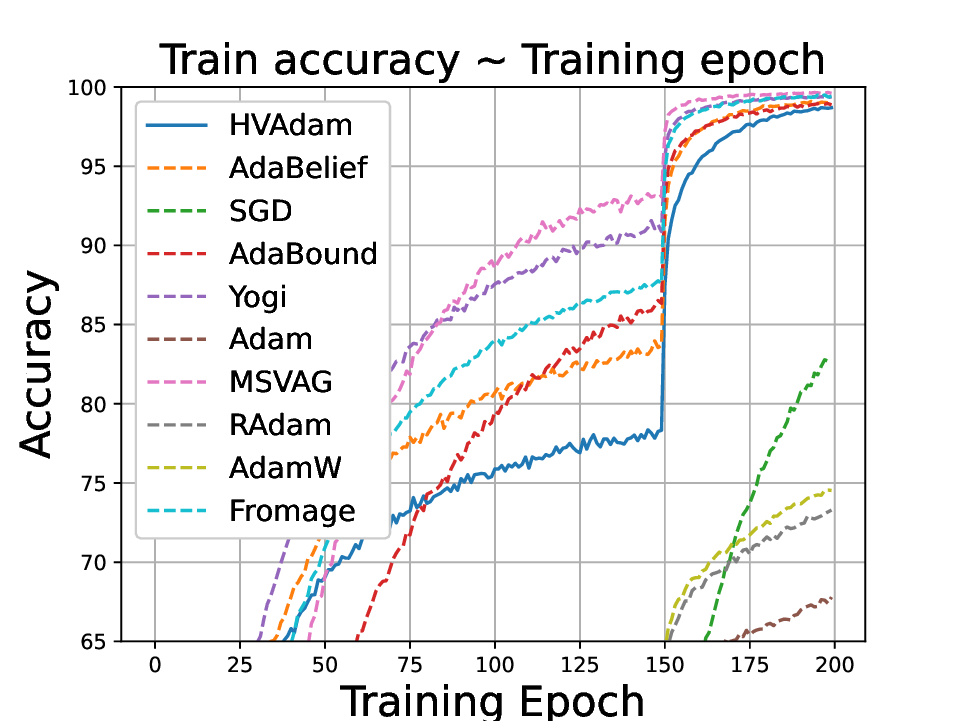
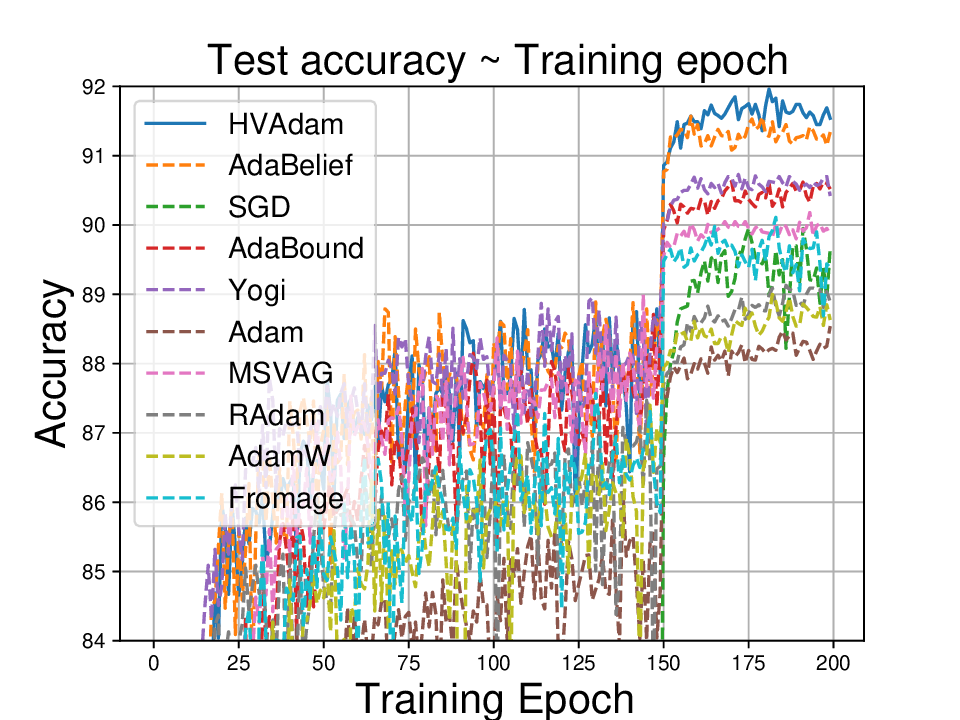
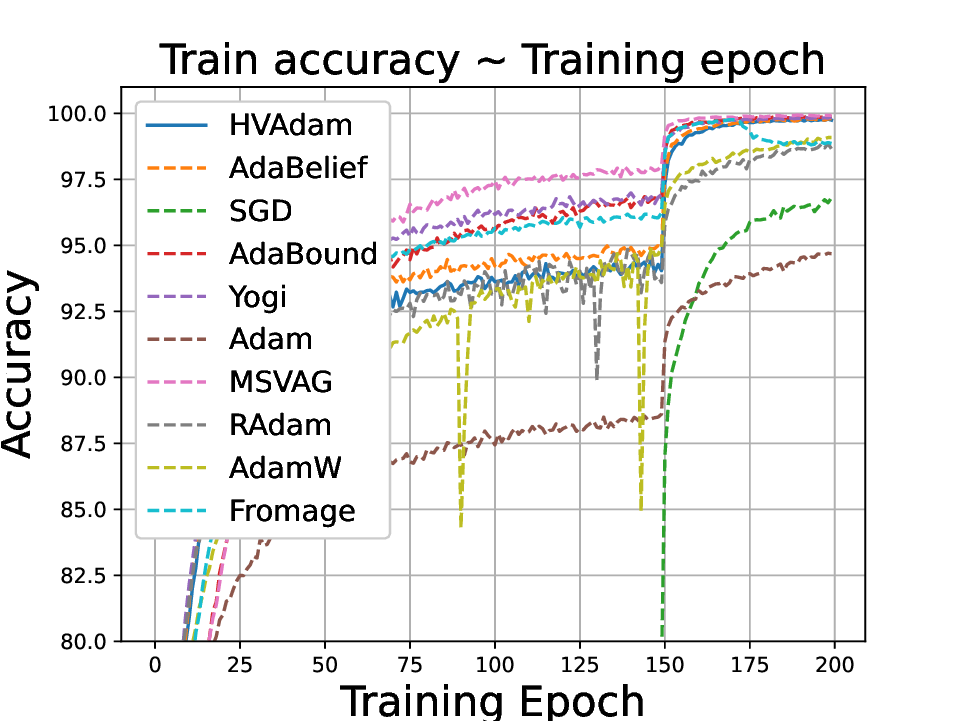
실험적으로는 CIFAR‑10/100, ImageNet 같은 이미지 분류 벤치마크에서 기존 Adam 대비 1.5~2배 빠른 수렴을 보였으며, FID 점수 기준 이미지 생성(GAN)에서는 특히 WGAN‑GP에서 10% 이상 개선된 결과를 기록했다. 자연어 처리에서는 Transformer 기반 언어 모델 학습 시 perplexity 감소 속도가 가속화되고, 최종 성능에서도 미세한 상승을 확인했다. 이러한 결과는 HVAdam이 “학습률 조정”이라는 전통적 개념을 넘어, 손실 지형 전체에 대한 전역적인 정보를 활용함으로써 파라미터 업데이트 효율을 극대화한다는 점을 시사한다.
또한 코드 공개와 함께 구현이 PyTorch와 TensorFlow 양쪽에서 호환되도록 설계되어, 연구자와 엔지니어가 손쉽게 기존 파이프라인에 적용할 수 있다. 다만 공분산 행렬 추정 과정에서 메모리 비용이 증가할 수 있다는 점은 대규모 모델(예: 수억 파라미터) 적용 시 추가적인 최적화가 필요함을 의미한다. 향후 연구에서는 저차원 근사, 스파스 공분산 구조 활용, 그리고 분산 학습 환경에서의 효율적인 동기화 메커니즘을 탐구함으로써 HVAdam의 적용 범위를 더욱 확대할 수 있을 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
Adaptive optimizers such as Adam and RMSProp have gained attraction in complex neural networks, including generative adversarial networks (GANs) and Transformers, thanks to their stable performance and fast convergence compared to non-adaptive optimizers. A frequently overlooked limitation of adaptive optimizers is that adjusting the learning rate of each dimension individually would ignore the knowledge of the whole loss landscape, resulting in slow updates of parameters, invalidating the learning rate adjustment strategy and eventually leading to widespread insufficient convergence