긴 꼬리 데이터에서 신경 붕괴 정렬을 통한 성능 향상
📝 원문 정보
- Title: Space Alignment Matters: The Missing Piece for Inducing Neural Collapse in Long-Tailed Learning
- ArXiv ID: 2512.07844
- 발행일: 2025-11-25
- 저자: Jinping Wang, Zhiqiang Gao, Zhiwu Xie
📝 초록 (Abstract)
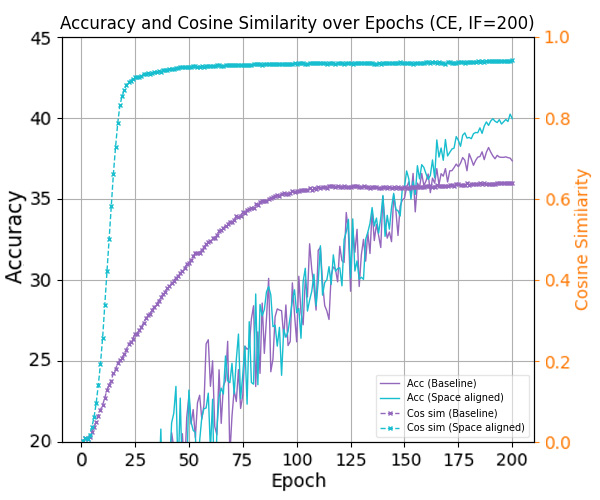
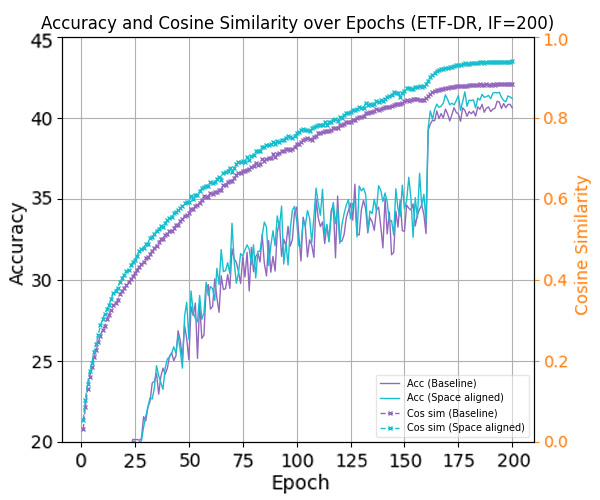
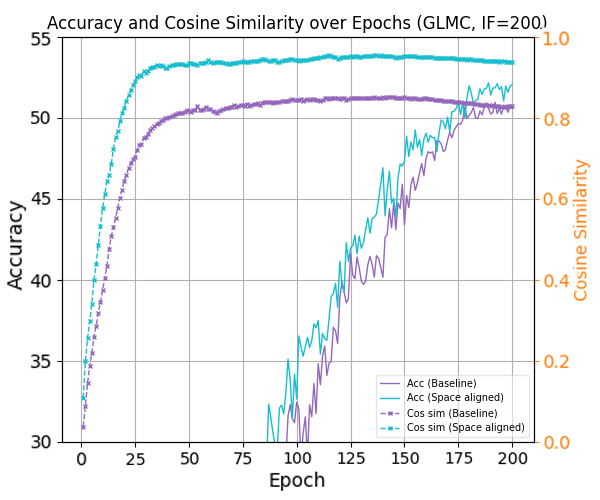
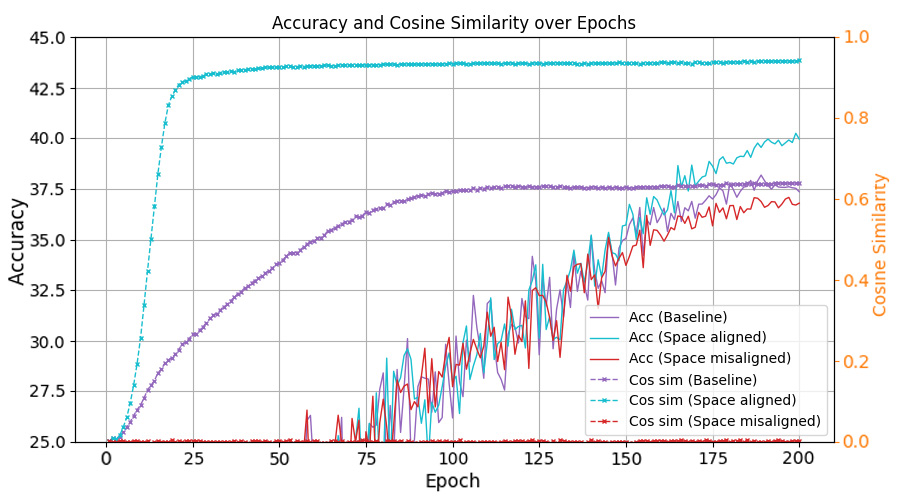
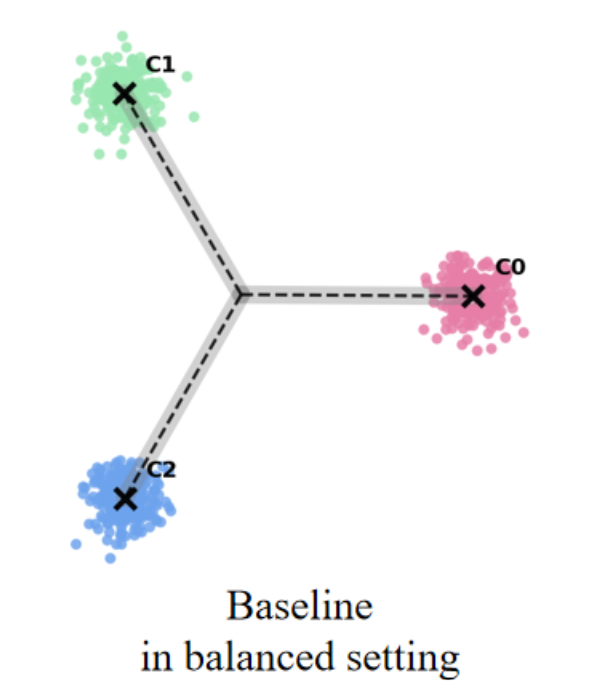
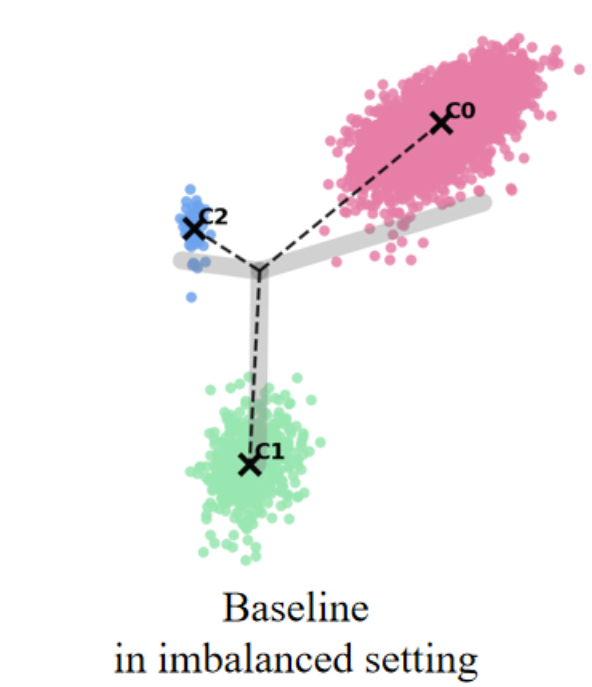
최근 연구들은 클래스가 균형을 이룰 때, 클래스별 특징 평균과 분류기 가중치가 자동으로 단순체 등각 긴밀 프레임(simplex equiangular tight frame, ETF) 형태로 정렬되는 신경 붕괴(Neural Collapse, NC) 현상을 밝혀냈다. 