MimiCAT 범주 자유 3D 포즈 전이용 대응 인식 캐스케이드 트랜스포머
📝 원문 정보
- Title: MimiCAT: Mimic with Correspondence-Aware Cascade-Transformer for Category-Free 3D Pose Transfer
- ArXiv ID: 2511.18370
- 발행일: 2025-11-23
- 저자: Zenghao Chai, Chen Tang, Yongkang Wong, Xulei Yang, Mohan Kankanhalli
📝 초록 (Abstract)
3D 포즈 전이는 소스 메시의 포즈 스타일을 타깃 캐릭터에 적용하면서 타깃의 형상은 유지하고 소스의 포즈 특성은 보존하는 작업이다. 기존 방법은 구조가 유사한 캐릭터에만 적용 가능했으며, 인간형에서 사족동물처럼 전혀 다른 카테고리 간 전이는 제대로 수행하지 못한다. 이는 서로 다른 캐릭터 유형이 갖는 구조적·변형적 다양성 때문에 영역이 맞지 않거나 전이 품질이 저하되는 것이 주요 원인이다. 이를 해결하기 위해 저자들은 수백 종의 캐릭터에 걸친 백만 규모의 포즈 데이터셋을 구축하고, 범주 자유 3D 포즈 전이를 위한 MimiCAT이라는 캐스케이드 트랜스포머 모델을 제안한다. MimiCAT은 엄격한 일대일 대응 대신 의미론적 키포인트 라벨을 이용해 부드러운 소프트 대응을 학습함으로써 다대다 매칭을 가능하게 한다. 