Title: How Far Can LLMs Emulate Human Behavior?: A Strategic Analysis via the Buy-and-Sell Negotiation Game
ArXiv ID: 2511.17990
발행일: 2025-11-22
저자: Mingyu Jeon, Jaeyoung Suh, Suwan Cho, Dohyeon Kim
📝 초록 (Abstract)
대형 언어 모델(LLM)의 급속한 발전에 따라, 최근 연구들은 단순한 질의‑응답을 넘어 복잡한 대화 능력과 인간과 유사한 행동 모방 가능성에 주목하고 있다. 특히 LLM이 실제 인간의 감정과 행동을 얼마나 정확히 재현할 수 있는지, 그리고 이러한 재현이 실생활 시나리오에서 효과적으로 작동할 수 있는지가 큰 관심사이다. 그러나 기존 벤치마크는 주로 지식 기반 평가에 초점을 맞추어 사회적 상호작용 및 전략적 대화 능력을 충분히 반영하지 못한다. 이를 보완하고자 본 연구는 매수‑매도 협상 시뮬레이션을 활용해 LLM의 인간 감정·행동 모방 및 전략적 의사결정 능력을 정량적으로 평가하는 방법론을 제안한다. 구체적으로 서로 다른 페르소나를 부여한 다수의 LLM을 구매자와 판매자 역할에 배치하고, 승률, 거래 가격, Shap 값 등을 종합적으로 분석한다. 실험 결과, 기존 벤치마크 점수가 높은 모델일수록 전반적인 협상 성과가 우수했으나, 감정·사회적 맥락을 강조하는 상황에서는 일부 모델의 성능이 저하되는 현상이 관찰되었다. 또한, 경쟁적·교활한 성향이 협상 결과에 있어 이타적·협력적 성향보다 더 유리하게 작용함을 확인했으며, 이는 부여된 페르소나가 협상 전략과 결과에 큰 변화를 일으킬 수 있음을 시사한다. 따라서 본 연구는 LLM의 사회적 행동 모방 및 대화 전략을 평가하는 새로운 접근법을 제시하고, 협상 시뮬레이션이 기존 벤치마크에서 간과되던 실제 상호작용 능력을 측정하는 의미 있는 보완 지표가 될 수 있음을 입증한다.
💡 논문 핵심 해설 (Deep Analysis)
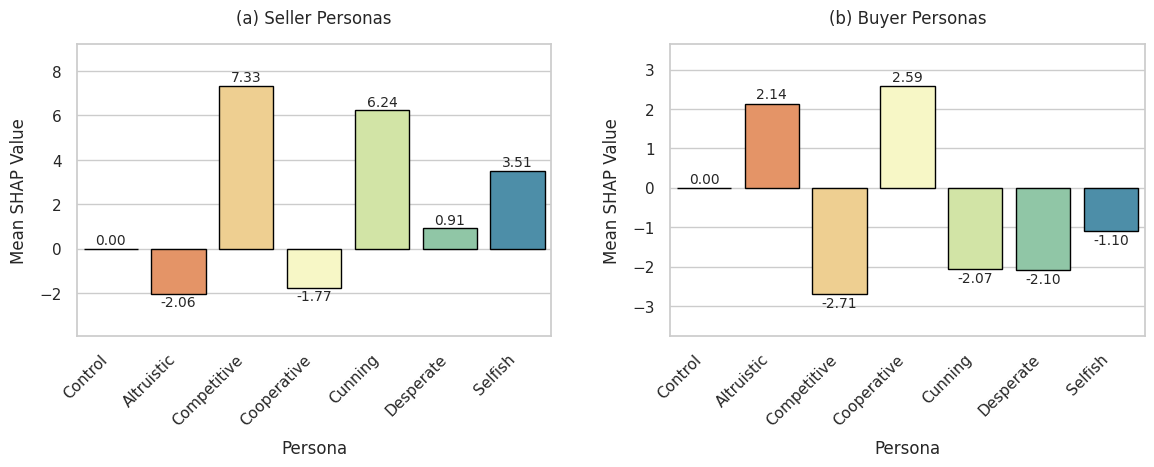
본 논문은 현재 LLM 평가 패러다임이 지식·언어 이해 중심으로 한정돼 있다는 비판에서 출발한다. 실제 인간과의 상호작용에서는 감정, 사회적 규범, 전략적 사고가 복합적으로 작용한다는 점을 간과하면, 모델이 실제 서비스 환경에서 얼마나 유용한지를 제대로 판단할 수 없다. 저자들은 이러한 공백을 메우기 위해 ‘Buy‑and‑Sell Negotiation Game’이라는 구조화된 협상 시나리오를 설계하였다. 이 시뮬레이션은 두 가지 핵심 요소를 포함한다. 첫째, 모델에게 ‘Buyer’와 ‘Seller’라는 명확한 역할을 부여하고, 각각에게 ‘협상가’, ‘협조자’, ‘교활한 상인’ 등 다양한 페르소나를 할당한다. 이를 통해 동일 모델이라도 페르소나에 따라 행동 양식이 어떻게 변하는지를 정량적으로 측정할 수 있다. 둘째, 협상 과정에서 발생하는 주요 성과 지표—승률, 최종 거래 가격, 그리고 Shapley Value(공헌도 분석)—를 수집한다. Shap Value를 도입한 점은 특히 주목할 만한데, 이는 각 발화가 전체 협상 결과에 미친 영향을 객관적으로 파악하게 해준다.