그러나 긴 꼬리(long‑tailed) 상황에서는 심각한 샘플 불균형으로 인해 NC 현상이 억제되어 일반화 성능이 크게 저하된다. 기존 접근법들은 특징이나 분류기 가중치에 제약을 가해 ETF 기하학을 회복하려 하지만, 특징 공간과 분류기 가중치 공간 사이의 명백한 정렬 불일치를 간과한다. 본 논문에서는 이러한 정렬 불일치가 최적 오류 지수(optimal error exponent)에 미치는 악영향을 이론적으로 정량화한다. 이 통찰을 바탕으로, 기존 긴 꼬리 학습 방법에 구조적 변형 없이 바로 적용할 수 있는 세 가지 명시적 정렬 전략을 제안한다. CIFAR‑10‑LT, CIFAR‑100‑LT, ImageNet‑LT 데이터셋에 대한 광범위한 실험 결과, 제안 방법이 모든 베이스라인을 일관되게 향상시키고 최첨단(state‑of‑the‑art) 성능을 달성함을 보여준다.💡 논문 핵심 해설 (Deep Analysis)
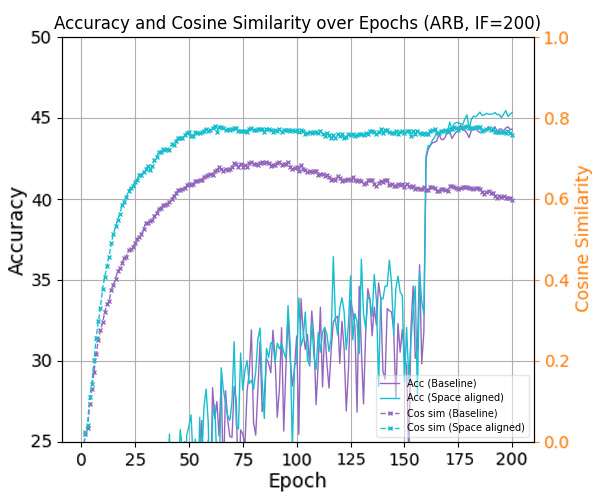
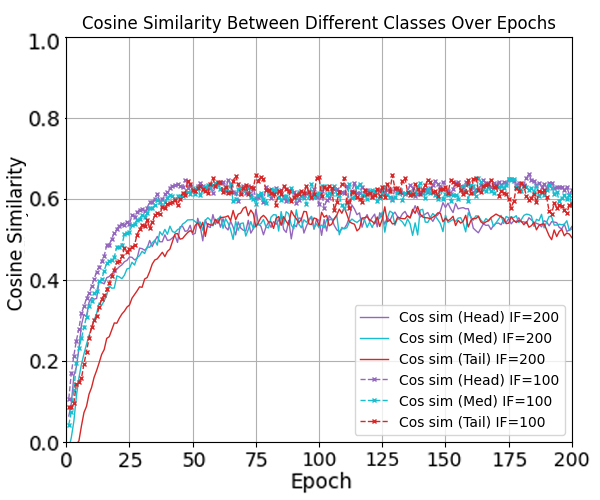