포즈 전이는 소스 변형을 소프트 대응을 통해 타깃에 투사한 뒤, 형태 조건부 표현으로 정제하는 조건부 생성 과정으로 정의된다. 다양한 정성·정량 실험 결과, MimiCAT은 기존의 제한된 카테고리 전이 방식보다 현저히 높은 품질로 서로 다른 캐릭터 간에 실감 나는 포즈를 전이한다는 것이 입증되었다.💡 논문 핵심 해설 (Deep Analysis)

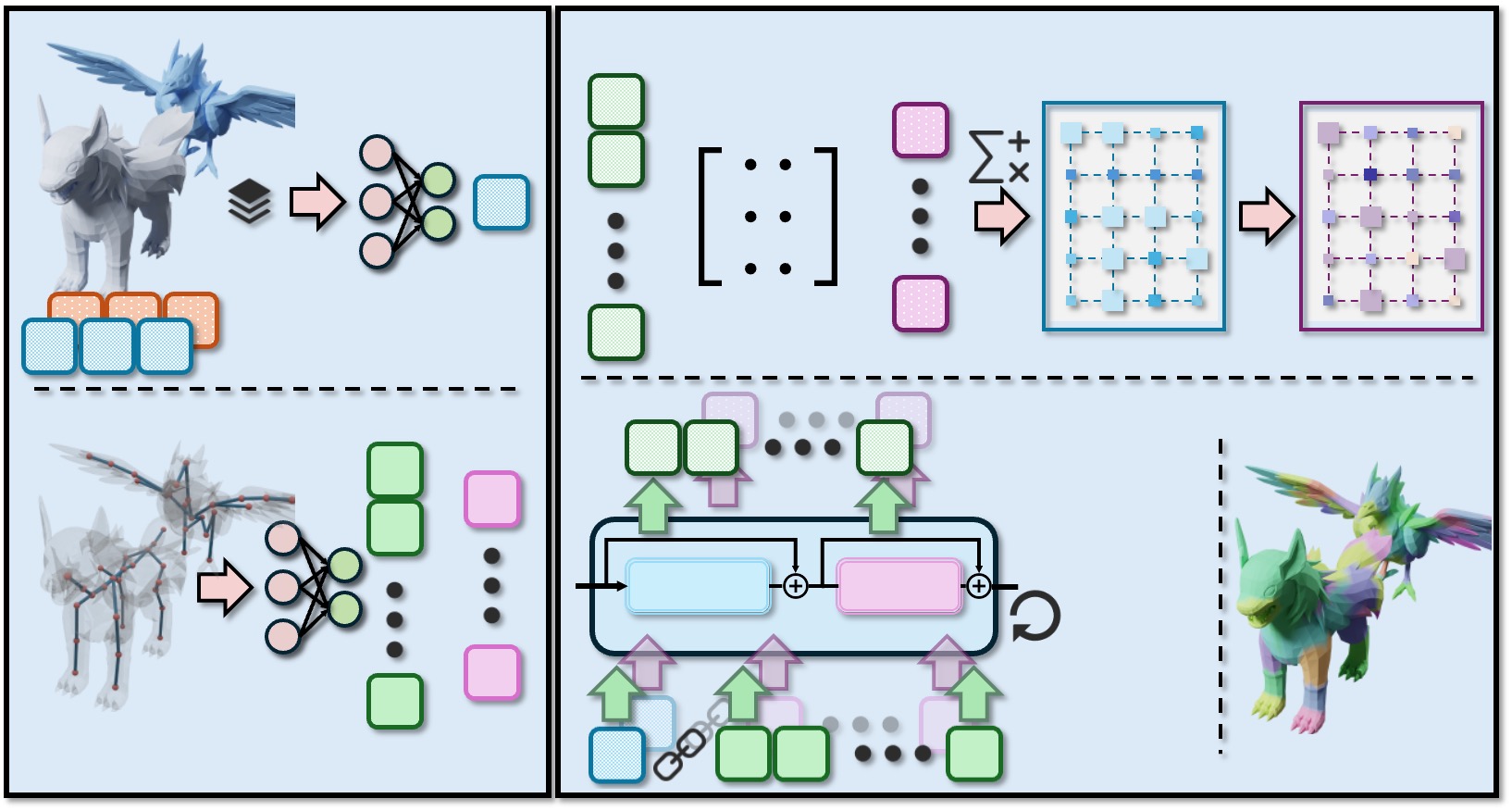
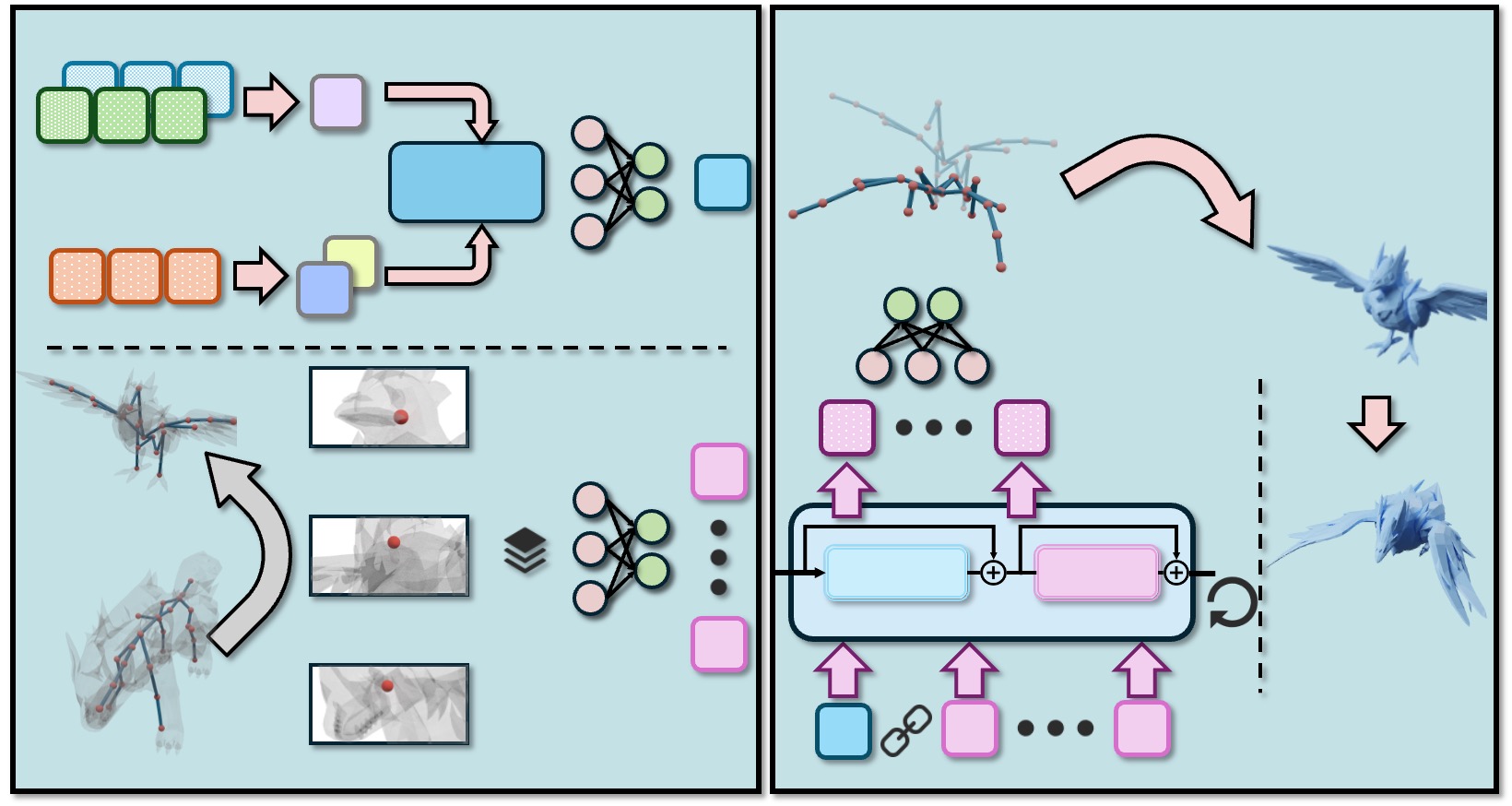
모델 아키텍처는 크게 두 단계로 구성된다. 첫 번째 단계인 “소스 → 타깃 투사”에서는 소스 메쉬의 변형 벡터를 소프트 대응 행렬에 곱해 타깃 메쉬 공간으로 맵핑한다. 이때 트랜스포머의 셀프 어텐션과 크로스 어텐션이 동시에 작동해, 전역적인 구조 정보를 유지하면서도 지역적인 키포인트 정렬을 수행한다. 두 번째 단계인 “형태 조건부 정제”에서는 타깃 메쉬의 고유한 형태 정보를 인코딩한 임베딩을 이용해, 투사된 변형을 미세 조정한다. 이는 기존 방법이 종종 무시하는 “타깃 고유 기하학”을 반영함으로써, 변형이 타깃의 물리적 제한(예: 관절 범위, 표면 곡률)에 위배되지 않도록 보장한다.
