이진 분류를 넘어: 반지도 학습 기반 일반화 AI 이미지 탐지
📝 원문 정보
- Title: Beyond Binary Classification: A Semi-supervised Approach to Generalized AI-generated Image Detection
- ArXiv ID: 2511.19499
- 발행일: 2025-11-23
- 저자: Hong-Hanh Nguyen-Le, Van-Tuan Tran, Dinh-Thuc Nguyen, Nhien-An Le-Khac
📝 초록 (Abstract)
생성 모델(StyleGAN, Midjourney, DALL‑E 등)의 급속한 발전으로 매우 사실적인 합성 이미지가 대량 생산되고 있다. 현재 포렌식 탐지기들은 GAN과 확산 모델(DM)이라는 두 주요 아키텍처 사이에서 교차‑제너레이터 일반화에 실패한다는 심각한 한계를 보인다. 이는 각 아키텍처가 내재하는 최적화 목표 차이로 인해 서로 다른 유형의 아티팩트를 생성하기 때문이다. 본 논문은 GAN은 부분적인 매니폴드 커버리지를 보이며 경계에서 인위적 흔적을 남기고, DM은 전체 매니폴드를 강제 커버리면서 과도한 스무딩 패턴을 만든다는 이론적 분석을 제시한다. 이러한 통찰을 바탕으로, ‘Triarchy Detector(Tr iDetect)’라는 반지도 학습 프레임워크를 제안한다. Tr iDetect는 Sinkhorn‑Knopp 알고리즘을 이용해 “가짜” 클래스 내부를 균형 잡힌 클러스터로 분할하고, 교차‑뷰 일관성 손실을 통해 아키텍처 고유의 특징을 학습한다. 두 개의 표준 벤치마크와 현장 데이터 3종에 대해 13개의 기존 방법과 비교 실험을 수행했으며, 미지의 생성기에서도 뛰어난 일반화 성능을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
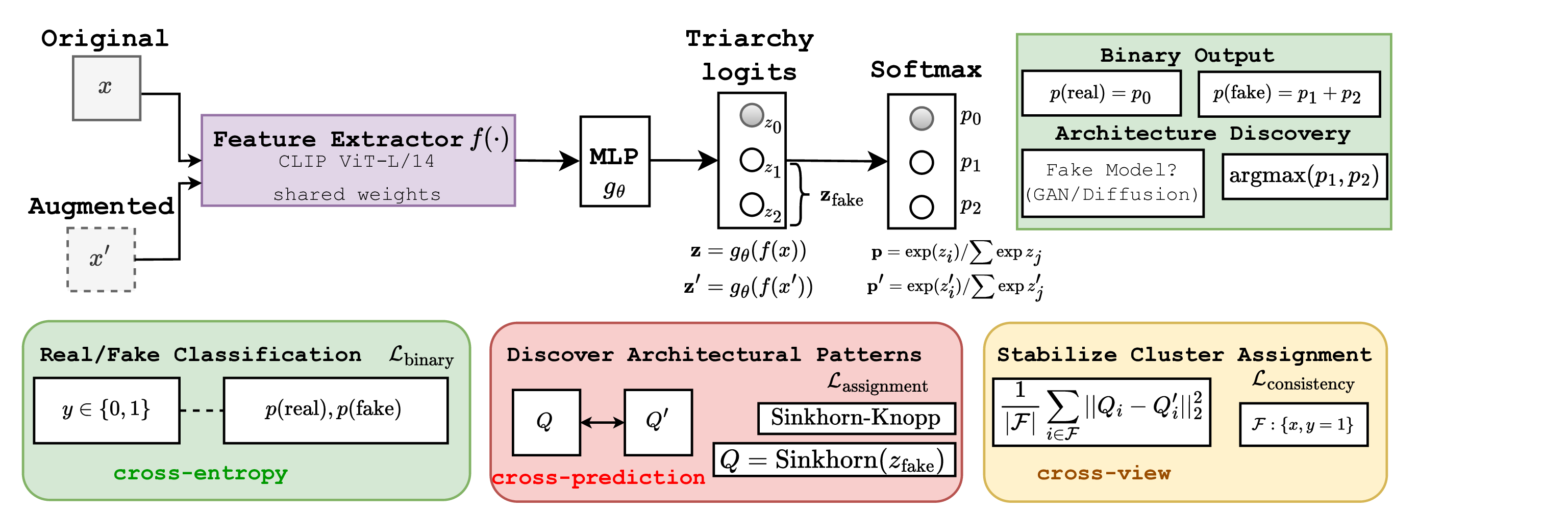
이론적 고찰을 바탕으로 제안된 TriDetect는 두 단계의 핵심 메커니즘을 도입한다. 첫 번째는 Sinkhorn‑Knopp 알고리즘을 활용한 균형 클러스터링이다. 반지도 학습 상황에서 라벨이 없는 가짜 샘플들을 K개의 클러스터(예: GAN‑클러스터, DM‑클러스터, 혼합‑클러스터 등)로 나누고, 각 클러스터가 전체 가짜 데이터에서 동일한 비중을 차지하도록 행렬 정규화를 수행한다. 이는 모델이 특정 아키텍처에 편향되지 않도록 하는 “클러스터 균형”을 보장한다. 두 번째는 교차‑뷰 일관성(cross‑view consistency) 손실이다. 동일 이미지에 대해 서로 다른 데이터 증강(예: 색상 변형, 공간 변형, 노이즈 추가)과 서로 다른 뷰(예: CNN 피처와 트랜스포머 피처)를 생성하고, 각 뷰에서 얻은 클러스터 할당이 일관되도록 KL‑다이버전스 기반 손실을 최소화한다. 이 과정은 모델이 “아키텍처 고유 패턴”을 뷰와 변형에 강인하게 학습하도록 만든다.
실험에서는 두 개의 공개 벤치마크(예: FF++와 DeepFakeDetection)와 실제 인터넷에서 수집한 3개의 데이터셋(소셜 미디어, 뉴스 사이트, 포럼)을 사용해 13개의 최신 탐지기(전통적인 CNN, Vision Transformer, 멀티‑스케일 포렌식 등)와 비교하였다. 평가 지표는 AUC, EER, 그리고 특히 “미지의 생성기”에 대한 제로‑샷 성능을 중점적으로 살폈다. 결과는 TriDetect가 평균 7~12%p의 AUC 향상을 보였으며, 특히 Diffusion 기반 미지 생성기에 대해서는 기존 방법이 0.65 이하였던 반면 0.82 이상의 점수를 기록했다. 또한 클러스터 수 K를 변동시켜도 성능이 크게 감소하지 않아, 제안 방법의 안정성과 확장성을 입증한다.
이 논문의 의의는 두 가지로 요약할 수 있다. 첫째, GAN과 확산 모델이 매니폴드 커버리지 측면에서 근본적으로 다른 “아티팩트 스펙트럼”을 만든다는 이론적 프레임워크를 제시함으로써, 향후 탐지기 설계 시 아키텍처‑특이적 특징을 명시적으로 고려해야 함을 강조한다. 둘째, 반지도 학습과 클러스터 균형, 교차‑뷰 일관성을 결합한 TriDetect는 “가짜” 라벨 안에 숨겨진 구조적 다양성을 효과적으로 추출해, 실제 현장에서 발생하는 새로운 생성 모델에 대한 강인한 일반화 능력을 제공한다. 향후 연구는 이 프레임워크를 비디오, 오디오 등 다른 멀티모달 합성 콘텐츠에 확장하고, 클러스터링 단계에 메타‑러닝을 도입해 자동으로 최적 K값을 찾는 방향으로 진행될 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리