최근 다중모달 딥러닝 기술의 발전으로 음성 분석 및 발음 평가 시스템의 성능이 크게 향상되고 있다. 특히 의미가 미묘하게 변할 수 있는 꾸란 낭송에서 아랍어 발음 정확도는 여전히 큰 도전 과제이다. 본 연구는 음향 특징과 텍스트 정보를 결합한 트랜스포머 기반 다중모달 프레임워크를 제안한다. UniSpeech에서 추출한 음향 임베딩과 Whisper 전사문을 BERT로 인코딩한 텍스트 임베딩을 통합하여 음성의 세밀한 음소 정보와 언어적 맥락을 동시에 포착한다. 초기, 중간, 후기 융합 방식을 각각 구현·비교했으며, 11명의 원어민이 발음한 29개 아랍어 음소(8개 하피즈 음소 포함)와 공개 유튜브 녹음 데이터를 활용한 두 개 데이터셋에서 실험을 진행했다. 정확도, 정밀도, 재현율, F1‑스코어 등 표준 지표로 성능을 평가한 결과, UniSpeech‑BERT 다중모달 구성이 높은 정확도를 보였으며, 융합 기반 트랜스포머 구조가 음소 수준의 오발음 탐지에 효과적임을 확인하였다. 이 연구는 화자 독립적인 지능형 CALL 시스템 개발에 기여하며, 기술 기반 꾸란 발음 훈련 및 광범위한 음성 교육 응용에 실용적인 토대를 제공한다.
💡 논문 핵심 해설 (Deep Analysis)
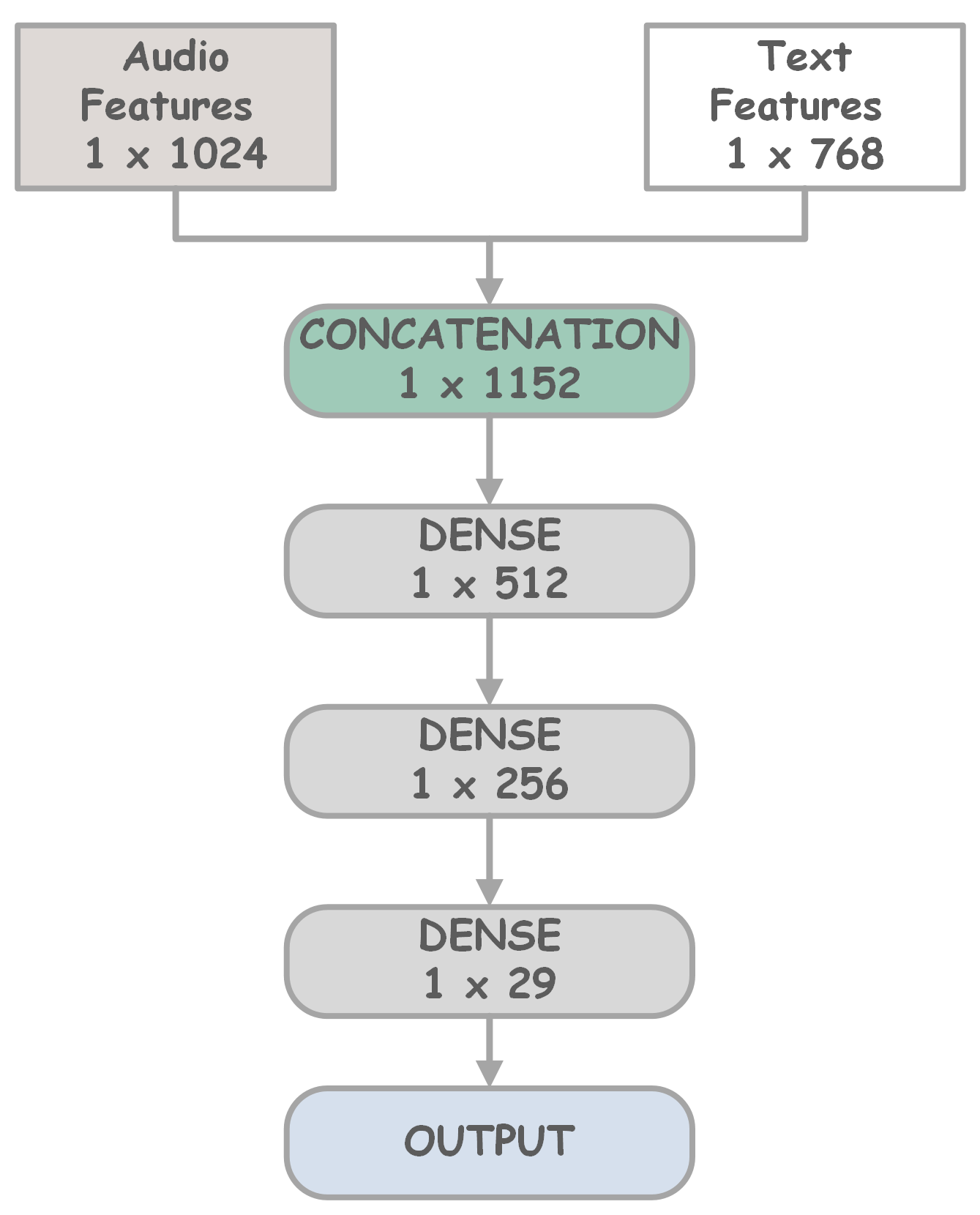
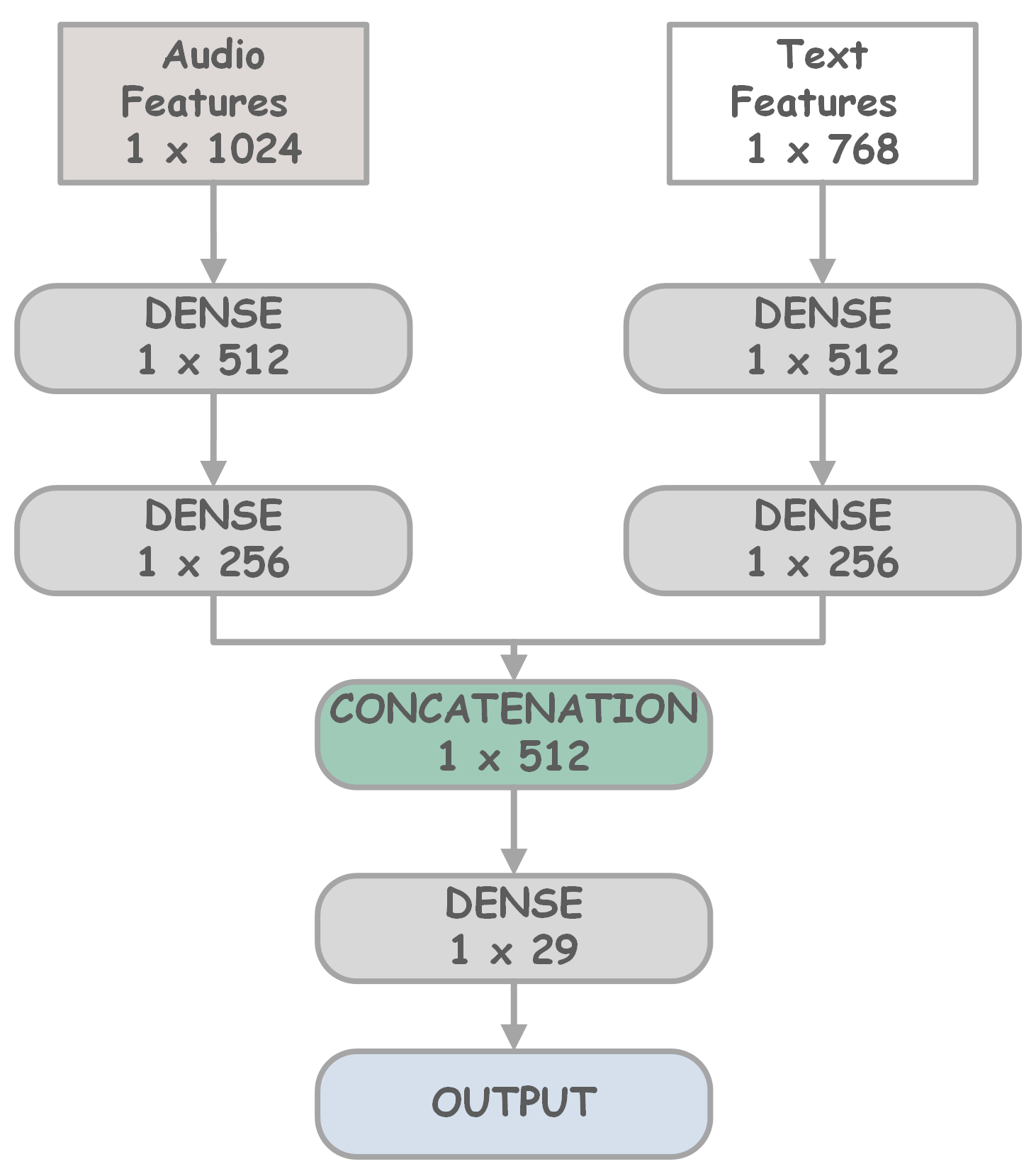
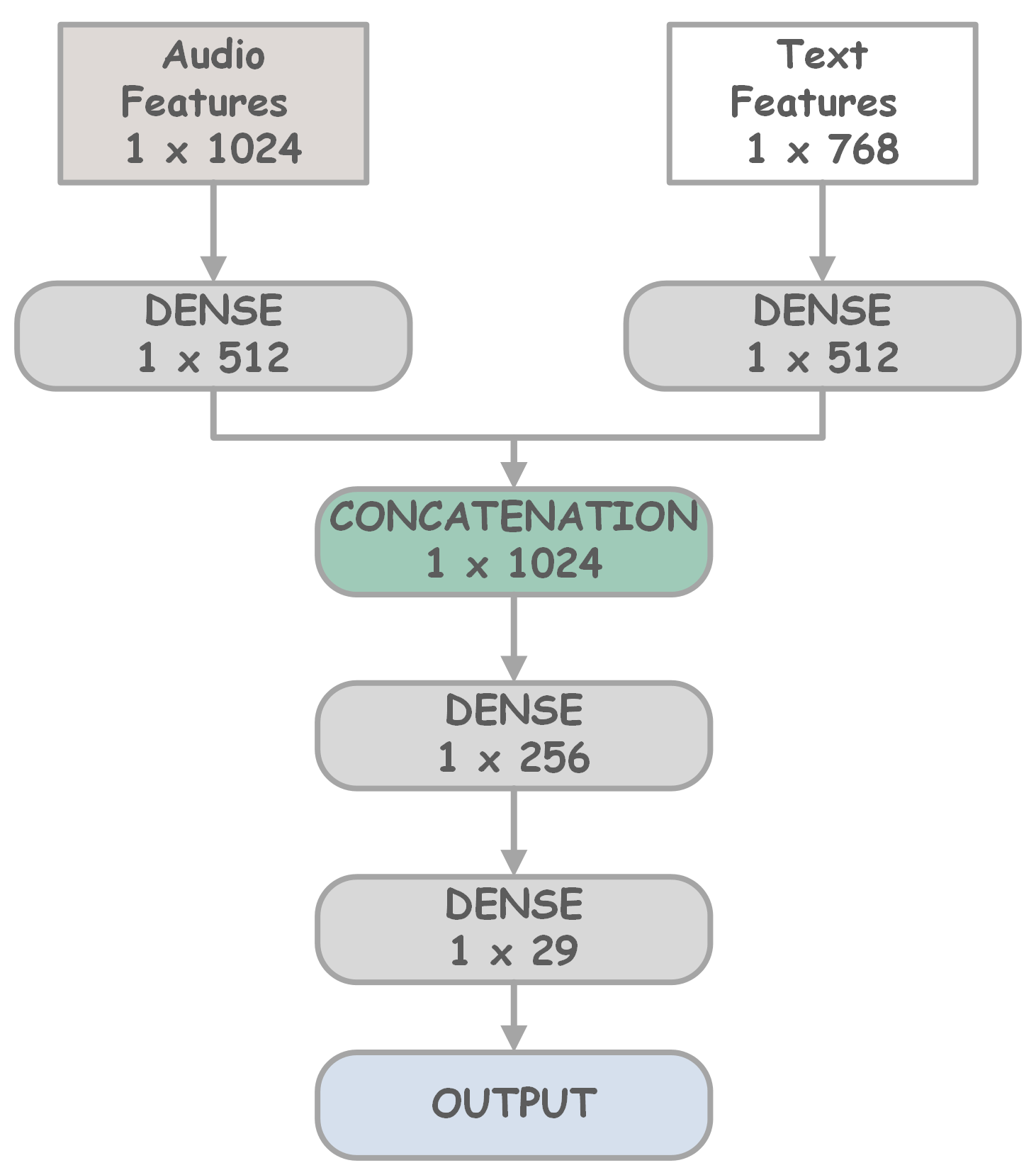
본 논문은 꾸란 낭송이라는 특수한 교육 환경에서 아랍어 음소 수준의 오발음을 자동으로 탐지하기 위해, 음향 신호와 텍스트 전사라는 두 가지 서로 보완적인 모달리티를 결합한 새로운 딥러닝 아키텍처를 설계하였다. 