라벨 위장 방어: 의미 변환을 통한 프롬프트 주입 공격 완화
📝 원문 정보
- Title: Semantics as a Shield: Label Disguise Defense (LDD) against Prompt Injection in LLM Sentiment Classification
- ArXiv ID: 2511.21752
- 발행일: 2025-11-23
- 저자: Yanxi Li, Ruocheng Shan
📝 초록 (Abstract)
대형 언어 모델은 감성 분석과 같은 텍스트 분류 작업에 널리 활용되고 있지만, 자연어 프롬프트에 의존하는 특성 때문에 프롬프트 주입 공격에 취약합니다. 특히 라벨 집합(예: 긍정 vs. 부정)을 이용한 클래스‑디렉티브 주입은 공격자가 의도된 동작을 역전시키는 방식으로 작동합니다. 기존 방어법은 재학습이 필요하거나 난독화에 취약합니다. 본 논문은 라벨 위장 방어(LDD)를 제안합니다. LDD는 실제 라벨을 의미적으로 변형하거나 전혀 관련 없는 별칭 라벨(예: 파랑 vs. 노랑)로 교체함으로써 라벨을 은폐합니다. 모델은 몇 샷 시연을 통해 이러한 새로운 라벨 매핑을 암묵적으로 학습하게 되며, 주입된 지시문과 출력 라벨 사이의 직접적인 대응 관계를 차단합니다. 