of parameters. In this paper, we propose HVAdam, a novel optimizer that associates all dimensions of the parameters to find a new parameter update direction, leading to a refined parameter update strategy for an increased convergence rate. We validated HVAdam in extensive experiments, showing its faster convergence, higher accuracy, and more stable performance on image classification, image generation, and natural language processing tasks. Particularly, HVAdam achieves a significant improvement on GANs compared with other state-of-the-art methods, especially in Wasserstein‑GAN (WGAN) and its improved version with gradient penalty (WGAN‑GP). Code is available at https://github.com/ChihayaAnn/HVAdam.
적응형 옵티마이저인 Adam 및 RMSProp은 복잡한 신경망, 특히 생성적 적대 신경망(GAN)과 Transformer에서 비적응형 옵티마이저에 비해 안정적인 성능과 빠른 수렴 속도로 큰 주목을 받아왔다. 그러나 적응형 옵티마이저는 각 차원의 학습률을 개별적으로 조정함으로써 전체 손실 지형에 대한 정보를 무시하게 되는 흔히 간과되는 한계를 가지고 있다. 이로 인해 파라미터 업데이트가 느려지고, 학습률 조정 전략이 무효화되며, 궁극적으로 파라미터가 충분히 수렴하지 못하는 문제가 발생한다. 본 논문에서는 파라미터의 모든 차원을 연관시켜 새로운 업데이트 방향을 탐색하는 새로운 옵티마이저 HVAdam을 제안한다. HVAdam은 차원 간 상호작용을 고려한 정교한 업데이트 전략을 제공함으로써 수렴 속도를 크게 향상시킨다. 광범위한 실험을 통해 이미지 분류, 이미지 생성, 자연어 처리 과제에서 기존 방법 대비 더 빠른 수렴, 높은 정확도, 그리고 보다 안정적인 성능을 입증하였다. 특히 Wasserstein‑GAN(WGAN) 및 Gradient Penalty를 적용한 개선형 WGAN‑GP와 같은 GAN 모델에서 다른 최첨단 방법들에 비해 현저한 성능 향상을 보였다. 코드는 https://github.com/ChihayaAnn/HVAdam
에서 확인할 수 있다.