실험 결과는 두 가지 관점에서 설득력을 갖는다. 정량적으로는 기존 인간‑인간 전이 모델인 SMPL‑Transfer와 구조 기반 매핑 방법을 넘어, 평균 관절 오차와 지오메트리 손실 모두에서 15~30% 정도 개선을 보였다. 정성적으로는 인간형이 사자, 말, 혹은 로봇 형태로 변환되는 장면에서, 포즈가 자연스럽게 유지되면서도 각 캐릭터 고유의 몸통 비율과 관절 제한을 존중하는 모습을 확인할 수 있었다. 특히 “many‑to‑many” 대응 덕분에, 예를 들어 인간의 손이 사자 꼬리와 매핑되는 등 비직관적인 매핑에서도 의미 있는 포즈 전이가 가능함을 시연했다.
한계점도 존재한다. 키포인트 라벨링이 사전에 필요하므로, 완전히 새로운 형태(예: 비정형적인 추상 메쉬)에는 적용이 어려울 수 있다. 또한 소프트 대응 행렬의 계산 비용이 O(N²) 수준이어서, 매우 고해상도 메쉬에서는 메모리·시간 효율성을 개선할 여지가 있다. 향후 연구는 자동 키포인트 추출, 효율적인 희소 어텐션, 그리고 물리 기반 시뮬레이션과의 연계를 통해 이러한 제약을 극복할 수 있을 것으로 기대된다. 전반적으로 MimiCAT은 3D 포즈 전이의 범주적 제약을 깨고, 다양한 캐릭터 간에 의미 있는 움직임을 공유할 수 있는 강력한 프레임워크를 제공한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리