실험 결과는 두 가지 중요한 함의를 제공한다. 첫째, 기존 벤치마크(예: MMLU, HELM) 점수가 높은 모델이 전반적인 협상 성과에서도 우수함을 확인했다. 이는 언어 이해와 지식 기반 능력이 전략적 대화에서도 기본적인 토대를 제공한다는 점을 시사한다. 그러나 감정 표현이나 사회적 맥락을 강조하는 상황에서는 ‘GPT‑4‑Turbo’와 같이 최신 모델조차도 성능 저하를 보였으며, 이는 현재 LLM이 감정 인식·표현 능력에서 아직 한계가 있음을 보여준다.
둘째, 페르소나가 협상 결과에 미치는 영향이 매우 크다는 점이다. 경쟁적·교활한 페르소나가 높은 가격을 얻고 승률을 끌어올리는 반면, 이타적·협력적 페르소나는 거래 성사율은 높지만 가격 측면에서 불리한 결과를 낳았다. 이는 인간 협상에서도 흔히 관찰되는 ‘협상 스타일’ 차이와 일맥상통한다. 흥미롭게도, 동일 모델이라도 페르소나 전환만으로 전략적 행동이 크게 달라지는 점은 LLM이 ‘인격’ 혹은 ‘전략적 성향’을 학습하고 적용할 수 있는 가능성을 보여준다.
이러한 결과는 몇 가지 실용적·학술적 시사점을 제공한다. 첫째, LLM을 실제 비즈니스 챗봇이나 고객 서비스에 적용할 때, 단순히 모델의 지식 점수만을 기준으로 선택하기보다, 목표 상황에 맞는 감정·사회적 행동 프로파일을 사전에 정의하고 검증하는 절차가 필요하다. 둘째, 협상 시뮬레이션과 같은 구조화된 사회적 과제는 기존 벤치마크를 보완하는 ‘실제 상호작용 능력’ 평가 지표로 활용될 수 있다. 마지막으로, Shap Value와 같은 기여도 분석 도구를 도입함으로써, 모델의 개별 발화가 협상 결과에 미치는 영향을 투명하게 파악할 수 있어, 모델 디버깅 및 정책 설계에 유용한 인사이트를 제공한다.