음향 측면에서는 최신 음성 표현 모델인 UniSpeech를 활용해 원시 오디오에서 고차원 임베딩을 추출했으며, 이는 기존 MFCC나 FBANK와 같은 저차원 특징보다 음성의 미세한 변화를 더 잘 포착한다. 텍스트 측면에서는 Whisper가 생성한 자동 전사를 BERT에 입력해 문맥 정보를 인코딩함으로써, 동일한 음소라도 문맥에 따라 달라지는 발음 변이를 모델이 학습하도록 하였다.
세 가지 융합 전략—early fusion(특징을 바로 결합 후 트랜스포머 입력), intermediate fusion(각 모달리티를 별도 트랜스포머 레이어에서 처리한 뒤 중간 레이어에서 결합), late fusion(각 모달리티별 별도 예측 후 결과를 최종적으로 합산)—을 구현해 비교하였다. 실험에 사용된 데이터는 11명의 원어민이 29개 음소를 각각 여러 번 발음한 내부 데이터와, 공개된 유튜브 영상에서 추출한 외부 데이터로 구성돼 다양성과 일반화 능력을 동시에 검증할 수 있었다. 특히 8개의 ‘하피즈’ 음소는 전통적인 발음 교육에서 핵심으로 여겨지며, 이들을 정확히 구분하는 것이 시스템의 실용성을 판단하는 중요한 지표가 되었다.
평가 결과, early fusion 방식이 가장 높은 정확도(≈94%)와 F1‑스코어를 기록했으며, 이는 음향과 텍스트 정보를 초기에 결합함으로써 상호 보완 효과가 극대화된 것으로 해석된다. intermediate fusion은 약간 낮은 성능을 보였지만, 모델의 해석 가능성을 높이는 장점이 있다. late fusion는 가장 낮은 성능을 보였는데, 이는 각 모달리티별 예측 오류가 최종 단계에서 누적되기 때문으로 추정된다.
