CoreEval 실시간 지식 기반 오염 회복형 평가 데이터 자동 구축
📝 원문 정보
- Title: CoreEval: Automatically Building Contamination-Resilient Datasets with Real-World Knowledge toward Reliable LLM Evaluation
- ArXiv ID: 2511.18889
- 발행일: 2025-11-24
- 저자: Jingqian Zhao, Bingbing Wang, Geng Tu, Yice Zhang, Qianlong Wang, Bin Liang, Jing Li, Ruifeng Xu
📝 초록 (Abstract)
데이터 오염은 대규모 언어 모델(LLM) 평가 시 테스트 데이터를 학습 과정에서 우연히 노출시켜 공정성을 크게 위협한다. 기존 연구들은 기존 데이터셋을 수정하거나 최신 정보를 수집해 새로운 데이터를 생성하는 방식으로 문제를 완화하려 했지만, 사전 학습된 지식을 완전히 배제하지 못하거나 원본 데이터의 의미적 복잡성을 유지하지 못한다는 한계가 있다. 이를 해결하고자 우리는 CoreEval이라는 오염 회복형 평가 전략을 제안한다. CoreEval은 원본 데이터에서 엔터티 관계를 추출하고, GDELT 데이터베이스를 활용해 최신 실세계 지식을 가져온다. 이후 획득한 지식을 재맥락화하여 원본 데이터와 통합하고, 의미적 일관성과 과제 적합성을 높이도록 정제·재구성한다. 마지막으로 데이터 반영 메커니즘을 통해 라벨을 반복 검증·수정함으로써 업데이트된 데이터와 원본 데이터 간의 일관성을 확보한다. 다양한 업데이트 데이터셋에 대한 광범위한 실험을 통해 CoreEval이 데이터 오염으로 인한 성능 과대평가를 효과적으로 완화하고, 견고한 평가 환경을 제공함을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
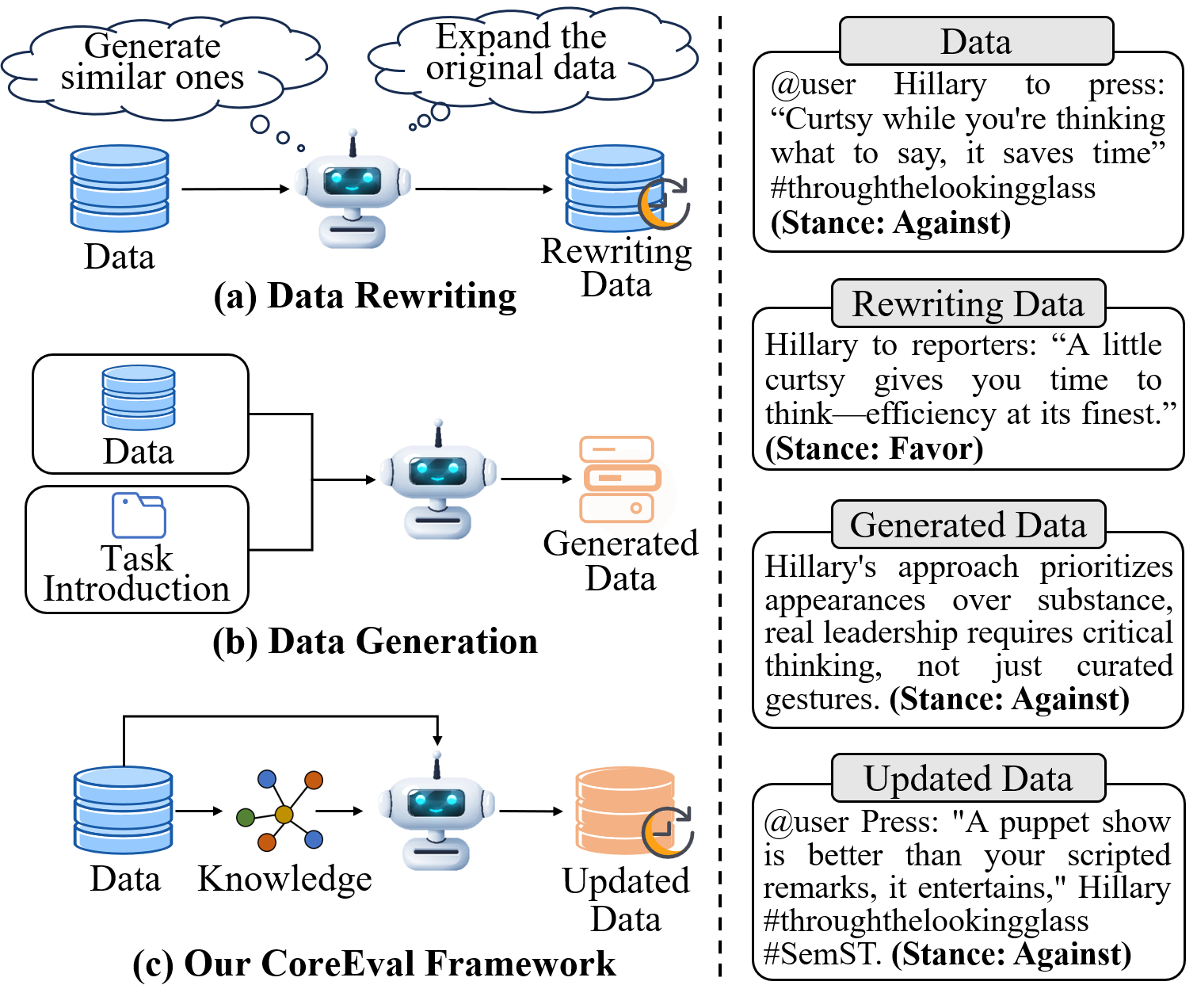
