시간 시계열 이상 탐지를 위한 문제 지향 평가 지표 분류 체계
📝 원문 정보
- Title: A Problem-Oriented Taxonomy of Evaluation Metrics for Time Series Anomaly Detection
- ArXiv ID: 2511.18739
- 발행일: 2025-11-24
- 저자: Kaixiang Yang, Jiarong Liu, Yupeng Song, Shuanghua Yang, Yujue Zhou
📝 초록 (Abstract)
시간 시계열 이상 탐지는 IoT·사이버 물리 시스템에서 널리 활용되지만, 적용 목적과 메트릭 가정이 다양해 평가가 어려웠다. 본 연구는 기존 메트릭을 “수학적 형태”가 아니라 “해결하고자 하는 평가 과제”에 따라 재해석하는 문제 지향 프레임워크를 제안한다. 20여 개의 대표 메트릭을 (1) 기본 정확도 중심, (2) 시의성 보상, (3) 라벨 불확실성 허용, (4) 인간 감사 비용 패널티, (5) 무작위·점수 부풀림에 대한 강인성, (6) 파라미터‑프리 교차 데이터셋 비교 가능성의 6가지 차원으로 분류하였다. 실제 탐지, 무작위 탐지, 최적 탐지 상황을 시뮬레이션해 각 메트릭의 점수 분포를 비교함으로써 “구별 능력”(meaningful detection vs. random noise)을 정량화했다. 실험 결과, 대부분의 이벤트‑레벨 메트릭은 높은 구별 능력을 보였지만 NAB, Point‑Adjust 등 널리 쓰이는 몇몇 메트릭은 무작위 점수에 취약함을 확인했다. 따라서 메트릭 선택은 작업 목표에 맞춰야 하며, 제안 프레임워크는 기존 메트릭을 이해하고 상황에 맞는 평가 방식을 설계·선정하는 데 유용한 통합적 시각을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
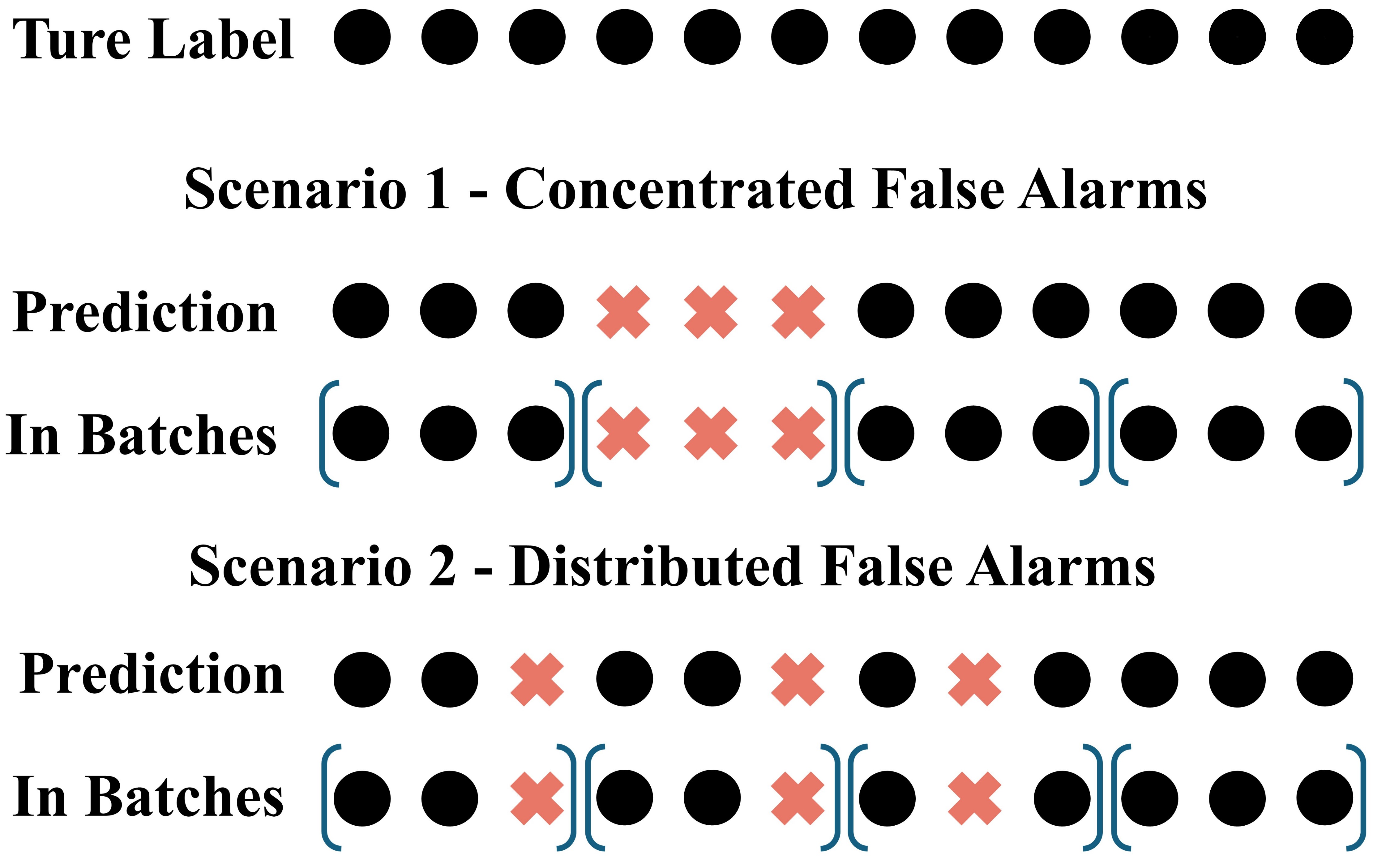