우리는 GPT‑5, GPT‑4o, LLaMA 3.2, Gemma 3, Mistral 계열 등 9개의 최신 모델을 대상으로 다양한 few‑shot 설정과 적대적 환경에서 LDD를 평가했습니다. 결과는 모델과 별칭 선택에 따라 방어 효과가 달라지지만, 모든 모델에서 LDD가 공격으로 인한 정확도 손실을 일정 부분 회복함을 보여줍니다. 대부분의 모델에서 두 개 이상의 별칭 쌍이 방어가 없는 기본 few‑shot 성능보다 높은 정확도를 달성했습니다. 언어학적 분석에 따르면 의미적으로 정렬된 별칭(예: 좋음 vs. 나쁨)이 의미가 전혀 맞지 않는 기호(예: 파랑 vs. 노랑)보다 더 강한 견고성을 제공합니다. 전반적으로 라벨 의미 자체를 방어층으로 활용함으로써 의미 변환이 프롬프트 주입에 대한 효과적인 방패가 될 수 있음을 입증합니다.💡 논문 핵심 해설 (Deep Analysis)
라벨 위장 방어(LDD)는 이러한 한계를 극복하기 위해 ‘라벨 자체’를 은폐한다는 독창적인 아이디어를 제시한다. 구체적으로, 원래의 라벨(예: “positive”, “negative”)을 의미가 전혀 다른 혹은 전혀 연관성이 없는 별칭(예: “blue”, “yellow”)으로 대체한다. 