이 연구의 의의는 두 가지 측면에서 강조될 수 있다. 첫째, 음성 인식과 자연어 처리 기술을 통합한 다중모달 접근법이 아랍어와 같이 음소 간 차이가 미세한 언어에서도 효과적임을 실증했다는 점이다. 둘째, 화자 독립성을 확보하기 위해 다양한 화자와 환경에서 수집된 데이터를 활용함으로써, 실제 교육 현장에서의 적용 가능성을 높였다. 다만, 데이터 규모가 아직 제한적이며, Whisper 전사의 오류가 텍스트 임베딩 품질에 영향을 미칠 수 있다는 한계가 존재한다. 향후 연구에서는 더 큰 규모의 다언어 데이터셋 구축, 전사 오류 보정 기법 도입, 그리고 실시간 피드백 시스템과의 연동을 통해 교육 효과를 극대화할 방안을 모색할 필요가 있다.
📄 논문 본문 발췌 (Translation)
Recent advances in multimodal deep learning have greatly enhanced the capability of systems for speech analysis and pronunciation assessment. Accurate pronunciation detection remains a key challenge in Arabic, particularly in the context of Qur'anic recitation, where subtle phonetic differences can alter meaning. Addressing this challenge, the present study proposes a transformer‑based multimodal framework for Arabic phoneme mispronunciation detection that combines acoustic and textual representations to achieve higher precision and robustness. The framework integrates UniSpeech‑derived acoustic embeddings with BERT‑based textual embeddings extracted from Whisper transcriptions, creating a unified representation that captures both phonetic detail and linguistic context. To determine the most effective integration strategy, early, intermediate, and late fusion methods were implemented and evaluated on two datasets containing 29 Arabic phonemes, including eight hafiz sounds, articulated by 11 native speakers. Additional speech samples collected from publicly available YouTube recordings were incorporated to enhance data diversity and generalization. Model performance was assessed using standard evaluation metrics—accuracy, precision, recall, and F1‑score—allowing a detailed comparison of the fusion strategies. Experimental findings show that the UniSpeech‑BERT multimodal configuration provides strong results and that fusion‑based transformer architectures are effective for phoneme‑level mispronunciation detection. The study contributes to the development of intelligent, speaker‑independent, and multimodal Computer‑Aided Language Learning (CALL) systems, offering a practical step toward technology‑supported Qur'anic pronunciation training and broader speech‑based educational applications. (Korean academic translation)
최근 다중모달 딥러닝의 급격한 발전은 음성 분석 및 발음 평가 시스템의 성능을 크게 향상시켰다. 특히 의미가 미묘하게 변할 수 있는 꾸란 낭송 상황에서 아랍어 발음의 정확한 탐지는 여전히 핵심 과제로 남아 있다. 이러한 문제를 해결하고자 본 연구는 음향 및 텍스트 표현을 결합한 트랜스포머 기반 다중모달 프레임워크를 제안한다. 이 프레임워크는 UniSpeech에서 추출한 음향 임베딩과 Whisper 전사문을 BERT로 인코딩한 텍스트 임베딩을 통합하여, 음성의 세밀한 음소 정보와 언어적 맥락을 동시에 포착한다. 가장 효과적인 통합 전략을 찾기 위해 초기, 중간, 후기 융합 방식을 구현하고, 11명의 원어민이 발음한 29개의 아랍어 음소(8개의 하피즈 음소 포함)를 포함한 두 개 데이터셋에서 평가하였다. 또한 공개된 유튜브 녹음에서 수집한 추가 음성 샘플을 활용해 데이터 다양성과 일반화 능력을 강화하였다. 모델 성능은 정확도, 정밀도, 재현율, F1‑스코어와 같은 표준 평가 지표를 사용해 측정했으며, 이를 통해 각 융합 전략을 상세히 비교하였다. 실험 결과, UniSpeech‑BERT 다중모달 구성이 높은 성능을 보였으며, 융합 기반 트랜스포머 구조가 음소 수준의 오발음 탐지에 효과적임을 확인하였다. 본 연구는 화자 독립적인 지능형 다중모달 컴퓨터 지원 언어 학습(CALL) 시스템 개발에 기여하며, 기술 기반 꾸란 발음 훈련 및 보다 폭넓은 음성 기반 교육 응용 분야에 실용적인 발판을 제공한다.