먼저 6가지 차원은 각각 실용적인 요구를 포착한다. (1) 기본 정확도는 전통적인 TP/FP 기반의 성능을, (2) 시의성은 이상이 발생한 시점에 얼마나 빠르게 탐지했는지를 보상한다. (3) 라벨 불확실성은 실제 라벨링이 애매하거나 지연될 때 허용 오차를 제공하며, (4) 인간 감사 비용은 운영자가 이상을 검증하는 데 드는 비용을 패널티로 반영한다. (5) 무작위·점수 부풀림에 대한 강인성은 악의적이거나 실수로 높은 점수를 주는 상황에서도 메트릭이 과도하게 상승하지 않도록 설계되었고, (6) 파라미터‑프리 비교 가능성은 서로 다른 데이터셋 간에 동일한 기준으로 성능을 비교할 수 있게 해준다.
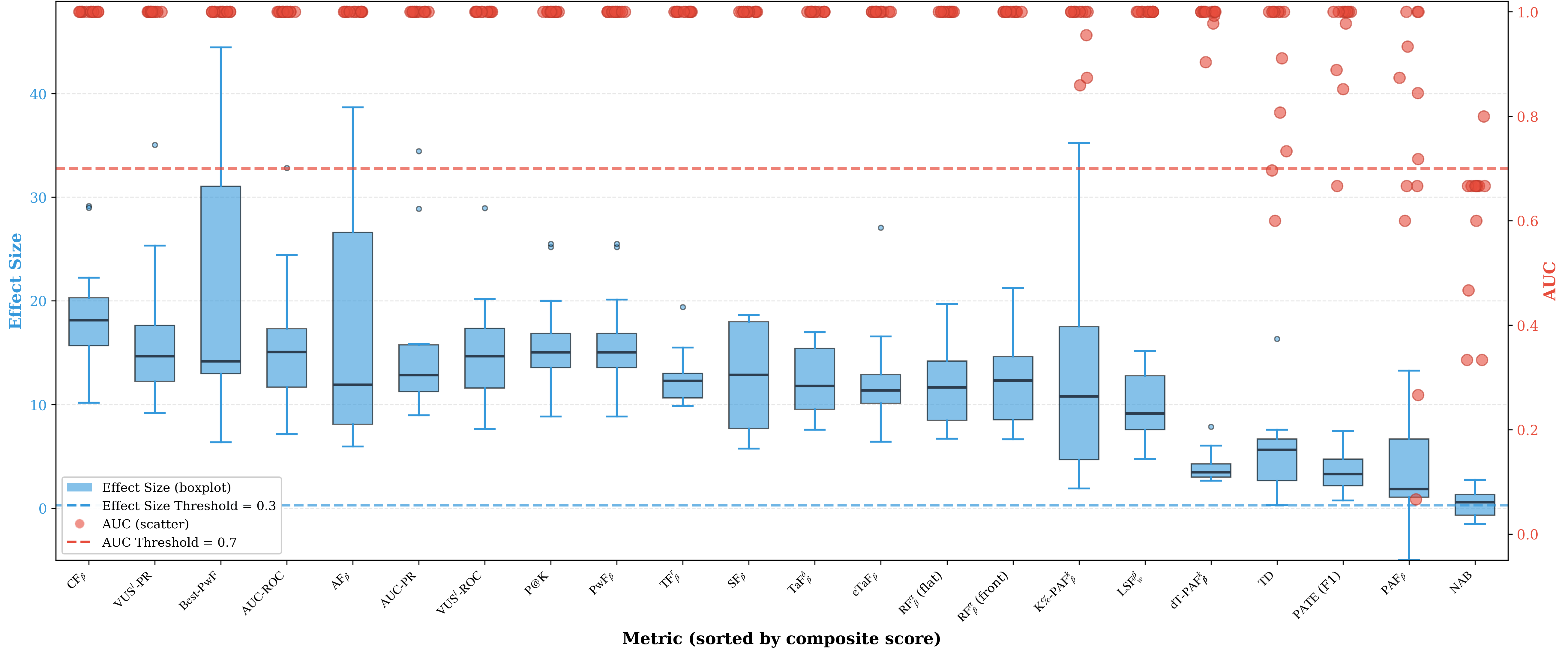
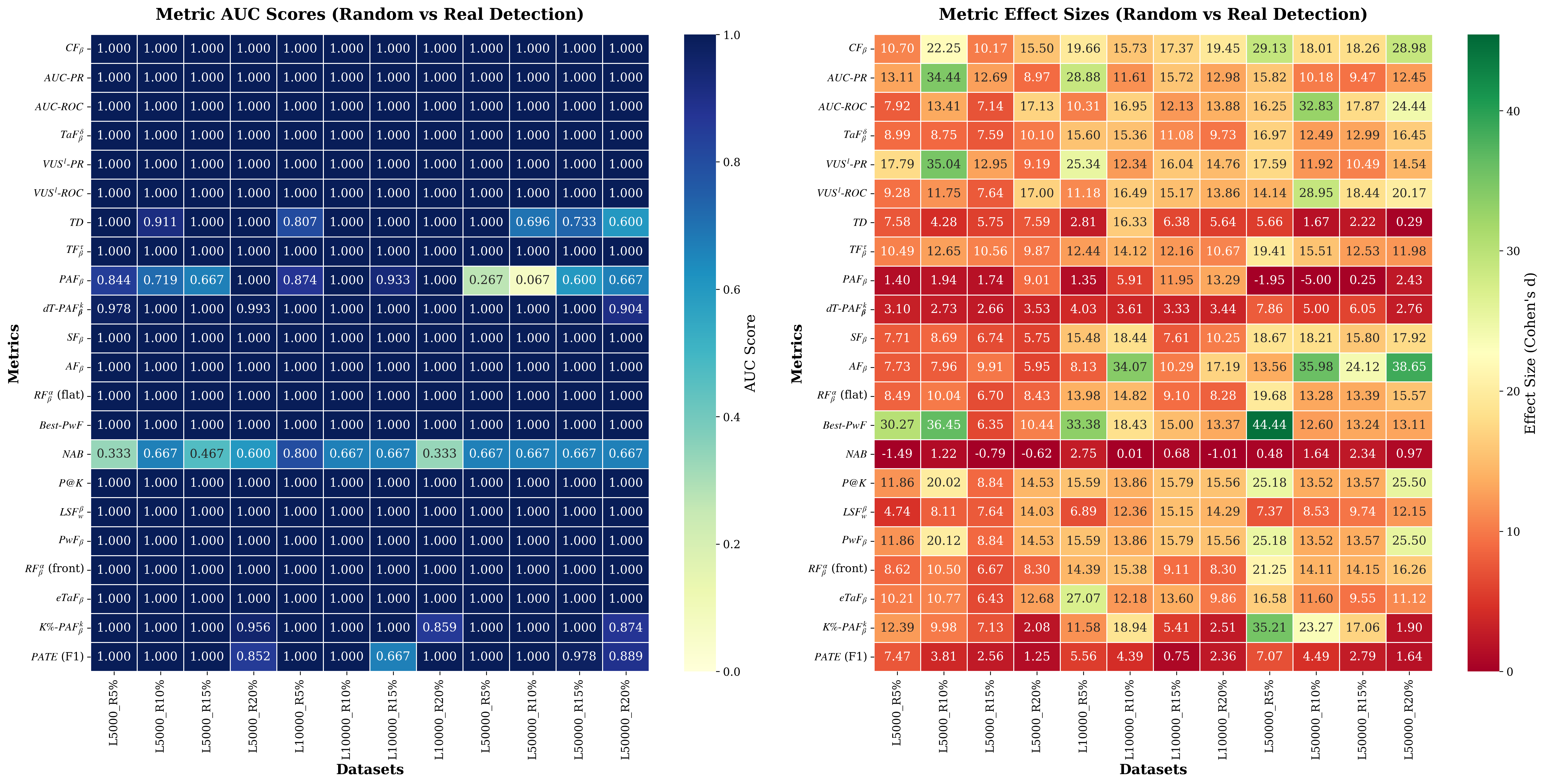
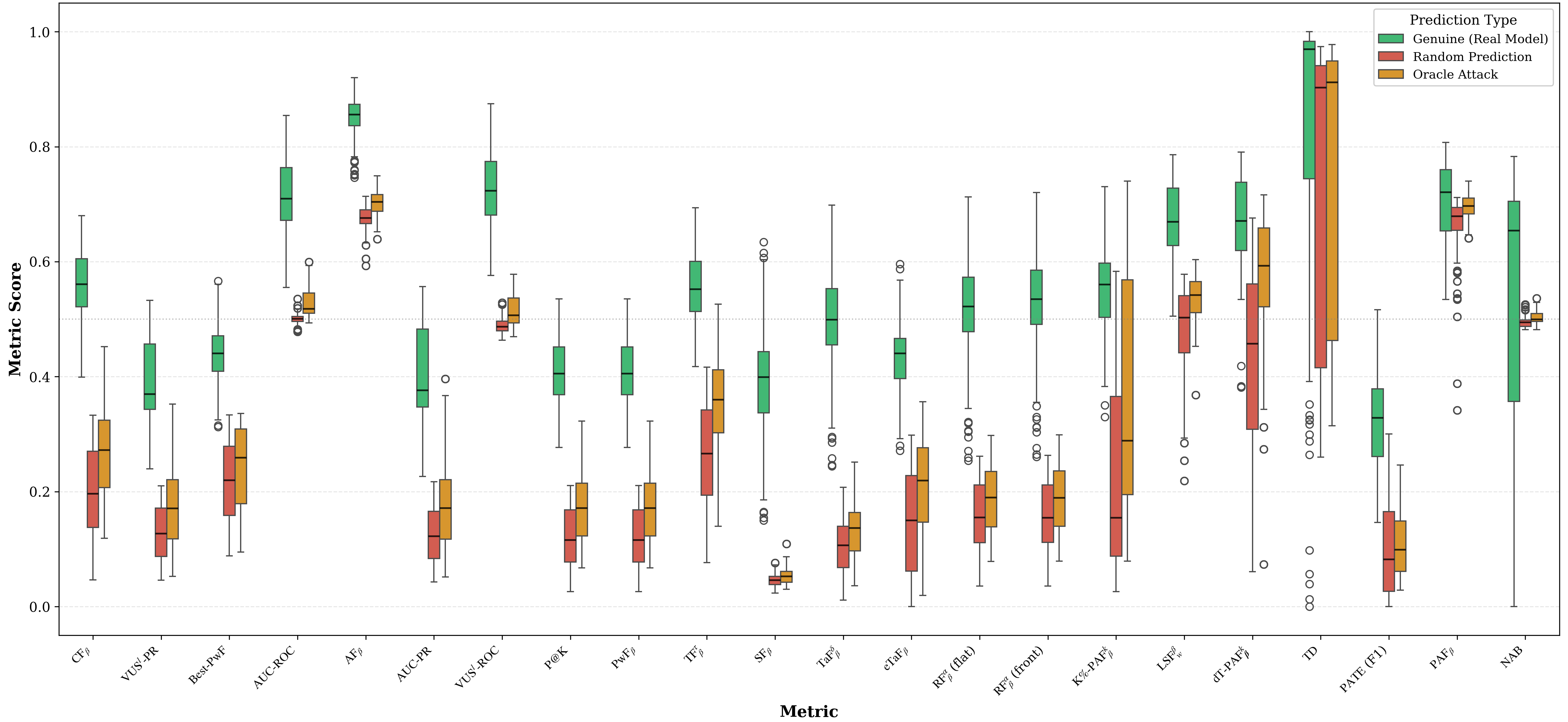
