노이즈에 강한 추상적 압축을 통한 검색 강화 언어 모델
📝 원문 정보
- Title: Noise-Robust Abstractive Compression in Retrieval-Augmented Language Models
- ArXiv ID: 2512.08943
- 발행일: 2025-11-19
- 저자: Singon Kim
📝 초록 (Abstract)
추상적 압축은 작은 언어 모델을 이용해 질의와 관련된 컨텍스트를 요약함으로써 검색‑증강 생성(RAG)의 연산 비용을 낮춘다. 그러나 검색된 문서에는 질의와 무관하거나 사실 오류가 포함된 정보가 높은 관련도 점수에도 불구하고 존재한다. 이러한 ‘노이즈’는 특히 긴 컨텍스트에서 주의가 분산될 때 압축기가 중요한 정보를 누락하게 만든다. 이를 해결하기 위해 저자들은 검색된 문서를 보다 세분화하고, 두 단계의 새로운 학습 방식을 도입한 ACoRN(Abstractive Compression Robust against Noise)을 제안한다. 첫 번째 단계에서는 오프라인 데이터 증강을 통해 두 종류의 검색 노이즈에 대한 압축기의 강인성을 높인다. 두 번째 단계에서는 다중 검색 문서에서 정보를 충분히 활용하지 못하고 위치 편향을 보이는 압축기의 한계를 보완하기 위해, 정답을 직접 뒷받침하는 핵심 정보를 중심으로 요약하도록 파인튜닝한다. 실험 결과, T5‑large를 ACoRN으로 학습시킨 압축기는 정답 문자열을 그대로 보존하면서 EM 및 F1 점수를 향상시켰으며, 특히 노이즈 문서가 많이 포함된 데이터셋에서 뛰어난 성능을 보였다.💡 논문 핵심 해설 (Deep Analysis)