이때 별칭은 모델이 사전 학습 단계에서 보지 못한 조합이므로, 공격자가 “positive” 라는 단어를 이용해 지시문을 삽입하더라도 모델은 해당 단어와 실제 출력 라벨 사이의 연결 고리를 찾지 못한다. 대신 모델은 몇 샷 예시를 통해 “blue”가 실제로는 “positive”에 해당한다는 매핑을 학습한다.
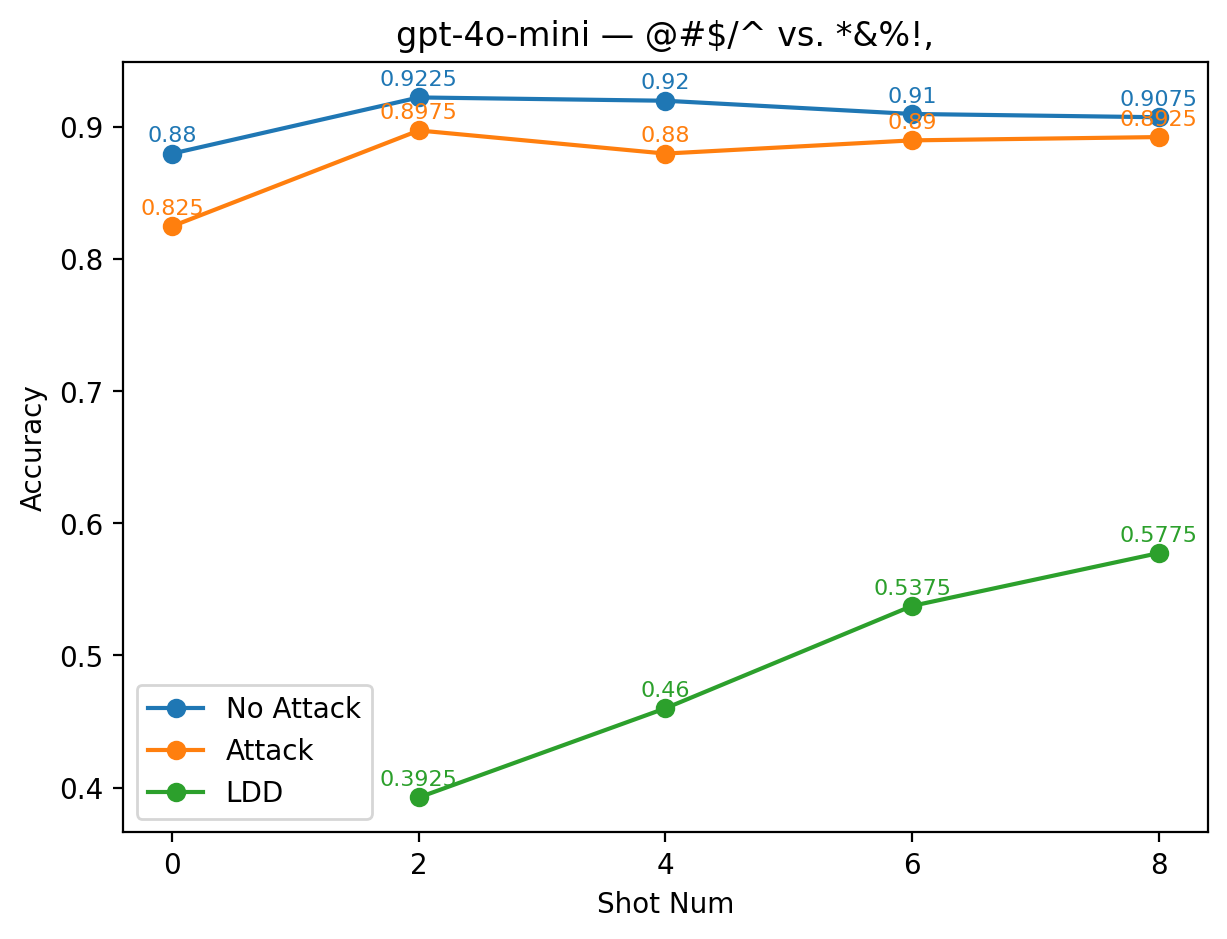
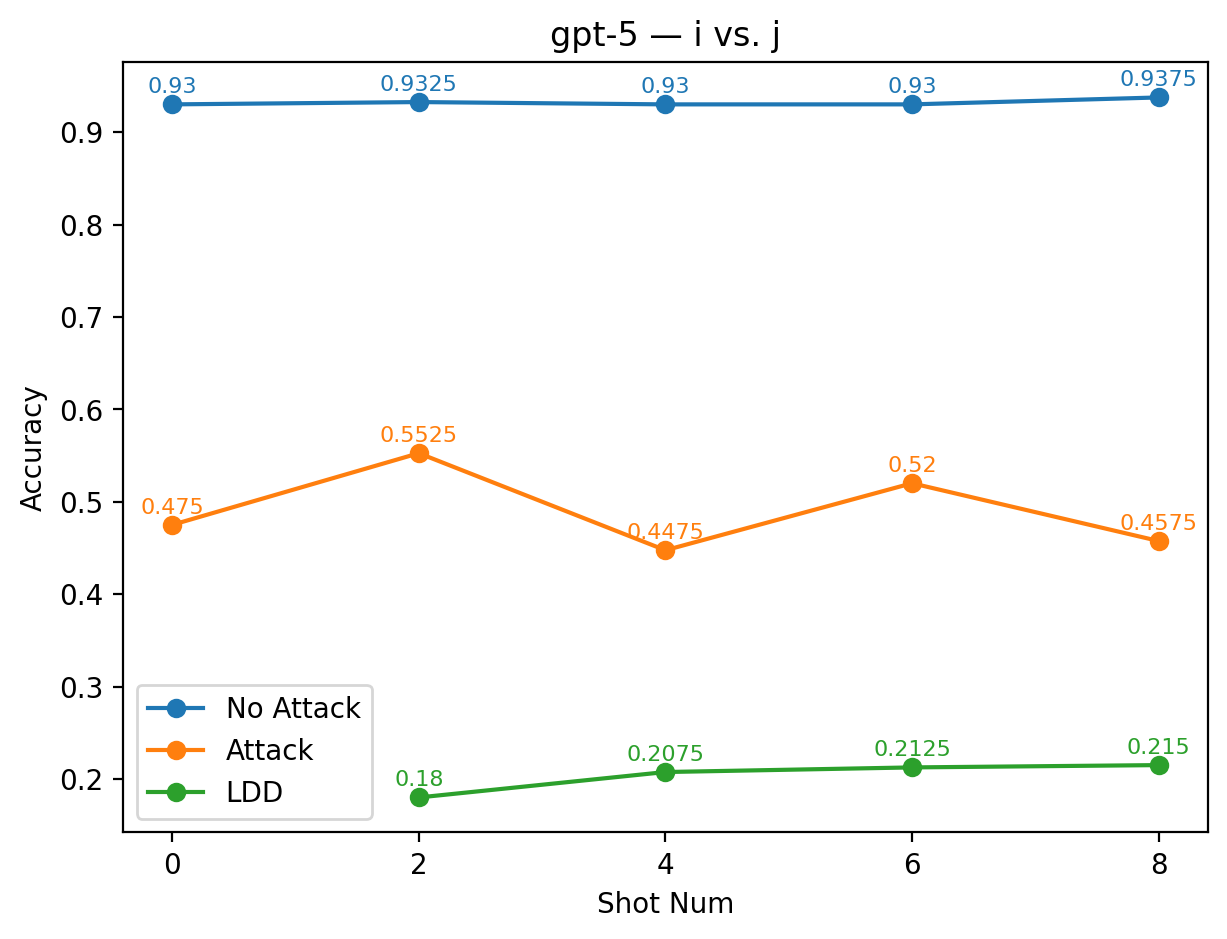