실험 설계는 특히 인상적이다. 저자들은 “진짜 탐지”(genuine), “무작위 탐지”(random), “오라클 탐지”(oracle) 세 가지 시나리오를 만들고, 각 메트릭에 대해 10,000회 이상 반복 샘플링을 수행해 점수 분포를 수집했다. 이를 통해 메트릭의 “구별 능력”(discriminative ability)을 ROC‑like 곡선이 아니라 점수 분포 간의 겹침 정도와 Kullback‑Leibler divergence 등으로 정량화했다. 결과는 기대와 다르게, 널리 쓰이는 NAB와 Point‑Adjust 같은 메트릭이 무작위 점수에 대해 높은 민감도를 보이며, 실제 의미 있는 탐지를 충분히 구별하지 못한다는 것을 보여준다. 반면, 이벤트‑레벨 F1, Precision‑Recall 기반 메트릭은 높은 구별 능력을 유지한다.
이러한 발견은 두 가지 실무적 교훈을 제공한다. 첫째, 평가 목적에 따라 메트릭을 선택해야 한다는 점이다. 예를 들어, 실시간 경보 시스템에서는 시의성을 강조하는 메트릭이 필요하고, 라벨링 비용이 큰 환경에서는 라벨 불확실성을 허용하는 메트릭이 유리하다. 둘째, 메트릭 자체가 공격에 취약할 수 있음을 인식하고, 무작위 점수 부풀림에 강인한 메트릭을 병행 사용하거나, 메트릭 점수에 대한 통계적 검증 절차를 도입해야 한다.
마지막으로, 제안된 프레임워크는 새로운 메트릭을 설계하거나 기존 메트릭을 개선할 때 체크리스트 역할을 할 수 있다. 연구자는 각 차원에 대한 요구사항을 명시하고, 해당 요구를 만족시키는 수식적 변형을 제안함으로써 보다 “컨텍스트‑어웨어”하고 “공정한” 평가 체계를 구축할 수 있다. 이는 특히 IoT와 사이버‑물리 시스템처럼 도메인마다 목표가 크게 다를 수 있는 분야에서 큰 가치를 가진다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리