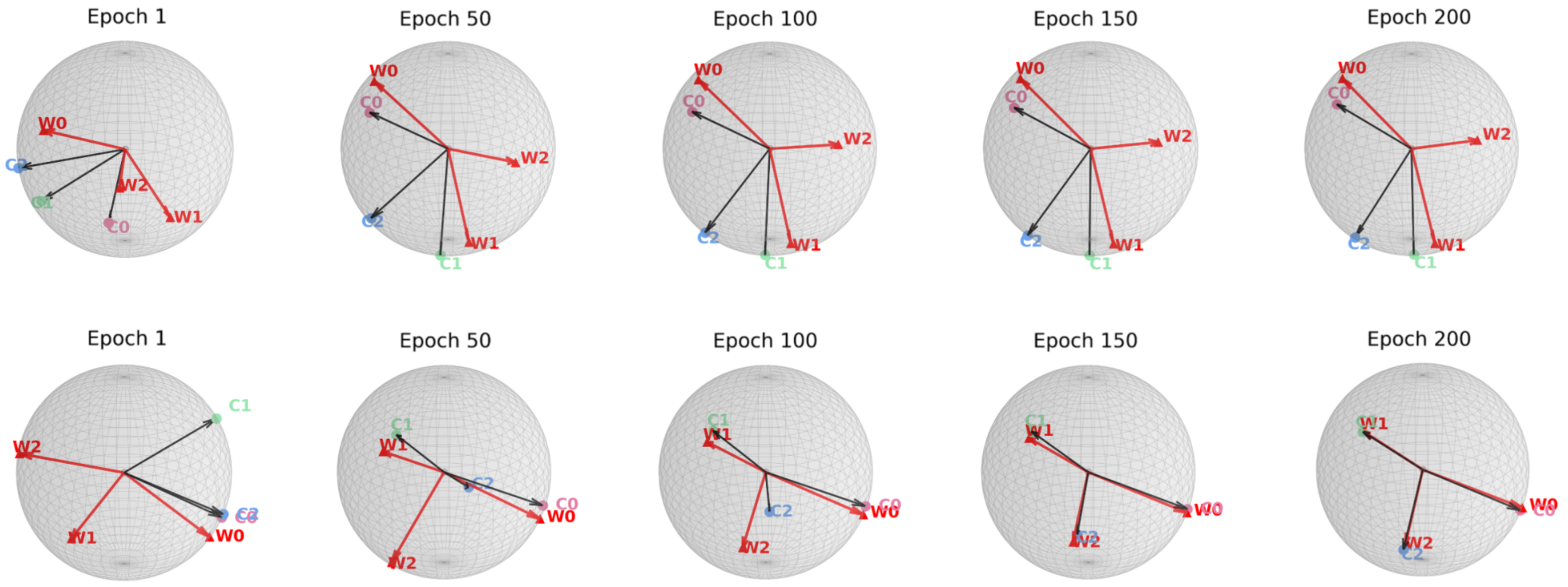
논문은 먼저 정렬 불일치가 오류 지수(error exponent)에 미치는 영향을 ‘최적 오류 지수(optimal error exponent)’라는 정량적 지표를 통해 분석한다. 이 지표는 대규모 샘플 한계에서 베르누이 오류 확률이 지수적으로 감소하는 속도를 나타내며, 정렬이 잘 이루어질수록 지수는 크게 증가한다. 저자는 정렬이 깨진 경우, 특히 소수 클래스의 특징 평균과 분류기 가중치 사이의 각도 차이가 커질수록 오류 지수가 급격히 감소함을 수학적으로 증명한다. 이는 단순히 특징을 정규화하거나 가중치를 재조정하는 수준을 넘어, 두 공간 간의 구조적 정렬 자체가 모델 일반화에 결정적 역할을 함을 의미한다.
이론적 통찰을 바탕으로 제안된 세 가지 정렬 전략은 다음과 같다. 첫째, 특징 공간을 직접 ETF 형태로 투영하는 ‘특징 정렬(Feature Alignment)’ 단계; 둘째, 분류기 가중치를 특징 평균에 맞추어 동적으로 업데이트하는 ‘가중치 정렬(Weight Alignment)’ 메커니즘; 셋째, 두 공간 간의 정렬 정도를 정규화 손실(term)로 명시적으로 최소화하는 ‘정렬 손실(Alignment Loss)’이다. 중요한 점은 이 전략들이 기존 긴 꼬리 학습 프레임워크(예: 재샘플링, 비용 민감 학습, 메타 학습 등)에 플러그인 형태로 삽입될 수 있어, 네트워크 구조나 학습 파이프라인을 변경할 필요가 없다는 것이다. 실험에서는 CIFAR‑10‑LT, CIFAR‑100‑LT, ImageNet‑LT 등 대표적인 긴 꼬리 벤치마크에 대해, 베이스라인 모델에 제안 정렬 모듈을 적용했을 때 Top‑1 정확도가 평균 2~4%p 상승하고, 특히 소수 클래스의 정확도가 크게 개선되는 것을 확인하였다. 이는 정렬 전략이 불균형에 의해 손상된 클래스 간 거리 구조를 복원하고, 보다 균형 잡힌 결정 경계를 형성함을 실증적으로 보여준다. 전체적으로 이 연구는 ‘정렬’이라는 새로운 차원의 접근을 통해 긴 꼬리 문제를 이론과 실험 양면에서 설득력 있게 해결했으며, 향후 불균형 학습, 메타 학습, 그리고 대규모 멀티클래스 문제에 대한 연구에 중요한 방향성을 제시한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리