요약하면, 본 연구는 LLM의 인간 행동 모방 능력을 정량화하는 새로운 프레임워크를 제시하고, 모델 선택·튜닝·배포 단계에서 감정·사회적·전략적 요소를 고려해야 함을 강조한다. 향후 연구에서는 보다 복합적인 다자 협상, 문화적 차이 반영, 그리고 장기적인 관계 구축 시나리오 등을 포함해 평가 범위를 확대함으로써, LLM이 진정한 ‘사회적 지능’에 근접하도록 하는 로드맵을 제시할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
**제목**
LLM이 인간 행동을 모방할 수 있는 한계: 매수‑매도 협상 게임을 통한 전략적 평가
초록
대형 언어 모델(LLM)의 급속한 발전에 따라, 최근 연구들은 단순한 질의‑응답을 넘어 복잡한 대화 능력과 인간과 유사한 행동 모방 가능성에 주목하고 있다. 특히 LLM이 실제 인간의 감정과 행동을 얼마나 정확히 재현할 수 있는지, 그리고 이러한 재현이 실생활 시나리오에서 효과적으로 작동할 수 있는지가 큰 관심사이다. 그러나 기존 벤치마크는 주로 지식 기반 평가에 초점을 맞추어 사회적 상호작용 및 전략적 대화 능력을 충분히 반영하지 못한다. 이를 보완하고자 본 연구는 매수‑매도 협상 시뮬레이션을 활용해 LLM의 인간 감정·행동 모방 및 전략적 의사결정 능력을 정량적으로 평가하는 방법론을 제안한다. 구체적으로 서로 다른 페르소나를 부여한 다수의 LLM을 구매자와 판매자 역할에 배치하고, 승률, 거래 가격, Shap Value 등을 종합적으로 분석한다. 실험 결과, 기존 벤치마크 점수가 높은 모델일수록 전반적인 협상 성과가 우수했으나, 감정·사회적 맥락을 강조하는 상황에서는 일부 모델의 성능이 저하되는 현상이 관찰되었다. 또한, 경쟁적·교활한 성향이 협상 결과에 있어 이타적·협력적 성향보다 더 유리하게 작용함을 확인했으며, 이는 부여된 페르소나가 협상 전략과 결과에 큰 변화를 일으킬 수 있음을 시사한다. 따라서 본 연구는 LLM의 사회적 행동 모방 및 대화 전략을 평가하는 새로운 접근법을 제시하고, 협상 시뮬레이션이 기존 벤치마크에서 간과되던 실제 상호작용 능력을 측정하는 의미 있는 보완 지표가 될 수 있음을 입증한다.
키워드
대형 언어 모델, 인간 행동 모방, 감정 인식, 전략적 협상, 페르소나, Shapley Value, 벤치마크 보완
1. 서론
LLM은 자연어 이해와 생성에서 눈부신 성과를 보여 왔으며, 이에 따라 다양한 실용 서비스에 적용되고 있다. 그러나 실제 인간과의 상호작용에서는 지식 전달을 넘어 감정 표현, 사회적 규범 준수, 전략적 의사결정 등이 복합적으로 요구된다. 기존 평가 체계는 이러한 요소를 충분히 검증하지 못한다는 비판이 제기되어 왔다.
2. 방법론
협상 시뮬레이션 설계: 매수자(Buyer)와 매도자(Seller) 역할을 각각 하나의 LLM에 할당하고, 각 모델에 ‘협상가’, ‘협조자’, ‘교활한 상인’ 등 서로 다른 페르소나를 부여한다.
성과 지표: (1) 승률 – 협상에서 이긴 횟수 비율, (2) 최종 거래 가격 – 협상 종료 시 합의된 가격, (3) Shap Value – 각 발화가 최종 결과에 기여한 정도를 정량화.
실험 설정: 최신 GPT‑4‑Turbo, Claude‑2, Llama‑2‑70B 등 여러 모델을 동일 조건 하에 테스트하고, 기존 벤치마크 점수와의 상관관계를 분석한다.
3. 결과
벤치마크와 협상 성과의 상관: 기존 지식 기반 벤치마크 점수가 높은 모델이 전반적으로 높은 승률과 유리한 가격을 달성했다.
감정·사회적 맥락에서의 성능 저하: 감정 표현을 요구하는 라운드에서는 일부 고성능 모델이 기대 이하의 Shap Value를 보이며, 감정 인식·표현 능력에 한계가 있음을 시사한다.
페르소나 효과: 경쟁적·교활한 페르소나가 높은 가격을 얻는 반면, 협조적·이타적 페르소나는 거래 성사율은 높지만 가격 면에서 불리했다. 동일 모델이라도 페르소나 전환만으로 전략이 크게 달라졌다.
4. 논의
본 연구는 LLM을 실제 비즈니스 대화 시스템에 적용할 때, 단순히 모델의 지식 점수만을 기준으로 선택하기보다 목표 상황에 맞는 감정·사회적 행동 프로파일을 사전에 정의하고 검증해야 함을 강조한다. 또한, 구조화된 협상 시뮬레이션과 Shap Value와 같은 기여도 분석 도구는 모델 디버깅 및 정책 설계에 유용한 인사이트를 제공한다.
5. 결론 및 향후 연구
본 논문은 LLM의 인간 행동 모방 능력을 정량화하는 새로운 평가 프레임워크를 제시하고, 협상 시뮬레이션이 기존 지식 기반 벤치마크를 보완하는 실용적인 메트릭이 될 수 있음을 입증한다. 향후 연구에서는 다자 협상, 문화적 차이 반영, 장기 관계 구축 시나리오 등을 포함해 평가 범위를 확대하고, 감정·사회적 인지 능력을 강화한 모델 개발을 촉진할 필요가 있다.