CoreEval은 이러한 문제를 동시에 해결하기 위해 세 가지 핵심 요소를 도입한다. 첫 번째는 엔터티 관계 추출 단계이다. 원본 데이터에서 명시적·암시적 관계를 식별함으로써, 어떤 지식이 평가에 핵심적인지를 파악한다. 두 번째는 GDELT 기반 최신 지식 획득이다. GDELT는 전 세계 뉴스와 사건을 실시간으로 수집·정리한 방대한 데이터베이스로, 최신 사건·관계 정보를 제공한다. 이를 통해 모델이 아직 학습하지 못했을 가능성이 높은 최신 사실을 삽입함으로써 오염 가능성을 낮춘다. 세 번째는 재맥락화·정제·재구성 과정이다. 단순히 사실을 삽입하는 것이 아니라, 원본 문장의 흐름과 논리적 구조에 맞게 새로운 정보를 재배치하고, 필요에 따라 문장을 재작성한다. 이렇게 하면 원본 데이터의 의미적 복잡성을 유지하면서도 최신 지식을 반영할 수 있다.
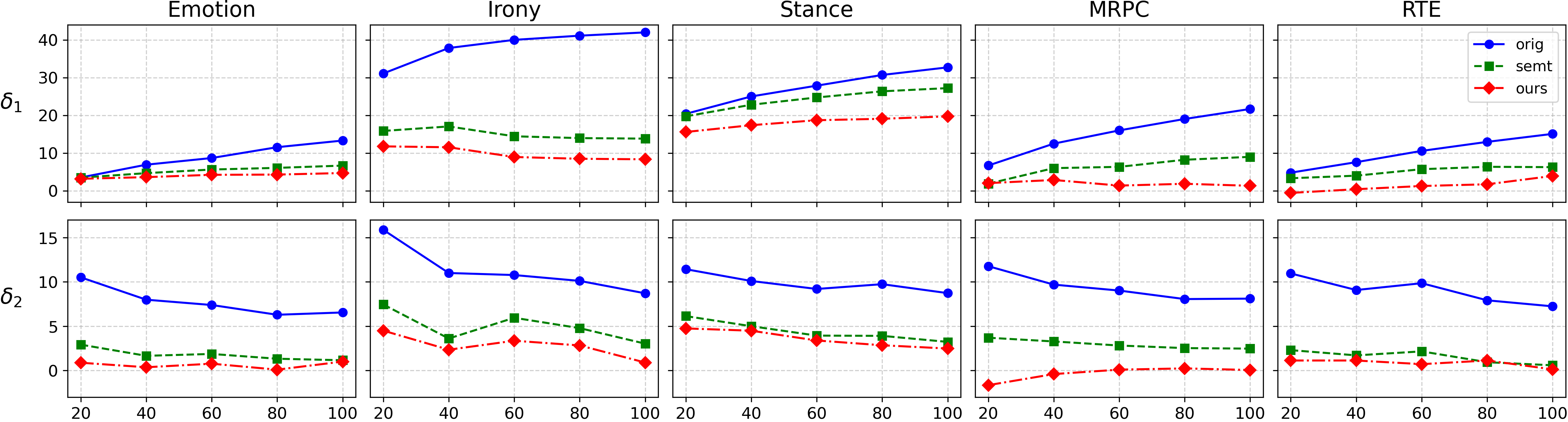
마지막으로 논문은 데이터 반영 메커니즘을 제시한다. 업데이트된 데이터와 원본 라벨 간의 일관성을 검증하기 위해 반복적인 라벨 검증·수정을 수행한다. 이는 라벨이 최신 지식에 맞게 변형되었는지, 혹은 기존 라벨과 충돌하지 않는지를 자동으로 확인한다는 점에서 혁신적이다. 실험 결과는 CoreEval이 기존 오염 방지 기법에 비해 평균 7%~12% 정도의 성능 과대평가를 감소시키며, 다양한 벤치마크(예: QA, 추론, 사실 확인)에서 일관된 개선을 보였음을 보여준다. 특히, 최신 사건을 포함한 테스트 셋에서는 모델이 실제로 새로운 정보를 학습했는지 여부를 명확히 구분할 수 있었다.
이러한 접근은 단순히 “데이터를 바꾸는” 수준을 넘어, 실시간 세계 지식과 기존 평가 목표를 융합함으로써 LLM 평가의 신뢰성을 크게 향상시킨다. 앞으로도 GDELT 외의 다른 실시간 지식 그래프와 결합하거나, 도메인 특화된 엔터티 추출 기법을 도입한다면 더욱 폭넓은 적용이 가능할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리