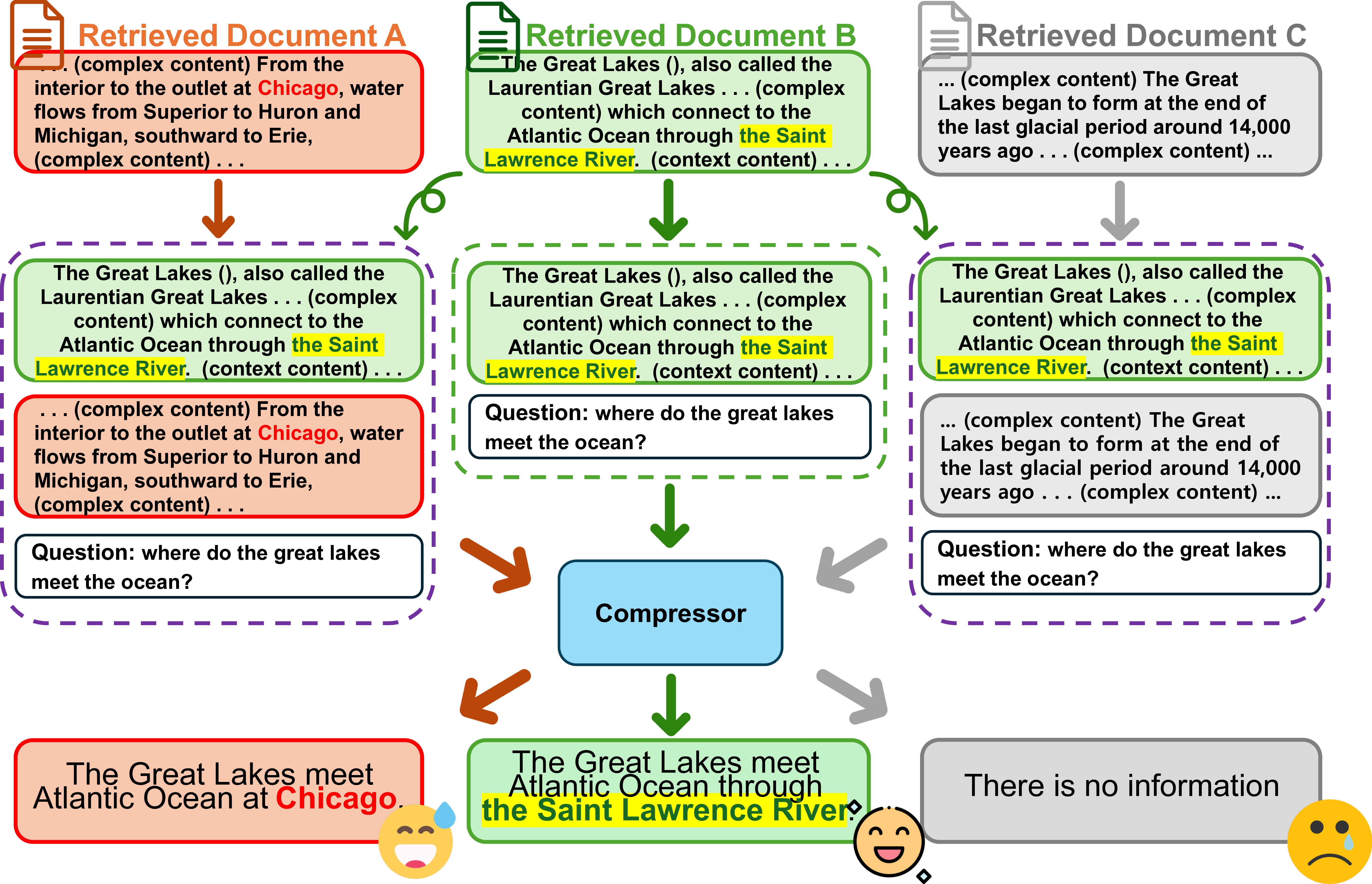
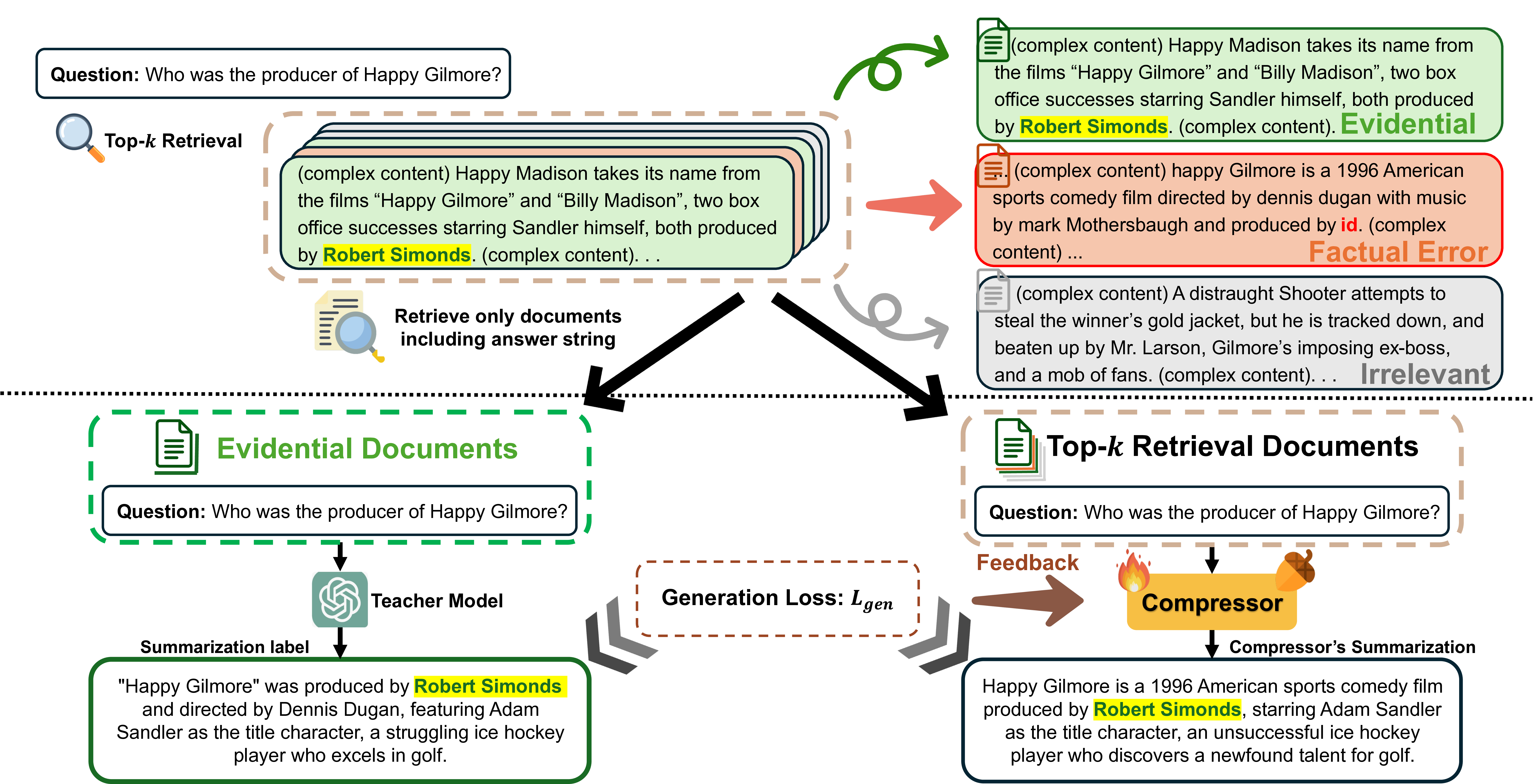
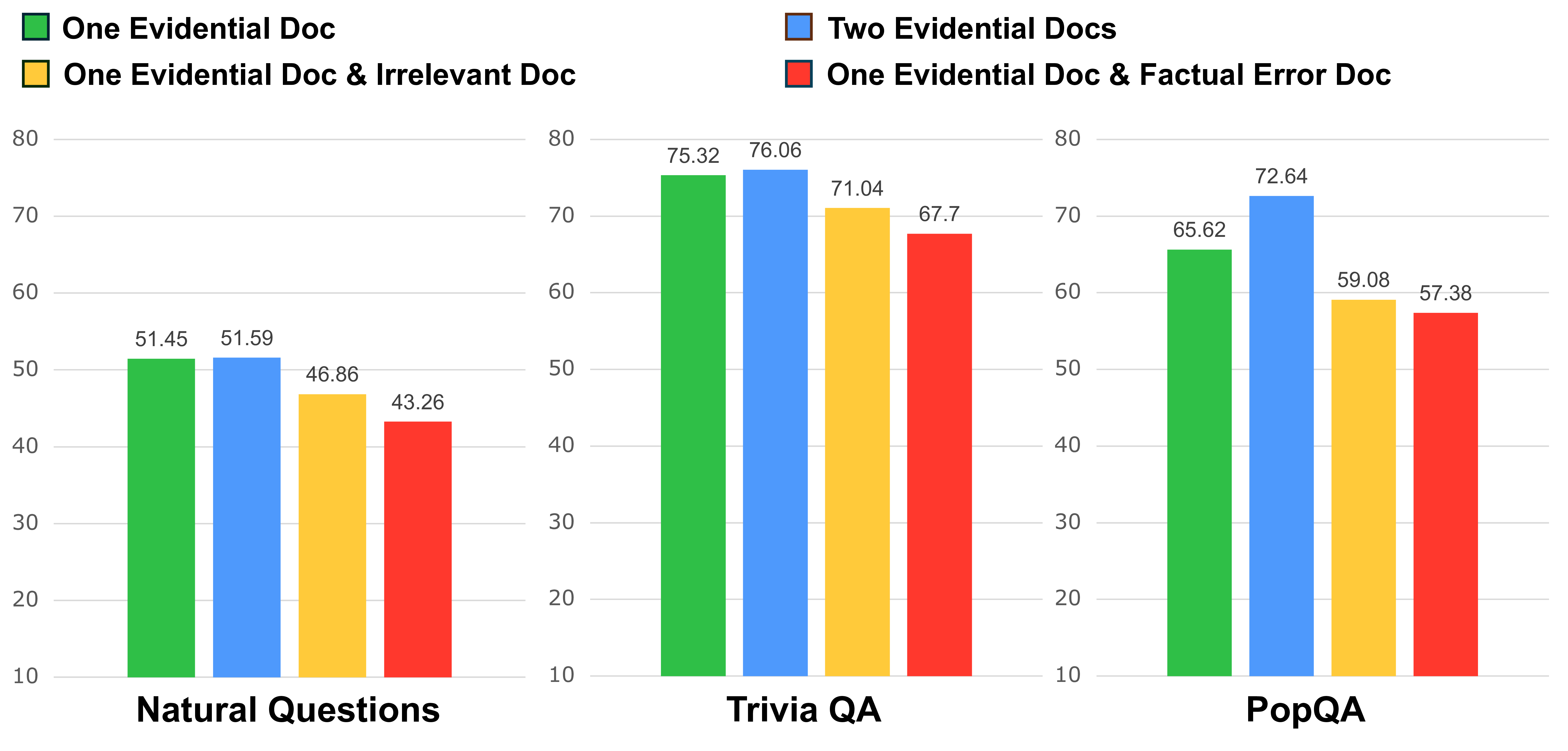
저자들은 먼저 “노이즈”를 두 가지 유형으로 구분한다. 첫 번째는 ‘irrelevant noise’로, 질문과 전혀 관련 없는 문장이나 단락이 포함된 경우다. 두 번째는 ‘misleading noise’로, 겉보기엔 관련 있어 보이지만 사실관계가 틀린 정보가 들어 있는 경우다. 이 두 유형은 압축기의 학습 데이터에 그대로 존재하면, 모델이 노이즈를 구분하지 못하고 중요한 정보를 무시하게 만든다.
