NNGPT 대형 언어 모델 기반 자가‑개선 AutoML 엔진
📝 원문 정보
- Title: NNGPT: Rethinking AutoML with Large Language Models
- ArXiv ID: 2511.20333
- 발행일: 2025-11-25
- 저자: Roman Kochnev, Waleed Khalid, Tolgay Atinc Uzun, Xi Zhang, Yashkumar Sanjaybhai Dhameliya, Furui Qin, Chandini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Dmitry Ignatov, Radu Timofte
📝 초록 (Abstract)
자기 개선 AI 시스템 구축은 여전히 핵심 과제이다. 본 논문에서는 컴퓨터 비전 분야를 중심으로 대형 언어 모델(LLM)을 자가‑개선 AutoML 엔진으로 전환하는 오픈소스 프레임워크 NNGPT를 제안한다. 기존 프레임워크와 달리 NNGPT는 새로운 모델을 생성함으로써 신경망 데이터셋을 확장하고, 생성‑평가‑자기 개선의 폐쇄‑루프를 통해 LLM을 지속적으로 미세조정한다. 하나의 프롬프트로 아키텍처 합성, 하이퍼파라미터 최적화(HPO), 코드‑인식 정확도·조기 종료 예측, 범위‑폐쇄 PyTorch 블록 합성(NN‑RAG), 강화학습 등 다섯 가지 LLM 기반 파이프라인을 통합한다. LEMUR 데이터셋을 기반으로 재현 가능한 메트릭을 제공하며, NNGPT는 아키텍처, 전처리 코드, 하이퍼파라미터를 검증·실행하고 결과로부터 학습한다. PyTorch 어댑터 덕분에 프레임워크에 구애받지 않으며, NN‑RAG는 1,289개 목표에 대해 73% 실행 가능성을 보이고, 3‑shot 프롬프트는 일반 데이터셋에서 정확도를 향상시킨다. 해시 기반 중복 제거는 수백 번의 실행을 절감한다. 원샷 예측은 탐색 기반 AutoML과 동등한 성능을 내어 시도 횟수를 크게 줄인다. LEMUR 상 HPO는 RMSE 0.60으로 Optuna(0.64)를 앞섰으며, 코드‑인식 예측기는 RMSE 0.14, Pearson r=0.78을 기록한다. 현재까지 5,000개 이상의 검증된 모델을 생성했으며, 코드·프롬프트·체크포인트는 논문 수락 시 공개될 예정이다.💡 논문 핵심 해설 (Deep Analysis)
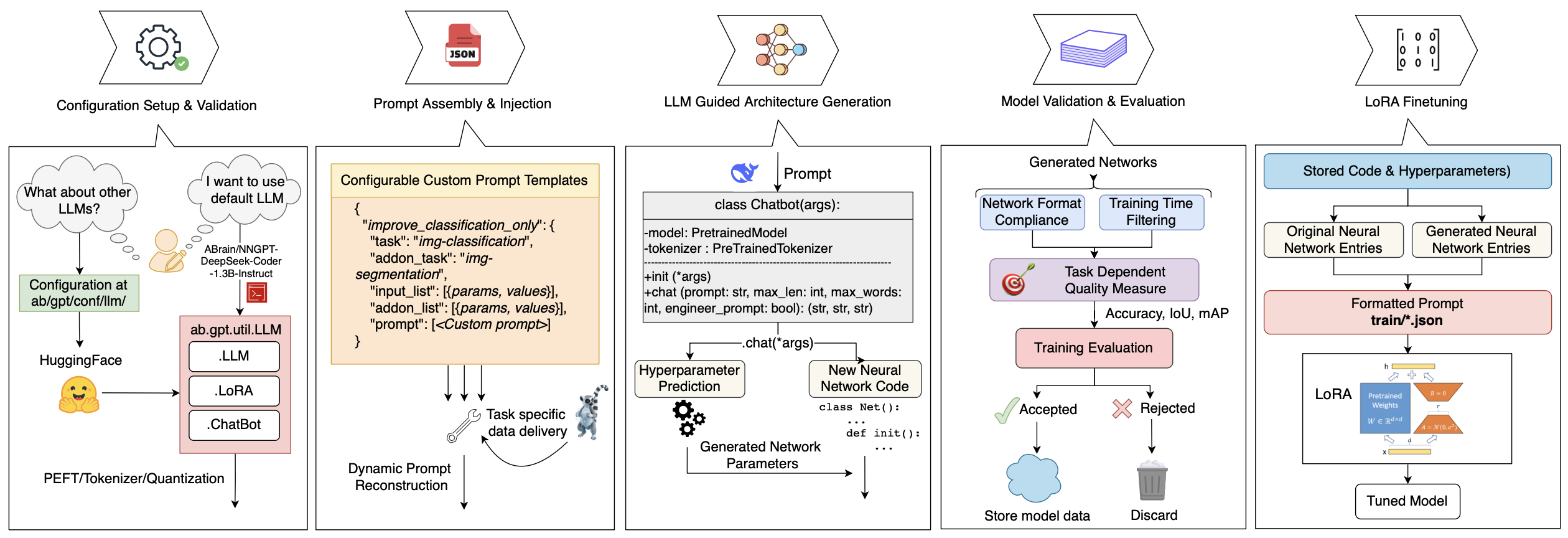