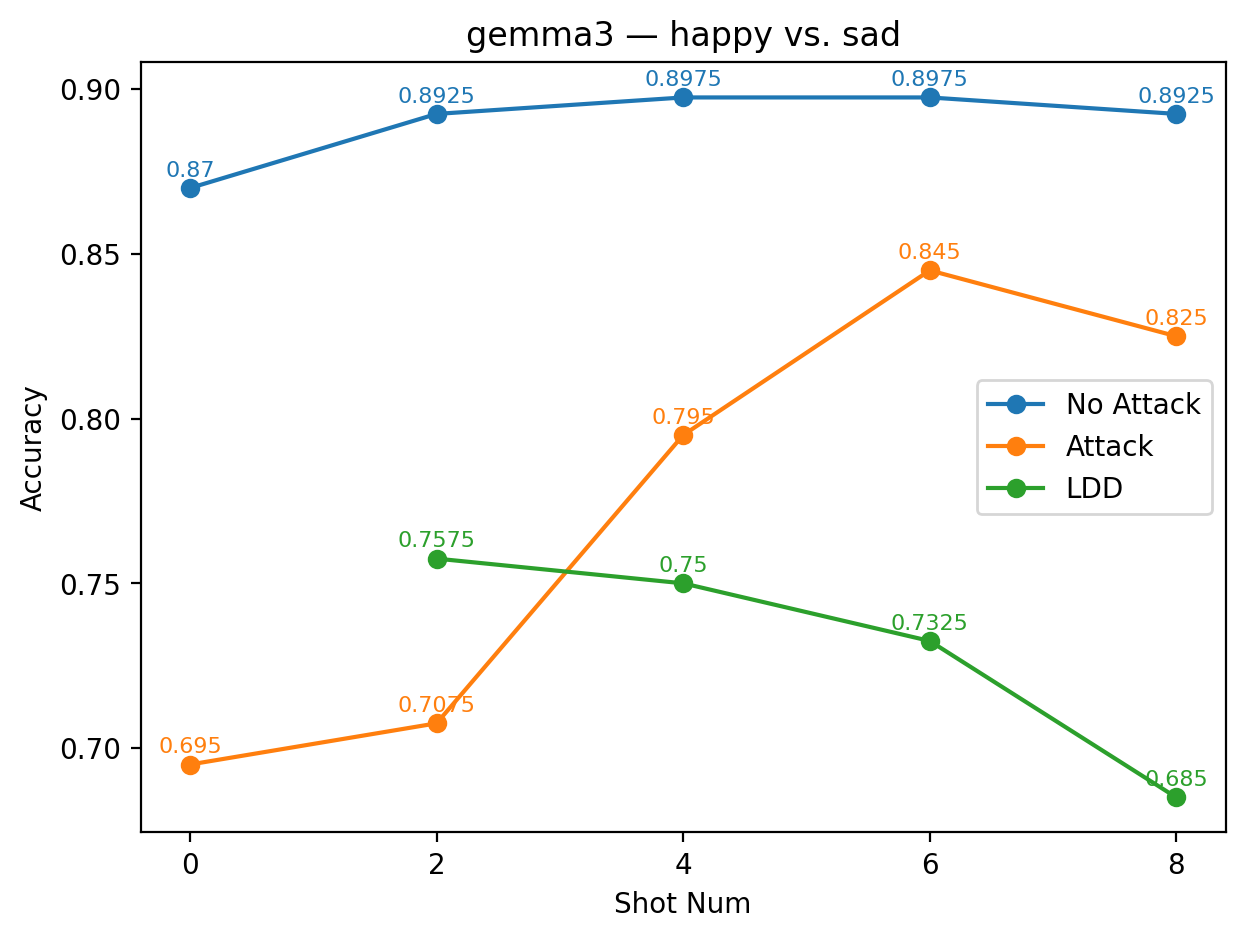
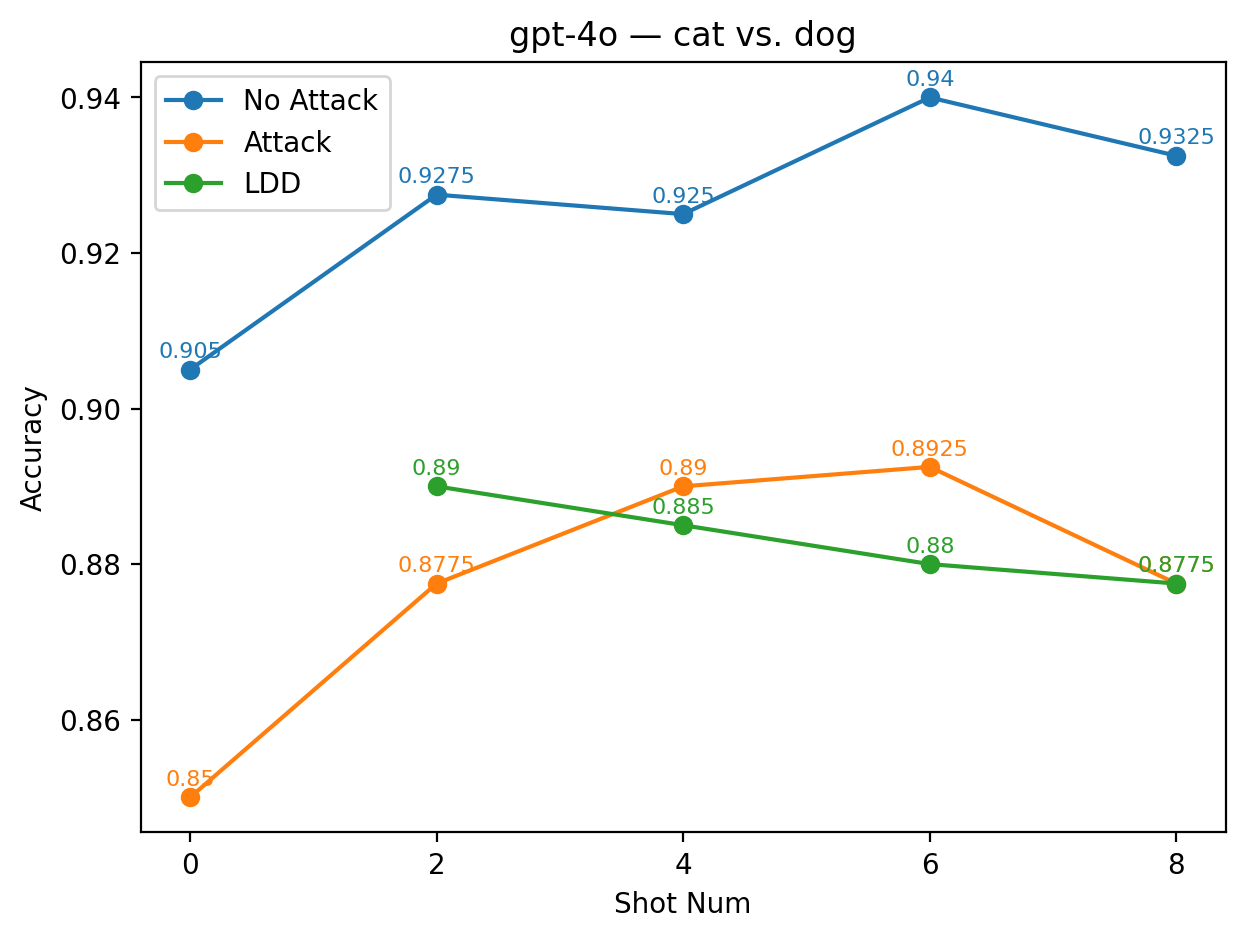
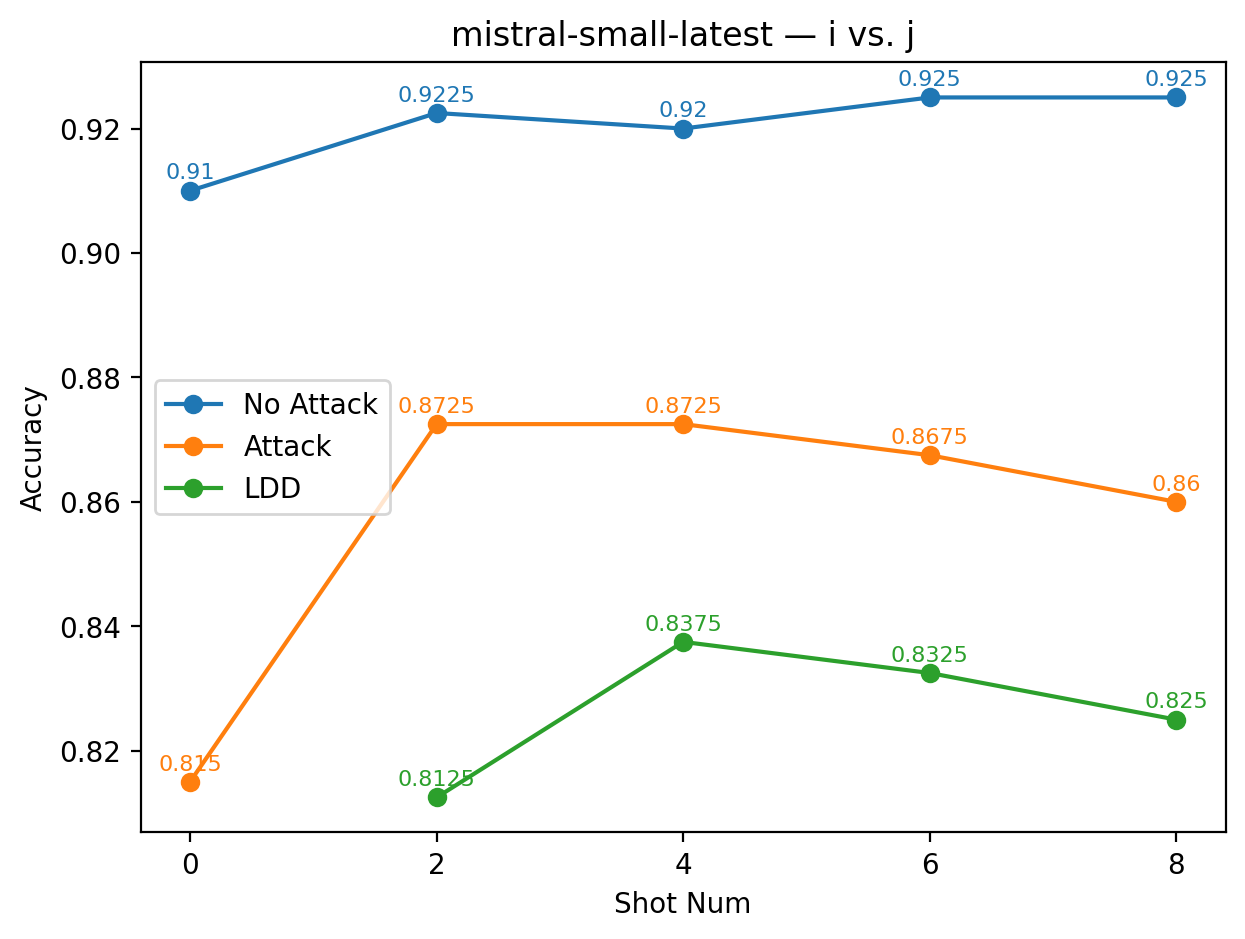
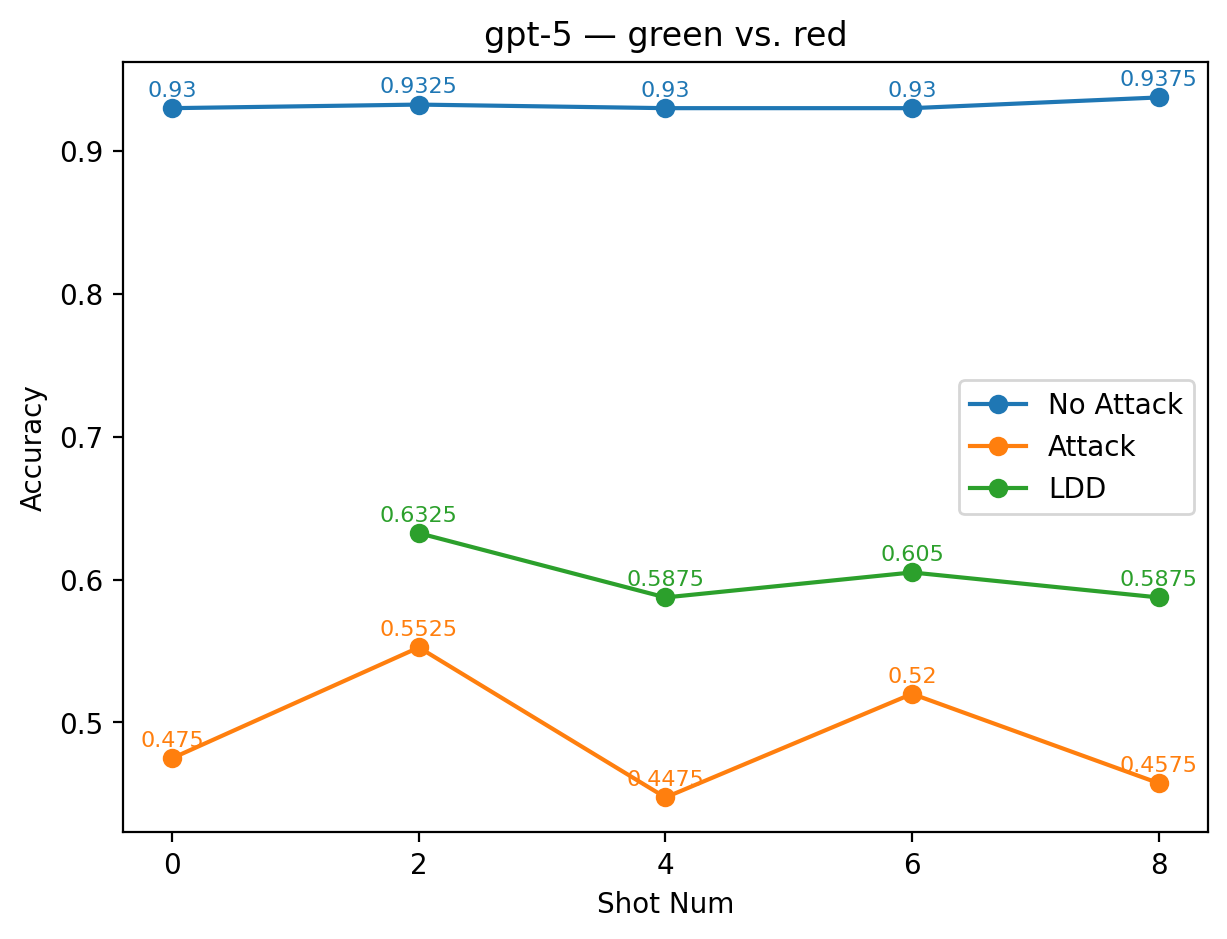
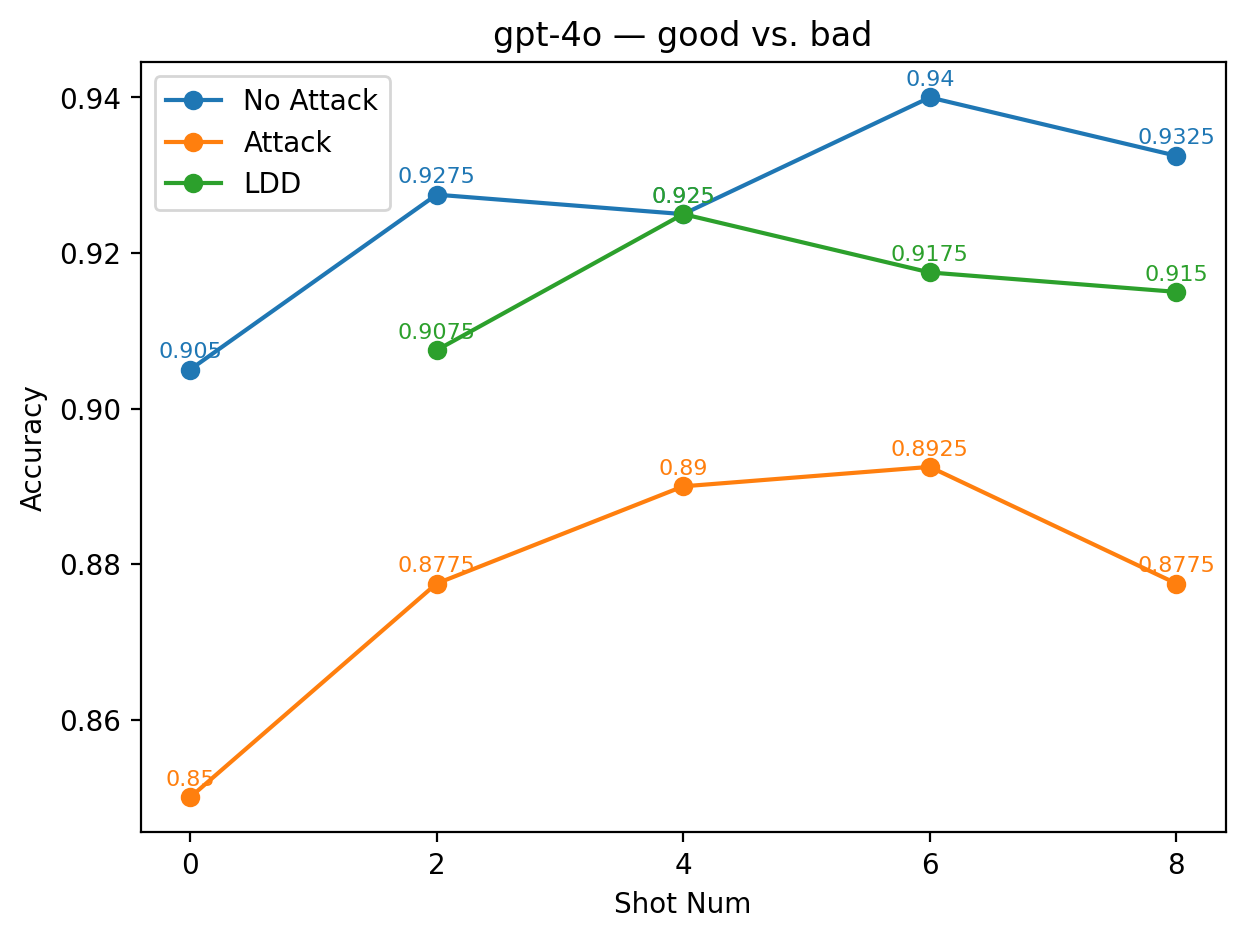
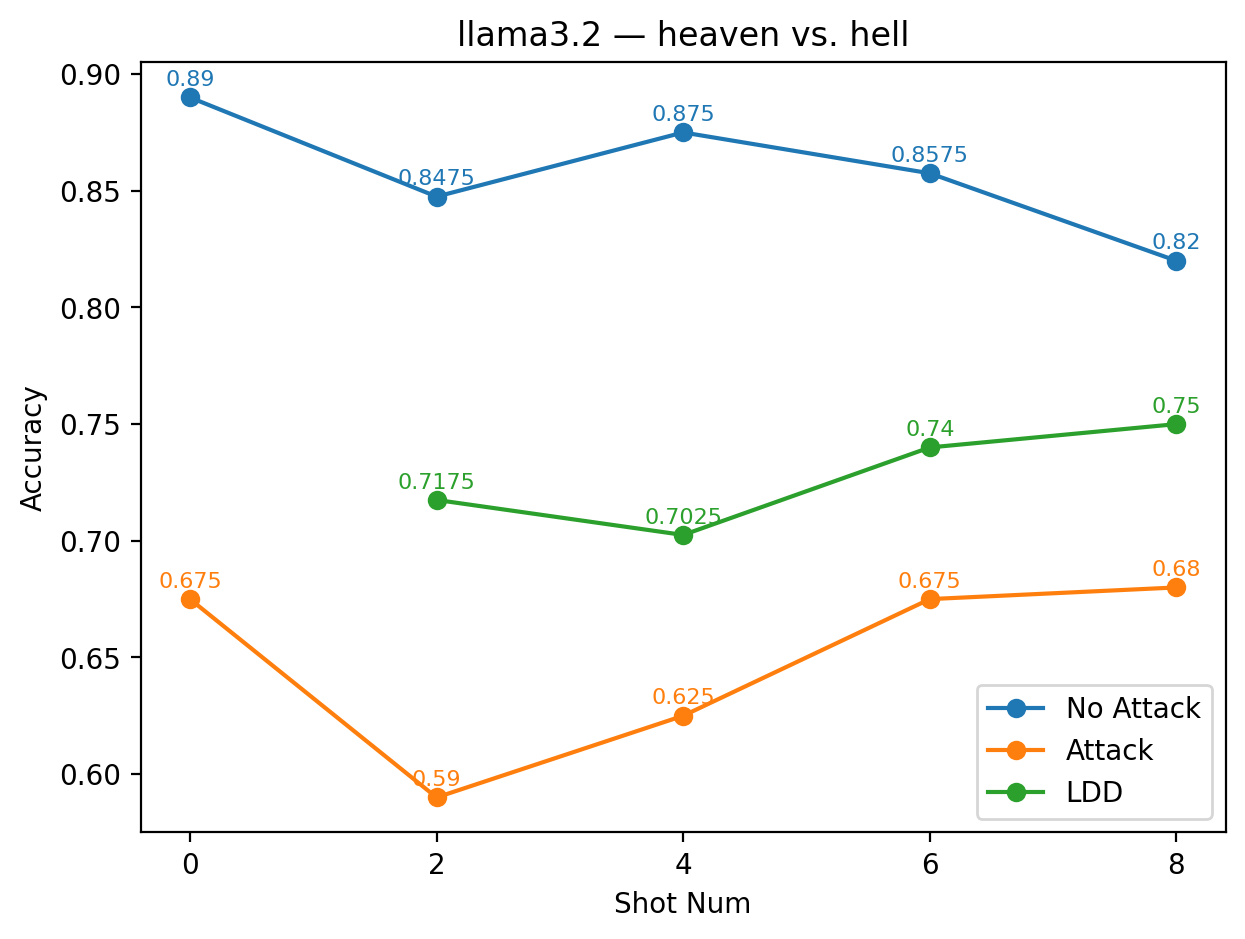
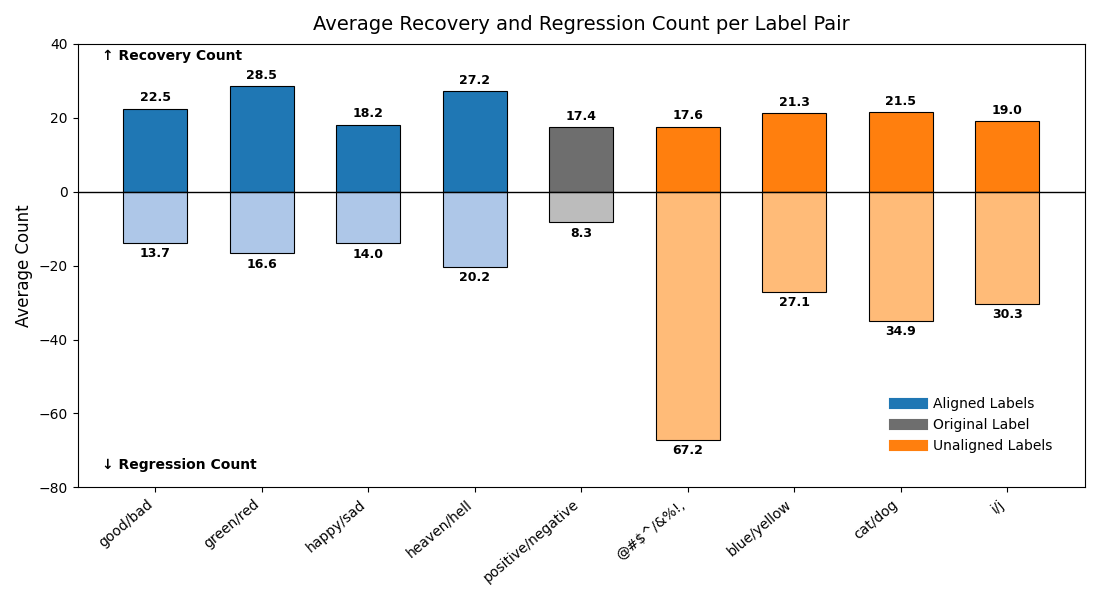
실험에서는 9개의 최신 LLM을 대상으로 다양한 few‑shot 프롬프트와 공격 시나리오를 구성했다. 주요 변수는 (1) 별칭의 의미적 정렬 정도(semantic alignment), (2) 별칭의 수와 조합, (3) 모델 규모와 아키텍처 차이이다. 결과는 흥미롭게도 ‘의미적으로 정렬된’ 별칭(예: “good” ↔ “bad”)이 ‘전혀 무관한’ 별칭(예: “blue” ↔ “yellow”)보다 방어 효과가 높았다. 이는 모델이 라벨 의미를 어느 정도 내재화하고 있기 때문에, 의미가 일관된 별칭은 학습 과정에서 더 빠르게 매핑되고, 공격 지시문과의 혼동을 최소화하기 때문이다.