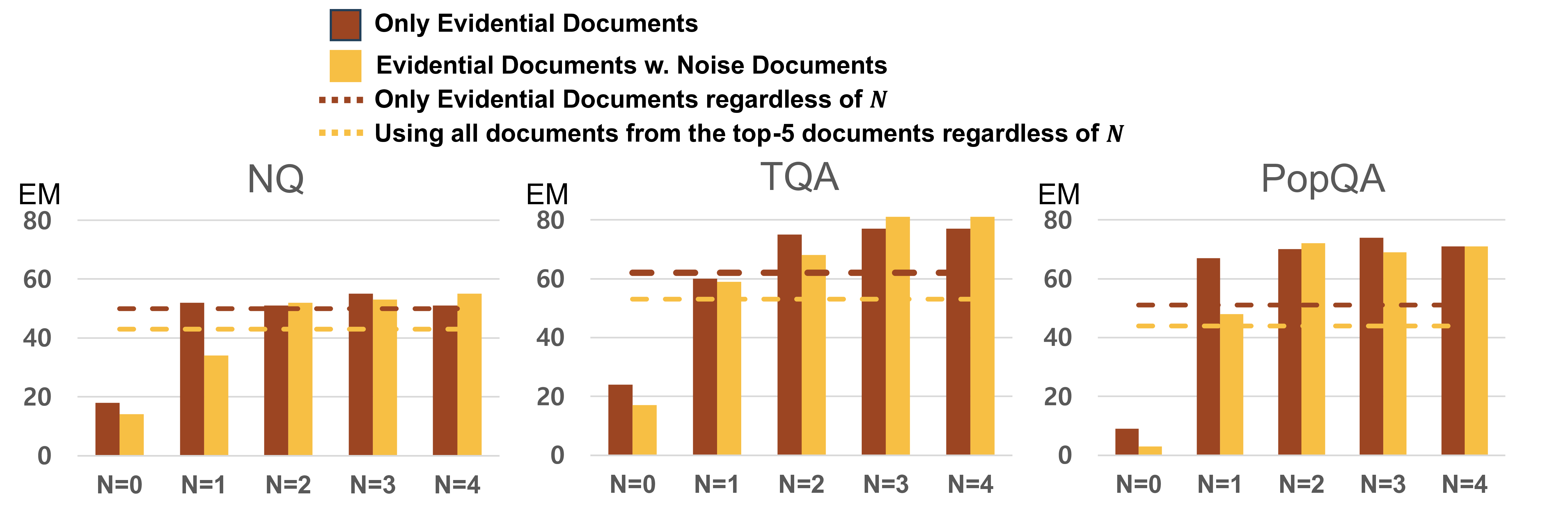
ACoRN은 이러한 문제를 해결하기 위해 두 단계의 학습 전략을 제시한다. ① 오프라인 데이터 증강 단계에서는 기존 훈련 샘플에 인위적으로 노이즈를 삽입한다. 예를 들어, 무관한 문장을 랜덤하게 추가하거나, 사실 오류가 포함된 문장을 교체함으로써 압축기가 노이즈와 신호를 구별하도록 강제한다. 이 과정은 기존 데이터의 분포를 크게 변형시키지 않으면서도 모델의 일반화 능력을 크게 향상시킨다. ② 파인튜닝 단계에서는 다중 검색 문서에서 핵심 정보를 추출하도록 압축기를 재학습한다. 여기서 핵심은 “정답을 직접 뒷받침하는 문장”을 중심으로 요약하도록 손실 함수를 설계한 점이다. 또한 위치 편향(positional bias)을 완화하기 위해 입력 순서를 무작위화하거나, 문서 간 가중치를 동적으로 조정하는 메커니즘을 도입한다.
실험에서는 T5‑large를 기본 압축기로 사용하고, ACoRN으로 학습시킨 버전과 기존 압축기 버전을 비교했다. EM(Exact Match)과 F1 점수 모두에서 유의미한 상승을 보였으며, 특히 노이즈 비율이 높은 데이터셋(NQ‑Open, TriviaQA 등)에서 성능 격차가 크게 나타났다. 흥미롭게도 압축된 출력이 정답 문자열을 그대로 포함하고 있어, 최종 생성 모델이 “증거”를 직접 인용할 수 있는 장점도 확인되었다.
이 연구는 RAG 시스템에서 압축기의 역할을 재조명하고, 노이즈에 강인한 압축기가 전체 파이프라인의 정확도와 효율성을 동시에 끌어올릴 수 있음을 실증한다. 향후에는 압축기와 검색기 사이의 공동 최적화, 혹은 멀티모달 노이즈 처리 등으로 연구 범위를 확장할 여지가 크다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리