둘째, 논문은 다섯 개의 파이프라인을 제시한다. ‘Zero‑shot 아키텍처 합성’은 사전 학습된 LLM이 새로운 네트워크 토폴로지를 즉시 제시할 수 있음을 보여주지만, 실제 실행 가능성(73%)은 아직 한계가 있음을 의미한다. ‘NN‑RAG’는 Retrieval‑Augmented Generation을 활용해 기존 PyTorch 블록을 재조합하는 방식으로, 코드 재사용성을 높이고 오류를 감소시킨다. 해시 기반 중복 제거는 실험 비용을 크게 절감한다는 실용적 기여가 눈에 띈다.
셋째, 성능 평가에서 제시된 수치는 흥미롭다. LEMUR 데이터셋 상 HPO가 Optuna보다 낮은 RMSE(0.60 vs 0.64)를 기록했으며, 코드‑인식 정확도 예측기가 높은 Pearson 상관계수(r=0.78)를 보인 점은 LLM이 코드와 성능 사이의 복잡한 관계를 어느 정도 파악하고 있음을 암시한다. 특히 ‘원샷 예측’이 탐색 기반 AutoML과 동등한 결과를 내는 점은 실험 횟수를 급감시킬 수 있는 잠재력을 보여준다.
하지만 몇 가지 비판적 시각도 필요하다. 첫째, 실험은 주로 컴퓨터 비전 데이터셋과 LEMUR이라는 자체 구축 코퍼스에 국한돼 있어, 다른 도메인(예: 자연어 처리, 시계열)으로의 일반화 가능성이 검증되지 않았다. 둘째, ‘자기 개선’ 루프에서 LLM이 어떻게 피드백을 받아 파인튜닝되는지 구체적인 학습 스케줄이나 데이터 증강 방법이 상세히 기술되지 않아 재현성이 의문이다. 셋째, 73% 실행 가능성은 아직 27%의 제안이 코드 오류 혹은 실행 불가능 상태임을 의미한다. 이는 실제 엔터프라이즈 환경에서 자동화된 파이프라인을 도입하기엔 위험 요소가 될 수 있다. 마지막으로, 공개 예정인 코드·프롬프트·체크포인트가 실제로 얼마나 문서화되고 사용하기 쉬운지에 따라 커뮤니티 채택이 좌우될 것이다.
종합하면, NNGPT는 LLM을 AutoML의 핵심 엔진으로 전환하려는 혁신적인 시도이며, 특히 생성‑평가‑학습 루프와 Retrieval‑Augmented 코드 합성은 향후 연구에 중요한 영감을 제공한다. 다만 현재 단계에서는 도메인 범위 확대, 실행 안정성 향상, 그리고 재현성을 위한 상세한 구현 공개가 필요하다. 이러한 과제가 해결된다면, NNGPT는 “코드와 모델을 동시에 설계·검증·학습”하는 차세대 AutoML 플랫폼으로 자리매김할 가능성이 크다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리