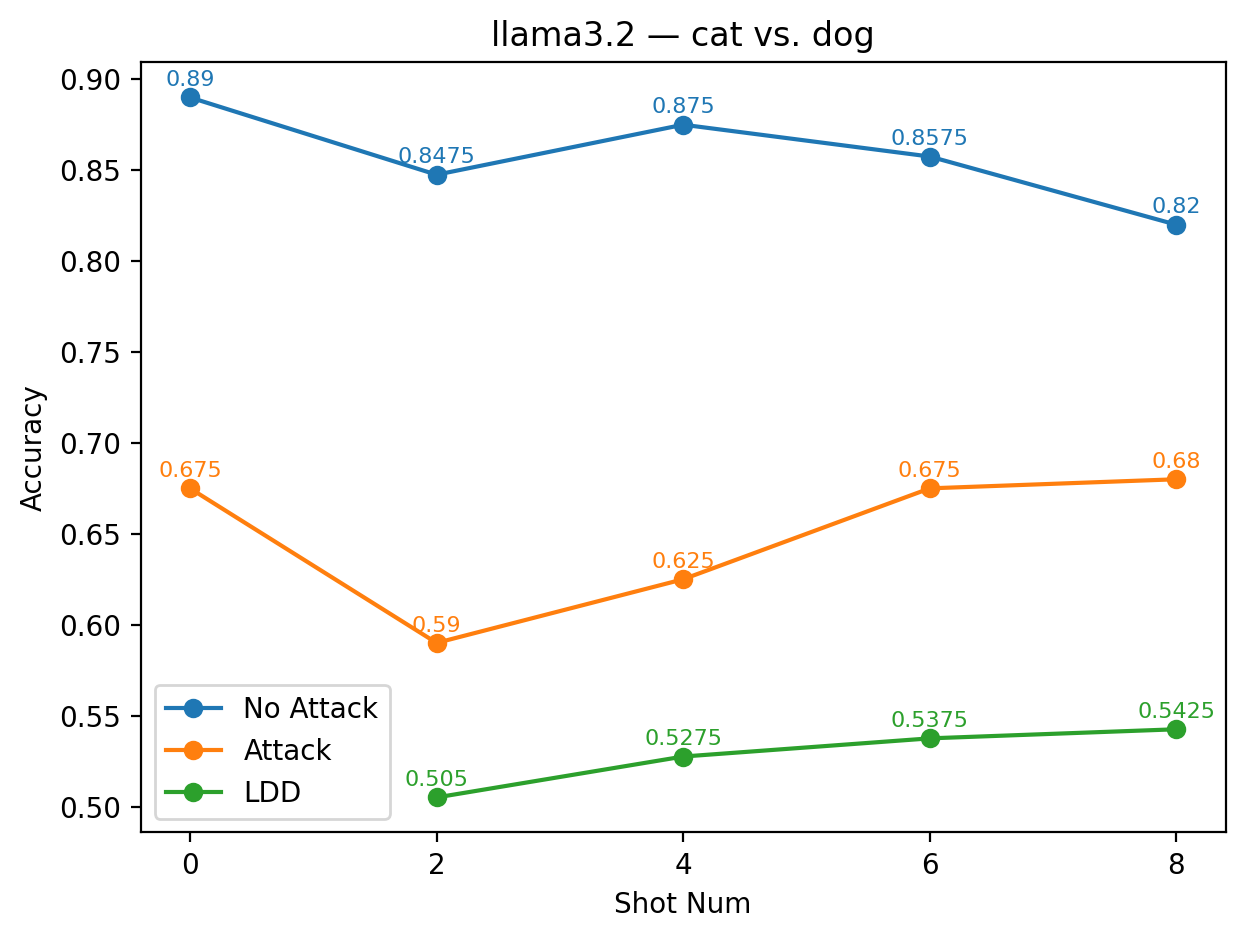
또한, 모든 모델에서 최소 하나 이상의 별칭 쌍이 방어가 없는 기본 few‑shot 성능을 초과했으며, 특히 GPT‑4o와 LLaMA 3.2는 별칭 선택에 따라 정확도 회복률이 30 % 이상에 달했다. 반면, 작은 규모의 Mistral 변형은 별칭에 민감하게 반응해 회복률이 10 % 수준에 머물렀다. 이는 모델 파라미터 수와 사전 학습 데이터 다양성이 라벨 위장 방어의 효과에 영향을 미친다는 점을 시사한다.
언어학적 분석에서는 별칭 간의 의미 거리(semantic distance)를 정량화하기 위해 WordNet 기반 유사도와 임베딩 코사인 유사도를 활용했다. 의미 거리가 작을수록(즉, 의미가 비슷할수록) 방어 효과가 높았으며, 이는 ‘의미적 연관성’이 모델 내부의 라벨 매핑을 강화한다는 가설을 뒷받침한다.
결론적으로, 라벨 위장 방어는 모델 재학습 없이도 프롬프트 주입 공격에 대한 실용적인 방어선을 제공한다. 다만 별칭 선택이 방어 성능에 결정적인 역할을 하므로, 실제 적용 시에는 도메인 특성에 맞는 의미적 정렬 별칭을 사전 테스트하는 것이 필요하다. 향후 연구에서는 자동 별칭 생성 알고리즘과 다중 라벨 시스템에 대한 확장 가능성을 탐색할 여지가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리